一种基于深度学习的医学图像活动轮廓分割方法
1.本发明涉及图像分割的技术领域,尤其涉及一种基于深度学习的医学图像活动轮廓分割方法,可应用于智慧医疗行业,计算机辅助诊断。
背景技术:
2.深度学习方法的发展使得计算机视觉技术飞速提高,然而医学图像分割是三维分割问题,现有深度神经网络应用到医学图像分割时,仍有所不足。根据数据的维度将三维图像的深度学习方法粗略分为两类:第一种方法通过牺牲三维的几何信息,在二维切片上训练2d网络;另一种方法使用三维网络,通过消耗大量gpu内存或是直接将图像切成小块,或者下采样后用神经网络直接处理三维数据。但是由于医学图像中部分小器官体积小、形状不一,比如胰腺、脾脏等,上述两种方法在边界以及细长狭小的部分分割结果不太理想。
3.传统的活动轮廓模型是个经典的医学图像分割模型,它高效且内存消耗低,通过处理二维边界或三维表面来处理高维图像问题。受传统的活动轮廓模型的启发,一些方法已经研究了基于边界的深度学习模型。这些方法使用神经网络来演化初始轮廓或使表面变形,来得到目标对象的二维边界或三维表面并得到最终的分割结果,这使得分割更高效,同时也使得边界更准确。然而,这些方法中的初始化边界是一组点,即点云数据,但他们的网络模型则是经典二维网络“unet”。数据与网络模型之间的差异严重影响预测精度和效率。
4.医学图像中的人体器官的自动分割,相较于传统的手工分割,极大地提高了图像分割速度并节省了人力,但是现有基于深度学习的图像分割方法获得的分割结果不够精细,存在着器官边界模糊,粘连等情况。基于边界的三维医学图像分割模型,输入的是点云数据,即由边界组成的点,但是使用的模型却是二维深度神经网络,模型不针对数据,预测精度不够高。
5.申请号为201811208492.8的发明专利,公开了一种半自动脑部图像分割方法,结合了图谱配准方法和活动轮廓分割方法的优点,实现了脑部图像的半自动分割;有效的利用了图谱的形状先验信息,并且能获得光滑连续的目标组织轮廓,但是这种方法不是全自动的,需要手动选择出目标组织边界轮廓点添加拓扑关系,得到初始活动轮廓。
技术实现要素:
6.针对现有基于深度学习的图像分割方法获得的分割结果不够精细,存在着器官边界模糊和粘连的技术问题,本发明提出一种基于深度学习的医学图像活动轮廓分割方法,是全自动的,由模型来预测初始轮廓和轮廓的演化,直接演化边界,可以得到一个更精确的分割结果;利用基于点云的网络来处理器官表面的点,提高了分割精度,同时也实现了更高的效率。
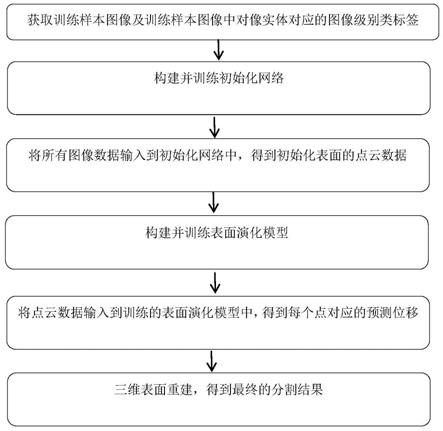
7.为了达到上述目的,本发明的技术方案是这样实现的:一种基于深度学习的医学图像活动轮廓分割方法,其步骤如下:
8.步骤一:获取医学图像作为样本图像,将样本图像分成训练集和测试集,获取训练
集中样本图像的像素级的标签;
9.步骤二:构建初始化网络,利用训练集中的样本图像和步骤一得到的像素级的标签训练初始化网络,得到粗分割模型;
10.步骤三:将所有样本图像输入到步骤二中得到的训练好的粗分割模型中得到像素级的粗分割预测图像,提取粗分割预测图像的边界点得到初始化表面的点云数据;
11.步骤四:构建表面演化网络模型,利用步骤三中得到的训练集的初始化表面的点云数据训练表面演化网络模型,得到表面演化模型;
12.步骤五:将步骤三得到的测试集的初始化表面的点云数据输入到表面演化模型中,得到边界点的预测位移,根据预测位移确定目标边界点,从而获得目标边界点集合;
13.步骤六:表面重建:利用目标边界点集合进行三维表面重建,得到最终的分割图像。
14.所述初始化网络的第一部分是卷积层,卷积层后设有批标准化层和激活函数层;紧接着是一个池化层;池化层后设有四个残差模块,其中第一个残差模块和第二个残差模块中最后的卷积层进行下采样操作,第三个残差模块和第四个残差模块中的卷积层使用膨胀卷积;接下来是密集空洞空间金字塔池化块,包含一个1
×
1的卷积层、三个膨胀卷积层以及一个全局池化层,且1
×
1的卷积层、三个膨胀卷积层和一个全局池化层并联,整合提取的特征输出一个分辨率小的分割预测图像;最后,采用上采样将分割预测图像还原到原图像的大小。
15.所述步骤一中像素级的标签是一个和样本图像同样大小、取值属于{0,1}的图像,1表示所需要的目标器官,0表示背景或其他不需要的器官;所述上采样中使用的插值方法是双线性差值法。
16.所述步骤二中初始化网络的训练方法为:将训练集中的样本图像即训练样本图像按照第三维度切成二维的切片,即:假设三维ct图像大小是h
×
w
×
d,那么可以看作是d张h
×
w大小的二维图像数据叠放在一起,每张二维图像称之为一个三维图像的一个切片;将切片输入到初始化网络,得到切片对应的分割预测图像;根据分割预测图像与像素级的标签做对比,计算二值交叉熵,作为初始化网络的损失函数,用梯度回传法更新初始化网络的参数;
17.所述像素级的粗分割预测图像的获得方法为:首先将所有训练集和测试集的三维ct图像按照第三维来分成多张二维图像,并将每个三维ct图像的二维图像依次都输入到粗分割模型中,得到预测的二维图像,并按照顺序将预测的二维图像依次叠放起来,还原回原三维图像的大小即将d张h
×
w大小的二维图像叠放成大小h
×
w
×
d的三维图像,得到一个像素级的粗分割预测图像。
18.所述提取粗分割预测图像的边界点的方法为:粗分割预测图像的每个像素点的取值是0或1,其中1表示是预测到的目标对象,而0则表示非目标对象;一个像素点周围有六个邻近像素点,若一个像素点值为1,且它的六个邻近像素点中有一个像素点为0,则这个像素点是边界点;
19.所有边界点的集合s={x1,x2,x3,
…
,x
n
},n为集合s中边界点的个数;将边界点扩充成一个边界带得到集合其中,表示图像
中的所有像素点,像素点到边界s的距离定义为像素点到边界点集合s中的所有点x的距离最小的距离,距离是指像素点和像素点x之间的的欧几里得距离,n为集合中像素点的个数;使用集合中的像素点作为初始化的点输入表面演化网络模型。
20.所述表面演化网络模型的网络结构为:第一部分是一个kp卷积层和一个一维的标准化层以及leaky激活函数;接下来是下采样部分共有五部分,一部分中包含两个kp残差模块,其中第二个kp残差模块中的kp卷积有下采样操作;中间三部分均包含3个kp残差模块,且每个部分的第三个kp残差模块中的kp卷积均有下采样操作;另一部分中包含两个kp残差模块,均无下采样操作;然后是四个上采样模块,每个上采样模块中包含一个上采样层、一个共享的多层感知机加上标准化层和激活函数;最后是两个连续的多层感知机,两个多层感知机后都是一维标准化层,用来输出最后的预测结果。
21.所述上采样层的上采样操作通过邻近算法还原出丢掉的那些像素点,使得最终输出的预测结果和输入的边界点是一致的;当特征经过上采样后,和四个有下采样操作的kp残差模块相对应的输出特征叠加在一起,输入共享的多层感知机中融合特征;
22.所述kp卷积的输入是以初始化边界点为中心、r为半径的点云数据,即集合其中,z
i
表示与边界点距离在半径r以内的像素点,为边界点集合;表示图像中的所有像素点;kp卷积是一个整合特征的操作,设表示输入的特征,f
i
代表每个像素点z
i
上的特征,则kp卷积是关于特征和核函数g的一个卷积操作:
[0023][0024]
其中,核函数g为:且{y
k
|||y
k
||2≤r,k<k}代表球体中k个关键点的位置,k个关键点的权重{w
k
|k<k}通过表面演化网络模型的训练更新参数,σ是控制距离对权重影响的参数。
[0025]
所述表面演化网络模型训练中损失函数为输出的预测位移和像素级的标签的真实位移的二范数,即:
[0026][0027]
其中,代表了二范数最大的前m个点的二范数的平均值,z
i
表示输入到表面演化网络模型中的像素点,δ(z
i
)表示像素点z
i
对应的像素级的标签生成的准确位移,γ(z
i
)表示像素点z
i
网络预测的位移;表示输入的点云数据,即输入是以初始化边界点为中心、半径为r的像素点的集合;
[0028]
以梯度回传法更新网络参数θ。
[0029]
所述根据预测位移确定目标边界点的方法为:
[0030]
将表面演化模型输出的预测位移加上该像素点原本的位置,得到了位移后的像素点的坐标即为目标边界点:
[0031][0032]
其中,表示初始化中的边界点的位置,表示表面演化模型输出的预测位移,表示初始化的表面点的集合。
[0033]
所述步骤六中表面重建的方法为:
[0034]
使用德劳内三角剖分算法将目标边界点集合剖分成空间中不均匀的四面体网格,且任一四面体的外接球范围内不会有其它点存在;去除外接圆半径大于5的四面体获得剩下的边界点和四面体,从剩下的边界点中获取的轮廓为阿尔法形状网格;使用细分算法对带有孔填充的阿尔法形状网格进行体素化,创建出一个封闭的曲面;使用泛洪算法填充封闭的曲面内的空洞,得到最终的三维分割结果。
[0035]
与现有技术相比,本发明的有益效果:本发明是一个全自动的医学图像分割模型,首先用一个二维网络模型来完成活动轮廓模型的边缘初始化,二维网络虽然精度不高,但计算量低速度快,然后用一个点云网络模型即表面演化模型来针对边界点进行优化,仅针对边界点,提高分割精度的同时也达到了节省计算时间的效果。仿真结果表明,本发明通过表面演化模型矫正了在粗分割阶段分割不准确的地方;另一方面,本发明不仅在精度上高于深度学习方法的一些经典模型,同时在速度上也快于一些基于深度学习的活动轮廓方法。
附图说明
[0036]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0037]
图1为本发明的流程示意图。
[0038]
图2为本发明初始化网络的结构图。
[0039]
图3为本发明表面演化网络的结构图。
[0040]
图4为本发明kp卷积的示意图。
[0041]
图5为本发明在msd脾脏数据集上和其他方法的两例典型对比结果。
[0042]
图6为本发明在公共数据集脾脏上和其他方法的两例典型对比结果。
具体实施方式
[0043]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有付出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0044]
如图1所示,一种基于深度学习的医学图像活动轮廓分割方法,提出了用于三维ct扫描图的一个全自动的分割器官模型,该分割器官模型是一个基于变分方法中的活动轮廓模型来进行边界演化,包括目标器官的表面初始化和目标器官的表面演化两个阶段。在第一阶段,通过2d卷积神经网络估计原始图像数据的粗分割,由于第一步的目的只是得到一
个粗略的边界初始化,对精度的要求不高,因此选用参数和计算量相对较少的2d模型,大致得到一个像素级的分割结果,这个结果准确度不高,但是足够初始化对象的边界了;然后从这个粗分割的结果中提取出属于目标对象的边界点的那些像素点作为初始化的表面边界点。在第二阶段,只针对这些表面边界点的位置进行演化,纠正不够准确的边界,具体地,使用点云卷积网络来预测初始化的表面边界点的偏移量,将所有边界点加上它们的偏移量,得到一个更准确的边界,最后,通过一个更准确的边界,可以得到一个更准确的分割结果。具体步骤如下:
[0045]
步骤一:获取医学图像作为样本图像,将样本图像分成训练集和测试集,获取训练集中样本图像的像素级的标签。
[0046]
获取三维ct医学图像,将图像数据分为训练集和测试集两个部分,并获取训练集中每个三维ct医学图像的标签,该标签是像素级的标签,标注了个每个像素点属于的类别。通常来说,1表示所需要的目标器官,如肾脏或脾脏或其他任何器官等,0表示背景或其他不需要的器官,这样,像素级的标签是一个和原图像同样大小的、但是取值属于{0,1}的一个图像。通常标注工作是由医生等专业人士来完成的。通常来说,医生会把所需要标注的目标画出来,即画出所有属于肾脏或脾脏或其他目标器官的那些像素点,那么这些像素点的取值就是1,其余的像素点的值就是0。
[0047]
步骤二:构建初始化网络,利用训练集中的样本图像和步骤一得到的像素级的标签训练初始化网络,得到粗分割模型。
[0048]
如图2所示,构建初始化网络:初始化网络的第一部分是一个核大小为3
×
3、步长为4的卷积层,卷积层后设有批标准化层以及一个激活函数层;图像在经过卷积变换后得到的特征,都是属于线性的变换,加上激活函数层可以将线性的变化变成非线性变换,从而提高网络的学习(拟合)能力。紧接着是一个池化层,池化层是一个下采样操作,它会给图像降维、去除冗余信息,从而对特征进行压缩、简化网络复杂度、减小计算量、减小内存消耗等等。然后是4个残差模块,其中第一个残差模块和第二个残差模块中最后一个3
×
3的卷积层,步长为2,通过步长为2的卷积层对图像进行下采样操作,使得图像的分辨率变小,而第三个残差模块和第四个残差模块中的卷积层,使用了膨胀卷积,膨胀系数分别为2和4,图像不再有下采样的操作。膨胀卷积与标准的卷积核不同,膨胀卷积在卷积核中增加了一些空洞,膨胀系数就是控制空洞的大小,可以在不增加参数量的同时扩大模型的感受野,获取到一些更非局部的特征信息。接下来是密集空洞空间金字塔池化块,其中包含了1个1
×
1的卷积,3个3
×
3的膨胀卷积层以及一个全局池化层,这1个1
×
1的卷积、3个膨胀卷积层和一个全局池化层是并联在一起的,3个膨胀卷积层的膨胀系数分别为6、12、18,密集空洞空间金字塔池化块的作用是整合提取的特征,这几个并联的卷积层和池化层输出的特征会叠加在一起,一起通过两个1
×
1的卷积层,这个卷积层将整合这些叠加在一起的特征,并输出一个与原图像的尺寸相比,分辨率小的分割预测图像。
[0049]
最后,采用上采样方法,将之前操作中被压缩了尺寸的图像还原到原图像的大小,其中这个上采样中使用的插值的方法是用的双线性差值法,将低分辨率的分割预测图像还原到原分辨率,并得到最终的预测图像。
[0050]
利用训练样本图像训练这个初始化网络,首先将训练样本图像的医学图像数据,按照第三维度切成二维的切片,即:假设三维ct图像大小是h
×
w
×
d的,那么可以看作是d张
h
×
w大小的二维图像数据叠放在一起,每张二维图像称之为一个三维图像的一个切片。将切片输入到上述描述的二维神经网络模型中即初始化网络,得到切片对应的分割预测图像。根据这些切片对应的分割预测图像与像素级的标签做对比,计算二值交叉熵,作为初始化网络的损失函数,用梯度回传法去更新初始化网络的参数。
[0051]
步骤三:将所有样本图像输入到步骤二中得到的训练好的粗分割模型中得到像素级的粗分割预测图像,提取粗分割预测图像的边界点得到初始化表面的点云数据,并计算每个边界点的位移。
[0052]
当初始化网络训练阶段结束后,得到一个ct图像的粗分割模型,将训练集和测试集的所有图像都输出入到这个粗分割模型中,并得到一个粗分割的结果,训练集的样本图像得到的分割结果将用在接下来边界演化的模型训练中,而测试集的样本图像得到的分割结果则会继续用来测试边界演化模型的分割结果。具体操作如下:
[0053]
首先将所有训练集和测试集的三维ct图像,都按照第三维来分成多张二维图像,并将每个三维ct图像的二维图像依次都输入到网络模型中,得到网络预测结果,并按照顺序将二维图像依次叠放起来,还原回原三维图像的大小,即将d张h
×
w大小的二维图像叠放成大小h
×
w
×
d的三维图像,这样,就得到一个像素级的预测结果,但是这个预测的结果,尤其是边界还不够准确,只能算是一个粗分割的三维图像,想要进一步提高预测的精度。不同与其他方法再利用一个网络来二次预测分割结果去提高精度,本发明将利用一个网络,预测粗分割预测图像的边界点的位移,让每个边界点的位置按照这个位移来移动,就可以将不准确的边界点移动到准确的位置,将不准确的边界演化成准确的边界。
[0054]
从粗分割预测图像中提取出属于表面的那些像素点即边界点。具体地说,粗分割预测图像是一个同原图像同样尺寸大小的图像,但是每个像素点的取值是0或1,其中1表示是预测到的目标对象,而0则表示非目标对象。一个像素点周围最近的有6个邻近像素点,分别为前后、左右、上下这六个邻近位置,那么如果一个点的取值为1,但是这周围6个邻近点中有一个点不为1,则认为这个点是边界点,因为此时的粗分割预测图像是不准确的,那么根据这个预测图像找的边界点也是一些不准确的边界点,本发明将通过第二部分的网络模型来将这些不准确的边界点移动到准确的位置上去。
[0055]
假设一共是n个边界像素点x
i
,即s={x1。同时,为了提高边界的鲁棒性,将边界点扩充成一个边界带集合:其中,代表了图像中的所有像素点,而计算的是像素点到边界s的距离,s表示的就是所有边界像素点的集合,距离是指空间两个像素点和x之间的的欧几里得距离,一个点到边界的距离的定义就是这个点到这个边界上距离最小的那个点的距离,而点x表示的是边界点集合s中距离像素点最近的那个点,也就是说,只要是距离粗分割边界的小于等于1的那些点,都将作为初始化的那些点。在实际实验中,不是直接使用边界点集合s来初始化,而是使用了距离边界少于等于1的那些点来初始化,即使用集合的那些点来作为初始化的点,以增加初始化的鲁棒性。表示的是集合中的某一个点。假设有n个点,边界带集合中的这些像素点将参与到后面的边界演化过程中去。
[0056]
另一方面,根据获取每个图像的标签找到真正属于边界的那些像素点,同样地,在
图像的像素级的标签中,对于每个像素点而言,如果值为1就表示是目标器官,如果值为0则表示非目标器官,同样地,一个像素点周围最近的有6个邻近像素点,分别为前后、左右、上下这六个邻近位置,那么如果一个点的取值为1,但是这周围6个邻近点中有一个点不为1,则认为这个点是边界点,此时,根据图像的标签找到的边界点就是准确的边界点。假设有m个点,且准确边界点集t={y1,y2,y3,
…
,y
m
}。有了这m个点,就可以计算每个边界像素点x
i
移动到真正的边界y
*
的位移:其中,是初始化边界点集中的某一个像素点,表示在准确边界点集t中和边界像素点距离最近的像素点,y是准确边界点集t中的像素点。
[0057]
此时初始化边界中每个点的位移就是接下来想要第二步的表面演化网络模型去预测的内容,有了这个位移,就可以把粗分割里那些不准确的边界点都移动到准确的边界上去。
[0058]
步骤四:构建表面演化网络模型,利用步骤三中得到的初始化表面的点云数据训练表面演化网络模型中的参数,得到表面演化模型。
[0059]
因为这些边界点都是空间中的点,本发明直接用针对点云数据的网络模型来处理医学图像的边界问题。过去的一些方法则是直接将球面上的点重排成二维平面的上,仍然用二维网络模型来处理,二维网络模型因为将点的位置重排,破坏了点云数据原来的位置结构,在模型提取特征的时候无法准确地利用到每个点的位置信息。
[0060]
本发明充分利用了球体中的核点卷积
‑‑‑
kp卷积(kernel point convolution),网络的输入是一些以初始化边界点为中心、r为半径的点云数据,即其中,z
i
表示的是与边界点距离在半径r以内的像素点,则表示的是初始化边界点集合中的像素点。kp卷积是一个整合特征的操作,如图4所示,假设表示输入的特征,那么f
i
代表了每个像素点z
i
上的特征,则kp卷积是一个关于特征和核函数g的一个卷积操作:
[0061][0062]
其中,核函数g的定义为:并且{y
k
|||y
k
||2≤r,k<k}代表了球体中k个关键点的位置,同时这k个关键点的权重{w
k
|k<k}要通过网络模型的训练来更新参数。在本发明的模型中,取15个关键点,也就是说k=15,这15个关键点的位置是在以原点为圆心,半径为r的球中随机生成的,σ则是一个控制距离对权重影响的参数,具体取值会根据点的密度进行调整。
[0063]
如图3所示,表面演化网络具体的结构如下:网络的第一部分是一个kp卷积层和一个一维的标准化层以及leaky激活函数,标准化层和激活函数增加网络的拟合能力。接下来在网络模型的下采样部分中共有5部分,第一部分中包含两个kp残差模块,其中第二个kp残差模块中的kp卷积是有下采样的,即随机丢掉一部分点,通过随机丢掉一部分点,降低了点的密度,可以扩大核函数卷积的半径,从而增大感受野。第二、第三、第四个部分中包含3个kp残差模块,且每个部分的第三个kp残差模块中的kp卷积有下采样操作。最后一个部分中
包含两个kp残差模块,均无下采样操作,此时到了下采样的最后一个部分,点的密度已经足够低,卷积的感受野足够大了,已经提取到了充足的非局部信息,所以不再需要下采样了。在下采样部分结束后之后,是四个上采样模块,每个上采样模块中包含一个上采样层和一个共享的多层感知机加上标准化层和激活函数,上采样层的上采样操作就是通过邻近算法还原出丢掉的那些点,使得最终输出的预测结果的点数和输入的点数是一致的。当特征经过上采样后,和之前四个尺寸中相对应的输出特征叠加在一起,输入共享的多层感知机中,用以融合特征。最后是两个连续的多层感知机,用来输出最后的预测结果,两个多层感知机后都是一个一维标准化层,并输出预测的位移结果γ(x)。这个模型要学习的就是每个点的位移,所以输出的就是每个点的位移。
[0064]
计算网络输出的预测位移和像素级标签的真实位移的二范数:
[0065][0066]
其中,代表了二范数最大的前m个点的二范数的平均值,z
i
表示是输入到模型中的点,δ(z
i
)表示像素点z
i
根据图像的标签生成的准确位移、γ(z
i
)表示像素点z
i
由网络预测的位移。本发明取m=0.65n;通过仅计算预测最不准确的那m个点,来提高表面演化模型的拟合能力,即让模型着重针对这些预测不准确的点,从而提高网络的预测准确度。以此作为网络的损失函数,以梯度回传法来更新网络参数θ。
[0067]
步骤五:表面演化:将步骤三得到的测试集中的初始化表面的点云数据输入到表面演化模型中,得到边界点的预测位移,每个边界点加上预测位移即为预测出的目标边界点,从而获得目标边界点集合。
[0068]
当表面演化模型训练结束后,将在表面初始化阶段得到的测试集的表面点云数据输入到表面演化网络中去,即输入点云数据需要注意的是,与训练阶段不一样,测试阶段只在乎边界点的位移是多少,即只关心像素点同时,由于的邻域范围内同时也存在其他的一些初始化边界点,因此不需要将每个边界点的领域都输入到模型中去测试一遍就能得到所有边界点的预测位移,这在一定程度又节省了计算量。有了每个点的预测位移,这个预测位移加上该点原本的位置,就得到了位移后的点的坐标:
[0069][0070]
其中,表示的是初始化中的边界点的位置坐标,表示的是表面演化模型的预测位移、表示的是初始化的表面点的集合。一个图像中,每个像素点的位置可以用三维坐标系来唯一确定,预测的位移同样是一个三维的向量,这个位移的数值大小和正负号分别代表着在这三个维度上需要移动的距离和正反方向,因此最终预测的表面点的位置可以通过每个初始化点的位置加上该点预测的位移来唯一确定。
[0071]
这样就得到了演化后的表面即目标边界点集合这个表面修正了之前的粗分割模型中不准确的边界点的位置。初始化的表面点的位置不准确,因此用第二部分的网络学习一个位移,将不准确的点移动到更准确的位移,演化后的表面会比粗
分割中更准确。
[0072]
步骤六:表面重建:利用目标边界点集合进行三维表面重建,得到最终的分割图像。
[0073]
在得到了更准确的目标边界点集合后,这个集合还只是一些散点,最终的目的还是得到一个三维的图像结果,因此将用这些点来恢复出三维图像。具体地,将使用一些算法来重建表面,最终得到三维的分割结果,这个过程中没有需要训练的参数,所以不存在训练过程。
[0074]
首先,使用德劳内三角剖分算法将目标边界点集合这个散点集剖分成空间中不均匀的四面体网格,且任一四面体的外接球范围内不会有其它点存在。为了去除掉一些相对孤立的点,使得重建出的表面更加光滑,去除外接圆半径大于5的四面体,同时也就去除掉了一些孤立点,并获得剩下的边界点和四面体,再从这些剩下的边界点中获取大致的轮廓,就是所谓的阿尔法形状网格。接下来,使用细分算法对带有孔填充的阿尔法形状网格进行体素化,也就是说创建出一个封闭的曲面,这个曲面就是通过演化边界点得到的更精确的表面,最后一步,使用泛洪算法填充这个封闭曲面内的空洞,这样就能得到最终的三维分割结果。
[0075]
本发明用戴斯相似性系数dsc和豪斯多夫距离hd,以及时间作为评价标准。所有实验的代码都是使用pytorc,在nvidia的gpu titan rtx上完成的。
[0076]
戴斯相似性系数dsc度量两个集合的相似性,具体定义如下:
[0077][0078]
其中,p代表了模型预测出的器官的所有像素点集合,而则是真实的器官所有像素点的集合。戴斯相似性系数dsc越大则表明分割结果越好。
[0079]
而豪斯多夫距离hd衡量的是两个表面之间的距离,具体定义如下:
[0080][0081]
其中,代表了模型预测出的器官表面的所有像素点集合,而则是真实的器官表面的素有像素点的集合。豪斯多夫距离hd越小则说明两个表面越接近,预测结果越好。
[0082]
在msd(medical segmentation decathlon)脾脏数据集上对比了相关方法的结果。msd数据集包含41个病,将数据集随机分为两组,一组为训练集包含21个用于训练模型,另一组为测试集包含20个病例用于测试。
[0083]
表1在msd脾脏数据集上的结果
[0084][0085]
其中,2维网络rstn来自于文献[qihang yu,lingxi xie,yan wang,yuyin zhou,elliot k.fishman,and alan l.yuille.recurrent saliency transformation network:
incorporating multi
‑
stage visual cues for small organ segmentation.in proceedings of the ieee conference on computer vision and pattern recognition(cvpr),pag来自于文献es 8280
–
8289,june 2018.]、3维网络vnet来自于文献[fausto milletari,nassir navab,and seyed
‑
ahmad ahmadi.v
‑
net:fully convolutional neural networks for volumetric medical image segmentation.in 2016fourth interna
‑
tional conference on 3d vision(3dv),october 2016.]、2维边界演化ebp[tianwei ni,lingxi xie,huangjie zheng,elliot k fishman,and alan l yuille.elastic boundary projection for 3d medical image segmentation.in proceedings of the ieee conference on computer vision and pattern recognition(cvpr),pages 2109
–
2118,2019.]、2维边界演化lsm来自于文献[lihong guo,yueyun liu,yu wang,yuping duan,and xue
‑
cheng tai.learned snakes for 3d image segmentation.signal processing,183:108013,june 2021.]。如图5所示,图5对比了标签、ebp方法、lsm方法和本发明在msd脾脏数据集上的测试结果的两个典型例子,分别是第一行和第二行。通过对比可以看出,本发明在边界处分割得更准确,而另外两种方法则比较容易分出界。
[0086]
同时在另一个公共脾脏数据集上也测试了本发明的分割结果,一共包含90个ct病例,其中,43个来自the cancer imaging archive(tcia),另外47个来自beyond the cranial vault(btcv)分割挑战赛随机选择45个病例,其中21个来自tcia,24个来自btcv来训练本发明的模型,而剩下的45个病例用于测试。
[0087]
表2公共脾脏数据集上的测试结果
[0088]
方法dsc(%)95%hd(mm)时间(s)2维边界演化lsm91.80%7.84213本发明93.87%4.6976
[0089]
由表1和表2可知,本发明在精度上优于其他的方法,在速度上优于同类型的边界演化方法。
[0090]
如图6所示,图6对比了标签、lsm方法和本发明在公共脾脏数据集上的测试结果的两个典型例子。同样可以看出,本发明可以有效地提高分割精度。本发明的测试结果更准确,边界更接近于标签的结果。
[0091]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1