一种基于范例学习的文本摘要生成框架及方法
1.本发明涉及深度学习和自然语言处理,尤其是涉及一种基于范例学习的文本摘要生成框 架及方法。
背景技术:
2.自动文本摘要(automatic text summarization)任务是自然语言处理(nlp)中的一类基 础任务,自动文本摘要旨在将文本或文本集合转换为包含关键信息的简短摘要。按照输出类 型可分为抽取式摘要(extractive summarization)和生成式摘要(abstractive)。抽取式摘要从 源文档中抽取关键句和关键词组成摘要,摘要全部来源于原文。生成式摘要根据原文,允许 生成新的词语、短语来组成摘要。
3.主流的抽取式摘要模型主要以句子为单位进行抽取,该方法的优点是事实一致性,缺点 是输出离散的句子,不具备通顺和流畅性,与人工写的摘要相差甚远。生成式摘要的主流框 架是序列到序列模型由一个编码器和解码器组成,编码器用于编码输入的文档,解码器用于 生成摘要。生成方法最明显的优点是语句连贯,缺点是可能会生成出一些无关或原文不相符 的信息。
4.目前自动摘要系统都是仅仅依赖于文档本身,受人类写摘要的影响,我们往往需要一些 写好的范例,给予我们写作风格和样式上的指导。尤其对于一些正式的使用场景,如学术论 文、法案条文等,摘要的生成除了要提取文章的关键部分外,写作风格也尤其重要。
技术实现要素:
5.为解决现有技术的不足,实现提取文章关键部分作为摘要的同时,也能获取文章写作风 格的目的,本发明采用如下的技术方案:
6.一种基于范例学习的文本摘要生成方法,包括如下步骤:
7.s1,为待生成摘要的源文档,检索出一组用于参考的范例摘要;
8.s2,基于序列到序列框架,使用最大似然损失进行训练,包括如下步骤:
9.s21,将源文档和范例摘要合并成一个序列;源文档和每个范例摘要的前后,分别设有[cls] 和[sep]标识符,用于标识源文档、范例的开始与结束;
[0010]
s22,通过极大似然估计,使用前t
‑
1个标准摘要的真值词来预测第t个词,极大似然估 计训练的损失函数:
[0011][0012][0013]
其中p()表示第t步解码在词表上的概率分布,表示第t步解码输出的隐向量,w表 示词表大小*隐向量维度的可学习矩阵,x表示源文档,e表示范例摘要,y
t
表示摘要中的
第 t个词,y
<t
表示第t步解码之前已经生成的词,n表示句子长度;
[0014]
s3,基于训练好的序列到序列框架,预测摘要,包括如下步骤:
[0015]
s31,将源文档和范例摘要合并成一个序列;
[0016]
s32,通过极大似然估计,使用前t
‑
1个预测词来预测第t个词,得到对数似然得分:
[0017][0018]
对数似然得分越大越好,在训练阶段是要优化损失函数,这个值越小越好,因此有一个 负号;
[0019]
s33,在解码阶段,每次解码器预测一个词的概率分布,但是仅仅保留top1的那个词是 不够的,因此生成文本时采用集束搜索算法(beam search),每次预测保留一组词(topk), 接着往下预测,形成的不同路径作为候选范例摘要,即束,将第k个束的对数似然得分mle
k
, 加入文本摘要评价指标rouge奖励分(rouge credit),鼓励在集束搜索的过程中,模型尽 量选择那些和范例比较相似的束(摘要),在集束搜索中,每生成n个词后,根据解码端对编 码端所有范例摘要的注意力得分,选取被关注最多的范例摘要,并增大与所述关注最多的范 例摘要相似的束的束得分;所述注意力得分,在深度学习模型中,会把所有的词转成一个向 量,解码器输出的隐向量和编码器端的向量点乘,根据点乘的结果,便可知道目前解码器在 关注源文档中的哪个词,在生成过程中,希望去关注那些和当前词关系较大的词,如果不使 用注意力机制,效果会非常差,因此,所有的序列生成模型都会带有对编码器的注意力,对 源文档的注意力是一个分布,根据分布可以得到注意力得分;
[0020]
s34,选择得分最高的候选摘要作为最终的摘要。
[0021]
进一步地,所述s33中,被关注最多的范例摘要exemplar1,计算第k个束和exemplar1的 文本摘要评价指标rouge的得分rouge
k
,文本摘要评价指标rouge奖励分:
[0022]
credit
k
=rouge
k
*g(t)
[0023]
其中为一个与解码步数t有关的函数,l
s
为超参数,当解码步数t大于l
s
, 开始使用奖励分,最终的束得分为rouge credit加上该束平均的对数似然得分mle
k
:
[0024]
score
k
=mle
k
+credit
k
[0025]
其中n表示句子长度,y
i
表示摘要中的第i个词,y
<i
表示第i步之前已经生成的词,x 表示源文档,e表示范例摘要。
[0026]
进一步地,所述s1中,首先经过了粗粒度的过滤,将源文档中抽取的抽取式摘要,与训 练集摘要计算文本摘要评价指标rouge,根据文本摘要评价指标的得分高低,选取一组训 练集摘要,与源文档进行相似度比较,训练检索相似范例摘要的能力,在预测阶段,选取相 似度最高的一组范例摘要。
[0027]
进一步地,从保留的前100个训练集摘要中,划分前8%作为正样本和其余的负样本,所 述相似度比较,采用基于多头的余弦相似度计算,使用多个头减轻过拟合现象,每一个头都 计算一次相似度,第k个头的相似度计算为:
[0028]
[0029][0030]
其中分别为正、负样本的得分,x表示源文档,y表示候选的训练集摘要, i表示第i个负样本,j表示第j个正样本,表示源文档x的隐向量,表示正/负样本 的隐向量,对比学习损失函数将所有头相加:
[0031][0032]
其中h表示头的数量,|c
+
|、|c
‑
|分别表示正、负样本集的大小,τ表示一个温度参数, exp()表示期望函数,在预测阶段根据所有头的投票,选择相似度高的范例摘要。
[0033]
进一步地,根据文本摘要评价指标的高低,选取一组候选训练集摘要,再将候选训练集 摘要,根据文本摘要评价指标的高低,划分正、负样本。
[0034]
进一步地,所述s2中,为了更好的模仿范例的写法,我们引入对齐机制,通过标签嵌入, 使范例摘要的第i句话和目标摘要的第i句话具有相同的标签g
i
,在解码端自动学习的过程中, 注意编码端带有相同标签的词,从而将范例摘要中的句子和目标摘要中的句子对齐。
[0035]
进一步地,所述s2中,通过标签嵌入,为源文档的句子添加标签g0,在解码器的每一步 输入也加入标签g0,以防解码器过度关注范例而忽略了对源文档的学习。
[0036]
一种基于范例学习的文本摘要生成框架,包括:摘要检索器和摘要生成器,所述摘要检 索器,为待生成摘要的源文档,检索出一组用于参考的范例摘要,所述摘要生成器,包括编 码器和解码器;
[0037]
所述编码器,将源文档与范例摘要合并成一个序列;
[0038]
所述解码器,通过极大似然估计,生成摘要,在训练阶段,使用前t
‑
1个标准摘要的真值 词来预测第t个词,极大似然估计训练的损失函数:
[0039][0040][0041]
其中p()表示第t步解码在词表上的概率分布,表示第t步解码输出的隐向量,w表 示词表大小*隐向量维度的可学习矩阵,x表示源文档,e表示范例摘要,y
t
表示摘要中的第 t个词,y
<t
表示第t步解码之前已经生成的词,n表示句子长度;
[0042]
预测阶段,使用前t
‑
1个预测词来预测第t个词,得到对数似然得分:
[0043][0044]
对数似然得分越大越好,在训练阶段是要优化损失函数,这个值越小越好,因此有一个 负号;每次解码器预测一个词的概率分布,但是仅仅保留top1的那个词是不够的,因此生成 文本时采用集束搜索算法,每次预测保留一组词(topk),接着往下预测,形成的不
同路径作 为候选范例摘要,即束,将第k个束的对数似然得分mle
k
,加入文本摘要评价指标rouge 奖励分,鼓励在集束搜索的过程中,模型尽量选择那些和范例比较相似的束(摘要),解码器 对编码器有一个注意力机制,在集束搜索中,每生成n个词后,根据根据解码器对所有范例摘 要的注意力得分,选取被关注最多的范例摘要,并增大与所述关注最多的范例摘要相似的束 的束得分;选择得分最高的候选摘要作为最终的摘要。
[0045]
进一步地,所述摘要检索器包括预训练模型、多层感知机和相似度计算单元;
[0046]
所述预训练模型,采用roberta,是很深的模型,训练很慢,获取源文档及范例摘要, 将其分成多个头,并输出源文档和范例摘要的隐向量;
[0047]
所述多层感知机,是轻量的,获取预训练模型的输出,输出源文档和范例摘要基于多个 头的隐向量;
[0048]
所述相似度计算单元,在训练阶段,计算源文档与训练集范例摘要的隐向量的余弦相似 度,训练检索相似范例摘要的能力,在预测阶段,取相似度最高的一组范例摘要。
[0049]
进一步地,所述摘要生成器,在训练阶段,为了更好的模仿范例的写法,我们引入了对 齐机制,将通过标签嵌入模型,使范例摘要中的句子和目标摘要中的句子对齐。
[0050]
本发明的优势和有益效果在于:
[0051]
本发明在提取文章关键部分作为摘要的同时,也能获取文章写作风格;采用集束搜索算 法,每次预测保留一组词,接着往下预测,形成的不同路径作为候选范例摘要,即束,将第 k个束的对数似然得分加入文本摘要评价指标rouge奖励分,鼓励在集束搜索的过程中, 模型尽量选择那些和范例比较相似的束(摘要);采用基于多头的余弦相似度计算,使用多个 头减轻过拟合现象;为了更好的模仿范例的写法,引入对齐机制,通过标签嵌入,将范例摘 要中的句子和目标摘要中的句子对齐;通过标签嵌入,为源文档的句子添加标签,在解码器 的每一步输入也加入标签,以防解码器过度关注范例而忽略了对源文档的学习。
附图说明
[0052]
图1是本发明中检索器的示意图。
[0053]
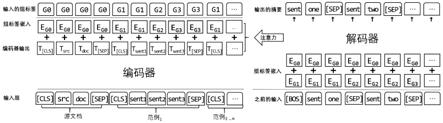
图2是本发明中基于范例学习的摘要模型。
具体实施方式
[0054]
以下结合附图对本发明的具体实施方式进行详细说明。应当理解的是,此处所描述的具 体实施方式仅用于说明和解释本发明,并不用于限制本发明。
[0055]
本发明提出了一个新的基于范例学习的生成式框架,摘要生成分为两阶段,首先使用一 个检索模型,为待生成摘要的文章检索出一些可供参考的范例摘要,与之前的工作不同,检 索器并不使用信息抽取的平台和技术,而是使用对比进行训练的。此外本发明提出了一个新 的利用这些范例的自动摘要模型,具体如下:
[0056]
一种基于范例学习的文本摘要生成框架,包括自动检索器和摘要生成模型。
[0057]
自动检索器,采用对比学习中的infonce误差函数进行训练。检索的数据库为训练集。 在进行对比学习之前,首先经过了粗粒度的过滤:使用一个简单的抽取式摘要模型,先对源 文档抽取一个抽取式摘要,然后用这个摘要和数据库中的摘要,计算文本摘要的评价
指标 rouge并保留前100个(数据库中的训练集摘要)。这100个样本中和源文档的标准摘要最 相似的前8%作为正样本,其余为负样本。受多头注意力的启发,在计算相似度使用余弦相似 度,在计算得分的时候,我们采用了多头相似度计算。具体来说,每一个头都计算一次相似 度,第k个头的相似度计算为:
[0058][0059][0060]
其中分别为正、负样本的得分,x表示源文档输入,y表示候选摘要输入, i表示第i个负样本,j表示第j个正样本,表示源文档输入x的隐向量,表示正/ 负候选摘要样本的隐向量,如图1所示,隐向量由模型根据输入的文本产生,最终的对比学 习损失函数将所有头相加:
[0061][0062]
其中h表示头的数量,|c
+
|、|c
‑
|分别表示正、负样本候选集的大小,τ表示一个温度参 数,exp()表示期望函数。在预测阶段根据所有头的投票选择范例。
[0063]
摘要生成模型,基于主流的序列到序列框架使用最大似然损失进行训练。生成模型包括 一个编码器和一个解码器。编码器负责编码输入的文本,解码器负责生成摘要。
[0064]
在生成之前,使用上文中训练好的检索器为每篇文章抽取k个范例,基于抽取出来这些范 例构建摘要生成模型。将源文档以及它的参考范例一并输入到模型中,具体地将源文档和范 例合并成一个序列,源文档和每个范例的前后依次有一个[cls]和[sep]的标识符,用于标识 源文档、范例的开始与结束。为了更好的模仿范例的写法,我们引入了对齐机制,我们认为 范例摘要中的句子和目标摘要中的句子是一一对齐的,生成第i句话的时候,我们希望模型关 注那些范例中的第i句话。对齐方式是加入标签嵌入(tag embedding),第i句话具有标签g
i
, 目标摘要和范例摘要中第i句话具有相同的标签嵌入,源文档被加上特殊的标签嵌入g0,在解 码器的每一步输入也加入这个标签。
[0065]
在训练阶段,我们是一个单词一个单词的来生成,比如生成“someone was elected”,我 们首先生成“someone”这个字再把“someone”作为输入去预测“was”,然后以“someone
ꢀꢀ
was”作为输入去预测“elected”,因此在生成第t个字符时需要之前已经生成好的t
‑
1个字符 作为解码器的输入。我们的摘要模型使用极大似然估计(mle)为损失函数,以teacher
‑
forcing 的方式得到训练,在训练时,使用前t
‑
1个step的ground truth来输出第t个step的值。例如 想生成一句话:“<s>someone was elected president</s>”,在训练时:
[0066]
当前步数解码器输入解码器输出step 0<s>someonestep 1<s>someonewasstep 2<s>someone waselected
step 3<s>someone was electedpresident
………
[0067]
令表示解码器第t步输出的隐向量,我们在该步得到在词表上的概率分布为:
[0068][0069]
训练误差函数使用极大似然估计(mle),
[0070][0071]
其中w是词表大小*隐向量维度的可学习矩阵,n表示句子长度,y
t
表示摘要中的第t个 词,y
<t
表示第t步之前已经生成的词,x表示源文档,e表示范例。
[0072]
在预测阶段,文档的标准摘要ground truth是未知的,因此在生成阶段每个模型第t个 step的输入并不是之前t
‑
1个step的ground truth,而是模型所预测的词。对于mle算法训 练的模型,在解码阶段,每次解码器预测一个词的概率分布,但是仅仅保留top1的那个词是 不够的,因此生成文本时采用集束搜索算法(beam search),允许每次保留top k个词接着往 下去生成,每个束可以看成是一个路径,即候选摘要,除原本的对数似然打分外,加入了 rouge奖励分(rouge credit),鼓励在集束搜索(beam search)的过程中,模型尽量选 择那些和范例比较相似的束(摘要)。在集束搜索中每生成n个词后,我们选取被解码器关注 最多的范例,并增大和这个范例相似的束的得分。假定目前被关注最多的范例是exemplar1, 我们计算每个束和这个范例的rouge得分,记第k个束的得分为rouge
k
,那么这个束的 rouge credit:
[0073]
credit
k
=rouge
k
*g(t)
[0074]
其中g(t)为一个和解码步数t有关的函数,我们设计l
s
为超参数,当 解码步数大于l
s
我们开始使用这个奖励分,最终的束得分为rouge credit加上该束平均的对 数似然得分:
[0075]
score
k
=mle
k
+credit
k
[0076][0077]
其中n表示句子长度,y
t
表示摘要中的第t个词,y
<t
表示第t步之前已经生成的词,x 表示源文档,e表示范例。最终选择得分最高的候选摘要作为最终的摘要。
[0078]
对于任意一篇文档,我们从训练集中首先找一些正样本(和它的摘要相似度高的为正样 本)和负样本(和它的摘要相似度低的为负样本),进行对比学习训练。如图1所示,我们为 每个输入的最前面都插入一个特殊标记<s>,我们的检索器由共享的预训练模型roberta和 多层感知机构成。预训练roberta的输入为文本,输出为文本的隐向量。我们取特殊标记<s> 的对应的隐向量作为文档表示。多层感知机层接受roberta的输出并作为输入,输出最终的 隐向量。相似度的计算使用两个隐向量的余弦相似度,类似于多头注意力,我们使用多个头 减轻过拟合现象,训练误差函数使用infonce。在预测阶段,直接根据相似度,取相似度最 高的top n作为范例摘要。
[0079]
由检索器取得范例后,我们基于范例学习的摘要模型,如图2所示,编码器
‑
解码器可替 换为任意主流的序列到序列模型,我们将源文档和范例合并成一个序列,源文档和每个范例 的前后依次有一个[cls]和[sep]的标识符。范例摘要中的第i句话和目标摘要的第i句话拥有相 同的标签嵌入g
i
,解码器端以[bos]、[eos]标识生成的开始和结束,[sep]表示一个句子生成 完毕。另外,为了区分源文档和范例,我们给源文档加上特殊的标签嵌入g0,在解码器的每 一步输入也加入这个标签,以防解码器过度关注范例而忽略了对源文档的学习。
[0080]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发 明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的 技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换, 并不使相应技术方案的本质脱离本发明实施例技术方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1