1.本发明涉及一种面向小样本图像集的超分辨率图像重构方法,具体设计是一种基于小样本图像的gan金字塔结构训练的超分辨率学习方法,属于人工智能、计算机视觉领域。
背景技术:2.在计算机视觉领域中,大致分为两个主要方向,分别是图像识别和图像生成。图像识别在日常生活中的使用非常普遍,现如今人们最常使用的人脸支付就是其中一种应用。图像生成的应用领域也非常广,例如可以将模糊图像进行放大并使得其细节变清晰的超分辨率,或者让一个图像可以平滑的改变风格的风格迁移等。
3.在多年来的计算机视觉研究中,卷积神经网络和残差网络已经得到了广泛的研究,并已用于提高现代深度神经网络的性能。事实证明,卷积神经网络和残差网络在提升深度神经网络的学习效率和学习精度上有很好的效果,提升了多种场景应用的效果,例如图像分类和超分辨率。
4.在2014年goodfellow等人提出了生成对抗学习网络gan,让图像生成这一任务方向取得了显著进展,但仍存在许多未解决的问题,比如原始的gan模型训练容易遇到梯度爆炸和图像细节学习不足等问题。之后有人提出将卷积神经网络cnn加入到gan中,组成了深度卷积生成对抗网络dcgan,目前来看这种尝试非常成功,解决了gan梯度爆炸等问题。然而,通过仔细检查这些生成的样本,尽管先进的imagenet gan模型擅长在结构约束较少的情况下生成图像类别(例如,海洋、天空和景观类别,这些类别更多地通过纹理而不是几何结构来区分),它无法捕捉某些类别中持续出现的几何或结构模式,这就使得它难以进行复杂的超分辨率任务。
5.生成对抗网络包括两种模型,分别是生成器g和判别器d,它们的训练同时进行:通过训练d使训练样本和来自g的样本的正确标签的概率最大化;同时通过最小化log(1
‑
d(g(z)))来调整生成器g的参数。
6.christian ledig等人在2017年首次提出将残差网络融入到gan中来加强模型的学习效率,残差网络的思想是将原来的输入加到经过卷积操作后的输出上,这样可以稳定训练,保证网络不会丢失原先已经学习到的细节,同时也让网络的学习深度有了较大的提升,使网络的学习精度有了长足的进步。christian ledig等人同时提出将这种新型的网络运用到超分辨率(super
‑
resolution,sr)的场景当中,在这之前sr的任务的效果都难以满足人们的要求,而这篇论文的结果直接获得了sota(state of the art)。
7.不过这个方法面向的是拥有较多数据集的情况下,它在小样本场景下的生成效果并不令人满意。
技术实现要素:8.本发明的目的是针对上述已有技术存在的不足和缺陷,在小样本图像集实现超分
辨率的任务中,提供了一种面向小样本图像集的超分辨率图像重构方法。
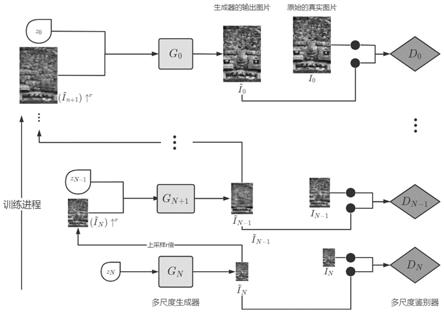
9.本发明采用的技术方案是:一种面向小样本图像集的超分辨率图像重构方法,本发明面向的对象是小样本图像集、本发明使用多层gan组成的串行金字塔结构来训练;
10.金字塔gan中包括多尺度生成模块和多尺度判别模块,其中生成器使用的是以卷积神经网络为基础的残差神经网络;
11.多尺度生成模块,包括多层的样本空间生成器g
n
~g0;
12.多尺度鉴别模块,包括多层的样本空间判别器d
n
~d0;
13.在基础的生成对抗学习模型的前提下,基于卷积神经网络并融合残差网络的新型gan在对待超分辨率这一任务时表现出了较好的效果。这种新型的gan保证了模型对图像学习的稳定性,保证模型不会出现梯度爆炸的现象,同时还降低了模型训练的时间,大大提升了模型的性能。
14.通过结合上述的方法,提出一种串行的多尺度gan金字塔训练结构,这个结构根据不同尺度对应的不同尺寸就行对应的学习,上一个尺寸的图像训练完成才进行下一层的训练,将上一层的输出上采样后作为下一层的输入进行学习。这个结构提高了模型对图像细节的学习精度,让模型非常适合小样本领域,同时也非常适用于超分辨率这一训练场景。
15.整体的方法架构如图1所示,整体的训练用公式表示为:
[0016][0017]
其中,为金字塔gan中每一层生成器g
n
的输出图像,g
n
()表示生成器的生成过程,z
n
表示高斯噪声,表示上一层输出图像的上采样。因为第n层没有上一层的输出,所以这一层的输入只有高斯噪声z
n
,具体公式如下:
[0018][0019]
其中,为金字塔gan中第n层生成器g
n
的输出图像,g
n
()表示生成器生成过程,z
n
表示高斯噪声。
[0020]
上述的公式再细化可以得到以下公式:
[0021][0022]
其中,为金字塔gan中每一层生成器g
n
的输出图像,表示上一层gan输出图像的上采样,ψ
n
()表示由5个conv(3
×
3)
‑
batchnorm
‑
leakyrelu卷积块组成的完全卷积网络。在训练阶段的最低尺度中,每个卷积块包括32个卷积核,每经过4个尺度,卷积核的数量翻倍。因为生成器是完全卷积的,所以可以在测试时生成任意大小和纵横比的图像(通过改变噪声图的维度)。
[0023]
上述方法的具体步骤如下:
[0024]
(1)在训练开始阶段,先对图像进行预处理,选择一个特定的比例1/r把原始的真实图像进行n次迭代下采样,下采样使用求像素均值的方法。得到迭代后的共n+1个尺度的图像,将这n+1个尺度图像保存为i0~i
n
,i0是原始图像,i
n
是n次下采样后尺寸最小的图像,这些图像将作为各级判别器的输入。
[0025]
(2)图像预处理过后,开始第n层的gan(生成对抗网络)学习,第n层生成器g
n
的输入为一个和i
n
尺寸相同的高斯噪声图像z
n
,之后第n层生成器g
n
通过学习后生成质量较低的
图像再把图像和步骤(1)中得到的下采样后的真实图像i
n
作为第n层判别器的输入,判别器判别后促使生成器改进生成效果,不断的更新生成图像,使最后的生成图像更接近于输入的真实图像i
n
,本层训练结束得到更新完成后质量最高的生成图像
[0026]
(3)下面开始第n
‑
1层gan的训练,在第n层gan训练完毕后,将该层的输出图像用双线性插值法进行比例为r的上采样,将得到的图像和相同尺寸的高斯噪声图像z
n
‑1作为生成器g
n
‑1的输入进行学习,然后得到生成的质量较低的图像然后把和真实图像i
n
‑1作为判别器d
n
‑1的输入进行判别,和g
n
‑1进行对抗,最后得到更新完成后质量较高的生成图像
[0027]
(4)迭代的运行步骤(3),对每一个尺度的图像都进行训练,到第0层训练完成后结束迭代,这时我们就得到了包括最小尺度的g
n
到最大尺度的g0共n+1个尺度的生成器,这时代表本模型的训练阶段结束。
[0028]
(5)训练阶段结束后,并不能立即进行超分辨率操作。在进行实际的测试时,会对输入图像进行二次训练。二次训练的过程和一次训练的类似,不过训练尺度不同,都是先运行步骤(1)和(2),然后迭代的运行步骤(3)(4),直到训练结束。
[0029]
(6)二次训练结束后,得到训练好的生成器g0,通过g0生成超分辨率重构后的图像,在本发明中,设置生成超分辨率的倍数为4倍,所以最后生成的图像是放大四倍并且细节更清晰的图像。
[0030]
在步骤(2)(3)中判别器返回的损失定义为两个部分,分别是对抗损失和重构损失。对抗损失就是生成器g和判别器d的基于代价函数l(g,d)的极大极小博弈的训练过程,这里用来表示。重构损失是指图像在经过生成器g中的卷积或反卷积等操作时,会损失一些图像精度,这里用αl
rec
(g)来表示,其中α表示的是残差网络中规定的学习率。
[0031]
把上述的损失函数加在一起,就构成了每一层gan中的损失函数,可以得到以下的计算公式为:
[0032][0033]
其中,表示的是每一层gan中的生成器g
n
和判别器d
n
在进行基于函数l
adv
(g,d)的极大极小博弈,这个函数实际上是通过计算均方误差来得到的,αl
rec
(g
n
)中α是残差网络中规定的学习率,l
rec
(g
n
)表示的是生成器g
n
在生成过程中的损失,具体计算公式如下:
[0034][0035]
其中,表示的是上一层的输出进行比例为r的上采样,表示生成器g
n
的生成结果,i
n
是这一层的真实图像,||||2表示的是||||中的公式取范数后平方。因为金字塔的第n层的输入只有高斯噪声z
n
,所以这一层l
rec
(g
n
)计算公式为:
[0036]
l
rec
=‖g
n
(z
n
)
‑
i
n
‖2[0037]
其中,g
n
(z
n
)表示的是第一层生成器g
n
的生成结果,z
n
表示的是第n的输入噪声,i
n
是这一层的真实图像,||||2表示的是||||中的公式取范数后平方。
[0038]
进一步地,步骤(2)、(3)中所述的gan模型是由生成器g0‑
n
和判别器d0‑
n
组成,其架构详见图2、3。具体运行步骤包括:
[0039]
(2.1)生成器g
n
的输入为高斯噪声z
n
和上一层输出的上采样
[0040]
(2.2)根据残差网络的思想,在生成器g
n
中要进行多次迭代,如图2所示,图中的conv层表示每次迭代操作,每次迭代包括卷积层conv,归一化层bn和激活层relu。对生成器g
n
的输入进行迭代,每隔5次迭代后得到一个张量,然后将得到的张量以一定比例和输入图像所表示的张量相加,得到最终的张量,然后再将这个张量转化成图像作为生成器g
n
的输出
[0041]
(2.3)通过步骤(2.2)得到生成器g
n
的输出图像再结合真实图像i
n
组成判别器d
n
的输入,之后判别器d
n
的结构和生成器g
n
类似,如图3所示,不过在5个conv卷积层后会有一个全连接层(dense),这个层是根据权重来分类的,dense全连接层后跟一个relu激活函数,然后再跟一个dense全连接层,最后是一个sigmoid激活层,这个层的作用是用来实现前向或后向的计算。判别器d
n
的作用是判断和真实图像i
n
是否相近,如果相差较大的话判别器d
n
会返回一个损失函数,并促使生成器g
n
重新生成,直到生成的结果可以通过判别器。
[0042]
本发明的有益效果是:提出了一种新型的gan金字塔结构,并且结合以卷积神经网络的残差网络为基础组成的新型gan。首先,本发明增强了模型训练的稳定性,大大降低了出现梯度爆炸情况的概率。第二,本发明加深了模型网络的可训练深度,这使得网络对图像细节的学习有了极大的进步。第三,gan金字塔结构串行训练,每一层对应不同的尺度和尺寸,从小到大依次训练,上一层输出的上采样作为下一层的输入,串联起各层的训练。这个设计大大提高模型对每张图像的学习效果。最后,通过上述的设计,本发明适用于很多小样本图像乃至单图像领域的任务,本发明选取小样本图像领域的超分辨率这一具有挑战的任务,取得了较好的效果。
附图说明
[0043]
图1是基于小样本图像的gan金字塔结构训练的超分辨率学习方法框架图;
[0044]
图2是gan金字塔中每层gan的生成器g
n
的结构图;
[0045]
图3是gan金字塔中每层gan的判别器d
n
的结构图;
[0046]
图4是本发明与其他先进的对抗学习网络以小样本中一张图片为例所做的对比实验结果。
具体实施方式
[0047]
下面结合附图和在小样本数据集上的训练对发明内容作进一步说明。
[0048]
实施例1:如图1
‑
4所示,一种面向小样本图像集的超分辨率图像重构方法,本发明使用多层gan组成的串行金字塔结构来训练;
[0049]
本发明在训练前会进行图像的预处理,会将原始的输入图片进行n次的下采样,原
始图像记为i0,第一次下采样得到的图像记为i1,以此类推,最后一次下采样得到的图像记为i
n
。
[0050]
在多层gan组成的串行金字塔结构中,每一层代表一个尺度,每一个尺度运用不同尺寸的图像进行训练,分别对应上述图像预处理的结果i
0~n
。
[0051]
训练时从最小的尺度i
n
开始,所以把第n层gan中的生成器记为g
n
,判别器记为d
n
,训练完毕后将得到的输出用双线性插值法进行上采样,,之后把上采样得到的图像作为第n
‑
1层gan的输入。这个过程以此类推,最后一层,也就是第0层gan使用的尺度就是i0,故这一层的生成器记为g0,判别器记为d0,具体流程可以参考图1。
[0052]
在多层gan组成的串行金字塔结构中,包括多尺度生成模块和多尺度鉴别模块,其中生成器使用的是以卷积神经网络为基础的残差神经网络;
[0053]
多尺度生成模块,包括多层的样本空间生成器g
n
~g0;
[0054]
多尺度鉴别模块,包括多层的样本空间判别器d
n
~d0;
[0055]
所述方法的网络结构如图1所示,具体运行步骤如下:
[0056]
(1)在训练开始阶段,先对图像进行预处理,选择一个特定的比例1/r把原始的真实图像进行n次迭代下采样,下采样使用求像素均值的方法。得到迭代后的共n+1个尺度的图像,将这n+1个尺度图像保存为i0~i
n
,i0是原始图像,i
n
是n次下采样后尺寸最小的图像,这些图像将作为各级判别器的输入。
[0057]
(2)图像预处理过后,开始第n层的gan(生成对抗网络)学习,第n层生成器g
n
的输入为一个和i
n
尺寸相同的高斯噪声图像z
n
,之后第n层生成器g
n
通过学习后生成质量较低的图像再把图像和步骤(1)中得到的下采样后的真实图像i
n
作为第n层判别器的输入,判别器判别后促使生成器改进生成效果,不断的更新生成图像,使最后的生成图像更接近于输入的真实图像i
n
,本层训练结束得到更新完成后质量最高的生成图像
[0058]
(3)下面开始第n
‑
1层gan的训练,在第n层gan训练完毕后,将该层的输出图像用双线性插值法进行比例为r的上采样,将得到的图像和相同尺寸的高斯噪声图像z
n
‑1作为生成器g
n
‑1的输入进行学习,然后得到生成的质量较低的图像然后把和真实图像i
n
‑1作为判别器d
n
‑1的输入进行判别,和g
n
‑1进行对抗,最后得到更新完成后质量较高的生成图像
[0059]
(4)迭代的运行步骤(3),对每一个尺度的图像都进行训练,到第0层训练完成后结束迭代,这时我们就得到了包括最小尺度的g
n
到最大尺度的g0共n+1个尺度的生成器,这时代表本模型的训练阶段结束。
[0060]
(5)训练阶段结束后,并不能立即进行超分辨率操作。在进行实际的测试时,会对输入图像进行二次训练。二次训练的过程和一次训练的类似,不过训练尺度不同,都是先运行步骤(1)和(2),然后迭代的运行步骤(3)(4),直到训练结束。
[0061]
(6)二次训练结束后,得到训练好的生成器g0,通过g0生成超分辨率重构后的图像,在本发明中,设置生成超分辨率的倍数为4倍,所以最后生成的图像是放大四倍并且细节更清晰的图像。
[0062]
对步骤(2)、(3)进行详细讨论,其具体运行步骤包括:
[0063]
(2.1)生成器g
n
的输入为高斯噪声z
n
和上一层输出的上采样
[0064]
(2.2)根据残差网络的思想,在生成器g
n
中要进行多次迭代,如图2所示,图中的conv层表示每次迭代操作,每次迭代包括卷积层conv,归一化层bn和激活层relu。对生成器g
n
的输入进行迭代,每隔5次迭代后得到一个张量,然后将得到的张量以一定比例和输入图像所表示的张量相加,得到最终的张量,然后再将这个张量转化成图像作为生成器g
n
的输出
[0065]
(2.3)通过步骤(2.2)得到生成器g
n
的输出图像再结合真实图像i
n
组成判别器d
n
的输入,之后判别器d
n
的结构和生成器g
n
类似,如图3所示,不过在5个conv卷积层后会有一个全连接层(dense),这个层是根据权重来分类的,dense全连接层后跟一个relu激活函数,然后再跟一个dense全连接层,最后是一个sigmoid激活层,这个层的作用是用来实现前向或后向的计算。判别器d
n
的作用是判断和真实图像i
n
是否相近,如果相差较大的话判别器d
n
会返回一个损失函数,并促使生成器g
n
重新生成,直到生成的结果可以通过判别器。
[0066]
本发明有着广泛的应用领域,不止可以应用在超分辨率这一任务上,在其他很多图像生成范围内的热门任务都可以使用,例如风格迁移、图像填充、paint
‑
to
‑
image、图像融合等。本发明着眼于小样本领域,针对小样本图像领域存在的数据集不充足和图像信息缺失等问题进行解决,大大提高了小样本图像乃至单图像领域的超分辨率任务的生成效果,在基础图像稀缺的情况下得到可以满足人们要求的超分辨率图像。
[0067]
本发明实验过程中,使用系统ubuntu 18.04,采用硬件cpu为amd ryzen 52600sii
‑
core processor 3.85ghz,编程语言为python 3.6,显卡为英伟达geforce rti 2070,深度学习框架为pytorch 1.4。所用数据集为小样本模糊数据集bsd100,图片都是清晰图片经过模糊处理后得到的,分辨率集中在80
×
80像素到120
×
120像素之间。本发明与其他先进的对抗学习网络以此数据集为例所做的对比实验结果如图4,对比实验结果评估参数如下表:
[0068]
模型rmseniqeedsr12.296.50dip13.826.35zssp13.087.13本发明16.223.71
[0069]
其中:rmse为root mean squared error,是均方误差的意思,在这里用于评估生成图像的质量,数值越大越好;niqe为natural image quality evaluator,用于评估生成图像和原始图像的失真程度,数值越小越好。
[0070]
综上所述,根据本发明实施的一种基于小样本图像的gan金字塔结构训练的超分辨率学习方法,是一种使用新型的以卷积神经网络为基础的残差网络组成的生成对抗网络(gan),利用这种新型gan构建一个存在多个尺度的gan金字塔结构。与之前的方法不同,本发明采用不同尺度串行训练的结构,上一层的输出上采样后作为下一层的输入进行训练,这样的结构让不同的尺度的训练可以有机的联系起来,不再是毫无联系的并行训练,加强了模型对每张图像的学习效果,进一步增强了图像的细节生成效果,在数据集较少的情况
下取得了令人满意的效果。
[0071]
本发明着眼于小样本学习在超分辨率场景下的应用,提高了在训练图像稀缺情况下获得超分辨率图像的清晰度,减少了训练时间和训练样本的数量,使重构图像质量得到了提升和保证。本发明的实际应用价值很高,比如追查犯罪嫌疑人时,原来的图片不够清晰且数量很少,这时可以用本发明生成高像素的清晰图片,还可以用于老照片清晰度提升等场景。
[0072]
上面结合附图对本发明的具体实施方式做了详细说明,但是本发明并不局限于上述实施方式,在进行不同任务场景的开发时,可以对本发明进行一定的改进,根据不同任务侧重点的不同来设计模型的结构,或者选择不同的训练尺度来调整图像学习的效率。