一种无屏手写识别装置及其识别系统的制作方法
1.本发明涉及手写识别技术领域,具体是指一种无屏手写识别装置及其识别系统。
背景技术:
2.随着手写体识别技术的速度发展,具有手写功能的平板电脑、智能移动终端等已经在市 场上非常普及。相对于键盘输入方式,手写笔输入是一种更直接的方式,是人们在纸上书写 汉字方式在电脑上的直接延伸,它更为自然、更符合普通中国人的书写习惯,可以有效降低 普通用户使用电脑、手机等智能设备的门槛。
3.传统的手写输入装置如电容笔或触控笔,具有精度高等特点,但这类手写输入装置的手 写输入都是依赖触控屏或手写屏,这样的使用特性一方面限制了它的使用场景,另一方面也 会带来制造成本的增加。而其它的基于摄像头捕捉手写笔运动轨迹的输入装置及方法,存在 光照条件、摄像头分辨率要求、成本等诸多不利因素限制其技术的应用,同样地,基于惯性 传感器(即加速度传感器、陀螺仪和磁力传感器等)的手写输入装置及方法也存在实际应用 精度差、用户体验不佳等局限性。这些手写输入装置及方法都是需要捕捉手写笔迹才能正常 识别结果,这种技术方法会给传感器的采集性能提出较高的要求。
技术实现要素:
4.本发明要解决的技术问题是解决上述问题,提供一种无屏手写识别装置及其识别系统。
5.为解决上述技术问题,本发明提供的技术方案为:一种无屏手写识别装置,包括笔身和 笔头,所述笔身设有接头插槽,所述笔身通过接头插槽连接笔头,所述笔头包括用于在任何 物理平面书写的双向电位器平衡环笔头,所述双向电位器平衡环笔头自由端设有第一笔尖, 所述双向电位器平衡环笔头外侧面设有第一按钮,所述笔身内设有芯片处理器、电源模块、 第一数据通信模块,所述笔头内设有第一数据采集模块。
6.进一步的,所述笔头包括用于在触摸屏或手写板上书写的电容笔头,所述电容笔头自由 端设有第二笔尖。
7.进一步的,所述笔身包括指环主体,所述指环主体一侧面设有指环套、按钮上键、按钮 下键,所述笔头设置在指环主体下面。
8.进一步的,所述第一笔尖靠近双向电位器平衡环笔头的一端设有插杆,所述双向电位器 平衡环笔头靠近第一笔尖的一端设有与插杆配合插接的插槽。
9.进一步的,所述第一按钮为上下按钮。
10.进一步的,所述第一数据采集模块包括笔头内设有的电位器及平衡环,所述第一数据采 集模块工作电压为5v dc,信号输出模式为vrx、vry2轴模拟输出,所述信号输出模式vrx、vry的值:从0~1000,分别代表:左
‑
右、上
‑
下,笔头未偏移时处于中间值500。
11.一种无屏手写识别系统,包括存储模块、第一深度学习模型、第二深度学习模型、第二 数据预处理模块、第二数据通信模块、字符展示模块、参数设置模块、深度学习模块训
练模块,具体包括以下步骤:
12.s1,获取无屏手写识别装置第一数据采集模块采集的原始手写数据,通过第一、第二数据通信模块按照协议格式上传到无屏手写识别系统,
13.s2,无屏手写识别系统根据笔画分割阀值对上传的原始手写数据使用第二数据预处理模块进行笔画切分,对切分后的数据进行预处理,组装成特定格式的输入数据,
14.s3,无屏手写识别系统将预处理好的数据输入到第一深度学习模型进行笔画类型预测,将笔画类型预测进行预处理后输入到第二深度学习模型进行汉字预测,同时,识别系统对topn汉字预测结果进行笔顺匹配优化处理并将优化处理后的结果进行通过字符展示模块展示和存储到存储模块,
15.s4,汉字识别采用多层双向gru网络结构实现,具体包括以下步骤:
16.s41,将第一深度学习模型的预测结果和采集的原始时序信息整合,
17.s42,将整合的笔顺时序数据进行规一化、规整化等预处理形成统一的数据形态,
18.s43,将预处理后的笔顺数据输入到第二深度学习模型进行汉字预测,
19.s44,对topn汉字预测结果进行笔顺匹配优化处理,调整汉字顺序将笔顺最匹配的汉字放在第一顺位,
20.s45,所述步骤将优化处理后的结果进行展示和存储,
21.采用以上结构后,本发明具有如下优点:让用户不依赖于触摸屏或手写板直接在任何物理平面上进行文字输入,更加便捷和智能化;同时本发明也不需要捕捉手写笔迹,仅需采集笔头的轴向偏移信息,采集方式简单有效,便于技术落地形成真实可用产品,具有广泛的应用场景。
22.优选的,所述步骤s1中,通过电位器及平衡环采集原始手写数据,具体采集的数据包括水平移动xs模拟信号、竖直移动ys模拟信号和时序ts,将原始采集数据通过数据通信模块按照协议格式上传到无屏手写识别系统,
23.所述步骤s2中,无屏手写识别系统根据笔画分割阀值对上传的原始采集数据进行笔画切分,无屏手写识别系统对水平移动xs模拟信号与竖直移动ys模拟信号进行滤波去噪:
[0024][0025]
无屏手写识别系统对模拟信号滤波去噪后,再通过阀值进行笔画分割,分割包括切分起始点和结束点:
[0026][0027]
起始点的个数和结束点的个数相等,它们都等于字符的总笔画数,分割得到的结
果是i
s
和 i
e
两个序列,
[0028]
无屏手写识别系统对切分后的数据进行预处理,组装成特定格式的输入数据,根据水平 移动xs模拟信号与竖直移动ys模拟信号以及i
s
和i
e
两个序列,得到每个笔画的模拟信号s
xs
和 s
ys
,每个笔画的长度不一致,需要规整到统一长度,统一长度可以预设为100,不足的用0 补齐,超出的截短,经过预处理后数据的shape为(100,2),
[0029]
所述步骤s4中,无屏手写识别系统将预处理好的数据输入到第一深度学习模型进行笔画 类型预测,第一深度学习模型采用多层双向gru结构,第一层神经元个数为200,dropout 为0.8;第二层神经元个数为100,dropout为0.8,损失函数为sparse_categorical_crossentropy, 优化器采用adam,分类个数为5,最后的输出结果可以取top 3,即候选识别结果为3个,
[0030]
所述步骤s41中,无屏手写识别系统将第一深度学习模型的预测结果和采集的原始时序 信息整合,每个笔画的起始点和结束点从i
s
和i
e
两个序列中获取,时长等于结束点减去起始点,
[0031]
所述步骤s42中,无屏手写识别系统将整合的笔顺时序数据进行规一化、规整化等预处 理形成统一的数据形态,
[0032]
所述步骤s43中,无屏手写识别系统将预处理后的笔顺数据输入到第二深度学习模型进 行汉字预测,第二深度学习模型采用多层双向gru结构,第一层神经元个数为500,dropout 为0.8;第二层神经元个数为400,dropout为0.8,损失函数为sparse_categorical_crossentropy, 优化器采用adam,分类个数由汉字训练集的字符规模来定,最后的输出结果可以取top 5, 即候选识别结果为5个,
[0033]
所述步骤s44中,无屏手写识别系统对top n汉字预测结果进行笔顺匹配优化处理,调 整汉字顺序将笔顺最匹配的汉字放在第一顺位,采用动态规划求解最长公共子串,动态规划 求解最长公共子序列的递归式如下:
[0034][0035]
所述步骤s45中,无屏手写识别系统将优化处理后的结果进行展示和存储。
[0036]
进一步地,所述步骤s41中第一深度学习网络模型识别结果中笔画类型包括笔画类型为 横编号为1、笔画类型为竖编号为2、笔画类型为撇编号为3、笔画类型为捺编号为4、笔画 类型为折编号为5。
[0037]
进一步地,所述步骤s42中无屏手写识别系统将字符总书写时长规一化为10s,输入样本 的特征值包括超始时间点、结束时间点、持续时长、起点是否为落笔、起点是否为收笔、笔 画种类,笔画总数,规整化是将输入样本的特征值的shape转换为(25,7)。
附图说明
[0038]
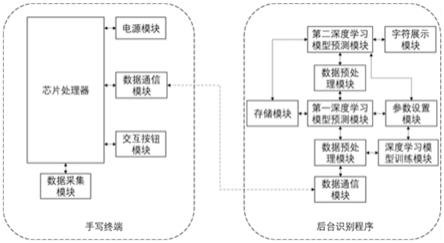
图1是本发明的无屏手写识别装置及其识别系统结构框架图。
[0039]
图2是本发明的识别系统笔顺类型识别的流程图。
[0040]
图3是本发明的笔顺识别结果进行第二深度学习网络模型识别汉字的流程图。
[0041]
图4是本发明的汉字识别的流程图。
[0042]
图5是本发明的无屏手写识别装置实施列一结构示意图。
[0043]
图6是本发明的无屏手写识别装置实施列二结构示意图。
[0044]
如图所示:1、笔身,2、笔头,3、接头插槽,4、第一笔尖,5、第一按钮,6、插杆,7、 插槽,8、指环主体,9、指环套,10、按钮上键;11、按钮下键,12、电容笔头,13、第二 笔尖。
具体实施方式
[0045]
下面结合附图对本发明做进一步的详细说明。
[0046]
主要包括移动端无屏手写识别装置和后台的无屏手写识别系统,其中移动端主要通过数 据采集模块和通信模块完成原始手写数据的采集以及数据的上传,后台无屏手写识别系统主 要对上传数据进行预处理并基于深度学习网络模型对手写体进行识别;
[0047]
实施列一
[0048]
结合附图1、图2、图3、图4、图5,一种无屏手写识别装置,包括笔身1和笔头2,所 述笔身1设有接头插槽3,所述笔身1通过接头插槽3连接笔头2,所述笔头2包括用于在任 何物理平面书写的双向电位器平衡环笔头,所述双向电位器平衡环笔头自由端设有第一笔尖 4,所述双向电位器平衡环笔头外侧面设有第一按钮5,所述笔身1内设有芯片处理器、电源 模块、第一数据通信模块,所述笔头2内设有第一数据采集模块。
[0049]
所述笔头2包括用于在触摸屏或手写板上书写的电容笔头12,所述电容笔头12自由端 设有第二笔尖13,完成一笔两用,充实扩展手写笔的使用场景。
[0050]
所述第一笔尖4靠近双向电位器平衡环笔头的一端设有插杆6,所述双向电位器平衡环 笔头靠近第一笔尖4的一端设有与插杆6配合插接的插槽7,便于更换日常书写磨损后的第 一笔尖4。
[0051]
所述第一按钮5为上下按钮,便于用户在识别候选汉字中选择想要的汉字。
[0052]
所述第一数据采集模块包括笔头2内设有的电位器及平衡环,所述第一数据采集模块工 作电压为5v dc,信号输出模式为vrx、vry2轴模拟输出,所述信号输出模式vrx、vry 的值:从0~1000,分别代表:左
‑
右、上
‑
下,笔头2未偏移时处于中间值500,随着笔头2 书写笔画方向不同,信号输出的阻值随着变化,这样通过采集电位器电压模拟输出信号可以 判断摇杆的推动位置,即水平移动(x)信号与竖直移动(y)信号,第一数数据采集模块由 第一数数据通信模块上传数据,上传时需要采集每个信号值的时序信息,便于后台无屏识别 系统判断每个笔画的时长信息。根据采集的水平移动(x)信号与竖直移动(y)信号,我们 就可以大致判断出每个笔画的类型,大致对应关系如附图3所示。横笔主要是笔头2左右移 动,竖笔主要是笔头2上下移动,撇笔主要是左下移动,捺笔主要是右下移动,折笔主要是 上下左右组合移动,笔画类型的判断主要是后台第一深度学习网络模型通过采集的水平移动 (x)信息与竖直移动(y)信息以及时序ts来预测的。
[0053]
一种无屏手写识别系统,包括存储模块、第一深度学习模型、第二深度学习模型、第二 数据预处理模块、第二数据通信模块、字符展示模块、参数设置模块、深度学习模块训练模 块,具体包括以下步骤:
[0054]
s1,获取无屏手写识别装置第一数据采集模块采集的原始手写数据,通过第一、第二数 据通信模块按照协议格式上传到无屏手写识别系统,在本实施例中移动手写装置与识别系统 之间采用串口通信方式,常用的串口波特率为9600,超时时长为0.5s,下位机通
信延时为5ms,防止通信错误,
[0055]
s2,无屏手写识别系统根据笔画分割阀值对上传的原始手写数据使用第二数据预处理模块进行笔画切分,对切分后的数据进行预处理,组装成特定格式的输入数据,
[0056]
s3,无屏手写识别系统将预处理好的数据输入到第一深度学习模型进行笔画类型预测,将笔画类型预测进行预处理后输入到第二深度学习模型进行汉字预测,同时,识别系统对topn汉字预测结果进行笔顺匹配优化处理并将优化处理后的结果进行通过字符展示模块展示和存储到存储模块,
[0057]
s4,汉字识别采用多层双向gru网络结构实现,具体包括以下步骤:
[0058]
s41,将第一深度学习模型的预测结果和采集的原始时序信息整合,
[0059]
s42,将整合的笔顺时序数据进行规一化、规整化等预处理形成统一的数据形态,
[0060]
s43,将预处理后的笔顺数据输入到第二深度学习模型进行汉字预测,
[0061]
s44,对topn汉字预测结果进行笔顺匹配优化处理,调整汉字顺序将笔顺最匹配的汉字放在第一顺位,
[0062]
s45,所述步骤将优化处理后的结果进行展示和存储,
[0063]
所述步骤s1中,通过电位器及平衡环采集原始手写数据,具体采集的数据包括水平移动xs模拟信号、竖直移动ys模拟信号和时序ts,
[0064]
所述步骤s2中,无屏手写识别系统根据笔画分割阀值对上传的原始采集数据进行笔画切分,无屏手写识别系统对水平移动xs模拟信号与竖直移动ys模拟信号进行滤波去噪:
[0065][0066][0067]
无屏手写识别系统对模拟信号滤波去噪后,再通过阀值进行笔画分割,分割包括切分起始点和结束点:
[0068][0069]
起始点的个数和结束点的个数相等,它们都等于字符的总笔画数,分割得到的结果是i
s
和i
e
两个序列,
[0070]
无屏手写识别系统对切分后的数据进行预处理,组装成特定格式的输入数据,根据水平移动xs模拟信号与竖直移动ys模拟信号以及i
s
和i
e
两个序列,得到每个笔画的模拟信号s
xs
和s
ys
,每个笔画的长度不一致,需要规整到统一长度,统一长度可以预设为100,不足的用0补齐,超出的截短,经过预处理后数据的shape为(100,2),
[0071]
所述步骤s4中,无屏手写识别系统将预处理好的数据输入到第一深度学习模型进
行笔画 类型预测,第一深度学习模型采用多层双向gru结构,第一层神经元个数为200,dropout 为0.8;第二层神经元个数为100,dropout为0.8,损失函数为sparse_categorical_crossentropy, 优化器采用adam,分类个数为5,最后的输出结果可以取top 3,即候选识别结果为3个, 在本实施方式中,在第一深度学习网络模型识别结果的基础上,识别系统对笔顺识别结果进 行第二深度学习网络模型识别汉字,具体流程如附图3所示,
[0072]
所述步骤s41中,无屏手写识别系统将第一深度学习模型的预测结果和采集的原始时序 信息整合,每个笔画的起始点和结束点从i
s
和i
e
两个序列中获取,时长等于结束点减去起始点,
[0073]
所述步骤s42中,无屏手写识别系统将整合的笔顺时序数据进行规一化、规整化等预处 理形成统一的数据形态,
[0074]
所述步骤s43中,无屏手写识别系统将预处理后的笔顺数据输入到第二深度学习模型进 行汉字预测,第二深度学习模型采用多层双向gru结构,第一层神经元个数为500,dropout 为0.8;第二层神经元个数为400,dropout为0.8,损失函数为sparse_categorical_crossentropy, 优化器采用adam,分类个数由汉字训练集的字符规模来定,在本实施方式中汉字训练集采用 国标一级、二级字库,总共6763个汉字,其中一级字库中有3755个,为常用汉字,二级字 库中有3008个,为次常用汉字,所以分类个数为6763。最后的输出结果可以取top 5。最后 的输出结果可以取top 5,即候选识别结果为5个,
[0075]
所述步骤s44中,无屏手写识别系统对top n汉字预测结果进行笔顺匹配优化处理,调 整汉字顺序将笔顺最匹配的汉字放在第一顺位,采用动态规划求解最长公共子串,动态规划 求解最长公共子序列的递归式如下:
[0076][0077]
所述步骤s45中,无屏手写识别系统将优化处理后的结果进行展示和存储。
[0078]
所述步骤s41中第一深度学习网络模型识别结果中笔画类型包括笔画类型为横编号为1、 笔画类型为竖编号为2、笔画类型为撇编号为3、笔画类型为捺编号为4、笔画类型为折编号 为5。
[0079]
所述步骤s42中无屏手写识别系统将字符总书写时长规一化为10s,输入样本的特征值 包括超始时间点、结束时间点、持续时长、起点是否为落笔、起点是否为收笔、笔画种类, 笔画总数,规整化是将输入样本的特征值的shape转换为(25,7)。
[0080]
本发明在具体实施时,本发明基于深度学习的无屏手写识别装置及其识别系统,其中移 动端传感器即电位器及平衡环,只需要采集笔尖的每个笔画轴向信息以及每个笔画的起始时 间及结束时间,相对于其他采集笔尖运动轨迹的方式,本发明的采集方式更简单高效、精度 更高。
[0081]
本发明的移动端传感器优选方式由双向电位器及一个平衡环组成,平衡环将笔尖位移分 为水平移动(x)与竖直移动(y),模拟采集电位器电压来判断摇杆的推动位置,相对于其 他传感器如加速度传感器、惯性传感器或重力传感器等,本系统能准确地切分出所书写汉字 的每个笔画,而其他传感器很难准确地分割出每个笔画的起始时间及结束时间;
[0082]
本发明的汉字识别分类器优选方式采用两个识别精度较高的多层双向gru网络模
型,第一深度学习网络模型根据采集数据识别笔顺类型,第二深度学习网络模型根据笔顺信息识别汉字,双网络模型结合具有良好的鲁棒性和较高的识别准确率。
[0083]
实施列二
[0084]
结合附图1、图2、图3、图4、图6,一种无屏手写识别装置,包括笔身1和笔头2,所述笔身1包括指环主体8,所述指环主体8一侧面设有指环套9、按钮上键10、按钮下键11,所述笔头2设置在指环主体8下面,所述笔身1设有接头插槽3,所述笔身1通过接头插槽3连接笔头2,所述笔头2包括用于在任何物理平面书写的双向电位器平衡环笔头,所述双向电位器平衡环笔头自由端设有第一笔尖4,所述双向电位器平衡环笔头外侧面设有第一按钮5,所述笔身1内设有芯片处理器、电源模块、第一数据通信模块,所述笔头2内设有第一数据采集模块。
[0085]
所述笔头2包括用于在触摸屏或手写板上书写的电容笔头12,所述电容笔头12自由端设有第二笔尖13,完成一笔两用,充实扩展手写笔的使用场景。
[0086]
所述第一笔尖4靠近双向电位器平衡环笔头的一端设有插杆6,所述双向电位器平衡环笔头靠近第一笔尖4的一端设有与插杆6配合插接的插槽7,便于更换日常书写磨损后的第一笔尖4。
[0087]
所述第一按钮5为上下按钮,便于用户在识别候选汉字中选择想要的汉字。
[0088]
所述第一数据采集模块包括笔头2内设有的电位器及平衡环,所述第一数据采集模块工作电压为5vdc,信号输出模式为vrx、vry2轴模拟输出,所述信号输出模式vrx、vry的值:从0~1000,分别代表:左
‑
右、上
‑
下,笔头2未偏移时处于中间值500,随着笔头2书写笔画方向不同,信号输出的阻值随着变化,这样通过采集电位器电压模拟输出信号可以判断摇杆的推动位置,即水平移动(x)信号与竖直移动(y)信号,第一数数据采集模块由第一数数据通信模块上传数据,上传时需要采集每个信号值的时序信息,便于后台无屏识别系统判断每个笔画的时长信息。根据采集的水平移动(x)信号与竖直移动(y)信号,我们就可以大致判断出每个笔画的类型,大致对应关系如附图3所示。横笔主要是笔头2左右移动,竖笔主要是笔头2上下移动,撇笔主要是左下移动,捺笔主要是右下移动,折笔主要是上下左右组合移动,笔画类型的判断主要是后台第一深度学习网络模型通过采集的水平移动(x)信息与竖直移动(y)信息以及时序ts来预测的。
[0089]
一种无屏手写识别系统,包括存储模块、第一深度学习模型、第二深度学习模型、第二数据预处理模块、第二数据通信模块、字符展示模块、参数设置模块、深度学习模块训练模块,具体包括以下步骤:
[0090]
s1,获取无屏手写识别装置第一数据采集模块采集的原始手写数据,通过第一、第二数据通信模块按照协议格式上传到无屏手写识别系统,在本实施例中移动手写装置与识别系统之间采用串口通信方式,常用的串口波特率为9600,超时时长为0.5s,下位机通信延时为5ms,防止通信错误,
[0091]
s2,无屏手写识别系统根据笔画分割阀值对上传的原始手写数据使用第二数据预处理模块进行笔画切分,对切分后的数据进行预处理,组装成特定格式的输入数据,
[0092]
s3,无屏手写识别系统将预处理好的数据输入到第一深度学习模型进行笔画类型预测,将笔画类型预测进行预处理后输入到第二深度学习模型进行汉字预测,同时,识别系统对topn汉字预测结果进行笔顺匹配优化处理并将优化处理后的结果进行通过字符展
示模块展示和 存储到存储模块,
[0093]
s4,汉字识别采用多层双向gru网络结构实现,具体包括以下步骤:
[0094]
s41,将第一深度学习模型的预测结果和采集的原始时序信息整合,
[0095]
s42,将整合的笔顺时序数据进行规一化、规整化等预处理形成统一的数据形态,
[0096]
s43,将预处理后的笔顺数据输入到第二深度学习模型进行汉字预测,
[0097]
s44,对top n汉字预测结果进行笔顺匹配优化处理,调整汉字顺序将笔顺最匹配的汉字 放在第一顺位,
[0098]
s45,所述步骤将优化处理后的结果进行展示和存储,
[0099]
所述步骤s1中,通过电位器及平衡环采集原始手写数据,具体采集的数据包括水平移动 xs模拟信号、竖直移动ys模拟信号和时序ts,
[0100]
所述步骤s2中,无屏手写识别系统根据笔画分割阀值对上传的原始采集数据进行笔画切 分,无屏手写识别系统对水平移动xs模拟信号与竖直移动ys模拟信号进行滤波去噪:
[0101][0102][0103]
无屏手写识别系统对模拟信号滤波去噪后,再通过阀值进行笔画分割,分割包括切分起 始点和结束点:
[0104][0105]
起始点的个数和结束点的个数相等,它们都等于字符的总笔画数,分割得到的结果是i
s
和 i
e
两个序列,
[0106]
无屏手写识别系统对切分后的数据进行预处理,组装成特定格式的输入数据,根据水平 移动xs模拟信号与竖直移动ys模拟信号以及i
s
和i
e
两个序列,得到每个笔画的模拟信号s
xs
和 s
ys
,每个笔画的长度不一致,需要规整到统一长度,统一长度可以预设为100,不足的用0 补齐,超出的截短,经过预处理后数据的shape为(100,2),
[0107]
所述步骤s4中,无屏手写识别系统将预处理好的数据输入到第一深度学习模型进行笔画 类型预测,第一深度学习模型采用多层双向gru结构,第一层神经元个数为200,dropout 为0.8;第二层神经元个数为100,dropout为0.8,损失函数为sparse_categorical_crossentropy, 优化器采用adam,分类个数为5,最后的输出结果可以取top 3,即候选识别结果为3个, 在本实施方式中,在第一深度学习网络模型识别结果的基础上,识别系统对笔顺识别结果进 行第二深度学习网络模型识别汉字,具体流程如附图3所示,
[0108]
所述步骤s41中,无屏手写识别系统将第一深度学习模型的预测结果和采集的原
始时序 信息整合,每个笔画的起始点和结束点从i
s
和i
e
两个序列中获取,时长等于结束点减去起始点,
[0109]
所述步骤s42中,无屏手写识别系统将整合的笔顺时序数据进行规一化、规整化等预处 理形成统一的数据形态,
[0110]
所述步骤s43中,无屏手写识别系统将预处理后的笔顺数据输入到第二深度学习模型进 行汉字预测,第二深度学习模型采用多层双向gru结构,第一层神经元个数为500,dropout 为0.8;第二层神经元个数为400,dropout为0.8,损失函数为sparse_categorical_crossentropy, 优化器采用adam,分类个数由汉字训练集的字符规模来定,在本实施方式中汉字训练集采用 国标一级、二级字库,总共6763个汉字,其中一级字库中有3755个,为常用汉字,二级字 库中有3008个,为次常用汉字,所以分类个数为6763。最后的输出结果可以取top 5。最后 的输出结果可以取top 5,即候选识别结果为5个,
[0111]
所述步骤s44中,无屏手写识别系统对top n汉字预测结果进行笔顺匹配优化处理,调 整汉字顺序将笔顺最匹配的汉字放在第一顺位,采用动态规划求解最长公共子串,动态规划 求解最长公共子序列的递归式如下:
[0112][0113]
所述步骤s45中,无屏手写识别系统将优化处理后的结果进行展示和存储。
[0114]
所述步骤s41中第一深度学习网络模型识别结果中笔画类型包括笔画类型为横编号为1、 笔画类型为竖编号为2、笔画类型为撇编号为3、笔画类型为捺编号为4、笔画类型为折编号 为5。
[0115]
所述步骤s42中无屏手写识别系统将字符总书写时长规一化为10s,输入样本的特征值 包括超始时间点、结束时间点、持续时长、起点是否为落笔、起点是否为收笔、笔画种类, 笔画总数,规整化是将输入样本的特征值的shape转换为(25,7)。
[0116]
本发明在具体实施时,本发明基于深度学习的无屏手写识别装置及其识别系统,其中移 动端传感器即电位器及平衡环,只需要采集笔尖的每个笔画轴向信息以及每个笔画的起始时 间及结束时间,相对于其他采集笔尖运动轨迹的方式,本发明的采集方式更简单高效、精度 更高。
[0117]
本发明的移动端传感器优选方式由双向电位器及一个平衡环组成,平衡环将笔尖位移分 为水平移动(x)与竖直移动(y),模拟采集电位器电压来判断摇杆的推动位置,相对于其 他传感器如加速度传感器、惯性传感器或重力传感器等,本系统能准确地切分出所书写汉字 的每个笔画,而其他传感器很难准确地分割出每个笔画的起始时间及结束时间;
[0118]
本发明的汉字识别分类器优选方式采用两个识别精度较高的多层双向gru网络模型,第 一深度学习网络模型根据采集数据识别笔顺类型,第二深度学习网络模型根据笔顺信息识别 汉字,双网络模型结合具有良好的鲁棒性和较高的识别准确率。
[0119]
以上对本发明及其实施方式进行了描述,这种描述没有限制性,实际的结构并不局限于 此。总而言之如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不 经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1