一种基于卷积神经网络的荞麦病害识别方法
1.本发明涉及植物病害识别技术领域,具体涉及一种基于卷积神经网络的荞麦病害识别方法。
背景技术:
2.荞麦(fagopyrum spp.)是一种营养丰富的重要杂粮,其含有蛋白质、纤维素、糖类和抗氧化物质芦丁等对人体健康非常有益的成分,且种植适应性强,耐寒冷、贫瘠,是具有开发潜力的优质作物资源。然而,病害导致荞麦的产量与品质受到极大影响,使得其营养价值、饲用品质等低下。荞麦的病害类型包括:荞麦斑枯病、荞麦菌核病、荞麦立枯病、荞麦轮纹病、荞麦霜霉病、荞麦褐斑病、荞麦病毒病、荞麦白霉病等。因此,准确及时对荞麦病害情况作出辨别,是预防和控制的重要手段。
3.现有的荞麦物病害识别手段主要是人工甄别,这种识别方式对专业知识要求高,且效率较低,往往容易错过最佳的控制时期。为此,公开号为cn111967424a的中国专利公开了《一种基于卷积神经网络的荞麦病害识别方法》,其首先,采用基于mser和cnn结合的方法对荞麦病害区域进行检测,从图像中分离出病害区域与非病害区域;然后,把病害区域图像送入基于inception结构改进以及采用基于余弦相似度卷积方式的卷积神经网络中进行训练和识别。
4.上述现有方案中的荞麦病害识别方法通过mser(区域特征提取)提取荞麦病害区域的特征图像;然后通过cnn(卷积神经网络)基于荞麦特征图像完成病害识别。其中,在卷积神经网络结构中,为了训练出一个很好的识别模型,需要对卷积神经网络中的参数需要优化以使得损失函数的值最小,现有方案采用的参数优化方式是梯度下降算法(gradient descent algorithm,gda)。然而,申请人发现梯度下降算法很难充分开发利用gpu、cpu向量化的能力,并且当函数有多个坡度的时,梯度下降算法难以保证全局最小值,很容易陷入局部最优,当参数很多的时候,训练的时间会成倍增长,导致识别模型的训练效果和训练效率均偏低,进而导致荞麦病害识别的准确性低且时间成本高。因此,如何设计一种用于荞麦病害识别且能够兼顾识别模型训练效果和训练效率的荞麦病害识别方法是亟需解决的技术问题。
技术实现要素:
5.针对上述现有技术的不足,本发明所要解决的技术问题是:如何提供一种用于荞麦病害识别且能够兼顾识别模型训练效果和训练效率的荞麦病害识别方法,从而能够有效提升荞麦病害识别的准确性,并降低荞麦病害识别的时间成本。
6.为了解决上述技术问题,本发明采用了如下的技术方案:
7.一种基于卷积神经网络的荞麦病害识别方法,包括以下步骤:
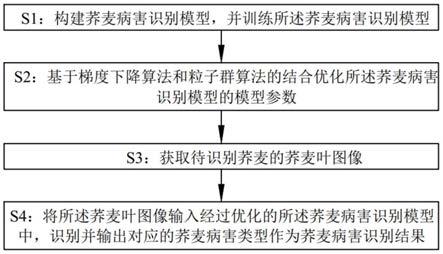
8.s1:构建荞麦病害识别模型,并训练所述荞麦病害识别模型;
9.s2:基于梯度下降算法和粒子群算法的结合优化所述荞麦病害识别模型的模型参
数;
10.s3:获取待识别荞麦的荞麦叶图像;
11.s4:将所述荞麦叶图像输入经过优化的所述荞麦病害识别模型中,识别并输出对应的荞麦病害类型作为荞麦病害识别结果。
12.优选的,步骤s1中,基于vgg16网络构建所述荞麦病害识别模型;
13.具体通过如下步骤构建所述荞麦病害识别模型:
14.s101:对vgg16网络的卷积层进行分块,得到多个卷积块;
15.s102:去除vgg16网络的密集连接分类器层,得到对应的conv_base网络;
16.s103:在conv_base网络的顶部添加dense层进行网络扩展;
17.s104:将conv_base网络的最后一个卷积块与dense层联合,得到对应的荞麦病害识别模型。
18.优选的,步骤s101中,将vgg16网络的卷积层分成5个卷积块;
19.步骤s104中,冻结conv_base网络的前4个卷积块,并将前4个卷积块的set_trainable属性设置为flase;
20.步骤s104中,将conv_base网络的最后一个卷积块的set_trainable属性设置为true。
21.优选的,通过如下步骤训练所述荞麦病害识别模型:
22.s111:通过预训练数据集训练conv_base网络的各个卷积块;
23.s112:对conv_base网络的各个卷积块进行冻结;
24.s113:解冻conv_base网络的最后一个卷积块,并通过荞麦病害数据集训练conv_base网络的最后一个卷积块;
25.s114:将conv_base网络各个卷积块的输出特征进行融合得到对应的高层特征,将高层特征输入dense层进行分类。
26.优选的,步骤s114中,通过如下公式对conv_base网络各个卷积块的输出特征进行融合:
27.f
oracle
=[α
×
f
block4
,β
×
f
block5
];式中:f
oracle
表示高层特征;f
block4
表示前4个卷积块的输出特征;f
block5
表示最后一个卷积块的输出特征;α、β表示权重参数,分别为0.6和0.4。
[0028]
优选的,步骤s113中,通过学习率为0.0001的rmsprop优化器训练最后一个卷积块。
[0029]
优选的,所述预训练数据为荞麦类同类作物的病害训练数据。
[0030]
优选的,所述预训练数据包括玉米、大豆、水稻中的任意一个或多个的病害训练数据。
[0031]
优选的,conv_base网络的分类器类别数与荞麦病害的类别数相对应。
[0032]
优选的,步骤s2中,通过如下步骤优化荞麦病害识别模型的模型参数:
[0033]
设有m个粒子,每个粒子有n维向量,第j个粒子的位置可以表示为w
i
=(w
i,1
,w
i,2
,...,w
i,n
)
t
,速度表示为v
i
=(v
i,1
,v
i,2
,...,v
i,n
)
t
;
[0034]
s201:初始化m个粒子的位置和速度;
[0035]
s202:计算各个粒子的适应度,并根据适应度更新w
*j,d
、w
*d
、g
j,d
;
[0036]
s203:通过以下公式更新每个粒子的位置和速度:
[0037][0038]
v
j,d(k+1)
=εv
j,d(k)
+r1η1(w
*j,d
‑
w
j,d(k)
)+r2η2(w
*d
‑
w
j,d(k)
)
‑
η3g
j,d(k)
;
[0039]
w
j,d(k+1)
=w
j,d(k)
+η4v
j,d(k+1)
;
[0040]
式中:s
j(k)
表示第j个粒子第k次计算后的损失函数;v
j,d(k+1)
表示第j个粒子的第d个维度在第k+1次计算后的速度;w
j,d(k+1)
表示第j个粒子的第j个维度在第k+1次计算后的位置,g
j,d(k)
表示第j个粒子的第d个维度的位置的梯度;ε表示惯性权重;r1、r2是介于[0,1]之间的随机数,η1、η2、η3是对应部分的参数,可以是常数,也可以是公式;w
*j,d
表示第j个粒子的第d个维度在第k次计算后的最优位置;w
*d
表示所有粒子的第d个维度在第k次计算后的最优位置;j∈1,2,
…
,m,d∈1,2,
…
,n。
[0041]
s204:判断是否达到最大迭代次数或全局最优位置满足最小界限:若满足停止条件,则停止计算并输出最优的模型参数;否则,返回步骤s202。
[0042]
本发明中的荞麦病害识别方法与现有技术相比,具有如下有益效果:
[0043]
在本发明中,将梯度下降算法和粒子群算法从底层结合得到了对应的“权值优化算法”,该算法克服了梯度下降算法难以充分开发利用gpu、cpu向量化的能力,难以保证全局最小值,容易陷入局部最优,以及梯度爆炸和梯度消失等问题,同时解决了粒子群算法缺乏速度动态调节,容易导致收敛精度低和不易收敛的问题;也就是,本发明将梯度下降算法和粒子群算法结合的方式,使得两种算法能够相辅相成、互相促进,提升了全局搜索能力,更能将模型优化到全局最优解,提升了网络参数的优化速度,进而能够兼顾识别模型的训练效果和训练效率,从而能够有效提升荞麦病害识别的准确性,并降低荞麦病害识别的时间成本。此外,荞麦病害的外在表现主要体现在叶片部位,因此本发明通过荞麦叶图像实现荞麦病害识别的方式,能够有效保证荞麦病害识别的识别效果和准确性。
附图说明
[0044]
为了使发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步的详细描述,其中:
[0045]
图1为实施例中荞麦病害识别方法的逻辑框图;
[0046]
图2为实施例中荞麦病害识别模型的网络结构图;
[0047]
图3为实施例中优化模型参数的流程图。
具体实施方式
[0048]
下面通过具体实施方式进一步详细的说明:
[0049]
实施例:
[0050]
本实施例中公开了一种基于卷积神经网络的荞麦病害识别方法。
[0051]
如图1所示,一种基于卷积神经网络的荞麦病害识别方法,包括以下步骤:
[0052]
s1:构建荞麦病害识别模型,并训练荞麦病害识别模型;
[0053]
s2:基于梯度下降算法和粒子群算法的结合优化荞麦病害识别模型的模型参数;
[0054]
s3:获取待识别荞麦的荞麦叶图像;
[0055]
s4:将荞麦叶图像输入经过优化的荞麦病害识别模型中,识别并输出对应的荞麦病害类型作为荞麦病害识别结果。
[0056]
在本发明中,将梯度下降算法和粒子群算法从底层结合得到了对应的“权值优化算法”,该算法克服了梯度下降算法难以充分开发利用gpu、cpu向量化的能力,难以保证全局最小值,容易陷入局部最优,以及梯度爆炸和梯度消失等问题,同时解决了粒子群算法缺乏速度动态调节,容易导致收敛精度低和不易收敛的问题;也就是,本发明将梯度下降算法和粒子群算法结合的方式,使得两种算法能够相辅相成、互相促进,提升了全局搜索能力,更能将模型优化到全局最优解,提升了网络参数的优化速度,进而能够兼顾识别模型的训练效果和训练效率,从而能够有效提升荞麦病害识别的准确性,并降低荞麦病害识别的时间成本。此外,荞麦病害的外在表现主要体现在叶片部位,因此本发明通过荞麦叶图像实现荞麦病害识别的方式,能够有效保证荞麦病害识别的识别效果和准确性。
[0057]
具体实施过程中,基于vgg16网络构建荞麦病害识别模型;
[0058]
结合图2所示,通过如下步骤构建荞麦病害识别模型:
[0059]
s101:对vgg16网络的卷积层进行分块,得到多个卷积块。具体的,将vgg16网络的卷积层分成5个卷积块;前10个卷积层作为前四个卷积块,后三个卷积层作为最后一个卷积块。
[0060]
s102:去除vgg16网络的密集连接分类器层,得到对应的conv_base网络;
[0061]
s103:在conv_base网络的顶部添加dense层进行网络扩展;
[0062]
s104:将conv_base网络的最后一个卷积块与dense层联合,得到对应的荞麦病害识别模型。具体的,冻结conv_base网络的前4个卷积块,并将前4个卷积块的set_trainable属性(可训练设置属性)设置为flase;将conv_base网络的最后一个卷积块set_trainable属性(可训练设置属性)设置为true。
[0063]
vgg16网络是14年牛津大学计算机视觉组和google deepmind公司研究员一起研发的深度网络模型,该网络一共有16个训练参数的网络。vgg16网络结构简洁,迁移到其他图片数据上的泛化性能非常好。vgg16网络常被用来提取图像特征,该网络训练后的模型参数在其官网上开源,可以用来在图像分类任务上进行在训练,使用较为广泛。
[0064]
conv_base网络是指卷积神经网络的基础构架网络。卷积神经网络(convolutional neural networks,cnn)是一类包含卷积计算且具有深度结构的前馈神经网络(feedforward neural networks),是深度学习(deep learning)的代表网络之一。卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift
‑
invariant classification),因此也被称为“平移不变人工神经网络(shift
‑
invariant artificial neural networks,siann),也是领域内常用的变人工神经网络之一,其基础构架网络为并领域技术人员熟知。
[0065]
dense层是指卷积神经网络的全连接层。
[0066]
具体实施过程中,通过如下步骤训练荞麦病害识别模型:
[0067]
s111:通过预训练数据集训练conv_base网络的各个卷积块,具体的,预训练数据为荞麦类同类作物的病害训练数据。预训练数据包括玉米、大豆、水稻中的任意一个或多个的病害训练数据。
[0068]
s112:对conv_base网络的各个卷积块进行冻结。
[0069]
s113:解冻conv_base网络的最后一个卷积块,并通过荞麦病害数据集训练conv_base网络的最后一个卷积块。具体的,通过学习率为0.0001的rmsprop优化器训练最后一个卷积块。
[0070]
s114:将conv_base网络各个卷积块的输出特征进行融合得到对应的高层特征,将高层特征输入dense层进行分类。具体的,conv_base网络的分类器类别数与荞麦病害的类别数相对应。通过如下公式对conv_base网络各个卷积块的输出特征进行融合:
[0071]
f
oracle
=[α
×
f
block4
,β
×
f
block5
];式中:f
oracle
表示高层特征;f
block4
表示前4个卷积块的输出特征;f
block5
表示最后一个卷积块的输出特征;α、β表示权重参数,分别为0.6和0.4。
[0072]
实际训练过程中,荞麦病害样本数量不足且均衡性差,容易导致荞麦病害识别模型训练精度低,进而导致荞麦病害识别的准确性低。为了提高荞麦病害识别的准确性,本发明采用迁移学习的思想,把玉米、大豆、水稻作物的同类病害样本与荞麦病害样本混合作为训练数据,进而保证了病害样本的数量和均衡性,从而能够提高荞麦病害识别的准确性。同时,本发明将预训练数据集用于训练conv_base网络的前四个卷积层,将荞麦病害数据集用于训练conv_base网络的最后一个卷积层,进而将基于预训练数据提取的底层特征和基于荞麦病害数据集提取的高层抽象特征融合得到高层特征,基于高层特征能够进一步保证荞麦病害识别的准确性。此外,conv_base网络各层对于荞麦不同病害的响应值不同,本发明希望微调的三层表示变化范围不要太大,于是采用学习率为0.0001的rmsprop优化器。
[0073]
具体实施过程中,结合图3所示,通过如下步骤优化荞麦病害识别模型的模型参数:
[0074]
设有m个粒子,每个粒子有n维向量,第j个粒子的位置可以表示为w
i
=(w
i,1
,w
i,2
,...,w
i,n
)
t
,速度表示为v
i
=(v
i,1
,v
i,2
,...,v
i,n
)
t
;
[0075]
s201:初始化m个粒子的位置和速度;
[0076]
s202:计算各个粒子的适应度,并根据适应度更新w
*j,d
、w
*d
、g
j,d
;
[0077]
s203:通过以下公式更新每个粒子的位置和速度:
[0078][0079]
v
j,d(k+1)
=εv
j,d(k)
+r1η1(w
*j,d
‑
w
j,d(k)
)+r2η2(w
*d
‑
w
j,d(k)
)
‑
η3g
j,d(k)
;
[0080]
w
j,d(k+1)
=w
j,d(k)
+η4v
j,d(k+1)
;
[0081]
式中:s
j(k)
表示第j个粒子第k次计算后的损失函数;v
j,d(k+1)
表示第j个粒子的第d个维度在第k+1次计算后的速度;w
j,d(k+1)
表示第j个粒子的第j个维度在第k+1次计算后的位置,g
j,d(k)
表示第j个粒子的第d个维度的位置的梯度;ε表示惯性权重;r1、r2是介于[0,1]之间的随机数,η1、η2、η3是对应部分的参数,可以是常数,也可以是公式;w
*j,d
表示第j个粒子的第d个维度在第k次计算后的最优位置;w
*d
表示所有粒子的第d个维度在第k次计算后的最优位置;j∈1,2,
…
,m
…
,d∈1,2,
…
,n
…
。
[0082]
s204:判断是否达到最大迭代次数或全局最优位置满足最小界限:若满足停止条件,则停止计算并输出最优的模型参数;否则,返回步骤s202。
[0083]
在本发明中,将梯度下降算法和粒子群算法从底层结合得到了对应的“权值优化算法”,该算法克服了梯度下降算法难以充分开发利用gpu、cpu向量化的能力,难以保证全局最小值,容易陷入局部最优,以及梯度爆炸和梯度消失等问题,同时解决了粒子群算法缺乏速度动态调节,容易导致收敛精度低和不易收敛的问题;也就是,本发明将梯度下降算法和粒子群算法结合的方式,使得两种算法能够相辅相成、互相促进,提升了全局搜索能力,更能将模型优化到全局最优解,提升了网络参数的优化速度,进而能够兼顾识别模型的训练效果和训练效率,从而能够有效提升荞麦病害识别的准确性,并降低荞麦病害识别的时间成本。
[0084]
本发明提供的基于卷积神经网络的荞麦病害识别方法,其中对荞麦叶图像的分类识别处理思路核心,还是在于从底层结合梯度下降算法和粒子群算法的优化,借助这种图像分类识别的核心思路和方法,实际上也可以用于金融图像、人脸图像等其他类型的图像分类识别应用领域中,亦具有广阔的技术应用前景。
[0085]
需要说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管通过参照本发明的优选实施例已经对本发明进行了描述,但本领域的普通技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离所附权利要求书所限定的本发明的精神和范围。同时,实施例中公知的具体结构及特性等常识在此未作过多描述。最后,本发明要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1