基于特征分离和重建的跨模态检索方法
1.本发明涉及一种跨模态检索方法,具体涉及一种基于特征分离和重建的跨模态检索方法。
背景技术:
2.随着多媒体的快速发展,互联网上有大量的信息,如图像、文本、视频、音频等。手工获取海量数据中不同模态之间的有用信息变得越来越困难。自然,我们需要一种强大的方法来帮助我们获得我们需要的文本、图像或视频。跨模态检索以数据的一种模态作为查询,检索另一种模态的相关数据。例如,我们可以使用文本来检索感兴趣的图像(就像我们在谷歌图像搜索上所做的那样),或者使用图像来检索相应的文本。当然,模态不限于图像和文本,其他模态如语音、物理信号和视频也可以作为跨模态检索的一个组成部分。
技术实现要素:
3.为了更好地进行跨模态检索,本发明提供了一种基于特征分离和重建的跨模态检索方法。
4.本发明的目的是通过以下技术方案实现的:
5.一种基于特征分离和重建的跨模态检索方法,包括如下步骤:
6.步骤一、对于图像
‑
文本对中的图像部分,使用resnet152网络作为图像分支的基础图像网络,选择图像
‑
文本对中的图像作为图像分支的输入,直接从倒数第二个全连接层中提取图像特征,以获得视觉表示v;
7.步骤二、对于图像
‑
文本对中的文本部分,使用词编码,将每个token 编码为词向量,然后使用gru作为文本分支的基础文本网络,将单词序列转化为文本表示l;
8.步骤三、在分别获得视觉表示v和文本表示l之后,通过视觉和文本多层感知器进行线性变换,分别得到视觉空间和文本空间的特征向量;
9.步骤四、将不同模态空间的特征向量分解为模态信息、语义信息、特定信息三部分,其中:
10.(1)模态信息mo,表征特征向量的来源;
11.(2)语义信息se,表征由特征向量表示的高层语义;
12.(3)特定信息sp,表征不同模态特征所特有的信息;
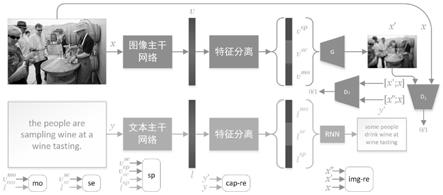
13.步骤五、利用特征分离模块将模态信息、语义信息和特定信息从视觉/ 文本表示中分离出来,得到视觉表示v和文本表示l的模态信息(v
mo
,l
mo
)、语义信息(v
se
,l
se
)和特定信息(v
sp
,l
sp
);
14.步骤六、采用dcgan的生成器和判别器分别作为图像重建的生成器 g和判别器d1,引入判别器d2确定生成的图像在内容上是否与真实图像一致,结合图像三种不同的信息(v
mo
;v
se
;v
sp
)进行图像重建;
15.步骤七、使用rnn解码文本三种不同的信息(l
mo
;l
se
;l
sp
)进行文本重建,最终生成
完整的句子。
16.相比于现有技术,本发明具有如下优点:
17.1、本发明将来自不同模态空间的特征向量分解为三部分:模态信息、语义信息和特定信息。
18.2、本发明在传统的跨模态检索任务中引入特征分离来处理不同模态之间的信息不对称,并使用不同的损失函数来监督特征向量的不同部分。
19.3、本发明还引入图像和文本重构任务分别组合图像和文本的三种不同信息,并通过多任务联合学习提高跨模态检索任务的性能,具有良好的鲁棒性。
20.4、本发明的方法可以很好地进行跨模态检索,并在多个数据库上取得了具有竞争力的结果。
附图说明
21.图1为本发明基于特征分离和重建的跨模态检索流程图;
22.图2为本发明在给定图像文本对输入的图像和文本重建结果;
23.图3为本发明的方法在ms
‑
coco数据集上给定图像查询的文本检索的可视化视觉结果;
24.图4为本发明的方法在ms
‑
coco数据集上给定文本查询的图像检索的可视化视觉结果。
具体实施方式
25.下面结合附图对本发明的技术方案作进一步的说明,但并不局限于此,凡是对本发明技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,均应涵盖在本发明的保护范围中。
26.本发明提供了一种基于特征分离和重建的跨模态检索方法,图1所示为整个网络的总体结构,大体上可以分成三个部分,具体内容如下:
27.第一个部分:多模态特征提取网络。
28.本发明遵循常用的空间学习方法来提取图像和文本的特征。形式上,给定任意图像
‑
文本对(x,y),其中x是图像,y=(w0...w
t
...w
t
‑1)是文本句子,w0、 w
t
和w
t
‑1分别表示第1个、第t+1个和第t个单词的one
‑
hot编码(token), t表示句子长度。通过使用w
e
w
t
∈r
k
将每个token嵌入到分布式表示中来编码文本,其中k=300,w
e
是word2vec嵌入矩阵。然后,使用gru作为基础文本网络,将这种可变长度的单词序列转化为有意义的、固定大小的文本表示l∈r
d
(只需将gru的最后一步输出作为整个句子的文本表示),其中d=3072。至于图像编码,为了适应可变大小的图像并受益于非常深的架构的性能,本发明依赖全卷积残差resnet
‑
152(在imagenet上预先训练) 作为基础图像网络,直接从倒数第二个完全连接的层fc7中提取图像特征,以获得视觉表示v∈r
d
。对于resnet152,图像嵌入的维数是2048。
29.本发明中,resnet152网络包括pool5、rec5b、rec4f、rec3d、rec2c 和pool1六个卷积模块和衔接在每一个卷积模块之后的pool5_a、rec5b_a、 rec4f_a、rec3d_a、rec2c_a和pool1_a六个附加模块以及串联在所有卷积模块之后的3个全连接层,其中:pool5_a、rec5b_a、rec4f_a、rec3d_a、 rec2c_a和pool1_a拥有相同的结构:3个卷积层、1个concate
层、1个 correlation层、1个sigmoid层和3个全连接层。
30.第二个部分:特征分离模块的具体结构。
31.在分别获得视觉表示和文本表示之后,由于不同模态之间的不对称性,本发明将不同模态空间的特征向量分解为三部分:(1)模态信息,表征特征向量的来源。同一模态特征向量的模态信息应尽可能接近。相反,他们应该尽量远离。(2)语义信息,表征了由特征向量表示的高层语义。特征向量的语义信息,来自不同的模态,具有相同的语义或相关的语义(即数据库中的一对样本),应尽可能接近彼此。相反,他们应该尽量远离。本发明采用图像语义信息向量和文本语义信息向量进行跨模态检索。(3)特定信息,表征了不同模态特征所特有的信息。例如,图像模态的特征向量具有特定于图像的细节信息(不同图像的细节明显不同),而该信息不存在于相应文本模态的特征向量中。本发明利用特征分离模块将上述模态信息、语义信息和特定信息从视觉/文本表示中分离出来。
32.具体地说,本发明将视觉表示v输入mlp
v
中,将文本表示l输入mlp
l
中,通过多层感知器的可学习参数进行线性变换,再进行归一化处理,最终得到视觉表示v和文本表示l的模态信息(v
mo
,l
mo
)、语义信息(v
se
,l
se
)和特定信息 (v
sp
,l
sp
),如下式所示:
[0033][0034][0035]
其中,mlp
v
表示视觉多层感知器,表示其可学习参数,分别表示归一化之前的视觉模态信息、视觉语义信息和视觉特定信息;mlp
l
表示文本多层感知器,表示其可学习参数,分别表示归一化之前的文本模态信息、文本语义信息和文本特定信息。
[0036]
第三部分:图像和文本重建。
[0037]
本发明构建图像和文本重构任务分别组合图像和文本的三种不同信息,通过多任务联合学习提高跨模态检索任务的性能。为了结合图像和文本的三种不同信息,本发明分别引入了图像和文本重建。图像重建的目标是鼓励视觉表示的三种不同信息来生成类似于真实图像的图像。生成性对抗网络(gan)可以用来生成图像,它由鉴别器和生成器组成。本发明采用 dcgan的生成器和判别器分别作为图像重建的生成器g和判别器d1。由于d1只能区分真假图像,因此无法保证生成的图像在内容上与地面真实的一致性。本发明又引入了d2来确定生成的图像在内容上是否与真实图像一致,如下式所示:
[0038]
x
′
=g([v
mo
;v
se
;v
sp
];θ
g
);
[0039][0040][0041]
其中,x
′
表示生成器生成的图像,p和q表示n属于x
′
的概率,θ表示可学习的参数。
[0042]
文本重建的目标是鼓励三种不同的文本表示信息生成一个真实句子。本发明使用rnn解码文本三种不同的信息,最终生成完整的句子,如下式所示:
[0043][0044]
其中,y
′
表示重建的句子的概率分布,w
e
表示word2vec嵌入矩阵,θ
rnn
表示rnn的可学习参数,fc2表示全连接层,表示fc2的可学习参数。
[0045]
本发明中,使用损失函数l作为优化目标,对整个网络(包括基础图像网络、基础文本网络、特征分离模块、图像重建网络和文本重建网络)进行训练,如下式所示:
[0046]
l=l
mo
+l
se
+l
sp
+l
img
‑
re
+l
cap
‑
re
;
[0047]
其中,模态损失l
mo
、语义损失(带有难负样本挖掘的三元排名损失)l
se
、特定损失l
sp
、图像重建损失l
img
‑
re
和文本重建损失l
cap
‑
re
分别如下所示:
[0048][0049][0050]
其中,n表示数据库中的样本对个数,表示第i个视觉模态信息特征,表示的均值向量,表示第i个文本模态信息特征,表示的均值向量,||
·
||2表示二范数。
[0051][0052][0053][0054]
其中,表示这两个向量的余弦相似度,表示第j个视觉语义信息特征,表示这两个向量的余弦相似度,表示第j个文本语义信息特征。
[0055][0056]
其中,表示第i个视觉特定信息特征,表示第i个文本特定信息特征,t表示转置。
[0057][0058][0059][0060]
其中,表示x来源于数据库中的图像,表示x
′
来源于图像生成器g,表示x
″
来源于g除去x
′
的部分。
[0061][0062]
其中,w
t
是来源于句子y的单词one
‑
hot编码,p(w
t
)是来源于rnn生成的w
t
的概率分布。
[0063]
实验结果:
[0064]
本发明输入到gru的单词嵌入的维数设置为300。本发明不限制句子长度,因为它对图形处理器的内存影响很小。本发明的gru和rnn都是从头开始训练的,具有3072维的四个堆叠的隐藏层。本发明将联合嵌入空间的维数设置为3072。本发明使用adam优化器训练30个epoch。前15 个epoch的学习率为0.0002,后15个epoch将学习率降低到0.00002。对于测试集的评估,本发明通过选择在验证集上表现最好的模型checkpoint来解决过拟合问题。最佳模型是根据验证集的召回总数选择的。
[0065]
在验证本发明性能时,本发明使用两个标准的公开数据库来评价本发明所提出的跨模态检索方法的性能,分别为ms
‑
coco和flickr30k。
[0066]
图2展示了本发明的方法在给定输入图像
‑
文本对的情况下的重建结果。第一列和第二列分别代表输入到网络中的图像文本对,第三列和第四列分别代表本发明的重建结果。从图3可以看出,本发明的方法可以根据输入的图像文本对重建出相近的图像和文本。
[0067]
表1展示了本发明的方法和15种最好的跨模态检索方法在r@1、r@5 和r@10这些评价标准在ms
‑
coco数据集中的定量评价结果。由于硬件的限制,本发明无法设置大多数方法在实验中设置的batchsize大小,如 100、128、160等。本发明选择vse++作为基线,并在现有硬件条件下重新运行他们的代码(batchsize=24)。本发明的方法在图像到文本(~3.4r@1,~1.9r@5和~1.0r@10)和文本到图像(~1.7r@1,~1.2r@5和~0.3r@10) 方面有显著的改进。至于表1中的结果,几种比较方法获得了更好的性能。由于硬件的限制,本发明在单个rtx 2080ti(11g)中将batchsize设置为24,而这些方法在更大batchsize的情况下获得了更好的性能。如果设置与它们相同的批量,本发明的方法需要更多的gpu。可以看出,本发明的方法可在batchsize=64、128、160等情况下实现跨模态检索任务的更好性能。
[0068]
表1实验结果与目前最好的跨模态检索结果在ms
‑
coco数据库上的对比
[0069][0070]
表2展示了本发明的方法在flickr30k数据集中的定量评价结果。本发明选择vse++作为基线,并在现有硬件条件下重新运行他们的代码(batchsize=24)。本发明的方法在图像到文本(3.3~r@1,2.7~r@5和 2.0~r@10)和文本到图像(3.2~r@1,2.5~r@5和1.3~r@10)方面有显著的改进。可以看出,本发明的方法可在batchsize=64、128、160等情况下实现跨模态检索任务的更好性能。
[0071]
表2实验结果与目前最好的跨模态检索结果在flickr30k数据库上的对比
[0072][0073]
图3展示本发明在ms
‑
coco数据集上给定图像查询的文本检索的可视化视觉结果,图4展示了本发明在ms
‑
coco数据集上给定文本查询的图像检索的可视化结果。对于每个图像查询,展示了前5个检索到的文本,这些文本按照本发明的方法预测的相似性分数进行排序。对于每个文本查询,展示了按相似度评分排名的前3个检索到的图像。这里将真正匹配的样本标记为蓝色,将错误匹配的样本标记为红色。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1