分布式轨迹流伴随模式挖掘方法
1.本发明涉及轨迹数据技术领域,具体地说,涉及一种分布式轨迹流伴随模式挖掘方法。
背景技术:
2.定位设备和位置跟踪技术的进步,产生了大量的轨迹数据,记录了各种应用中的人、车辆和动物的移动,如社交网络、交通管理、科学研究和军事侦察。
3.近年来,基于轨迹数据流的伴随模式挖掘技术不断产生,但现有系统仅适用于小规模数据集,在大规模轨迹数据流中表现不佳,主要原因及挑战如下:
4.(1)实时性:轨迹数据流具有无限增长,快速到达,实时更新特性,且难以将其存储,因此需要及时进行处理。这就要求轨迹流数据中的伴随模式挖掘算法满足时间上高效的要求,而传统算法并不能很好的满足以上要求。
5.(2)方向性:在真实的轨迹流伴随模式中,数据点移动方向多样。鉴于传统的dbscan对移动对象进行聚类,容易产生冗余数据信息。为了达到较好的聚类效果节省聚类时间,挖掘算法需要具有方向性,而现有的算法并未考虑方向因素。
6.(3)并行性:城市级别的轨迹数据实时到达,规模巨大,使得单台服务器和单线程的处理难以负载。因此,需要多台服务器对数据分块处理并增加算法的并行度,而现有的算法都是单节点单线程算法,无法应对大规模轨迹数据。
技术实现要素:
7.本发明的内容是提供一种分布式轨迹流伴随模式挖掘方法,其能够克服现有技术的某种或某些缺陷。
8.根据本发明的一种分布式轨迹流伴随模式挖掘方法,其包括以下步骤:
9.一、数据预处理:根据地理区域的划分将数据划分为多个区域,得到分区边界,输出分区编号;
10.二、监测不断到达的数据流;
11.三、当前快照创建时间窗口,窗口大小为当前快照时间;
12.四、根据分区编号执行keyby算子,利用哈希函数分发到不同的节点,其中具有相同分区编号的对象被发送到相同的节点;
13.五、map阶段:每个节点对接收到的当前分区的数据执行基于方向的密度聚类,并得到当前分区的密度聚类簇集合;
14.六、第一个recude阶段:对map阶段得到的密度聚类簇集合汇聚到主节点进行聚类合并,输出合并后簇的集合;
15.七、第二个reduce阶段,对第一个reduce合并后簇的集合执行模式挖掘,与候选伴随集合取交集,生成新的候选伴随,并输出当前快照的伴随模式结果。
16.作为优选,步骤一中,分区过程如下所示:
17.(1)计算轨迹数据集的最大和最小经纬度,建立轨迹数据集的最小外接矩形rectangle;
18.(2)对rectangle均匀划分,使每个分区中包含相同数量的对象,并根据下式公式分别得到分区位置编号n
i
;
19.给定轨迹流快照s
i
中轨迹的集合x
i
和y
i
表示对象o
i
在快照s
i
的空间坐标,list为有序列表存储集合中所有对象的x轴坐标,则分区边界的位置
[0020][0021]
其中size表示list的容量,n表示分区的数量,且0≤i<n;
[0022]
(3)由n
i
生成对应的分区region
i
,其中region
i
的范围为(n
i
‑
r,n
i+1
+r),这里令r=ε,ε为密度连接的距离阈值。
[0023]
作为优选,步骤五中,密度聚类采用adbscan算法,adbscan算法是融合角度的密度聚类算法,具体为:
[0024]
[0025][0026]
算法中的距离度量采用欧式距离;其中序号2开始遍历数据集d的所有点;序号3判断当前遍历到的对象是否已经被访问过,如果被访问过则跳过此对象访问下一个对象,如果未被访问过则标记为核心对象;序号4设置p为已访问,找出与点p距离不大于r,且角度差不大于δ
a
的所有点集合n。序号5至序号21如果p的邻域范围内对象数满足δ
s
则遍历p的邻域集合n;序号7至序号14遍历判断如果n内的对象p'已经被访问,判断是否是噪声点,如果是噪声点说明p'不属于任何簇,将p'标记为非噪声点并聚类到当前簇;序号15至序号19如果p'未被访问,则查找p'的邻域n'并加入n中;序号22如果p的邻域内对象数量小于δ
s
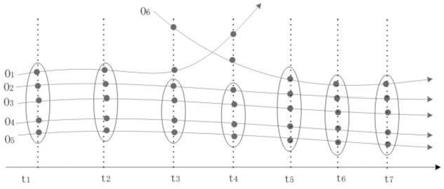
则将p标记为噪声点;序号25最终返回聚类后的簇的集合
[0027]
作为优选,步骤六中,聚类合并采用mc算法,具体为:
[0028][0029]
序号1和序号2,第一个指针停留在第i个簇,第二个指针j遍历i之后的簇。序号3判断后遍历到的簇是否存在第一个簇region的相邻region中,如果不存在继续查找下一个簇,如果存在则序号4至序号6若两个簇c
i
和c
j
有相同对象,则将c
j
中的所有对象添加到c
i
中,并从c中移除c
j
。
[0030]
作为优选,步骤七中,模式挖掘采用pcpm算法,pcpm算法为并行的伴随模式挖掘算法,具体为:
[0031]
[0032][0033]
序号1初始化新的候选伴随集合r',r'的初始值为空;序号2至序号16通过取交集来增加候选伴随,其中序号3创建多线程,加快取交集的速度,序号5至序号7使用定义10从候选集中删除相交对象,并在下一个相交前检查其剩余大小,提前结束数量过少的候选伴随与簇的交叉过程;序号8及时删除已经取过交集且剩余大小r.size
‑
δ
s
的候选伴随;序号9至序号10将交叉后满足阈值δ
s
的结果存储在候选伴随模式集合中,在存储过程中为集合r'加锁,防止两个线程同时写入导致数据错误;序号11至序号13如果候选伴随模式集合满足时间阈值则被实时输出;序号18至20使用定义11检查是否有一个包含相同对象但持续周期较长的候选r
i
吗,如果没有则将c
j
添加到候选伴随集合中。
[0034]
本发明基于方向的分布式聚类和并行的伴随模式挖掘,提出了新的分布式流聚类算法和模式挖掘算法。
[0035]
本发明的有益效果主要有以下几个方面:
[0036]
(1)基于轨迹数据的地理信息设计分布式策略,均匀划分地理区域,将数据分发到不同的节点;并设计聚类合并算法mc(merge cluster),合并聚类结果。
[0037]
(2)根据轨迹数据的特性,抽取轨迹数据的方向信息,设计基于方向的adbscan(angle
‑
dbscan)算法,聚合方向且位置相近的轨迹点。
[0038]
(3)在伴随模式匹配阶段提出pcpm(parallel companion pattern mining)算法,设计多线程的匹配方式和并行的模式匹配,提高伴随模式挖掘效率。
[0039]
(4)对以上内容进行整合,基于flink分布式大数据流处理平台,设计了分布式轨
迹流伴随模式挖掘框架dcpfs,并以谷歌生活数据集和成都市交通数据为例进行验证,本算法具有更快的处理速度。
附图说明
[0040]
图1为实施例1中模式挖掘的过程示意图;
[0041]
图2为实施例1中轨迹流伴随模式挖掘框架示意图;
[0042]
图3为实施例1中dcpfs挖掘伴随对象示例图;
[0043]
图4为实施例1中轨迹数据集的分区过程示意图;
[0044]
图5为实施例1中dbscan算法的聚合结果示意图;
[0045]
图6为实施例1中mc算法的合并过程示意图;
[0046]
图7为实施例1中交叉的过程示意图;
[0047]
图8为实施例1中在geolife上eps对伴随模式挖掘性能的影响示意图;
[0048]
图9为实施例1中在taxi上eps对伴随模式挖掘性能的影响示意图;
[0049]
图10为实施例1中在geolife上minpts对伴随模式挖掘性能的影响示意图;
[0050]
图11为实施例1中在taxi上minpts对伴随模式挖掘性能的影响示意图;
[0051]
图12为实施例1中在geolife上angle对伴随模式挖掘性能的影响示意图;
[0052]
图13为实施例1中在taxi上angle对伴随模式挖掘性能的影响示意图;
[0053]
图14为实施例1中在geolife上duration对伴随模式挖掘性能的影响示意图;
[0054]
图15为实施例1中在taxi上duration对伴随模式挖掘性能的影响示意图;
[0055]
图16为实施例1中在taxi数据集上组合参数对伴随模式挖掘性能的影响示意图。
具体实施方式
[0056]
为进一步了解本发明的内容,结合附图和实施例对本发明作详细描述。应当理解的是,实施例仅仅是对本发明进行解释而并非限定。
[0057]
实施例1
[0058]
先将对轨迹流的伴随模式挖掘框架做一个概述。
[0059]
示例1:图1展示模式挖掘的过程,其中包含五个对象在四个快照中的位置,假设集合对象数量阈值为4,时间阈值为3,{o1,o2,o3,o4,o5}在起始时间相互接近且向同一方向运动,o1在t3位置由于角度与其他对象的角度偏差大于阈值而脱离集合,其中{o2,o3,o4,o5}数量和时间阈值在t4时刻被实时输出。随着时间的推移,o6在t5时刻被加入到集合中,由于在t5时刻不满足时间阈值,包含o6的集合对象只输出{o2,o3,o4,o5},当到达t7时刻{o2,o3,o4,o5,o6}满足时间阈值被输出。
[0060]
定义1轨迹流:一条轨迹流s,包含一系列的快照集合s={s1,s2,...,s
i
,...,s
n
}其中s
i
是在时间戳i的快照s。
[0061]
定义2快照:每个快照s
i
包含移动对象的集合其中x
i
,y
i
表示对象o
i
在快照s
i
的空间坐标。
[0062]
定义3密度可达:令o表示一个快照中对象的集合,ε表示距离阈值,μ表示密度阈值则n
ε
={o
j
∈o|dist(o
i
,o
j
)≤ε}。如果且|n
ε
|≥μ从对象o
i
到对象o
j
是密度可达的。
[0063]
定义4密度连接:令o表示一个快照中对象的集合,如果存在对象的连接链
{o1,...,o
n
}∈o其中o1=o
j
,o
n
=o
i
,从o
i
到o
i+1
是密度可达的,则o
i
与o
j
是密度相连的。
[0064]
定义5快照聚类:给定一个快照s
i
,定义表示快照聚类的集合,其中是快照s
i
的第k个簇。
[0065]
定义6伴随模式:令δ
s
表示数量阈值,δ
t
表示周期阈值,一组轨迹对象r被称为伴随模式,如果满足以下条件:
[0066]
(1)r的成员之间是密度连接的在时间周期t内,其中t≥δ
t
;
[0067]
(2)r的成员数量r.size≥δ
s
。
[0068]
定义7候选伴随:令δ
s
表示数量阈值,δ
t
表示周期阈值,一组轨迹对象r'被称为候选伴随,如果满足以下条件:
[0069]
(1)r'的成员之间是密度连接的在时间周期t内,其中t<δ
t
;
[0070]
(2)r'的成员数量r'.size≥δ
s
;
[0071]
我们引入伴随模式的框架和算法,表1列出了本实施例所使用到的符号。
[0072]
表1符号定义
[0073][0074]
分布式挖掘框架
[0075]
聚类操作在伴随模式挖掘中占有重要的地位,且在整个过程中消耗了大量的时间。在真实场景中,轨迹数据集包含大量的快照数,并且随着时间的推移快照被移动对象不断产生,在面对城市级别的大规模轨迹数据,基于单机模式挖掘算法难以做到快速响应。现有的分布式部署方案被应用于聚类阶段使得响应速度提升数倍。目前的聚类方法对每个快照下的对象进行聚类,各快照下的聚类操作互不影响,但是在轨迹数据实时到达的场景中,需要对当前的快照及时聚类,以快照为范围的聚类的方式并不适用。考虑到现实场景中距离较远的对象很难会被聚类为一个簇,因此对当前地理范围内的位置信息划分为多个区域,每个区域赋予唯一的编号,相同区域中的对象产生的信息被收集到同一台节点处理,在不同区域中移动的对象产生的位置信息由不同的节点处理。每个节点对收集到的轨迹点执行聚类操作,由于移动对象一般会朝着某一方向前进,运动方向相差过大的对象被聚类到一起不具有实际意义反而增加了聚类的冗余。因此在聚类阶段考虑移动对象的角度因素,削减了聚类结果的规模,减少了下一阶段聚类合并和模式挖掘中需要对比的对象数量和时间消耗。在地理分区的边缘,由于地理划分的原因,可能存在距离相近的对象被聚类到不同的簇中,因此需要扫描所有簇将存在相同对象的簇合并为一个簇。最后,当前快照的所有簇与上一个快照的所有簇进行对比,如果存在交叉的对象,交叉的结果会被存储为候选的伴随模式,但候选伴随模式持续存在且满足快照数量时被确定为伴随模式。由于每个快照中
的簇数量有限,交叉操作仅需要很少的时间开销。因此充分利用当前计算机的多核特性,使用并行方案执行交叉操作,提高了交叉过程的效率。
[0076]
轨迹流伴随模式挖掘框架如图2所示,包含数据分区、分布式聚类和模式挖掘三个阶段。为满足分布式聚类的需求,需要对轨迹数据分区,图2中(a)部分根据轨迹数据的地理位置,划分多个分区。图2中(b)部分对接收到按分区执行keyby操作,将相同分区内的数据发送到同一个节点。图2中(c)部分为分布式处理过程,将框架最耗时的adbscan聚类操作分发给多个节点执行,当数据量增加只需要增加节点数量即可满足快速响应的需求。图2中(d)部分聚合所有节点的聚类簇,合并拥有相同对象的簇。图2中(e)部分由于模式挖掘中的交叉操作数据量有限,因此仅单节点处理足以满足要求,同时为了提高交叉的效率,采用多线程方式,并行执行交叉步骤。
[0077]
dcpfs框架算法流程如算法1所示。序号1至序号2为数据预处理阶段,根据地理区域的划分将数据划分为多个区域,其中区域的数量等于分布式节点的数量。序号3中监测不断到达的数据流。序号4至序号15为当前快照创建时间窗口,窗口大小为当前快照时间。序号5至序号7根据第一步中的到的每个对象的分区编号执行keyby算子,利用哈希函数分发到不同的节点,其中具有相同分区编号的对象被发送到相同的节点。序号8至序号10为map阶段,每个节点对接收到的当前分区的数据执行基于方向的密度聚类,并得到当前分区的密度聚类簇集合序号11至序号13为第一个recude阶段,对map阶段的到的聚类簇集合汇聚到主节点进行聚类合并,输出合并后簇的集合序号14至序号16为第二个reduce阶段,对第一个reduce合并后簇的集合执行模式挖掘算法,与候选伴随集合r取交集,生成新的候选伴随,并输出当前快照的伴随模式结果r'。
[0078]
算法1:dcpfs框架
[0079][0080]
图3给出了dcpfs框架挖掘伴随对象的示例。在该示例中,首先根据监测区域将数据划分为三个分区,从三个分区产生的对象集合{a,b,c,d,e,f},{f,g,h,i,j,k},{k,l,m,n,p,1}被标记为不同的分区编号n1,n2,n3。我们将标记为n1,n2,n3的数据集分别发送到不同的节点。{a,b,c,d,e,f},{f,g,h,i,j,k},{k,l,m,n,p,1}分别在节点1,节点2和节点3被执行adbscan密度聚类操作分别得到聚类结果簇{a,b,c},{d,e,f},{f,g,h},{i,j,k},{k,l,m},{n,p,q}其中每个簇中的对象之间满足定义4。可以看到{d,e,f}和{f,g,h},{i,j,k}和{k,l,m}存在相同的对象。因此将{a,b,c},{d,e,f},{f,g,h},{i,j,k},{k,l,m},{n,p,q}汇集到节点1执行mc聚类合并操作,{d,e,f}与{f,g,h}被合并为{d,e,f,g,h},{i,j,k}与{k,l,m}被合并为{i,j,k,l,m},最终得到四个簇{a,b,c},{d,e,f,g,h},{i,j,k,l,m},{n,p,q}。在执行pcpm模式挖掘操作时,由于快照模式挖掘的结果{a,b,c},{e,f,g,h,i},{j,k,l}被缓存在内存中,于是从内存中取出{a,b,c},{e,f,g,h,i},{j,k,l}与当前聚类合并后的簇{a,b,c},{d,e,f,g,h},{i,j,k,l,m},{n,p,q}对比并相互取交集得到{a,b,c},{e,f,g,h},{j,k,l}。由于{n,p,q}是新产生的簇且与缓存中的簇没有相同对象,因此{a,b,c},{e,f,g,h},{j,k,l},{n,p,q}满足定义7加入并替换缓存对象。且如果在缓存中存在簇满足定义6,会被立即输出为伴随对象。
[0081]
数据分区
[0082]
执行分布式聚类算法,则必须对数据分区。
[0083]
定义8:给定轨迹流快照s
i
中轨迹的集合x
i
和y
i
表示对象o
i
在快照s
i
的空间坐标,list为有序列表存储集合中所有对象的x轴坐标,则分区边界的位置
[0084][0085]
其中size表示list的容量,n表示分区的数量,且0≤i<n。
[0086]
分区过程如下所示:
[0087]
(1)计算轨迹数据集的最大和最小经纬度,建立轨迹数据集的最小外接矩形rectangle;
[0088]
(2)对rectangle均匀划分,使每个分区中包含相同数量的对象,并根据定义8分别得到分区位置编号n
i
。
[0089]
(3)由n
i
生成对应的分区region
i
,其中region
i
的范围为(n
i
‑
r,n
i+1
+r),这里令r=ε,ε为密度连接的距离阈值。
[0090]
根据数据划分的结果,不同的region
i
被发送到不同的分布式节点,由于每个region
i
中的数据容量相近,所以使得每个节点处理相同的数据量,保证了节点间的负载均衡。
[0091]
图4详细介绍了轨迹数据集的分区过程:首次计算得到轨迹数据集的最大和最小经纬度位置(x1,y1)和(x2,y2),并建立最小外接矩形rectangle;其次对rectangle的长边划分,根据分布式节点数量n,计算得到n1~n5的位置,最后由r计算得到region1~region4的范围为(n1‑
r,n2+r)~(n4‑
r,n5+r)。
[0092]
adbscan算法
[0093]
图5显示了dbscan算法的聚合结果。首先,在每个从节点上,找出核心对象,方框点表示了核心对象的位置,圆形区域表示其邻域范围。其次,从某一核心对象出发,产生密度可达的聚类簇,当访问完所有点则结束计算。adbscan算法在dbscan算法的基础上,计算当前快照与上一个快照位置向量与正北方向的夹角,从而加入方向维度信息。adbscan要求密度相连的群体对象中,核心对象与邻域范围内的点角度差小于阈值δ
a
。下面给出了角度差的计算公式:
[0094]
定义9:给定两个相邻快照s1,s2,(x1,y1)和(x2,y2)是对象o在快照s1,s2的坐标,轨迹向量与正北方向的夹角可以表示为:
[0095][0096][0097]
定义10:给定快照s
i
两个轨迹点o1,o2,两个轨迹点的角度差可以表示为:
[0098]
[0099]
定义11:adbscan:给定快照s
i
,对于则o
i
与o
j
之间密度连接且满足角度差angledf(o
i
,o
j
)<δ
a
,其中是快照s
i
的第k个簇,δ
a
是密度连接的角度阈值。
[0100]
adbscan算法如算法2所示,算法中的距离度量采用欧式距离。其中序号2开始遍历数据集d的所有点;序号3判断当前遍历到的对象是否已经被访问过,如果被访问过则跳过此对象访问下一个对象,如果未被访问过则标记为核心对象。序号4设置p为已访问,找出与点p距离不大于r,且角度差不大于δ
a
的所有点集合n。序号5至序号21如果p的邻域范围内对象数满足δ
s
则遍历p的邻域集合n。序号7至序号14遍历判断如果n内的对象p'已经被访问,判断是否是噪声点,如果是噪声点说明p'不属于任何簇,将p'标记为非噪声点并聚类到当前簇。序号15至序号19如果p'未被访问,则查找p'的邻域n'并加入n中。序号22如果p的邻域内对象数量小于δ
s
则将p标记为噪声点。序号25最终返回聚类后的簇的集合
[0101]
算法2 adbscan//融合角度的密度聚类算法
[0102]
[0103][0104]
adbscan算法需要访问当前快照中的所有对象,区域查询的次数决定了算法的时间复杂度,adbscan的时间复杂度为o(n2),但是由于加入了角度维度,因剪枝无用的对象而生成范围更小的簇,执行下一步的聚类合并和模式挖掘节省了时间和空间上的开销。
[0105]
mc算法
[0106]
如图3中所示椭圆区域内的两个簇c1和c2,如果在单机运行环境中c1和c2由于密度可达,会被划分为一个簇。然而在分布式环境中,c1和c2被划分为两个区域分别属于region1和region2。因此需要对分布式聚类结果聚合,将相同的簇合并。下面给出了mc的定义及计算方法:
[0107]
定义12:当前快照s
i
下对于给定的两个簇如果如果则使得且因此那么
[0108]
与单纯的按照分区聚类相比,mc算法有效的解决了分布式聚类中大簇被分割成多个簇造成结果不准确的问题。同时通过仅对比相邻分区的中的对象,减少了70%的数据间的对比,有效提升了算法的效率同时保证了算法的准确性。
[0109]
算法3 mc//聚类合并算法
[0110]
[0111][0112]
聚类合并算法mc的具体过程如算法3所示。序号1和序号2,第一个指针停留在第i个簇,第二个指针j遍历i之后的簇。序号3判断后遍历到的簇是否存在第一个簇region的相邻region中,如果不存在继续查找下一个簇,如果存在则序号4至序号6若两个簇c
i
和c
j
有相同对象,则将c
j
中的所有对象添加到c
i
中,并从c中移除c
j
。重复上述过程。
[0113]
令n1表示分区的数量,n2表所有示集合中簇的数量,m表示当前簇的平均大小。则算法2的时间复杂度是o(n
22
/n1*(m
12
)),由于簇的数量在可控范围内,需要比较每个簇中的对象,因此mc的时间复杂度为o(n2)。
[0114]
图6展示了聚类的合并过程。其中region1包含簇c1,region2包含簇c2,region3包含簇c3。c1包含对象{o1,o2,o3,o4},c2包含对象{o2,o3,o5,o6,o7},c3包含对象{o6,o7,o8,o9,o
10
}。region1与region2相邻,region2与region3相邻,region1与region3不相邻。因此c1与c2相交得到共同对象{o2,o3}。因此合并c1与c2并去除重复的对象,合并后的簇包含对象{o1,o2,o3,o4,o5,o6,o7}。由于c1与c3在不相邻的区域中,因此c1不与c3取交集。因为c2属于region2与region3相邻,因此c1和c2合并后与c3取交集。聚类合并过程依次从region1到region3扫描每个区域中的簇,将有相同元素的簇依次合并,合并后的簇与剩余的簇取交集,并将拥有相同对象的簇合并。
[0115]
伴随模式挖掘
[0116]
从节点的聚类结果汇集到主节点,将具有相同对象的簇合并,当前时间的簇与候选伴随取交集,当交集的结果达到阈值δ
s
被存储为到的候选伴随。一旦候选伴随的周期超过阈值δ
t
,会被立即输出为伴随对象。同时,一旦候选的规模小于数量阈值δ
s
,就不再是合格的候选伴随,应该从内存中删除。为了加快算法响应的速度,在候选和当前时间交叉阶段,充分利用单节点多核的特性,设计了并行方式,采用线程池控制并行度,为了防止写入错误,集合添加同步锁,保证交叉阶段的准确性。
[0117]
定义13:令r表示候选伴随,δ
s
表示阈值大小,如果r中存在超过size(r)
‑
δ
s
的对象已经出现在交叉簇中,r和剩余的簇交叉不会产生任何大于δ
s
的结果。
[0118]
证明:当且仅当每个对象在每个快照中只出现一次且只属于一个簇。如果存在超过size(r)
‑
δ
s
对象出现在已经交叉的簇中,甚至最好的情况所有剩余对象在单一的簇中,交叉结果仍然小于size(r)
‑
(size(r)
‑
δ
s
)=δ
s
。
[0119]
定义14:封闭候选:对于一个候选伴随r
i
,如果不存在任何候选r
j
,使得使得且r
i
的周期小于r
j
的周期,则r
i
是一个封闭候选。
[0120]
算法4:pcpm//并行的伴随模式挖掘算法
[0121][0122][0123]
算法4列出了伴随模式挖掘阶段算法pcpm。序号1初始化新的候选伴随集合r',r'的初始值为空。序号2至序号16通过取交集来增加候选伴随,其中序号3创建多线程,加快取交集的速度,序号5至序号7使用定义10从候选集中删除相交对象,并在下一个相交前检查其剩余大小,提前结束数量过少的候选伴随与簇的交叉过程。序号8及时删除已经取过交集且剩余大小r.size
‑
δ
s
的候选伴随。序号9至序号10将交叉后满足阈值δ
s
的结果存储在候选伴随模式集合中,在存储过程中为集合r'加锁,防止两个线程同时写入导致数据错误。序号
11至序号13如果候选伴随模式集合满足时间阈值则被实时输出。序号18至20使用定义11检查是否有一个包含相同对象但持续周期较长的候选r
i
吗,如果没有则将c
j
添加到候选伴随集合中。
[0124]
令n1表示对象的数量,n2表示候选伴随集合r的大小,算法4的时间复杂度为o(n1*n2)。因此dcpfs算法的时间复杂度为
[0125]
证明:在聚类阶段,算法需要的时间复杂度去执行密度聚类。在聚类合并阶段mc的时间复杂度为算法在交叉阶段,假设m1是簇的数量,m2是候选伴随的数量,l1表示簇的平均大小,l2表示候选簇的平均大小,则单个交叉任务的时间复杂度为l1*l2。假如m1*l1=n1,m2*l2=n2,因此交叉阶段的时间复杂度为o(n1*n2),总的时间复杂度为由于包含修剪策略和并行算法,因此可以节省大约50%的时间。
[0126]
图7展示了交叉的过程。假设每个快照包含1个时间戳,大小阈值δ
s
为3,时间阈值δ
t
为4。对象当快照到达,s1中的两个簇作为候选伴随,即r1和r2。快照s2到达产生新簇并与s1取交集,并产生新的候选伴随r3。快照s3到达,由于r2与快照s3取交集,被剪枝为{o8,o9,o
10
}。快照s4到达,由于r2与快照s4取交集,小于大小阈值δ
s
,因此r2被删除。最后,由于r1满足时间阈值δ
t
,算法输出{o1,o2,o3,o4},在此过程中r最大包含19个对象。
[0127]
实验
[0128]
实验数据
[0129]
如表2所示,本实施例使用两组真实场景的数据集:
[0130]
taxi.该数据集为成都市2014年8月3日包含13640辆出租车超过2千万条gps记录,其中剔除了从凌晨0点到凌晨6点之间的数据;
[0131]
geolife.该数据集保存了182名用户在2008年4月1日的旅游记录.对于每个用户,收集gps信息。
[0132]
表2轨迹数据集信息
[0133][0134]
实验环境
[0135]
本实验运行在拥有5个节点的flink
[22]
集群上,每个节点的操作系统版本为centos7.0,处理器为6
‑
core inter xeon cpu gold 5117cpu@2.00ghz,rom和ram分别为400gb和20gb。java虚拟机采用jdk1.8,分布式版本为flink1.7.2,并搭建在hadoop2.7.2的yarn上。所有代码都是用java语言编写,使用编辑器为idea2020.1,使用maven4.0.0配置相关依赖。本实施例的baseline
[14]
实验和数据由主节点单独运行和处理,相当一台独立的的运行设备。
[0136]
数据预处理
[0137]
本实施例对原始数据集的时间戳重新编号,使时间戳从1开始,并设置固定采样率为30秒。在处理缺失数据时,使用线性插值法填充缺失值,并删减掉比固定频率小的多余数据。根据同一id当前时间与下一个时间点的相连向量计算与正北方向的夹角(0
°
~360
°
)。然后将数据集进行离线地理划分。处理后的数据集包含如下信息:用户id,纬度,经度,时间
戳,角度,分区(例如6136,30.663005,104.089374,810,202,11)。
[0138]
实验对比及分析
[0139]
文本设置了多个参数,用来评估各参数对baseline和dcpfs性能的影响并对各参数进行试验验证。参数设置如表3所示。
[0140]
表3实验参数设置
[0141][0142]
其中eps表示最小聚类半径,minpts表示最小聚类数量,duration表示伴随模式的最小周期,angle表示角度阈值。
[0143]
为了更加准确的评估算法在每个快照的时间效率,本实施例采用平均快照处理时间的方式,以下给出了伴随模式挖掘框架在每个快照的平均快照处理时间的计算公式:
[0144][0145]
算法效率实验
[0146]
在实验之前,首先使用采样点数据测试dcpfs的挖掘数量与baseline方法的挖掘数量一样,证实了dcpfs计算结果的正确性。在实时应用的场景中,快照可能在1~2秒内被送达,因此为了满足实时性的要求,伴随模式的挖掘需要在下一个快照被送达之前做出响应。为了检测本实施例提出的分布式方法的高效性,本实施例与baseline方法进行了比较。其中,由于geolife在17278个快照中分布76220个轨迹点,平均每个快照包含约5个轨迹点;在taxi中,2160个快照中分布27363616个轨迹点,平均每个快照中包含约12668个轨迹点,geolife数据较taxi更加稀疏,因此仅需要极少的时间就可以做出响应。
[0147]
图8和图9表示eps的变化对伴随对象发现效率的影响。
[0148]
在图8中,geolife数据集中baseline最少响应时间约1毫秒,最多响应时间约4毫秒,平均响应时间约为3毫秒;而dcpfs的最少响应时间约0.4毫秒,最多响应时间约1.3毫秒,平均响应时间约为0.6毫秒。因此dcpfs比baseline方法减少了约75%的时间消耗,这是因为分布式处理五台节点的处理速度远远超过单机处理的速度,而分布式处理需要增加聚类合并阶段的时间消耗,而模式挖掘阶段通过并行处理方案小规模的缩短了dcpfs的整体时间,很好的弥补了聚类合并阶段的缺陷。可以看出,dcpfs和baseline对eps的值较敏感,当eps为100米时dcpfs和baseline可以在最短的时间内做出响应,当eps的值为200时,baseline比eps的值为100时响应时间增加了2倍。这是由于geolife数据集中,旅行团队之间的距离一般在较近的范围内活动,而由于旅行者分别会参与到不同的游玩项目中相互之间又有一定的距离。eps在geolife的合理设置可以有效减少不必要的时间消耗。
[0149]
在图9中,可以看到taxi数据集中当eps的值是10米时,baseline最少响应时间约600毫秒,随着eps的值增大,baseline的响应时间逐渐增加,eps的值增大到90米时,baseline需要7000毫秒的时间做出响应,这远远超出了实时响应的时间限制。而dcpfs的最少响应时间是当eps的值为3米时约为200毫秒,最长响应时间是当eps的值为90米时约为400毫秒;可以看到随着eps的增加,dcpfs的处理时间缓慢增加,但依然可以在一秒之内做
出响应。这是由于taxi数据集来自真实的交通车辆数据,对象密度较大,而baseline的单节点难以处理,从而导致严重的超时现象。综上所述,eps在taxi数据集上的影响,随着eps的增大,模式挖掘的响应时间逐渐增加。
[0150]
图10和图11表示minpts的变化对伴随对象发现效率的影响。
[0151]
在图10中,可以看到geolife数据集中当minpts的值为5时,baseline响应时间约5毫秒,随着minpts的值增加baseline的响应时间逐渐缩短,当minpts的值增大到20时,baseline仅需要约1毫秒的时间做出响应。而dcpfs最大响应时间是当minpts的值是5时约为1.2毫秒,最少响应时间是当minpts的值是16时约为0.3毫秒。在minpts的值较小时dcpfs比baseline方法减少了约70%的时间消耗,随着minpts值的增大,dcpfs比baseline方法在minpts的值为20时仅减少了约50%的时间消耗,这是因为,在adbscan阶段,minpts的值较小时会得到小而多的簇,随着minpts的值增大会得到大而少的簇,这导致会产生多个簇中的对象属于不同的分区,增加了聚类合并阶段的时间消耗。可以看到,dcpfs和baseline对eps的值较敏感,随着minpts的值增大,响应时间逐渐缩短。
[0152]
在图11中,可以看到taxi数据集中当minpts的值是2时,baseline大约需要23000毫秒做出响应,远远超出了实时伴随模式挖掘的时间要求。这是在adbscan阶段,minpts的值为2会挖掘大量无用的小簇,带来的大量的时间开销。然而dcpfs将小簇分布在多个节点,有效的分散了主节点的压力。说明dcpfs在minpts变化具有很好的稳定性。在minpts的值为8、15、25、40时,baseline的值分别为963毫秒、667毫秒、598毫秒、552毫秒;dcpfs的值分别为333毫秒、346毫秒、269毫秒、339毫秒。可以看到dcpfs比baseline方法效率提升了约50%,因为大量冗余的小簇使得聚类合并和交叉阶段的时间消耗增加,降低了dcpfs的效率。
[0153]
图12和图13表示angle的变化对伴随对象发现效率的影响。
[0154]
在图12中,geolife数据集中baseline的最低响应时间是当angle的值为40时约为3.1毫秒,最高响应时间是当angle的值为20时约为3.7毫秒;dcpfs的最低响应时间是当angle的值为20时,约为0.4毫秒,最高响应时间是当angle的值10时为约为1.3毫秒。可以看到,baseline和dcpfs对angle的变化表现的不敏感。这是因为,角度设置值无论怎样发生变化adbscan依然需要扫描整个快照内的对象。相反,通过设置不同的角度值,可以发现更符合真实场景的簇,剪枝方向差过大的对象减少簇的冗余。总而言之,在geolife数据集上,dcpfs比baseline平均减少了约75%的时间消耗。
[0155]
图13中,taxi数据集中baseline的最低响应时间是当angle的值为5时约为523毫秒,最高响应时间是当angle的值为15时约为1000毫秒。dcpfs的最低响应时间是当angle的值为15时约为320毫秒,最高响应时间是当angle的值为5时约为352毫秒。如图中所示,在angle的值为5时,dcpfs仅仅比baseline提升了约30%的时间效率;这是因为当angle的值为5时,adbscan阶段由于角度值设置过小,会产生较多的小簇,在dcpfs中较多的小簇会增加聚类合并阶段和模式挖掘阶段的时间消耗,进而影响dcpfs的整体性能。但从总体性能看,angle的变化对baseline影响不大,尤其是dcpfs在不同的angle时表现稳定。因此,可以看到在taxi数据集上,baseline和dcpfs对angle的变化表现的依然不敏感。总而言之,在taxi数据集上,除了因angle值过小引起的小簇现象,dcfps比baseline减少了约70%的时间消耗。
[0156]
图14和图15表示duration的变化对伴随对象发现效率的影响。
[0157]
图14中,可以看到geolife数据集中当duration的值80时,baseline最高响应时间是duration的值为80时约为3.4毫秒,在duration的值为80之后,随着duration的值增加baseline的响应时间逐渐缩短,当duration的值增大到140时最低响应时间约2.4毫秒。而dcpfs的最高响应时间是当duration的值为80时约为1.3毫秒,随着duration的值增加dcpfs的响应时间逐渐缩短,最低响应时间是duration的值为140时约为0.4毫秒。在duration的值为可以看到随着duration的增大,算法的时间消耗逐渐降低;这是因为duration的值增大,会使得一些较短的伴随模式被剪枝,挖掘出更长的伴随模式,使得算法的时间性能提升。总而言之,在geolife数据集上,不同的duration下dcpfs比baseline平均减少了约70%的时间消耗。
[0158]
图15中,可以看到taxi数据集中当duration的值为10时baseline最低响应时间约963毫秒,当duration的值为5时baseline的最高响应时间约1024毫秒。当duration的值为10时dcpfs的最低响应时间约为355毫秒,当duration的值为80时dcpfs的最高响应时间约为369毫秒。可以看到baseline和dcpfs对duration的变化在taxi数据集上不敏感,这是由于taxi数据集中包含较多的长轨迹,较小的duration对长轨迹依然能做出响应。综上所述,数据集中长轨迹较多,数据量较大时,duration的值变化dcpfs的表现更加稳定。在taxi数据集上不同的duration下dcpfs比baseline平均减少约70%的响应时间。
[0159]
在图16中,我们根据taxi数据集真实的情况设置了合理的参数组合,用来评估在大规模轨迹数据处理情况中dcpfs和baseline的性能差异。本次实验共设计了五个参数组合,其中参数组合如下表4所示:
[0160]
表4 taxi数据集上的参数组合
[0161][0162]
从图16中可以看到,当取参数组合a时baseline的最低响应时间是1021毫秒,当取参数组合d时baseline的最高响应时间是1066毫秒。当取参数组合a时dcpfs的最低响应时间是329毫秒,当取参数组合d时dcpfs的最高响应时间是355毫秒。可以看到根据真实的场景设置合理的参数可以使baseline和dcpfs的响应时间稳定。综合以上实验表明,dcpfs算法在大规模数据集上表现良好,可以在毫秒级别内对当前快照的数据进行处理并做出响应。且dcpfs在各种参数测试下表现稳定,具有更好的鲁棒性。
[0163]
总结
[0164]
本实施例针对轨迹流伴随模式挖掘实时响应问题,提出了一个基于分布式的轨迹流伴随模式框架。首先对该框架的整体结构进行介绍;其次列举了轨迹数据流和伴随模式的相关定义;再次根据数据的地理分布设计了数据分区策略,在分布式阶段设计了融合角度的密度聚类算法;为了解决分布式聚类中因数据分区导致的聚类结果缺失问题,设计了聚类合并算法对聚类结果进行合并,并这几了剪枝策略;在模式挖掘阶段设计了并行挖掘方法,有效的提高了模式挖掘的效率。最后使用真实世界的数据集对运行效率进行了评估。
实验结果表明,dcpfs在轨迹流的伴随模式挖掘相比baseline时间消耗大大降低,可以满足大规模轨迹数据实时响应的需求。
[0165]
以上示意性的对本发明及其实施方式进行了描述,如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1