一种基于分层时序多示例学习的学生学习参与度评估方法与流程
1.本发明属于计算机视觉、人工智能、教育领域,尤其涉及一种基于分层时序多示例学习的学生学习参与度评估方法。
背景技术:
2.大规模开放在线课程(mooc)的出现引起了教育界的广泛关注和极大期待。尽管新教育途径具有广阔的潜力,但学生学习完成率过低被认为是其主要问题之一。为了克服这一不足,对个别学生在线学习活动期间的参与度进行动态评估可以提供及时的教学干预,以提高学习完成率,并且进行个性化的学习。由于在mooc环境中经常看到大量学生,手动进行此类评估的成本高得令人望而却步。因此,即时评估学生学习参与度的自动化技术的研究受到越来越多的关注。
3.学习参与度自动评估的研究存在以下问题:
4.1)由于逐段注释的工作耗时费力,以往很多方法只解决了评估整个视频的学习参与度的问题,对于更有意义的视频片段参与度的评估缺乏关注。
5.2)远程教育的课程通常持续数十分钟甚至一个小时,大量的视频数据使得评估难以进行。因此,如何获得能够代表整个视频和每个短片的有效特征成为亟待解决的问题。
技术实现要素:
6.本发明的目的在于针对现有技术的不足,提供一种基于分层时序多示例学习的学生学习参与度评估方法。
7.本发明的目的是通过以下技术方案来实现的:一种基于分层时序多示例学习的学生学习参与度评估方法,包括以下步骤:
8.步骤1,从每个视频中抽取图像帧,每l帧图像构成一个视频片段,一个视频获取n个视频片段。
9.步骤2,对每个视频片段里的每一帧图像使用openpose、fsa
‑
net以及plfd网络分别提取身体姿态特征、头部姿态特征以及面部关键点特征,用于学习参与度的评估。
10.步骤3,对于视频片段的每一类特征序列,分别使用bi
‑
lstm网络获取每个时刻的隐藏状态;将隐藏状态输入底层时序多示例学习模块(b
‑
tmil),得到视频片段的特征表示。将一个视频所有视频片段提取的特征,通过全连接以及顶层多示例学习模块(t
‑
tmil)进行处理,得到视频的特征表示。其中,b
‑
timil、t
‑
tmil均基于自注意力机制实现,结构相同。
11.步骤4,将步骤3中b
‑
tmil提取的三类视频片段级的特征进行融合,同时将步骤3中t
‑
tmil提取的三类视频级的特征进行融合。
12.步骤5,视频片段级的融合特征经过全连接操作,得到视频片段的学习参与度。视频级的融合特征经过全连接操作,得到视频的学习参与度。用视频片段参与度的均值和视频的学习参与度,分别建立局部与全局监督,训练整个网络。
13.进一步地,步骤1中,抽取图像帧具体为等间距每隔几帧保留一帧。
14.进一步地,步骤2中,对于视频片段帧v
i,j
,使用openpose、fsa
‑
net以及plfd网络分别提取头部姿势特征e
i,j
、身体姿势特征b
i,j
和面部关键点m
i,j
。对于视频片段v
i
,则得到头部姿势序列e
i
={e
i,1
,e
i,2
…
,e
i,l
},身体姿势序列b
i
={b
i,1
,b
i,2
…
,b
i,l
}和面部关键点序列m
i
={m
i,1
,m
i,2
…
,m
i,l
}。
15.进一步地,步骤3中,b
‑
tmil模块作用于构成一个短视频片段的采样视频帧序列,其中帧是示例,片段是包。需要获取包的有效表示,以便准确获取其标签。使用一个自注意力机制的多示例学习模块来作用于bi
‑
lstm的所有时刻的隐藏状态,通过可训练的参数自适应地获得包的表征。
16.进一步地,用x
i
表示头部姿势序列、身体姿势序列、面部关键点序列中的一个,将x
i
输入到bi
‑
lstm中,得到隐藏状态序列h
i
={h
i,1
,h
i,2
…
,h
i,l
}。x
i
对应的片段级聚合特征计算为经过降维处理后的加权和形式:
[0017][0018][0019][0020]
其中,表示片段级头部姿势特征序列、片段级身体姿势特征序列、片段级面部关键点特征序列中的一个。δ是relu函数,是用于降维的全连接操作。是权重矩阵,
⊙
是逐元素乘法,σ是sigmoid函数,τ是tanh函数。
[0021]
进一步地,步骤3中,t
‑
tmil作用于视频片段之间,视频片段认为是示例,由片段组成的完整视频就是包。在片段级特征的基础上应用mil模块。通过全连接操作减少片段级特征的维度,以生成更有效的嵌入表示。构造视频片段的加权组合来表示视频。
[0022]
进一步地,表示视频级头部姿势特征序列、视频级身体姿势特征序列、视频级面部关键点特征序列中的一个:
[0023][0024][0025][0026]
其中,是t
‑
tmil中的权重矩阵。表示片段级头部姿势特征序列、片段级身体姿势特征序列、片段级面部关键点特征序列中的一个。
[0027]
进一步地,步骤4中,采用加权特征融合方法,提取用于评估的片段级和视频级融合特征。权重矩阵与特征矩阵大小相同,由可训练的参数组成。权重矩阵的每一列通过softmax函数归一化得到不同特征在对应维度上的不同比例,然后加权求和得到加权融合特征。
[0028]
本发明的有益效果是:本发明根据示例之间的时间相关性,建立分层时序多示例学习模型,该模型由视频帧
‑
视频片段的底层模块以及视频片段
‑
视频的顶层模块构成。本发明使用从视频中提取的头部姿态、面部表情以及身体姿态三类特征以及视频级的学习参与度标签训练评估模型,该模型不仅能够得到视频级的学习参与度,而且能够得到所有视频片段的学习参与度。本发明的实现方法便捷、高效、计算简单,使学习参与度评估精度得到可靠的保证。
附图说明
[0029]
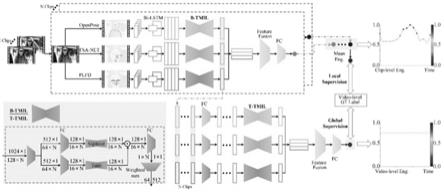
图1为学习参与度评估框架示意图;
[0030]
图2为特征融合过程示意图。
具体实施方式
[0031]
如图1所示,本发明一种基于分层时序多示例学习的学生学习参与度评估方法,包括以下步骤:
[0032]
步骤1,预处理。从每个视频中,等间距抽取3000帧的图像;每30帧图像构成一个视频片段,因此一个视频能够获取100个视频片段。
[0033]
下采样:学习者的身体姿态、头部姿势以及面部关键点在学习过程中往往会逐渐而缓慢地变化。因此,我们通过每隔几帧保留一帧来对每个原始视频进行下采样,以实现更有效的计算处理。在我们的实验中,每个视频保留3000帧用于评估。
[0034]
分割:由于当前时刻的特征对其他时刻学习参与度的评估影响不大,并且网络通常难以处理冗长的特征序列,我们将输入视频分割成短视频片段作为基本分析对象。我们将视频片段的长度设置为30帧,在我们所有的实验中表示为l=30,以在所提出的方法的计算效率和准确性之间权衡的结果。从每个视频中提取的视频片段的数量n=100。
[0035]
步骤2,特征提取。对每个视频片段里的每一帧图像使用openpose、fsa
‑
net以及plfd网络分别提取身体姿态特征、头部姿态特征以及面部关键点特征,用于学习参与度的评估。
[0036]
根据之前的研究,肢体语言和面部表情与学习者的学习参与度有很强的相关性。因此,我们使用头部姿势特征、身体姿势特征和面部关键点作为输入来提高我们模型的准确性和鲁棒性。对于视频片段帧v
i,j
,我们使用openpose、fsa
‑
net以及plfd网络分别提取头部姿势特征e
i,j
、身体姿势特征b
i,j
和面部关键点m
i,j
;i=1~n,j=1~l。然后对于视频片段v
i
,我们可以得到头部姿势序列e
i
={e
i,1
,e
i,2
…
,e
i,l
},身体姿势序列b
i
={b
i,1
,b
i,2
…
,b
i,l
}和面部关键点序列m
i
={m
i,1
,m
i,2
…
,m
i,l
}。
[0037]
步骤3,分层时序多示例学习模型(h
‑
tmil)。基于仅具有视频级标签的帧
‑
片段
‑
视频结构,如图1所示,我们提出了由底层时序多示例学习模块(b
‑
tmil)和顶层时序多示例学习模块(t
‑
tmil)组成的分层时序多示例学习模型(h
‑
tmil),分别致力于学习片段与其组成帧之间的潜在关系以及视频与其组成片段之间的潜在关系。通过这个框架,我们建立了底层视频帧和视频级标签之间的连接,并且可以隐式地学习中间件的表达,即对评估片段级学习参与度有用的片段级特征。
[0038]
步骤3.1,底层时序多示例学习模块(b
‑
tmil)。对于视频片段的每一类特征序列,
我们分别使用bi
‑
lstm网络获取每个时刻的隐藏状态。将隐藏状态输入底层时序多示例学习模块(b
‑
tmil),得到视频片段的特征表示。如图1左下角所示,b
‑
tmil基于自注意力机制实现。
[0039]
b
‑
tmil模块作用于构成一个短视频片段的采样视频帧序列,其中帧是示例,片段是包。我们需要获取包的有效表示,以便准确获取其标签。然而,与传统的多示例学习mil不同,对于短时间帧序列,帧之间存在很强的时序相关性。使用bi
‑
lstm捕获时间关联并使用隐藏状态最后一层来表达序列,会造成早期信息的丢失。针对这个问题,我们使用一个自注意力机制的多示例学习模块来作用于bi
‑
lstm的所有时刻的隐藏状态,通过可训练的参数自适应地获得包的表征。使用身体姿态特征作为例子来展示。
[0040]
首先,我们将身体姿势特征序列b
i
输入到bi
‑
lstm中,得到隐藏状态序列h
i
={h
i,1
,h
i,2
…
,h
i,l
}。片段级聚合特征可以计算为经过降维处理后的加权和形式:
[0041][0042]
其中,δ指的是relu函数,指的是用于降维的全连接操作。权重计算公式为:
[0043][0044]
其中,计算如下:
[0045][0046]
式中,是权重矩阵,
⊙
是逐元素乘法,σ是sigmoid函数,τ是tanh函数。其中,tanh函数用于获取特征之间的相关性,sigmoid函数作为门机制。
[0047]
类似于片段级身体姿势特征序列的聚合过程,我们使用b
‑
tmil模块提取片段级头部姿势特征序列和片段级面部关键点特征序列即将上述过程中的b
i
替换为e
i
或m
i
。
[0048]
步骤3.2,顶层时序多示例学习模块(t
‑
tmil)。将一个视频所有视频片段提取的特征,通过全连接以及顶层多示例学习模块(t
‑
tmil)进行处理,得到该视频的特征表示。如图1左下角所示,跟b
‑
timil类似,t
‑
tmil同样基于自注意力机制实现。
[0049]
与b
‑
tmil类似,t
‑
tmil作用于视频片段之间,视频片段可以认为是示例,由片段组成的完整视频就是包。然而,由于每个视频的持续时间较长,我们认为视频片段之间不再存在强烈的时间关系。之前很多工作一般认为视频级特征可以表示为所有片段级特征的平均值。这些方法平等对待所有视频片段,这对最终评估的准确性产生不利影响。为了获得更健壮和灵活的视频表示,我们仍然在片段级特征的基础上应用mil模块。并且顶层模块变得更加类似于传统的多示例结构。这里我们也以身体姿态特征为例来描述t
‑
tmil的过程。
[0050]
通过全连接操作减少片段级特征的维度,以生成更有效的嵌入表示。我们构造视频片段的加权组合来表示视频,其计算如下:
[0051][0052][0053]
其中,为视频级身体姿态特征序列。计算如下:
[0054][0055]
其中,是t
‑
tmil中的权重矩阵。与上述过程类似,我们使用t
‑
tmil模块聚合视频级头部姿势特征序列和视频级面部关键点特征序列即将上式中的替换为或
[0056]
步骤4,特征融合。将步骤3.1提取的三类视频片段级的特征进行融合,同时将步骤3.2提取的三类视频级的特征进行融合。融合过程如图2所示。
[0057]
我们使用三种类型的特征来评估学习参与度,而我们的分层模块分别处理每种类型的特征。为了实现不同特征之间的优势互补,增加判断信息,我们提出了一种加权特征融合方法,提取用于评估的片段级和视频级融合特征。如图2所示,权重矩阵与特征矩阵大小相同,由可训练的参数组成。权重矩阵的每一列通过softmax函数归一化得到不同特征在该维度上的不同比例,然后加权求和得到加权融合特征。
[0058]
步骤5,视频片段级的融合特征经过全连接操作,得到视频片段的学习参与度。视频级的融合特征经过全连接操作,得到视频的学习参与度。用视频片段参与度的均值和视频的学习参与度,分别建立局部与全局监督,训练该网络。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1