多媒体检索方法、装置及计算机设备与流程
1.本发明涉及互联网技术领域,尤其涉及一种多媒体检索方法、装置及计算机设备。
背景技术:
2.随着社会的发展,在人们日常生活中,人们的维权意识越来越强烈。例如,在多媒体侵权检索领域,多媒体侵权检索是指根据用户输入的多媒体,从多媒体库中找到与该用户所输入的多媒体最为相似的多媒体,可判定为该多媒体的侵权多媒体。即需要从一批需要被保护的候选多媒体中找到所被侵权的多媒体。
3.目前,常见的多媒体检索(例如视频检索)做法是根据视频特征(如视频embedding)进行检索,进而获取检索后得到的视频。然而,根据单一的视频特征进行侵权视频的判定很容易出现误判的情况,导致视频检索的准确度较低。因此,如何准确地进行多媒体检索是当前亟待解决的一个技术问题。
技术实现要素:
4.本技术实施例提出了一种多媒体检索方法及装置,可以在对各模态特征进行融合处理得到待检索多媒体的多模态特征之前,预先对各模态特征分别进行自融合处理,使得多模态特征更加准确,从而提高多媒体检索的准确性。
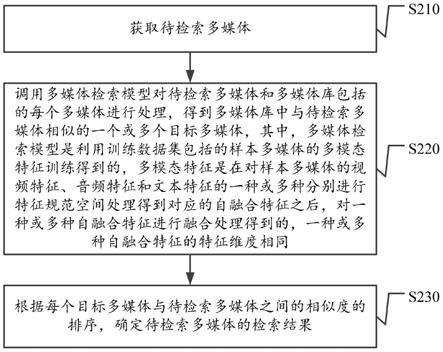
5.一方面,本技术实施例提供一种多媒体检索方法,该方法包括:
6.获取待检索多媒体;
7.调用多媒体检索模型对待检索多媒体和多媒体库包括的每个多媒体进行处理,得到多媒体库中与待检索多媒体相似的一个或多个目标多媒体,其中,多媒体检索模型是利用训练数据集包括的样本多媒体的多模态特征训练得到的,多模态特征是在对样本多媒体的视频特征、音频特征和文本特征的一种或多种分别进行特征规范空间处理得到对应的自融合特征之后,对一种或多种自融合特征进行融合处理得到的,一种或多种自融合特征的特征维度相同;
8.根据每个目标多媒体与待检索多媒体之间的相似度的排序,确定待检索多媒体的检索结果。
9.一方面,本技术实施例提供一种多媒体检索装置,该装置包括:
10.获取单元,用于获取待检索多媒体;
11.处理单元,用于调用多媒体检索模型对所述待检索多媒体和多媒体库包括的每个多媒体进行处理,得到所述多媒体库中与所述待检索多媒体相似的一个或多个目标多媒体,其中,所述多媒体检索模型是利用训练数据集包括的样本多媒体的多模态特征训练得到的,所述多模态特征是在对样本多媒体的视频特征、音频特征和文本特征的一种或多种分别进行特征规范空间处理得到对应的自融合特征之后,对一种或多种自融合特征进行融合处理得到的,一种或多种自融合特征的特征维度相同;
12.确定单元,用于根据每个目标多媒体与所述待检索多媒体之间的相似度的排序,
确定所述待检索多媒体的检索结果。
13.一方面,本技术实施例提供一种计算机设备,该计算机设备包括存储器和处理器,存储器存储有计算机程序,计算机程序被处理器执行时,使得处理器执行上述的多媒体检索方法。
14.一方面,本技术实施例提供一种计算机可读存储介质,该计算机可读存储介质存储有计算机程序,该计算机程序被计算机设备的处理器读取并执行时,使得计算机设备执行上述的多媒体检索方法。
15.一方面,本技术实施例提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述的多媒体检索方法。
16.通过本技术实施例,在获取到待检索多媒体之后,可以调用多媒体检索模型对待检索多媒体和多媒体库包括的每个多媒体进行处理,得到多媒体库中与待检索多媒体相似的一个或多个目标多媒体,其中,多媒体检索模型是利用训练数据集包括的样本多媒体的多模态特征训练得到的,并且多模态特征是在对样本多媒体的视频特征、音频特征和文本特征的一种或多种分别进行特征规范空间处理得到对应的自融合特征之后,对一种或多种自融合特征进行融合处理得到的,一种或多种自融合特征的特征维度相同;然后,根据每个目标多媒体与待检索多媒体之间的相似度的排序,确定待检索多媒体的检索结果。可见,本技术实施例中,用于检索待检索多媒体的多媒体检索模型是利用多个样本多媒体的多模态特征训练后得到的,首先,提前对样本多媒体的视频特征、音频特征和文本特征的一种或多种分别进行特征规范空间处理,从而确定了对应的自融合特征,进一步地,根据一种或多种自融合特征再融合处理后得到样本多媒体的多模态特征。因此,本技术中的多模态特征在对各模态特征进行拼接融合之前,还会预先对各模态特征分别进行自融合处理得到对应的自融合特征,相比于直接对各模态特征进行拼接融合,本技术可以将各模态的特征维度压缩到相同的特征维度,使得各模态特征能够均衡分布;并且规范各模态的特征空间,因此,本技术所确定的多模态特征更加准确。进一步地,基于更加准确的待检索多媒体的多模态特征进行多媒体检索时,也可以检索得到更加准确的目标多媒体,进而提高多媒体检索的准确性。
附图说明
17.为了更清楚地说明本技术实施例技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
18.图1是本技术实施例提供的一种多媒体检索系统的架构示意图;
19.图2是在申请实施例提供的一种多媒体检索方法的流程示意图;
20.图3a是本技术实施例提供的一种非局部操作模块的原理示意图;
21.图3b是本技术实施例提供的一种基于残差的非局部操作的原理示意图;
22.图4是本技术实施例提供的一种确定音频特征的流程示意图;
23.图5a是本技术实施例提供的一种多媒体检索模型的结构示意图;
24.图5b是本技术实施例提供的另一种多媒体检索模型的结构示意图;
25.图5c是本技术实施例提供的另一种多媒体检索模型的结构示意图;
26.图6是本技术实施例提供的一种训练多媒体检索模型的流程示意图;
27.图7是本技术实施例提供的一种神经网络模型确定相似度的结构示意图;
28.图8是本技术实施例提供的一种多媒体检索装置的结构示意图;
29.图9是本技术实施例提供的一种计算机设备的结构示意图。
具体实施方式
30.这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本技术相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本技术的一些方面相一致的装置和方法的例子。
31.首先,介绍本技术实施例中所涉及到的一些技术术语:
32.图像识别:类别级别的识别,不考虑对象的特定实例,仅考虑对象的类别(如人、狗、猫、鸟等)进行的识别并给出对象所属类别。一个典型的例子是大型通用物体识别开源数据集imagenet中的识别任务,识别出某个物体是1000个类别中的哪一个。
33.imagenet:大型通用物体识别开源数据集。
34.imagenet预训练模型:基于imagenet训练一个深度学习网络模型,得到该模型的参数权重即为imagenet预训练模型。
35.视频检索:包括输入文字描述、返回视频,以及输入视频、返回相关视频,下文关注第二种视频检索视频情况。
36.视频相似度排序:在query视频在检索库中获取相似视频的任务中,需要对检索结果进行排序,使得排在前面的视频与query更相似。
37.视频侵权:当a视频为b视频的一部分、包含b视频、部分素材来自b视频,即构成a视频对b视频侵权。
38.进一步地,对本技术实施例涉及的技术术语再次进行介绍:
39.一、人工智能:
40.人工智能(artificial intelligence,ai)是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。随着人工智能技术研究和进步,人工智能技术在多个领域展开研究和应用,例如常见的智能家居、智能穿戴设备、虚拟助理、智能音箱、智能营销、无人驾驶、自动驾驶、无人机、机器人、智能医疗、智能客服、智能游戏、智慧交通等,相信随着技术的发展,人工智能技术将在更多的领域得到应用,并发挥越来越重要的价值。
41.本技术实施例提供的方案属于人工智能领域下属的计算机视觉技术(computer vision,cv),语音技术(speech technology)和自然语言处理(nature language processing,nlp)技术等,可以应用于视频侵权检索、视频相似度检索排序等领域。本技术中,用于多媒体检索的多媒体检索模型是根据样本多媒体的多模态特征训练得到的,多模态特征是根据视频特征、音频特征和文本特征的一种或多种得到的。其中,可以利用计算机视觉技术提取样本多媒体的视频特征,利用语音技术提取样本多媒体的音频特征,以及利
用自然语言处理技术提取样本多媒体的文本特征。基于样本多媒体的多个维度的特征来确定出来的多模态特征用于模型训练,最终训练得到的多媒体检索模型的准确性较高。从而,在多媒体检索应用中,利用准确性更高的多媒体检索模型检索得到的检索结果也更加准确。因此,本技术提供的多媒体检索方法对于视频检索、音频检索、音视频检索等多媒体检索等应用领域具有较高的参考价值和实践意义。
42.二、云技术:
43.云技术(cloud technology)基于云计算商业模式应用的网络技术、信息技术、整合技术、管理平台技术、应用技术等的总称,可以组成资源池,按需所用,灵活便利。云计算技术将变成重要支撑。技术网络系统的后台服务需要大量的计算、存储资源,如视频网站、图片类网站和更多的门户网站。伴随着互联网行业的高度发展和应用,将来每个物品都有可能存在自己的识别标志,都需要传输到后台系统进行逻辑处理,不同程度级别的数据将会分开处理,各类行业数据皆需要强大的系统后盾支撑,只能通过云计算来实现。
44.目前,云技术主要分为云基础技术类以及云应用类;云基础技术类可以进一步细分为:云计算、云储存、数据库以及大数据等;云应用类可以进一步细分为:医疗云、云物联、云安全、云呼叫、私有云、公有云、混合云、云游戏、云教育、云会议、云社交以及人工智能云服务等。
45.从基础技术角度来说,本技术的多媒体检索方法涉及云技术下属的云计算;从应用角度来说,本技术的多媒体检索方法涉及云技术下属的人工智能云服务。
46.云计算(cloud computing)是一种计算模式,它将计算任务分布在大量计算机构成的资源池上,使各种应用系统能够根据需要获取计算力、存储空间和信息服务。提供资源的网络被称为“云”。“云”中的资源在使用者看来是可以无限扩展的,并且可以随时获取,按需使用,随时扩展,按使用付费。
47.所谓人工智能云服务,一般也被称作是aiaas(ai as a service,中文为“ai即服务”)。这是目前主流的一种人工智能平台的服务方式,具体来说aiaas平台会把几类常见的ai服务进行拆分,并在云端提供独立或者打包的服务。这种服务模式类似于开了一个ai主题商城:所有的开发者都可以通过api接口的方式来接入使用平台提供的一种或者是多种人工智能服务,部分资深的开发者还可以使用平台提供的ai框架和ai基础设施来部署和运维自已专属的云人工智能服务。
48.在本技术中,调用多媒体检索模型对待检索多媒体和多媒体库包括的每个多媒体进行处理,得到多媒体库中与待检索多媒体相似的一个或多个目标多媒体,以及利用训练数据集包括的多个样本多媒体的多模态特征训练多媒体检索模型,涉及大规模计算,需要巨大的算力和存储空间,因此在本技术中,可以由计算机设备通过云计算技术获取足够算力和存储空间,进而执行本技术中所涉及的确定待检索多媒体的检索结果。
49.进一步地,可以将本技术涉及的多媒体检索方法封装为一个人工智能云服务,且仅对外暴露一个接口。当在某一业务场景下需要使用本技术所涉及的多媒体检索功能时,通过调用该接口,即可完成对待检索多媒体的多媒体检索功能(例如视频检索等)。
50.三、区块链:
51.区块链(blockchain)是分布式数据存储、点对点传输、共识机制、加密算法等计算机技术的新型应用模式。区块链本质上是一个去中心化的数据库,是一串使用密码学方法
相关联产生的数据块,每一个数据块中包含了一批次网络交易的信息,用于验证其信息的有效性(防伪)和生成下一个区块。区块链可以包括区块链底层平台、平台产品服务层以及应用服务层。
52.本技术的多媒体检索方法可与区块链技术相结合,例如可以将待检索多媒体、目标多媒体和训练数据集等上传至区块链中进行保存,可以保证区块链上的数据不易被篡改。
53.本技术实施例可以广泛应用于多媒体相似度检索、多媒体侵权检索等领域。例如在多媒体相似度检索应用中,通过调用多媒体检索模型对用户输入的query视频(待检索视频)进行识别,然后可以得到多媒体库中与待检索视频相似的一个或多个目标视频。然后,根据每个目标多媒体与待检索多媒体之间的相似度,进行相似度排序,可以按照相似度由高到低的排列顺序确定待检索多媒体的检索结果。进一步地,基于相似度检索得到的一个或多个目标视频,在多媒体侵权检索应用中,可以从一个或多个目标视频中,确定出与待检索视频之间构成侵权的侵权视频。后续,基于侵权视频做进一步的维权处理等。
54.请参考图1,图1是本技术实施例提供的一种多媒体检索系统的架构示意图。该多媒体检索的系统架构图包括:服务器140以及终端设备集群,其中,终端设备集群可以包括:终端设备110、终端设备120、终端设备130等等。终端设备集群与服务器140可以通过有线或无线通信方式进行直接或间接地连接,本技术在此不做限制。
55.图1所示的服务器140可以是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、cdn(content deliverynetwork,内容分发网络)、以及大数据和人工智能平台等基础云计算服务的云服务器。
56.图1所示的终端设备110、终端设备120、终端设备130等可以是手机、平板电脑、笔记本电脑、掌上电脑、移动互联网设备(mid,mobile internet device)、车辆、车载设备、路边设备、飞行器、可穿戴设备,例如智能手表、智能手环、计步器等,等具有模型训练功能的智能设备。
57.在一种可能的实现方式中,以终端设备110为例,终端设备110获取待检索多媒体,然后终端设备110将待检索多媒体发送至服务器140。然后,服务器140在获取到待检索多媒体之后,调用多媒体检索模型对待检索多媒体和多媒体库包括的每个多媒体进行处理,得到多媒体库中与待检索多媒体相似的一个或多个目标多媒体。其中,多媒体检索模型是利用训练数据集包括的多个样本多媒体的多模态特征训练得到的,多模态特征是在对样本多媒体的视频特征、音频特征和文本特征的一种或多种分别进行特征规范空间处理得到对应的自融合特征之后,对一种或多种自融合特征进行融合处理得到的。接下来,服务器140根据每个目标多媒体与待检索多媒体之间的相似度的排序,确定待检索多媒体的检索结果。最后,服务器140将待检索多媒体的检索结果发送至终端设备110。后续,终端设备110可以输出并展示待检索多媒体的检索结果。
58.当然,调用多媒体检索模型对待检索多媒体和多媒体库包括的每个多媒体进行处理,得到多媒体库中与待检索多媒体相似的一个或多个目标多媒体。不一定是由服务器140来执行,也可以由终端设备110或者终端设备集群中的其它任意计算机设备来执行。并且,利用训练数据集包括的多个样本多媒体的多模态特征训练得到多媒体检索模型,也不一定
由服务器140来执行,同样可以由终端设备110或者终端设备集群中的其它任意计算机设备来执行。
59.在一种可能的实现方式中,可以将本技术实施例提供的多媒体检索系统部署在区块链的节点,例如可以将服务器140和终端设备集群中包括的每个计算机设备均当成区块链的节点设备,共同构成区块链网络。因此本技术中对待检索多媒体的多媒体检索流程可以在区块链上执行,这样既可以保证多媒体检索流程的公平公正化,同时可以使得多媒体检索流程具备可追溯性,提升多媒体检索流程的安全性。
60.可以理解的是,本技术实施例描述的系统架构示意图是为了更加清楚的说明本技术实施例的技术方案,并不构成对于本技术实施例提供的技术方案的限定,本领域普通技术人员可知,随着系统架构的演变和新业务场景的出现,本技术实施例提供的技术方案对于类似的技术问题,同样适用。
61.基于以上分析,下面结合图2对本技术的多媒体检索方法进行描述。请参见图2,图2是本技术实施例提供的一种多媒体检索方法的流程示意图。该多媒体检索方法可以由计算机设备执行,计算机设备可以为终端设备,计算机设备也可以包括终端设备和服务器。如图2所示,该多媒体检索方法可包括步骤s210~s230。其中:
62.s210:获取待检索多媒体。
63.本技术实施例中,多媒体可以包括视频、音频、文本中的一种或多种。其中,多媒体为视频的情况下,视频可以为纯视频,视频也可以包括音频和文本,本技术对此不作具体限定。例如,用户可以输入一段需要进行检索的query视频,则计算机设备可以将用户输入的query视频作为待检索多媒体。
64.s220:调用多媒体检索模型对所述待检索多媒体和多媒体库包括的每个多媒体进行处理,得到多媒体库中与待检索多媒体相似的一个或多个目标多媒体,其中,多媒体检索模型是利用训练数据集包括的样本多媒体的多模态特征训练得到的,多模态特征是在对样本多媒体的视频特征、音频特征和文本特征的一种或多种分别进行特征规范空间处理得到对应的自融合特征之后,对一种或多种自融合特征进行融合处理得到的,一种或多种自融合特征的特征维度相同。
65.本技术实施例中,多媒体检索模型可以为神经网络模型。例如,多媒体检索模型可以具体是rnn(循环神经网络,recurrentneural network,rnn)模型,lstm(长短期记忆网络,lstm,long short-term memory),gru(门控循环神经网络,gated recurrent neural network)模型,或者神经网络模型也可以为其它类型的网络模型,例如递归神经网络模型等,本发明对此不作限定。
66.在一种可能的实现方式中,计算机设备调用多媒体检索模型对待检索多媒体和多媒体库包括的每个多媒体进行处理,得到多媒体库中与待检索多媒体相似的一个或多个目标多媒体,的流程可以包括:首先,获取待检索多媒体的特征信息,特征信息包括视频特征、音频特征和文本特征的一种或多种。然后,将待检索多媒体的特征信息输入多媒体检索模型进行处理,得到待检索多媒体的多模态特征。最后,调用多媒体检索模型对待检索多媒体的多模态特征以及多媒体库包括的每个多媒体的多模态特征进行处理,得到多媒体库中与待检索多媒体相似的一个或多个目标多媒体。
67.本技术主要是通过提取多媒体的特征信息,特征信息可以包括视频特征(可表示
为视频embedding)、音频特征(可包括音乐embedding和人声embedding)和文本特征(如标题embedding)中的一种或多种之后,将所提取出来的多媒体的特征信息输入到本技术实施例所提供的多媒体检索模型中进行处理,最终通过相似度层进行相似度度量。因此,接下来,针对如何提取多媒体的视觉embedding、基于音频的音乐embedding和人声embedding、标题embedding、模型学习等进行详细描述:
68.在一种可能的实现方式中,特征信息包括视频特征。那么,获取待检索多媒体的视频特征的流程,可以包括:首先,获取待检索多媒体的视频数据;然后,对视频数据进行分镜处理,得到分镜处理后的多个分镜视频;接下来,根据多个分镜视频确定视频数据对应的多个视频片段;最后,分别确定多个视频片段中每个视频片段的视频特征,并根据每个视频片段的视频特征,确定待检索多媒体的视频特征。
69.举例来说,可以利用non-local neural networks模型(非局部神经网络模型)获取待检索多媒体的视频特征。其中,该模型获取视频特征的方法主要是基于图像embedding的时间序列,训练3d(3dimensions,三维)卷积,并通过non-local(非局部)的方法获取长程序列关系。本处embedding采用全连接分类层(fully connected layers,fc)输入向量作为视频embedding。
70.在具体实现时,由于non-local每次学习指定帧fr的短视频,为了降低计算时间,本技术可以预先把待检索多媒体进行分镜处理,分镜处理之后得到多个分镜视频,然后可以从每个分镜视频中抽取3帧(例如第一帧、中间帧、最后一帧)组成一个新视频。然后,将所得到的多个新视频中由32帧组成一个视频片段。接下来,再分别计算每个视频片段的视频特征(non-local embedding,非局部视频特征),并根据多个视频片段的视频特征,最终确定出待检索多媒体的视频特征。例如,可以通过多个视频片段的视频特征求取平均值,然后将所确定的平均值作为待检索多媒体的视频特征;又如,可以将多个视频片段的视频特征中各特征位取最大值(假设有10段音频,每段128维特征,那么对128维中的每一维度,均取10个中的最大值组成),作为待检索多媒体的视频特征。
71.接下来,进一步阐述基于non-local neural networks模型获取待检索多媒体的视频特征的相关原理:
72.首先,non-local neural networks模型中,设计的3d的网络结构与2d的网络结构类似,故non-local neural networks模型可以采用resnet50 c2d(conv2d)。其中,本技术实施例提供的一种非局部神经网络模型的结构示意图可以如表1所示:
73.表1.非局部神经网络模型的结构
[0074][0075][0076]
如上表1所示,其中每个res block模块后均有maxpooling(最大池化处理),其中,res block模块是指构成resnet(residual neural network,残差神经网络)的基础模块。基于res block模块可以将模型改造为3d的网络,3d与2d网络不同在于模型输入为t
×w×
h,深度网络层输出为t
×
w1
×
h1
×
c,其中的卷积核也需要相应改成conv3d卷积,卷积核从(3x3)增加时间维度为(tx3x3)。最终得到t
×4×7×
7的输出为视频在深度特征空间表征(resnet 3d特征)。
[0077]
接下来,介绍一下non-local模块(非局部操作模块),请参见图3a,图3a是本技术实施例提供的一种非局部操作模块的原理示意图。如图3a所示,在获取了resnet 3d特征后,其中non-local模块的操作如下:1x1表示采用1x1的卷积,故卷积核的大小为nx1x1(n为时间维度),oc=c/2表示output channel(输出通道)变为input channel(输入通道)一半。下图对输入x分别进行θ和卷积运算后把结果进行矩阵相乘,产生了x内h
×
w元素内部的self-attention(自注意力)功能,得到n个时间下hw
×
hw的自相关信息,即n
×
hw
×
hw输出,该信息通过softmax(归一化)处理,由于softmax会使得输入向量被激活到0~1范围且向量和为1,故等价于做归一化。经过归一化的自相关信息与g卷积操作的输出做矩阵乘法,相当于以hw相关信息对g结果进行加权求和输出。由于该输出对每一个位置的学习都考虑了所有hw的相关信息,故称为non-local非局部操作。得到加权的输出后,经过一次卷积操作使得channel变回c,再与输入x对应位置相加(类似残差res结构,增加输入与输出间的直连通道,避免梯度消失),产生最后的输出。
[0078]
最后,请参见图3b,图3b是本技术实施例提供的一种基于残差的非局部操作的原
理示意图。non-local neural networks模型在resnet深度特征空间表征后通过3个堆叠的non-local模块提取视频embedding,经过avg pooling池化(平均池化)以及fc分类层得到视频分类。如图3b所示,本技术实施例中需要提取的视频embedding为avg pooling的输出。
[0079]
在一种可能的实现方式中,特征信息包括音频特征。那么,获取待检索多媒体的音频特征的流程,可以包括:首先,获取待检索多媒体的音频数据;然后,对音频数据进行分离处理,得到音乐数据和人声数据;接下来,确定音乐数据对应的音乐特征,以及确定人声数据对应的人声特征;最后,将音乐特征和人声特征作为待检索多媒体的音频特征。
[0080]
具体实现时,待检索多媒体中的音频数据可能会包括音乐数据和人声数据。针对音乐数据和人声数据需要分开处理,本技术实施例中可采用开源的模型进行处理,当然也可以采用业务收集的数据对开源模型重新训练,进而提取音频embedding。
[0081]
举例来说,请参见图4,图4是本技术实施例提供的一种确定音频特征的流程示意图。如图4所示,首先,获取待检索多媒体的音频数据;然后,对音频数据进行分离处理,得到音乐数据和人声数据。其中,对音频数据进行分离处理可以利用开源的spleeter(法国的音乐流媒体公司deezer开源的音轨分离软件spleeter)完成此任务。即通过“spleeter separate-i audio_example.mp3-oaudio_output”指令可以输出音乐通道的wav文件(音乐数据)与人声通道的wav文件(人声数据)。
[0082]
然后,对音乐数据和人声数据分别求embedding。其中,可以采用vggish模型分别提取音乐数据的音乐embedding以及人声数据的人声embedding。其中,vggish模型是在youtube的audioset数据预训练得到模型,audioset是由google的声音理解团队于2017年3月发布,旨在为音频事件检测提供常见的大规模评估任务,其为由200万个人标记的10秒youtube视频音轨组成的数据集,其标签来自600多个音频事件类的本体。并且,vggish模型支持从wav文件中提取具有语义的128维embedding特征向量。
[0083]
最后,对某个通道(音乐或人声)音频每1秒切分成多段,通过vggish模型提取1个128维embedding,多段音频求平均得到的音频embedding代表该通道的音频embedding。
[0084]
在一种可能的实现方式中,特征信息包括文本特征。那么,获取待检索多媒体的文本特征的流程,可以包括:首先,获取待检索多媒体的文本数据;然后,提取文本数据的文本特征,并将所提取得到的文本特征作为待检索多媒体的文本特征。
[0085]
举例来说,文本数据可以包括标题数据、弹幕数据、评论数据中的一种或多种。本技术实施例中,可以利用词向量模型提取文本数据的文本特征。其中,词向量模型可以包括word2vec模型,word2vec模型可以包括fasttext模型、cbow模型。当然,词向量模型还可以包括bert模型等等。
[0086]
在一种可能的实现方式中,将待检索多媒体的特征信息输入多媒体检索模型进行处理,得到待检索多媒体的多模态特征的流程,可以包括:首先,调用多媒体检索模型的去冗余注意力层对待检索多媒体的特征信息包括的每个单模态特征进行特征规范空间处理,以得到每个单模态特征对应的自融合特征,单模态特征为视频特征、音频特征和文本特征中的任一种。然后,调用多媒体检索模型的卷积层分别对每个单模态特征对应的自融合特征进行卷积堆叠处理,并将卷积堆叠处理后的每个自融合特征进行拼接处理,以确定待检索多媒体的拼接特征。最后,调用多媒体检索模型的融合层对待检索多媒体的拼接特征进行融合提炼处理,得到待检索多媒体的多模态特征。
[0087]
接下来,以任意两个多媒体为例,通过调用多媒体检索模型对任一多媒体进行处理的过程进行详细说明。请参见图5a,图5a是本技术实施例提供的一种多媒体检索模型的结构示意图。如图5a所示,视频特征可以表示为视频embedding、视频特征可以表示为音频embedding,并且音频embedding进一步可以包括音乐embedding和人声embedding,文本特征可以表示为文本embedding。视频、音频、文本三者分别经过各自的输入多媒体检索模型的卷积层提取到相关信息后,通过concat(拼接)操作拼接得到64x3=192维特征向量。然后,经过fusion模块(多媒体检索模型的融合层)对卷积层得到的192维的拼接特征进行融合提炼,最后输出128维的多模态embedding(多模态特征)。针对任意两个多媒体,分别提取得到多模态特征1和多模态特征2,最后根据多模态特征1和多模态特征2经过度量学习得到两个多媒体之间的相似度。其中,fusion模块为多个由relu激活的fc全连层堆叠组成(注意最后一个fc不需要添加relu),如采用2个fc堆叠:fc(64,128)+relu+fc(128,128),输出结果后进行l2norm(normalization,标准化/归一化)得到视频多模态embedding:vem。
[0088]
可见,本技术中的特征信息可以包括多媒体在音频维度、视频维度以及文本维度等多维度的特征,然后通过多媒体检索模型对特征信息的处理,得到的多模态特征可以融合音频维度、视频维度以及文本维度等多维度的特征,因此,相比于单一维度的特征而言,本技术实施例中所确定的多模态特征更加全面和准确。
[0089]
其中,多媒体检索模型再处理多模态特征不同长度的输入特征时,例如上述视频embedding为1024维,音频embedding为128维,维度不同,故在视频embedding、音频embedding、文本embedding分别输入到第一层时,均先压缩到64维,这里压缩维度可以调整(变大变小);各模态的特征处理输入分支这里为3个卷积堆叠,也可以采用fc+relu结构堆叠,一般取2~3层堆叠即可。其中,卷积堆叠处理的流程可以如下表2所示:
[0090]
表2.卷积堆叠处理流程表
[0091]
名称输入/输出维度参数conv111*1024/1*641*1,64conv211*128/1*641*1,64conv311*128/1*641*1,64conv12、131*64/1*641*1,64conv22、231*64/1*641*1,64conv32、331*64/1*641*1,64fc11*192/1*128192*128fc21*128/1*128128*128
[0092]
由上述表1可知,不同维度的输入特征在经过卷积层和全连接层的卷积堆叠处理之后,可以均压缩为同一维度的特征,可以方便后续的融合层的融合提炼处理,最终得到更加准确的多模态特征。
[0093]
需要说明的是,本技术中,在调用多媒体检索模型对所述待检索多媒体和多媒体库包括的每个多媒体进行处理之前,可以预先获取多媒体库包括的每个多媒体的多模态特征。并且,多媒体库中的任一多媒体的多模态特征的确定方式可以参考前述获取待检索多媒体的多模态特征的具体执行过程,本技术在此不做具体限定。当然,也可以是在获取待检索多媒体之前,预先获取多媒体库包括的每个多媒体的多模态特征。
[0094]
在一种可能的实现方式中,调用多媒体检索模型的去冗余注意力层对待检索多媒体的特征信息包括的每个单模态特征进行特征规范空间处理,以得到每个单模态特征对应的自融合特征的流程,可以包括:首先,针对待检索多媒体的特征信息包括的每个单模态特征,获取单模态特征的位置权重向量,并调用去冗余注意力层的压缩层对单模态特征进行维度压缩处理,得到维度压缩后的单模态特征。然后,调用去冗余注意力层的注意力层,利用位置权重向量和维度压缩后的单模态特征,计算位置相关后的单模态特征,并根据维度压缩后的单模态特征所指示的模态维度,对位置相关后的单模态特征进行计算,得到冗余单模态特征。最后,调用去冗余注意力层的去冗余层,对冗余单模态特征规范化处理,得到规范权重向量,并根据规范权重向量对冗余单模态特征进行加权处理,以得到每个单模态特征对应的自融合特征。
[0095]
举例来说,如图5b所示,图5b是本技术实施例提供的另一种多媒体检索模型的结构示意图。同样的,以任意两个多媒体为例,通过调用图5b中所示的多媒体检索模型对任一多媒体进行处理的过程进行详细说明。其中,针对任意两个多媒体,如多媒体1和多媒体2来说,分别抽取多媒体1和多媒体2再音频模态下的数据,从而得到音频1和音频2。在一种可能的实现方式中,在将音频1和音频2输入至于vggish模型之前,还可以分别对音频1和音频2进行音乐增强处理,其中,音乐增强处理可以包括但不限于:变速、变调、增大降低音量,在原音频上增加攻击,譬如加入掌声、其他场外声等处理方式。最后,通过vggish模型分别对音乐增强处理后的音频1和音频2进行音频特征的提前,以分别得到音频特征1和音频特征2。
[0096]
需要说明的是,本技术实施例中,对于单模态特征进行规范空间处理,其目的是学习conv21、22、23(以图5b的例子来说)组成的由单模态上游任务(指提取预训练好的该模态信息的模型训练时的任务,如音频模态)到单模态规范空间映射的方式。图5b对音频模态,学习一个从音频模态到目标模态的信息,在该模态下的训练方法与下面相似度训练方法一致,对于该模态下相似的样本,学习目标标签1,不相似样本目标标签0。
[0097]
具体来说,图5b中的特征空间去冗余的注意力模态(即去冗余注意力层)需要学习一个位置相关权重向量ws(64x64)。该位置相关权重向量ws中的(i,j)位的值代表每个位i与位j的相关关系。其中,位置相关权重向量ws可以参见表3所示:
[0098]
表3.位置相关权重向量
[0099]
layernameinput/outputsizeparametersattention-mat1x64/1x6464x64矩阵
[0100]
为了方便描述,接下来以多媒体检索模型对音频1进行处理的详细流程进行阐述说明。首先,对模态特征(如图5b中的音频特征1)压缩到64维(conv21),得到压缩后的音频特征1(可表示为f1)。然后,在conv22中,对输入的1x64特征f1:
[0101]
1)计算位置相关后的特征:进行矩阵相乘f1*ws,得到自相关向量vr:1x64;
[0102]
2)计算负自相关向量64-vr得到冗余向量(相关最大值为1,最小为0,当64位全部相互冗余,则冗余达到最大值64);
[0103]
3)对冗余向量规范化(即向量每个位置的值除以向量的和,得到1x64的权重)。
[0104]
最后,conv22中,在以权重对conv22的输出结果(1x64)进行加权(第i位置的权重乘以第i位置原始输出得到最终去冗余attention后的i位置输出)后即可得到音频特征1对
应的自融合特征1。
[0105]
同理,对于音频2来说,如何根据音频特征2得到对应的自融合特征2,也可参考上述通过多媒体检索模型“根据音频特征1得到对应的自融合特征1”的处理流程,本技术实施例在此不再赘述。
[0106]
例如,对于由4个特征位[1,1,1,1]产生的特征经过ws相关矩阵:
[0107]
可以知道,维度1与23相关、维度2与14相关、维度31相关,维度42相关。然后可以计算得到位置相关后向量为[3,3,2,2],进而计算得到负相关向量[1,1,2,2]。接下来,对负相关向量[1,1,2,2]进行规范化(即除以1+1+2+2=6)得到attention权重(规范权重向量):[1/6,1/6,1/3,1/3]。该规范权重向量可以表示每个特征位代表多少份该模态空间的某些位融合信息。如维度1与23相似,则该位仅表示了该位1/6份信息。
[0108]
综上所述,本技术实施例中,通过去冗余注意力层进行相关attention去冗余后,可以把各维度的排重信息压缩到维度相同的规范空间中并均衡表达,这样每个模态的规范空间可以代表排重特征在该模态上的分布,这个分布在融合后可以均衡地产生对多媒体更完整的描述,即多模态特征。在对多媒体的各个模态下的特征(单模态特征,视频特征、音频特征、文本特征中的任一种),应用中也可以通过单模态或者任意参与训练的多模态组合就可以检索到具有模糊相似关系的类似重复视频,而不需要所有模态都具备,因为现实中本来就有一定量的视频文本或者音频缺失的,所以这里也可以应用。
[0109]
另外,基于位置自相关attention去冗余对比其他self-attention(不学习64x64的相关矩阵,而是直接特征自己相乘采用特征自相关64x64并求向量某一维度的和的到1x64的相关向量,替代位置attention中1x64相关向量),self-attention实际上是增强自身信息,但并不能知道哪些特征位之间有相关。然而当某个样本在某几个特征位预测都比较大,并不代表这几个位所代表的信息在所有样本中都是相关的,如某张草坪与狗的图像,在三个特征位置预测比较强,这三个特征位可能一个是草坪、一个是狗头、一个是狗尾,这时候实际相关只有2个位,而不是三个。在位置attention去冗余上是可以通过全部样本学习的64x64相关矩阵找到狗头狗尾的强相关、狗头和草坪的弱相关(相比起狗头狗尾的共现、狗头草坪共现的概率低很多,也就相关性低很多)。从而在规范空间里每个信息都公平打分。而self-attention实际上产生的是不公平的打分(如三个特征共现则三者自相关变大,增强了三者信息,而实际上狗头狗尾相关性强,只能提供1份(或1+x,x为0~1之间)信息,而非2份)。因此,本技术实施例中通过多媒体检索模型的去冗余注意力层对待检索多媒体的特征信息包括的每个单模态特征进行特征规范空间处理,可以有效提高各模态early fusion特征(自融合特征)表达。
[0110]
进一步地,请参见图5c,图5c是本技术实施例提供的另一种多媒体检索模型的结构示意图。本技术实施例中,在基于图5b所设计的多媒体检索模型中的去冗余attention作为early fusion(提前融合)是为了增强多媒体的各个模态特征之间的权重均衡性。然后,基于待检索多媒体的多模态特征来说,即可将待检索多媒体在各个模态下的特征同时输入至图5c所示的多媒体检索模型,通过对提前融合后得到的各个模态下的自融合特征之后,
再对各个模态下的自融合特征进行融合提炼处理,最终得到待检索多媒体的多模态特征。
[0111]
多模态特征因为有前文说的维度不一致、不同特征度量空间差异,现有方法直接把各模态concat的方式,不做early fusion,又或者在输入时直接embedding相乘得embedding自相关后拉成一维向量(即1x128的音频特征变成128x128相关后,reshape称1x16384维特征)就全部特征concat、产生video embedding(late-fusion)。这里做模态空间的统一规范化,通过特征交叉对特征冗余信息识别并做去冗余的加权,可以使得在规范化空间中可以对样本进行加权。使得输出的embedding值重新调整,从而最后对于不同度量空间差异、不同的冗余信息,可以在规范空间中产生均衡的作用(冗余越多的位,权重变小,如最后64维特征中对于32位冗余位,起都分别加权1/2)。
[0112]
s230:根据每个目标多媒体与所述待检索多媒体之间的相似度的排序,确定待检索多媒体的检索结果。
[0113]
本技术实施例中,如图5a所示,基于以上分析,调用多媒体检索模型对待检索多媒体和多媒体库中的各个多媒体进行处理之后,可以得到待检索多媒体与多媒体库中的各个多媒体之间的相似度。然后,将相似度大于或者等于相似度阈值的多媒体确定为目标多媒体,其中,所确定的目标多媒体的数量可以为一个,也可以为多个,本技术对此不做具体限定。
[0114]
其中,确定相似度阈值的方式可以为预先获取一个经验阈值,也可以为根据样本数据集中的样本对来计算相似度阈值。其中,根据样本数据集确定相似度阈值的方式可以包括:分别计算样本数据集中的每个样本对的相似度,然后从0~1每0.01为步长搜索阈值(0.01~0.99),每次搜索都以该阈值为判决门限(大于阈值表示相似,小于表示不相似),并基于搜索结果计算f1。最后,获取使f1最大的阈值thr作为应用中的相似度阈值。其中,计算f1可以参见如下公式(1)所示:
[0115][0116]
其中,公式(1)中,p是指precision,称为精确率/查准率,r是指recall,称为召回率/查全率。f1的值就是精确率和召回率之间的调和均值。
[0117]
在一种可能的实现方式中,可以将得到的目标多媒体按照相似度由高到低进行排序,然后将排序后的一个或多个目标多媒体作为待检索多媒体的检索结果,并输出检索结果给用户。
[0118]
本技术实施例中,在获取到待检索多媒体之后,可以调用多媒体检索模型对待检索多媒体和多媒体库包括的每个多媒体进行处理,得到多媒体库中与待检索多媒体相似的一个或多个目标多媒体,其中,多媒体检索模型是利用训练数据集包括的多个样本多媒体的多模态特征训练得到的,并且多模态特征是根据视频特征、音频特征和文本特征的一种或多种得到的;然后,根据每个目标多媒体与待检索多媒体之间的相似度的排序,确定待检索多媒体的检索结果。可见,本技术实施例中,用于检索待检索多媒体的多媒体检索模型是利用多个样本多媒体的多模态特征训练后得到的,首先,提前对样本多媒体的视频特征、音频特征和文本特征的一种或多种分别进行特征规范空间处理,从而确定了对应的自融合特征,进一步地,根据一种或多种自融合特征再融合处理后得到样本多媒体的多模态特征。因此,本技术中的多模态特征在对各模态特征进行拼接融合之前,还会预先对各模态特征分
别进行自融合处理得到对应的自融合特征,相比于直接对各模态特征进行拼接融合,本技术可以将各模态的特征维度压缩到相同的特征维度,使得各模态特征能够均衡分布;并且规范各模态的特征空间,因此,本技术所确定的多模态特征更加准确。进一步地,基于更加准确的待检索多媒体的多模态特征进行多媒体检索时,也可以检索得到更加准确的目标多媒体,进而提高多媒体检索的准确性。
[0119]
基于以上分析,本技术实施例通过调用多媒体检索模型进行多媒体检索,可以得到更加准确的检索结果。接下来,对如何训练得到多媒体检索模型进行详细说明。请参见图6,图6是本技术实施例提供的一种训练多媒体检索模型的流程示意图。其中,该模型训练方法可以由计算机设备执行,计算机设备可以为终端设备,计算机设备也可以包括终端设备和服务器。如图6所示,该模型训练方法可包括步骤s610~s630。其中:
[0120]
s610:获取训练数据集,训练数据集包括多个样本对以及每个样本对的样本标签,多个样本对包括模态完整样本对和模态缺失样本对,样本标签用于指示每个样本对包括的第一样本多媒体和第二样本多媒体在各个单模态特征之间的相似性。
[0121]
本技术实施例中,用于模型训练的训练数据集可以包括m个样本对,m为正整数,并且,多个样本对包括模态完整样本对和模态缺失样本对,每个样本对包括第一样本多媒体和第二样本多媒体,以及每个样本对携带的样本标签用于指示第一样本多媒体和第二样本多媒体在各个单模态特征是否为相似多媒体。并且,每个样本对中的第一样本多媒体和第二样本多媒体所包括的模态特征的数量相同。例如,某样本对中的第一样本多媒体包括3个单模态特征(视频特征、音频特以及文本特征),那么,该样本对中的第二样本多媒体同样包括视频特征、音频特以及文本特征这三个单模态特征。并且,还可以同时标注每个样本对中的第一样本多媒体和第二样本多媒体分别在各个单模态特征之间的相似性。第一样本多媒体与第二样本多媒体在视频特征之间相似,则标注为1;第一样本多媒体与第二样本多媒体在音频特征之间不相似,则标注为0。最终,第一样本多媒体与第二样本多媒体之间的样本标签,可以根据第一样本多媒体与第二样本多媒体在各个单模态特征之间的相似性来确定:若第一样本多媒体与第二样本多媒体在视频特征、音频特以及文本特征均相似,则样本标签可以1;若第一样本多媒体与第二样本多媒体在视频特征、音频特以及文本特征均不相似,则样本标签可以为0。若第一样本多媒体与第二样本多媒体在视频特征、音频特相似,在文本特征不相似,则样本标签可以2/3。并且,在获取到训练数据集之后,可以预先提取样本库中每个样本多媒体的特征信息,特征信息包括视频特征、音频特征、文本特征中的一种或多种。
[0122]
接下来,针对如何准备每个batch(即一次迭代所使用的样本量)的样本进行详细阐述:
[0123]
(a)模态完整样本对:对于上述训练数据集中所标注的样本对,抽取模态信息完整下的样本对作为完全样本,例如本技术中,可以将具包括视频特征、音频特征以及文本特征的多媒体作为模态完整样本。
[0124]
(b)模态缺失样本:对于所有标注的视频对,若出现模态缺失,此类样本在某一模态下信息是缺乏对;另外由于应用中也常会出现模态缺失的问题,为了提升模态缺失的空间表征以及模态间相互检索能力,需要对模态缺失进行兼容性学习。样本准备上,对于每个batch的pair对,当模态完整时,产生两个缺失模态pair对(故对于bs个样本对的batch,总
共有bs~3*bs个样本对需要学习),产生缺失模态pair对的方式是随机选择1~k-1个输入模态信息丢弃(假设一共有k个模态,对于图5a共有3个模态,则k-1=2,随机丢弃1个或2个模态)。对于缺失模态,若原始视频标签为1:则其相似度标签从1变化为0.33或0.67(丢弃2个模态、丢弃1个模态表示缺失了0.67或0.33的相似度信息r,仅剩下1-r的统一空间相似度);若原始标签为0:缺失模态标签依然为0。学习中缺失模态损失计算与完整模态相同,不同的是缺失部分模态输入为0,缺失模态标签变化。
[0125]
本技术实施例中,缺失模态的增强学习目标是保证当有模态缺失时,相似度度量需要更公正。对比现有的方法一,不处理缺失模态,容易产生两个单模态相似、多模态是否相似未知的视频(因为缺失,真正状态未知的)也会产生预测为1的强相似信息,然而实际上应该是在多模态环境下的模糊相似,本方法能提供1个单模态相似的弱相似程度,即1/3(对于3个模态)相似,更接近多模态意义上的相似度预测效果。从特征空间衡量,则是各独立模态都提供了全量模态空间的一个子空间,只有所有子空间都相似,才能产生多模态的整体统一空间相似。
[0126]
s620:利用模态缺失样本对包括的第一样本多媒体的单模态特征和第二样本多媒体的单模态特征对第一神经网络模型进行单模态训练,得到第二神经网络模型,单模态特征为视频特征、音频特征和文本特征中的任一种。
[0127]
在一种可能的实现方式中,神经网络模型可以是初始的神经网络模型,神经网络模型也可以是预训练处理后的神经网络模型,本技术在此不做具体限定。例如,神经网络模型可以为rnn模型、lstm模型等等。
[0128]
在一种可能的实现方式中,计算机设备利用模态缺失样本对包括的第一样本多媒体的单模态特征和第二样本多媒体的单模态特征对第一神经网络模型进行单模态训练,得到第二神经网络模型的流程,可以包括:
[0129]
首先,调用第一神经网络模型对模态缺失样本对包括的第一样本多媒体的单模态特征进行特征规范空间处理,以得到第一样本多媒体的单模态特征对应的自融合特征,同时,调用第一神经网络模型对所述模态缺失样本对包括的第二样本多媒体的单模态特征进行特征规范空间处理,以得到第二样本多媒体的单模态特征对应的自融合特征;
[0130]
然后,根据第一样本多媒体的单模态特征对应的自融合特征、第二样本多媒体的单模态特征对应的自融合特征、以及模态缺失样本对的样本标签,调整第一神经网络模型的模型参数,并将模型参数调整后的第一神经网络模型作为第二神经网络模型。其中,调整第一神经网络模型的模型参数可以具体包括:通过模态缺失样本对包括的第一样本多媒体和第二样本多媒体之间的相似度,以及模态缺失样本对的样本标签之间的差异,计算第一神经网络模型的模型损失;然后,根据第一神经网络模型的模型损失,更新第一神经网络模型的模型参数;最后,当第一神经网络模型满足模型收敛条件时,将模型参数更新后的第一神经网络模型作为第二神经网络模型。
[0131]
具体实现时,可以通过调用第一神经网络模型对第一样本多媒体的单模态特征对应的自融合特征以及第二样本多媒体的单模态特征对应的自融合特征进行相似度计算,从而得到模态缺失样本对包括的第一样本多媒体和第二样本多媒体之间的相似度。进而,通过模态缺失样本对包括的第一样本多媒体和第二样本多媒体之间的相似度,以及模态缺失样本对的样本标签之间的差异,调整第一神经网络模型的模型参数,并将模型参数调整后
的第一神经网络模型作为第二神经网络模型。
[0132]
具体实现时,计算机设备调用神经网络模型对每个样本对包括的第一样本多媒体的特征信息和第二样本多媒体的特征信息进行处理,以得到第一样本多媒体与第二样本多媒体之间的相似度的具体流程,可以包括:首先,将每个样本对包括的第一样本多媒体的特征信息和第二样本多媒体的特征信息输入神经网络模型进行处理,分别得到第一样本多媒体的多模态特征和第二样本多媒体的多模态特征。然后,调用神经网络模型对第一样本多媒体的多模态特征和第二样本多媒体的多模态特征进行处理,得到第一样本多媒体与第二样本多媒体之间的相似度。
[0133]
举例来说,如图7所示,图7是本技术实施例提供的一种神经网络模型确定相似度的结构示意图。如图7所示,第一样本多媒体的特征信息可以包括:视频特征m1、音乐特征m2、人声特征m3、标题特征m4,同样的,第二样本多媒体的特征信息也可以包括:视频特征n1、音乐特征n2、人声特征n3、标题特征n4。然后,调用神经网络模型对第一样本多媒体的特征信息进行处理,得到第一样本多媒体的多模态特征的过程可以包括:调用神经网络模型的卷积层分别对第一样本多媒体的视频特征m1、音乐特征m2、人声特征m3、标题特征m4进行卷积堆叠处理,并将卷积堆叠处理后的视频特征m1、音乐特征m2、人声特征m3、标题特征m4进行拼接处理,以确定第一样本多媒体的拼接特征。并调用神经网络模型的融合层对第一样本多媒体的拼接特征进行融合提炼处理,得到第一样本多媒体的多模态特征(可以表示为多模态特征1)。同理,调用神经网络模型对第二样本多媒体的特征信息进行处理,得到第二样本多媒体的多模态特征的过程与上述类似,第二样本多媒体的多模态特征(可以表示为多模态特征2)。最后,通过神经网络模型对多模态特征1和多模态特征2进行处理,即可得到第一样本多媒体与第二样本多媒体之间的相似度。
[0134]
s630:利用模态完整样本对包括的第一样本多媒体的特征信息和第二样本多媒体的特征信息对第二神经网络模型进行联合模态训练,得到多媒体检索模型,特征信息包括视频特征、音频特征和文本特征的一种或多种。
[0135]
在一种可能的实现方式中,计算机设备利用模态完整样本对包括的第一样本多媒体的特征信息和第二样本多媒体的特征信息对第二神经网络模型进行联合模态训练,得到多媒体检索模型的流程,可以包括:
[0136]
调用第二神经网络模型对模态完整样本对包括的第一样本多媒体的各个单模态特征分别进行特征规范空间处理,得到模态完整样本对包括的第一样本多媒体的每个单模态特征对应的自融合特征,以及对模态完整样本对包括的每个自融合特征进行融合处理,得到第一样本多媒体的多模态特征。
[0137]
同时,调用第二神经网络模型对模态完整样本对包括的第二样本多媒体的各个单模态特征分别进行特征规范空间处理,得到模态完整样本对包括的第二样本多媒体的每个单模态特征对应的自融合特征,以及对模态完整样本对包括的每个自融合特征进行融合处理,得到第二样本多媒体的多模态特征。
[0138]
最后,根据第一样本多媒体的多模态特征、第二样本多媒体的多模态特征、以及模态完整样本对的样本标签,调整第二神经网络模型的模型参数,并将模型参数调整后的第二神经网络模型作为多媒体检索模型。
[0139]
具体实现时,可以通过调用第二神经网络模型对第一样本多媒体的多模态以及第
二样本多媒体的多模态特征进行相似度计算,从而得到模态完整样本对包括的第一样本多媒体和第二样本多媒体之间的相似度。进而,通过模态完整样本对包括的第一样本多媒体和第二样本多媒体之间的相似度,以及模态完整样本对的样本标签之间的差异,调整第二神经网络模型的模型参数,并将模型参数调整后的第二神经网络模型作为多媒体检索模型。
[0140]
其中,调整第二神经网络模型的模型参数可以具体包括:通过模态完整样本对包括的第一样本多媒体和第二样本多媒体之间的相似度,以及模态完整样本对的样本标签之间的差异,计算第二神经网络模型的模型损失;然后,根据第二神经网络模型的模型损失,更新第二神经网络模型的模型参数;最后,当第二神经网络模型满足模型收敛条件时,将模型参数更新后的第二神经网络模型作为多媒体检索模型。
[0141]
其中,所谓模型收敛条件可以是指:当神经网络模型的训练次数达到预设训练阈值时,例如100次,则可以认为神经网络模型满足模型收敛条件,即将训练100次后的神经网络模型作为多媒体检索模型。当模型预测的相似度和样本标签之间的差异数据小于误差阈值时,则可以认为神经网络模型满足模型收敛条件。当神经网络模型相邻两次训练得到的相似度之间的变化小于变化阈值时,则可以认为神经网络模型满足模型收敛条件。
[0142]
具体实现时,在模型训练的过程中,假设共有m个样本对,每bs(batch_size:1次迭代所使用的样本量)个样本对为一个批次,共m/bs个批次,每1个批次进行模型前向计算并参数更新,当完成了全量m/bs次更新后,即代表完成一个epoch(1个epoch表示过了1遍训练数据集中的所有样本)。因此,可以共进行k个epoch训练(或当连续10个epoch的平均loss没有下降,即可停止模型训练)。
[0143]
另外,在计算模型损失的过程中,把模型的所有模型参数都设为需要学习状态,训练时神经网络模型对输入的样本对的embedding特征进行前向计算得到预测结果多模态特征1(可表示为vem i)和多模态特征2(可表示vemj)。计算cosine-similarity(余弦相似度),对比相似度与标签的差异,得到loss(模型损失)。其中,当第一样本多媒体和第二样本多媒体相似时,模型损失的计算公式如公式(2)所示:
[0144]
loss=1-vemi
t
*vemj
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0145]
当第一样本多媒体和第二样本多媒体不相似时,模型损失的计算公式如公式(3)所示:
[0146]
loss=vemi
t
*vemj
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0147]
其中,公式(2)和公式(3)中,vemi
t
*vemj就是指cosine-similarity(余弦相似度),即第一样本多媒体和第二样本多媒体之间的相似度。
[0148]
最后,在模型参数更新的过程中,可以采用loss进行梯度后向计算得到全部模型参数的更新值,并更新神经网络模型。在更新模型参数的过程中,可以采用0.005的学习率,每轮学习由loss回传得到梯度后,根据学习率更新网络权重。当然,在训练神经网络模型的过程中,除了可以调整模型参数,还可以调整模型的网络深度等等。
[0149]
需要说明的是,本技术实施例中,可以先基于模态缺失样本对包括的第一样本多媒体的单模态特征和第二样本多媒体的单模态特征对第一神经网络模型进行单模态训练,得到第二神经网络模型之后,再基于模态完整样本对包括的第一样本多媒体的特征信息和第二样本多媒体的特征信息对第二神经网络模型进行联合模态训练,得到多媒体检索模
型。通过这种方式,首先基于单模态特征的规范空间对神经网络模型进行初步训练后,将样本多媒体的不同维度的特征映射到规范空间内,再通过多模态规范空间的融合联合学习产生目标多模态空间的联合表征效果,即本技术实施例通过预先学习与联合学习方式进行模型训练,从而提升模态缺失情况下的相似度空间表征效果,从而可以使得训练后得到的多媒体检索模型更加准确。
[0150]
本技术实施例中,将训练好的神经网络模型作为多媒体检索模型之后,可以应用于多媒体相似度检索、多媒体侵权检索等领域。接下来,对训练后得到的多媒体检索模型的应用进行详细阐述:
[0151]
(1)针对完全模态检索应用:对于具备全部模态的两个视频检索可以按上述方法进行相似度判断。例如,在多媒体相似度检索应用中,通过调用多媒体检索模型对用户输入的query视频(待检索视频)进行识别,然后可以得到多媒体库中与待检索视频相似的一个或多个目标视频。然后,根据每个目标多媒体与待检索多媒体之间的相似度,进行相似度排序,可以按照相似度由高到低的排列顺序确定待检索多媒体的检索结果。
[0152]
(2)针对不完全模态检索:对于缺失模态检索,可以使缺失的模态输入全0,通过统一的多模态空间产生缺失相似度(如缺失1份模态信息,则最多只有2/3相似度)。可以通过这种方式从单一模态召回多模态(或任何模态组合)空间中的模糊相似视频。由于做了单模态信息的内部均衡(自相关)以及外部均衡(统一模态表征维度、缺失模态学习)、故单一模态检索召回后,两个视频的多模态相似度具备模态上的相似程度表达,如果输入query是双模态,则不同模态相似的视频可以产生0、1/3、2/3相似的效果。
[0153]
其中,缺失模态的学习对于两个相似视频的预测结果具有相似模态程度表征效果。而如果不区分模态对所有样本只学习0、1,是无法知道有多少模态相似的信息的,即不具备联合模态上相似程度表征。相似性程度表征的一个作用是可以对召回的视频根据模型similarity(相似度)得分进行结果的排序。得分越高越相似。
[0154]
综上所述,基于相似度检索得到的一个或多个目标视频,在多媒体侵权检索应用中,可以从一个或多个目标视频中,确定出与待检索视频之间构成侵权的侵权视频。后续,基于侵权视频做进一步的维权处理等。
[0155]
请参见图8,图8是本技术实施例提供的一种多媒体检索装置的结构示意图。该多媒体检索装置800可应用于图2和图6对应的方法实施例中的计算机设备。多媒体检索装置800可以是运行于轻量节点中的一个计算机程序(包括程序代码),例如该多媒体检索装置800为一个应用软件;该装置可以用于执行本技术实施例提供的方法中的相应步骤。该多媒体检索装置800可包括:
[0156]
获取单元801,用于获取待检索多媒体;
[0157]
处理单元802,用于调用多媒体检索模型对所述待检索多媒体和多媒体库包括的每个多媒体进行处理,得到所述多媒体库中与所述待检索多媒体相似的一个或多个目标多媒体,其中,所述多媒体检索模型是利用训练数据集包括的样本多媒体的多模态特征训练得到的,所述多模态特征是在对所述样本多媒体的视频特征、音频特征和文本特征的一种或多种分别进行特征规范空间处理得到对应的自融合特征之后,对一种或多种自融合特征进行融合处理得到的,所述一种或多种自融合特征的特征维度相同;
[0158]
确定单元803,用于根据每个目标多媒体与所述待检索多媒体之间的相似度的排
序,确定所述待检索多媒体的检索结果。
[0159]
在一种可能的实现方式中,处理单元802调用多媒体检索模型对所述待检索多媒体和多媒体库包括的每个多媒体进行处理,得到所述多媒体库中与所述待检索多媒体相似的一个或多个目标多媒体,包括:
[0160]
获取所述待检索多媒体的特征信息,所述特征信息包括视频特征、音频特征和文本特征的一种或多种;
[0161]
将所述待检索多媒体的特征信息输入多媒体检索模型进行处理,得到所述待检索多媒体的多模态特征;
[0162]
调用所述多媒体检索模型对所述待检索多媒体的多模态特征以及所述多媒体库包括的每个多媒体的多模态特征进行处理,得到所述多媒体库中与所述待检索多媒体相似的一个或多个目标多媒体。
[0163]
在一种可能的实现方式中,特征信息包括视频特征,获取单元801获取所述待检索多媒体的特征信息,包括:
[0164]
获取所述待检索多媒体的视频数据;
[0165]
对所述视频数据进行分镜处理,得到分镜处理后的多个分镜视频;
[0166]
根据所述多个分镜视频确定所述视频数据对应的多个视频片段;
[0167]
分别确定所述多个视频片段中每个视频片段的视频特征,并根据所述每个视频片段的视频特征,确定所述待检索多媒体的视频特征。
[0168]
在一种可能的实现方式中,特征信息还包括音频特征,获取单元801还用于执行以下操作:
[0169]
获取所述待检索多媒体的音频数据;
[0170]
对所述音频数据进行分离处理,得到音乐数据和人声数据;
[0171]
确定所述音乐数据对应的音乐特征,以及确定所述人声数据对应的人声特征;
[0172]
将所述音乐特征和所述人声特征作为所述待检索多媒体的音频特征。
[0173]
在一种可能的实现方式中,处理单元802将所述待检索多媒体的特征信息输入多媒体检索模型进行处理,得到所述待检索多媒体的多模态特征,包括:
[0174]
调用多媒体检索模型的去冗余注意力层对所述待检索多媒体的特征信息包括的每个单模态特征进行特征规范空间处理,以得到所述每个单模态特征对应的自融合特征,所述单模态特征为所述视频特征、所述音频特征和所述文本特征中的任一种;
[0175]
调用所述多媒体检索模型的卷积层分别对所述每个单模态特征对应的自融合特征进行卷积堆叠处理,并将卷积堆叠处理后的每个自融合特征进行拼接处理,以确定所述待检索多媒体的拼接特征;
[0176]
调用所述多媒体检索模型的融合层对所述待检索多媒体的拼接特征进行融合提炼处理,得到所述待检索多媒体的多模态特征。
[0177]
在一种可能的实现方式中,处理单元802调用多媒体检索模型的去冗余注意力层对所述待检索多媒体的特征信息包括的每个单模态特征进行特征规范空间处理,以得到所述每个单模态特征对应的自融合特征,包括:
[0178]
针对所述待检索多媒体的特征信息包括的每个单模态特征,获取所述单模态特征的位置权重向量,并调用所述去冗余注意力层的压缩层对所述单模态特征进行维度压缩处
理,得到维度压缩后的单模态特征;
[0179]
调用所述去冗余注意力层的注意力层,利用所述位置权重向量和所述维度压缩后的单模态特征,计算位置相关后的单模态特征,并根据所述维度压缩后的单模态特征所指示的模态维度,对所述位置相关后的单模态特征进行计算,得到冗余单模态特征;
[0180]
调用所述去冗余注意力层的去冗余层,对所述冗余单模态特征规范化处理,得到规范权重向量,并根据所述规范权重向量对所述冗余单模态特征进行加权处理,以得到所述每个单模态特征对应的自融合特征。
[0181]
在一种可能的实现方式中,处理单元802调用多媒体检索模型对所述待检索多媒体和多媒体库包括的每个多媒体进行处理,得到所述多媒体库中与所述待检索多媒体相似的一个或多个目标多媒体之前,所述方法还包括:
[0182]
获取训练数据集,所述训练数据集包括多个样本对以及每个样本对的样本标签,所述多个样本对包括模态完整样本对和模态缺失样本对,所述样本标签用于指示所述每个样本对包括的第一样本多媒体和第二样本多媒体在各个单模态特征之间的相似性;
[0183]
利用所述模态缺失样本对包括的第一样本多媒体的单模态特征和第二样本多媒体的单模态特征对第一神经网络模型进行单模态训练,得到第二神经网络模型,所述单模态特征为视频特征、音频特征和文本特征中的任一种;
[0184]
利用所述模态完整样本对包括的第一样本多媒体的特征信息和第二样本多媒体的特征信息对所述第二神经网络模型进行联合模态训练,得到多媒体检索模型,所述特征信息包括视频特征、音频特征和文本特征的一种或多种。
[0185]
在一种可能的实现方式中,处理单元802利用所述模态缺失样本对包括的第一样本多媒体的单模态特征和第二样本多媒体的单模态特征对第一神经网络模型进行单模态训练,得到第二神经网络模型,包括:
[0186]
调用第一神经网络模型对所述模态缺失样本对包括的第一样本多媒体的单模态特征进行特征规范空间处理,以得到所述第一样本多媒体的单模态特征对应的自融合特征;
[0187]
调用第一神经网络模型对所述模态缺失样本对包括的第二样本多媒体的单模态特征进行特征规范空间处理,以得到所述第二样本多媒体的单模态特征对应的自融合特征;
[0188]
根据所述第一样本多媒体的单模态特征对应的自融合特征、所述第二样本多媒体的单模态特征对应的自融合特征、以及所述模态缺失样本对的样本标签,调整所述第一神经网络模型的模型参数,并将模型参数调整后的第一神经网络模型作为第二神经网络模型。
[0189]
在一种可能的实现方式中,处理单元802利用所述模态完整样本对包括的第一样本多媒体的特征信息和第二样本多媒体的特征信息对所述第二神经网络模型进行联合模态训练,得到多媒体检索模型,包括:
[0190]
调用所述第二神经网络模型对所述模态完整样本对包括的第一样本多媒体的各个单模态特征分别进行特征规范空间处理,得到所述模态完整样本对包括的第一样本多媒体的每个单模态特征对应的自融合特征,以及对所述模态完整样本对包括的每个自融合特征进行融合处理,得到所述第一样本多媒体的多模态特征;
[0191]
调用所述第二神经网络模型对所述模态完整样本对包括的第二样本多媒体的各个单模态特征分别进行特征规范空间处理,得到所述模态完整样本对包括的第二样本多媒体的每个单模态特征对应的自融合特征,以及对所述模态完整样本对包括的每个自融合特征进行融合处理,得到所述第二样本多媒体的多模态特征;
[0192]
根据所述第一样本多媒体的多模态特征、所述第二样本多媒体的多模态特征、以及所述模态完整样本对的样本标签,调整所述第二神经网络模型的模型参数,并将模型参数调整后的第二神经网络模型作为多媒体检索模型。
[0193]
在一种可能的实现方式中,处理单元802根据所述第一样本多媒体与所述第二样本多媒体之间的相似度以及对应的样本标签,对所述神经网络模型进行训练,得到所述多媒体检索模型,包括:
[0194]
根据所述第一样本多媒体和所述第二样本多媒体之间的相似度以及对应的样本标签,计算所述神经网络模型的模型损失;
[0195]
根据所述神经网络模型的模型损失,更新所述神经网络模型的模型参数;
[0196]
当所述神经网络模型满足模型收敛条件时,将模型参数更新后的神经网络模型作为多媒体检索模型。
[0197]
通过本技术实施例,在获取到待检索多媒体之后,可以调用多媒体检索模型对待检索多媒体和多媒体库包括的每个多媒体进行处理,得到多媒体库中与待检索多媒体相似的一个或多个目标多媒体,其中,多媒体检索模型是利用训练数据集包括的多个样本多媒体的多模态特征训练得到的,并且多模态特征是根据视频特征、音频特征和文本特征的一种或多种得到的;然后,根据每个目标多媒体与待检索多媒体之间的相似度的排序,确定待检索多媒体的检索结果。可见,本技术实施例中,用于检索待检索多媒体的多媒体检索模型是利用多个样本多媒体的多模态特征训练后得到的,首先,提前对样本多媒体的视频特征、音频特征和文本特征的一种或多种分别进行特征规范空间处理,从而确定了对应的自融合特征,进一步地,根据一种或多种自融合特征再融合处理后得到样本多媒体的多模态特征。因此,本技术中的多模态特征在对各模态特征进行拼接融合之前,还会预先对各模态特征分别进行自融合处理得到对应的自融合特征,相比于直接对各模态特征进行拼接融合,本技术可以将各模态的特征维度压缩到相同的特征维度,使得各模态特征能够均衡分布;并且规范各模态的特征空间,因此,本技术所确定的多模态特征更加准确。进一步地,基于更加准确的待检索多媒体的多模态特征进行多媒体检索时,也可以检索得到更加准确的目标多媒体,进而提高多媒体检索的准确性。
[0198]
请参见图9,图9是本技术实施例提供的一种计算机设备的结构示意图。该计算机设备900用于执行图2和图6对应的方法实施例中计算机设备所执行的步骤,该计算机设备900包括:一个或多个处理器910;一个或多个输入设备920,一个或多个输出设备930和存储器940。上述处理器910、输入设备920、输出设备930和存储器940通过总线950连接。存储器940用于存储计算机程序,所述计算机程序包括程序指令,处理器910用于调用存储器940存储的程序指令,执行以下操作:
[0199]
获取待检索多媒体;
[0200]
调用多媒体检索模型对所述待检索多媒体和多媒体库包括的每个多媒体进行处理,得到所述多媒体库中与所述待检索多媒体相似的一个或多个目标多媒体,其中,所述多
媒体检索模型是利用训练数据集包括的样本多媒体的多模态特征训练得到的,所述多模态特征是在对所述样本多媒体的视频特征、音频特征和文本特征的一种或多种分别进行特征规范空间处理得到对应的自融合特征之后,对一种或多种自融合特征进行融合处理得到的,所述一种或多种自融合特征的特征维度相同;
[0201]
根据每个目标多媒体与所述待检索多媒体之间的相似度的排序,确定所述待检索多媒体的检索结果。
[0202]
在一种可能的实现方式中,处理器910调用多媒体检索模型对所述待检索多媒体和多媒体库包括的每个多媒体进行处理,得到所述多媒体库中与所述待检索多媒体相似的一个或多个目标多媒体,包括:
[0203]
获取所述待检索多媒体的特征信息,所述特征信息包括视频特征、音频特征和文本特征的一种或多种;
[0204]
将所述待检索多媒体的特征信息输入多媒体检索模型进行处理,得到所述待检索多媒体的多模态特征;
[0205]
调用所述多媒体检索模型对所述待检索多媒体的多模态特征以及所述多媒体库包括的每个多媒体的多模态特征进行处理,得到所述多媒体库中与所述待检索多媒体相似的一个或多个目标多媒体。
[0206]
在一种可能的实现方式中,特征信息包括视频特征,处理器910获取所述待检索多媒体的特征信息,包括:
[0207]
获取所述待检索多媒体的视频数据;
[0208]
对所述视频数据进行分镜处理,得到分镜处理后的多个分镜视频;
[0209]
根据所述多个分镜视频确定所述视频数据对应的多个视频片段;
[0210]
分别确定所述多个视频片段中每个视频片段的视频特征,并根据所述每个视频片段的视频特征,确定所述待检索多媒体的视频特征。
[0211]
在一种可能的实现方式中,特征信息还包括音频特征,处理器910还用于执行以下操作:
[0212]
获取所述待检索多媒体的音频数据;
[0213]
对所述音频数据进行分离处理,得到音乐数据和人声数据;
[0214]
确定所述音乐数据对应的音乐特征,以及确定所述人声数据对应的人声特征;
[0215]
将所述音乐特征和所述人声特征作为所述待检索多媒体的音频特征。
[0216]
在一种可能的实现方式中,处理器910将所述待检索多媒体的特征信息输入多媒体检索模型进行处理,得到所述待检索多媒体的多模态特征,包括:
[0217]
调用多媒体检索模型的去冗余注意力层对所述待检索多媒体的特征信息包括的每个单模态特征进行特征规范空间处理,以得到所述每个单模态特征对应的自融合特征,所述单模态特征为所述视频特征、所述音频特征和所述文本特征中的任一种;
[0218]
调用所述多媒体检索模型的卷积层分别对所述每个单模态特征对应的自融合特征进行卷积堆叠处理,并将卷积堆叠处理后的每个自融合特征进行拼接处理,以确定所述待检索多媒体的拼接特征;
[0219]
调用所述多媒体检索模型的融合层对所述待检索多媒体的拼接特征进行融合提炼处理,得到所述待检索多媒体的多模态特征。
[0220]
在一种可能的实现方式中,处理器910调用多媒体检索模型的去冗余注意力层对所述待检索多媒体的特征信息包括的每个单模态特征进行特征规范空间处理,以得到所述每个单模态特征对应的自融合特征,包括:
[0221]
针对所述待检索多媒体的特征信息包括的每个单模态特征,获取所述单模态特征的位置权重向量,并调用所述去冗余注意力层的压缩层对所述单模态特征进行维度压缩处理,得到维度压缩后的单模态特征;
[0222]
调用所述去冗余注意力层的注意力层,利用所述位置权重向量和所述维度压缩后的单模态特征,计算位置相关后的单模态特征,并根据所述维度压缩后的单模态特征所指示的模态维度,对所述位置相关后的单模态特征进行计算,得到冗余单模态特征;
[0223]
调用所述去冗余注意力层的去冗余层,对所述冗余单模态特征规范化处理,得到规范权重向量,并根据所述规范权重向量对所述冗余单模态特征进行加权处理,以得到所述每个单模态特征对应的自融合特征。
[0224]
在一种可能的实现方式中,处理器910调用多媒体检索模型对所述待检索多媒体和多媒体库包括的每个多媒体进行处理,得到所述多媒体库中与所述待检索多媒体相似的一个或多个目标多媒体之前,所述方法还包括:
[0225]
获取训练数据集,所述训练数据集包括多个样本对以及每个样本对的样本标签,所述多个样本对包括模态完整样本对和模态缺失样本对,所述样本标签用于指示所述每个样本对包括的第一样本多媒体和第二样本多媒体在各个单模态特征之间的相似性;
[0226]
利用所述模态缺失样本对包括的第一样本多媒体的单模态特征和第二样本多媒体的单模态特征对第一神经网络模型进行单模态训练,得到第二神经网络模型,所述单模态特征为视频特征、音频特征和文本特征中的任一种;
[0227]
利用所述模态完整样本对包括的第一样本多媒体的特征信息和第二样本多媒体的特征信息对所述第二神经网络模型进行联合模态训练,得到多媒体检索模型,所述特征信息包括视频特征、音频特征和文本特征的一种或多种。
[0228]
在一种可能的实现方式中,处理器910利用所述模态缺失样本对包括的第一样本多媒体的单模态特征和第二样本多媒体的单模态特征对第一神经网络模型进行单模态训练,得到第二神经网络模型,包括:
[0229]
调用第一神经网络模型对所述模态缺失样本对包括的第一样本多媒体的单模态特征进行特征规范空间处理,以得到所述第一样本多媒体的单模态特征对应的自融合特征;
[0230]
调用第一神经网络模型对所述模态缺失样本对包括的第二样本多媒体的单模态特征进行特征规范空间处理,以得到所述第二样本多媒体的单模态特征对应的自融合特征;
[0231]
根据所述第一样本多媒体的单模态特征对应的自融合特征、所述第二样本多媒体的单模态特征对应的自融合特征、以及所述模态缺失样本对的样本标签,调整所述第一神经网络模型的模型参数,并将模型参数调整后的第一神经网络模型作为第二神经网络模型。
[0232]
在一种可能的实现方式中,处理器910利用所述模态完整样本对包括的第一样本多媒体的特征信息和第二样本多媒体的特征信息对所述第二神经网络模型进行联合模态
训练,得到多媒体检索模型,包括:
[0233]
调用所述第二神经网络模型对所述模态完整样本对包括的第一样本多媒体的各个单模态特征分别进行特征规范空间处理,得到所述模态完整样本对包括的第一样本多媒体的每个单模态特征对应的自融合特征,以及对所述模态完整样本对包括的每个自融合特征进行融合处理,得到所述第一样本多媒体的多模态特征;
[0234]
调用所述第二神经网络模型对所述模态完整样本对包括的第二样本多媒体的各个单模态特征分别进行特征规范空间处理,得到所述模态完整样本对包括的第二样本多媒体的每个单模态特征对应的自融合特征,以及对所述模态完整样本对包括的每个自融合特征进行融合处理,得到所述第二样本多媒体的多模态特征;
[0235]
根据所述第一样本多媒体的多模态特征、所述第二样本多媒体的多模态特征、以及所述模态完整样本对的样本标签,调整所述第二神经网络模型的模型参数,并将模型参数调整后的第二神经网络模型作为多媒体检索模型。
[0236]
在一种可能的实现方式中,处理器910根据所述第一样本多媒体与所述第二样本多媒体之间的相似度以及对应的样本标签,对所述神经网络模型进行训练,得到所述多媒体检索模型,包括:
[0237]
根据所述第一样本多媒体和所述第二样本多媒体之间的相似度以及对应的样本标签,计算所述神经网络模型的模型损失;
[0238]
根据所述神经网络模型的模型损失,更新所述神经网络模型的模型参数;
[0239]
当所述神经网络模型满足模型收敛条件时,将模型参数更新后的神经网络模型作为多媒体检索模型。
[0240]
应当理解,本技术实施例中所描述的计算机设备可执行前文图2和图6所对应实施例中对多媒体检索方法的描述,也可执行前文图8所对应实施例中对多媒体检索装置800的描述,在此不再赘述。另外,对采用相同方法的有益效果描述,也不再进行赘述。
[0241]
此外,这里需要指出的是:本技术实施例还提供了一种计算机存储介质,且计算机存储介质中存储有前文提及的多媒体检索装置800所执行的计算机程序,且该计算机程序包括程序指令,当处理器执行上述程序指令时,能够执行前文图2和图6所对应实施例中的方法,因此,这里将不再进行赘述。对于本技术所涉及的计算机存储介质实施例中未披露的技术细节,请参照本技术方法实施例的描述。作为示例,程序指令可以被部署在一个计算机设备上,或者在位于一个地点的多个计算机设备上执行,又或者,在分布在多个地点且通过通信网络互连的多个计算机设备上执行,分布在多个地点且通过通信网络互连的多个计算机设备可以组成区块链系统。
[0242]
根据本技术的一个方面,提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备可以执行前文图2和图6所对应实施例中的方法,因此,这里将不再进行赘述。
[0243]
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,上述程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,上述存储介质可为磁碟、
光盘、只读存储记忆体(read-only memory,rom)或随机存储记忆体(randomaccess memory,ram)等。
[0244]
以上所揭露的仅为本技术较佳实施例而已,当然不能以此来限定本技术之权利范围,因此依本技术权利要求所作的等同变化,仍属本技术所涵盖的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1