一种基于公共品演化博弈模型的群体知识共享方法
1.本发明属于信息资源共享技术领域,更具体地,涉及一种基于公共品演化博弈模型的群体知识共享方法。
背景技术:
2.在线学习社区中知识共享是非常重要的环节,但是由于进行知识共享行为需要付出一定的成本,以至于社区中很多成员采用不共享的策略,这会导致群体的知识共享程度低下,网络共享数据量较低,不利于社区网络的健康发展,因此,如何促进社区中的成员进行知识共享、提高群体知识共享程度是本领域技术人员迫切需要解决的一个技术问题。
技术实现要素:
3.为了克服现有技术中存在的不足,本发明的目的是提供一种基于公共品演化博弈模型的群体知识共享方法,以提高群体共享水平,使得社区能够达到高共享水平稳态,从而促使社区长期稳定的发展。
4.本发明提供一种基于公共品演化博弈模型的群体知识共享方法,包括以下步骤:
5.步骤1、定义在线学习社区的群体为一个包含多个用户节点的集合,将用户进行知识共享的比例作为用户的策略,将用户调整知识共享比例的程度作为用户的策略调整速度,将用户获取的知识总量作为用户的收益,构建群体知识共享对应的公共品演化博弈模型;
6.其中,知识共享比例的取值范围为[0,1];
[0007]
步骤2、初始化所有用户节点,以相同的概率随机设置每个用户的策略,设置每个用户的策略调整速度为0,并对初始化的策略和初始化的策略调整速度进行记录;
[0008]
步骤3、根据记录的每个用户的策略,通过所述公共品演化博弈模型计算每个用户的收益,并对收益进行记录;
[0009]
步骤4、根据记录的每个用户的收益,得到每个用户的历史最优收益和该用户历史最优收益对应的历史最优策略,以及每个用户所在群体中获得的最优收益和该最优收益对应的最优策略;
[0010]
步骤5、根据每个用户的历史最优收益和每个用户所在群体中获得的最优收益,对每个用户的记忆系数和模仿系数进行更新;
[0011]
其中,所述记忆系数表示用户根据自身经验改变策略的概率,模仿系数表示用户根据该用户所在群体经验改变策略的概率;
[0012]
步骤6、结合粒子群优化算法对每个用户的策略和策略调整速度进行更新,更新后重复执行步骤3至步骤5,直到群体的知识共享水平达到稳定状态;
[0013]
其中,将用户的策略对应于粒子群优化算法中的粒子位置,将用户的策略调整速度对应于粒子群优化算法中的粒子速度,将用户的收益对应于粒子群优化算法中的粒子适应度。
[0014]
优选的,所述步骤2中,初始化用户的策略采用如下方式:
[0015]
strategy=slimit(1)+(slimit(2)
‑
slimit(1))*rand(1,n)
[0016]
其中,strategy表示策略,slimit(1)、slimit(2)分别表示策略上限、策略下限,rand函数生成随机数值,n表示用户总人数,rand(1,n)表示生成n个取值范围在[0,1]的数值并赋予n个用户节点作为初始化策略。
[0017]
优选的,所述步骤3中,计算用户的收益采用如下方式:
[0018][0019]
其中,u
i,j
(t)表示第t轮博弈时用户i参与以邻居j为中心的群体中获得的收益,i∈n,j∈n,n表示用户总人数;q
i
表示用户i所拥有的知识量,s
i,t
表示用户i在第t轮博弈时的策略;k
i
表示用户i的邻居数量,k
i
+1表示用户i及其邻居的数量之和,r表示增益系数,k
j
表示用户j的邻居数量,k
j
+1表示用户j及其邻居数量之和;ω
j
表示以用户j为中心的邻居集合;l∈(ω
j
∪j)表示用户l属于用户j及其邻居集合,q
l
表示用户l所拥有的知识量,s
l,t
表示用户l在第t轮博弈时的策略,k
l
表示用户l的邻居数量,k
l
+1表示用户l及其邻居的数量之和;
[0020][0021]
其中,u
i
(t)表示第t轮博弈时用户i获得的累积收益,ω
i
表示以用户i为中心的邻居集合,j∈(ω
i
∪i)表示用户j属于用户i及其邻居集合;c表示成本系数。
[0022]
优选的,所述步骤5中,记忆系数记为w,模仿系数记为1
‑
w,对用户的记忆系数和模仿系数进行更新采用如下方式:
[0023][0024]
其中,表示用户i在开始第t+1轮博弈前,获得的历史最优收益;表示在第t轮博弈时用户i所在群体中获得的最优收益,用户i所在群体包括用户i及其邻居集合;p表示用户i在第t轮博弈中获得的收益。
[0025]
优选的,所述步骤6中,结合粒子群优化算法对用户的策略和策略调整速度进行更新采用如下方式:
[0026][0027]
s
i,t+1
=s
i,t
+v
i,t+1
[0028]
其中,v
i,t+1
表示第t+1轮博弈时用户i的策略调整速度;v
i,t
表示第t轮博弈时用户i的策略调整速度;w表示记忆系数,表示用户i在开始第t+1轮博弈前,获得的历史最优策略;s
i,t
表示用户i在第t轮博弈时的策略;表示在第t轮博弈时用户i所在群体中获得最高收益的用户采用的策略,用户i所在群体包括用户i及其邻居集合;s
j,t
表示表示用户j在第t轮博弈时的策略;s
i,t+1
表示用户i在第t+1轮博弈时的策略。
[0029]
本发明中提供的一个或多个技术方案,至少具有如下技术效果或优点:
[0030]
在发明中,定义在线学习社区的群体为一个包含多个用户节点的集合,将用户进行知识共享的比例作为用户的策略,将用户调整知识共享比例的程度作为用户的策略调整速度,将用户获取的知识总量作为用户的收益,构建群体知识共享对应的公共品演化博弈模型;对所有用户对应的策略和策略调整速度进行初始化;基于用户的策略,通过公共品演化博弈模型计算每个用户的收益;基于用户的收益,得到每个用户的历史最优收益和该用户历史最优收益对应的历史最优策略,以及每个用户所在群体中获得的最优收益和该最优收益对应的最优策略;根据每个用户的历史最优收益和每个用户所在群体中获得的最优收益,对每个用户的记忆系数和模仿系数进行更新;将用户的策略对应于粒子群优化算法中的粒子位置,将用户的策略调整速度对应于粒子群优化算法中的粒子速度,将用户的收益对应于粒子群优化算法中的粒子适应度,结合粒子群优化算法对每个用户的策略和策略调整速度进行更新,更新后重复执行上述步骤直到群体达到稳态。即本发明基于在线学习社区的特征构建群体知识共享对应的公共品演化博弈模型,结合粒子群优化算法,根据用户的行为特性将用户的策略连续化,调整用户的记忆系数和模仿系数,以动态调整用户的共享策略,能够提高群体共享水平,使得社区能够达到高共享水平稳态,从而促使社区长期稳定的发展。
附图说明
[0031]
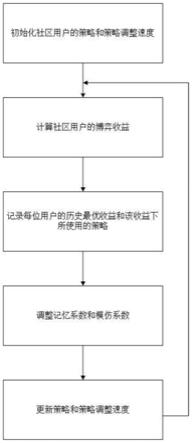
图1为本发明实施例提供的一种基于公共品演化博弈模型的群体知识共享方法的流程图。
具体实施方式
[0032]
为了更好的理解上述技术方案,下面将结合说明书附图以及具体的实施方式对上述技术方案进行详细的说明。
[0033]
对于知识共享,传统的博弈模型采用的是纯策略,即共享或者不共享。而在现实情况下,对于具有独立行动、思考、判断和决策能力的用户而言,其决策行为过程较为复杂并具有一定程度的不确定性,因此相对于纯策略来说,混合策略会更加的合理。因此,根据在线学习社区的特征,本发明采用公共品博弈模型对其进行模拟,该模型属于多人博弈类型,与在线学习社区交互行为的特性更加的契合。
[0034]
本发明定义每个用户可以决定自己共享的比例,该比例就是用户进行知识共享选择的策略。将策略定义在[0,1]这一区间,以刻画用户共享知识的程度和意愿,0表示用户未共享任何知识,但是根据社区特性,其也可以从别人的共享中获的收益,并且无需承担任何损失;而1表示用户共享所有的知识量,付出的成本是因分享而失去知识独占性所带来的损失,以及在知识共享过程中花费的时间、精力等。如此,用户的不同共享比例对应不同的策略。
[0035]
粒子群优化算法(pso)具有很好的演化寻优特性,大多是用于“连续变量”中寻优,而连续策略空间公共品演化博弈中个体的策略更新过程与pso算法中粒子的行为有很多相似的特征,由此启发,本发明引入pso算法。
[0036]
pso算法初始化生成一群随机例子,算法的核心是每一次迭代,粒子通过追随自身
历史最优解和种群历史最优解两个“极值”来调整速度和位置,该动态调整的速度是更新粒子位置的关键,而粒子位置象征着离最优解的距离,适应度是评价该粒子解的唯一标准。从生物和社会角度而言,用户都希望自己通过交互能够获得较高的收益,因此收益对用户的策略选择具有重要的影响。因此,本发明在用户策略更新的过程中引入pso算法,将用户的策略(贡献比例)对应于粒子位置,把用户的收益对应于粒子的适应度,用户结合个体经验及社会群体经验调整贡献比例,进行策略的更新和演化。
[0037]
本发明将粒子群优化算法与公共品博弈技术相结合,根据用户的行为特性将用户的策略连续化,设置动态函数调整用户的记忆系数和模仿系数,以动态调整用户的共享策略,能够提高群体共享水平,使得社区能够达到高共享水平稳态,从而促使社区长期稳定的发展。
[0038]
本实施例提供了一种基于公共品演化博弈模型的群体知识共享方法,参见图1,包括以下步骤:
[0039]
步骤1:定义在线学习社区的群体为一个包含多个用户节点的集合,将用户进行知识共享的比例作为用户的策略,将用户调整知识共享比例的程度作为用户的策略调整速度,将用户获取的知识总量作为用户的收益,构建群体知识共享对应的公共品演化博弈模型。
[0040]
其中,知识共享比例的取值范围为[0,1]。
[0041]
即根据在线学习社区和社区中的用户学习特征,构建相应的公共品演化博弈模型。特征主要指:社区用户具有一定的知识水平(即所拥有的知识量),用户的共享意愿,用户进行知识共享需要花费的成本,用户能够获得的知识收益等。
[0042]
设置了一个由n个用户节点组成的群体,由集合n={1,2,...,n}表示;根据在线学习社区用户的学习特征,对每一个用户节点i∈n进行了“知识量”“共享成本”“策略”“策略调整速度”“博弈收益”的定义。
[0043]
知识量q指:用户自身所拥有的知识量。共享成本c(成本系数)指:用户进行知识共享需要花费的时间精力等成本。策略s指:用户进行知识共享的比例。策略调整速度v指:用户调整知识共享比例的程度,具体的,用户根据自身惯性速度(即用户在上一次博弈中的策略调整速度,初次为0)、个体经验(即用户学习自身最优策略的程度)、社会经验(即用户向群体中收益最高的用户学习策略的程度)调整策略的方向(即程度)。收益p指:用户博弈后获得的知识量。
[0044]
步骤2:初始化所有用户节点,以相同的概率随机设置每个用户的策略,设置每个用户的策略调整速度为0,并对初始化的策略和初始化的策略调整速度进行记录。
[0045]
一方面,对策略进行初始化时,设strategy表示各个用户的策略集合,不同的策略代表着不同的贡献比例,其为连续值,此处可以用以下方式进行初始化:
[0046]
strategy=slimit(1)+(slimit(2)
‑
slimit(1))*rand(1,n)
[0047]
其中,slimit(1)和slimit(2)分别表示策略上限、策略下限,rand函数生成随机数值,n表示用户总人数,rand(1,n)表示生成n个取值范围在[0,1]的数值并赋予n个用户节点作为初始化策略。
[0048]
例如,slimit(1)=0,slimit(2)=1。
[0049]
另一方面,将各个用户的策略调整速度均初始化为0。
[0050]
在接下来的博弈过程中,每个用户会根据自身历史收益和其他邻居的收益来调整自己的策略调整速度,而后进一步的更新策略。
[0051]
步骤3:根据记录的每个用户的策略,通过所述公共品演化博弈模型计算每个用户的收益,并对收益进行记录。
[0052]
用户i参与以其自身为中心及以其邻居为中心的共k
i
+1个群体的博弈,其中k
i
是用户i的邻居数量。
[0053]
所述步骤3包括以下子步骤:
[0054]
步骤3.1:计算每个用户在每轮博弈中参与以某一邻居为中心的群体(包括该用户)时获得的收益。
[0055]
第t轮博弈时,用户i参与以邻居j为中心的群体中获得的收益表示为:
[0056][0057]
其中,u
i,j
(t)表示第t轮博弈时用户i参与以邻居j为中心的群体中获得的收益,i∈n,j∈n,n表示用户总人数;q
i
表示用户i所拥有的知识量,s
i,t
表示用户i在第t轮博弈时的策略(分享比例),0≤s
i,t
≤1;k
i
表示用户i的邻居数量,k
i
+1表示用户i及其邻居的数量之和,r表示的是增益系数,k
j
表示用户j的邻居数量,k
j
+1表示用户j及其邻居数量之和;ω
j
表示以用户j为中心的邻居集合;l∈(ω
j
∪j)表示用户l属于用户j及其邻居集合,q
l
表示用户l所拥有的知识量,s
l,t
表示用户l在第t轮博弈时的策略,k
l
表示用户l的邻居数量,k
l
+1表示用户l及其邻居的数量之和。
[0058]
例如,增益系数为1.56,将群体中共享的知识量翻1.56倍后平均分给群体中的成员,再减去成员的共享量,这就是成员在这个群体中获得的收益。
[0059]
步骤3.2:计算每个用户在每轮博弈中获得的总收益。
[0060]
第t轮博弈时用户i获得的累积收益u
i
(t)表示为:
[0061][0062]
其中,ω
i
表示以用户i为中心的邻居集合,
j∈(ωi∪i)
表示用户j属于用户i及其邻居集合;c表示成本系数。
[0063]
例如,成本系数为0.01,将用户共享的知识量乘以成本系数0.01,即为用户进行知识共享所花费的成本。花费的成本应远小于用户的共享知识量,所以成本系数也应足够小。
[0064]
步骤4:根据记录的每个用户的收益,得到每个用户的历史最优收益和该用户历史最优收益对应的历史最优策略,以及每个用户所在群体中获得的最优收益和该最优收益对应的最优策略。
[0065]
步骤5:根据每个用户的历史最优收益和每个用户所在群体中获得的最优收益,对每个用户的记忆系数和模仿系数进行更新。
[0066]
其中,所述记忆系数表示用户根据自身经验改变策略的概率,模仿系数表示用户根据该用户所在群体经验改变策略的概率。
[0067]
即根据步骤4得出的相关数据,对用户的记忆系数w和模仿系数(1
‑
w)进行更新。更新公式如下:
[0068][0069]
其中,表示用户i在开始第t+1轮博弈前,获得的历史最优收益,表示在第t轮博弈时用户i所在群体中(包括自身)获得的最优收益,p表示用户i在本次(第t轮)博弈中获得的收益。
[0070]
步骤6:结合粒子群优化算法对每个用户的策略和策略调整速度进行更新,更新后重复执行步骤3至步骤5,直到群体的知识共享水平达到稳定状态。
[0071]
其中,将用户的策略对应于粒子群优化算法中的粒子位置,将用户的策略调整速度对应于粒子群优化算法中的粒子速度,将用户的收益对应于粒子群优化算法中的粒子适应度。
[0072]
即本发明利用pso算法的核心思想对策略进行更新,此处策略这一属性对应着pso算法中的“位置”,收益代表pso算法中的“适应度”,策略调整速度对应pso算法中的“速度”。
[0073]
结合粒子群优化算法对用户的策略和策略调整速度进行更新采用如下方式:
[0074][0075]
s
i,t+1
=s
i,t
+v
i,t+1
[0076]
其中,v
i,t+1
表示第t+1轮博弈时用户i的策略调整速度;v
i,t
表示第t轮博弈时用户i的策略调整速度;w表示记忆系数,表示用户i在开始第t+1轮博弈前,获得的历史最优策略;s
i,t
表示用户i在第t轮博弈时的策略;表示在第t轮博弈时用户i所在群体中获得最高收益的用户采用的策略,用户i所在群体包括用户i及其邻居集合;s
j,t
表示表示用户j在第t轮博弈时的策略;s
i,t+1
表示用户i在第t+1轮博弈时的策略。
[0077]
当群体中知识共享水平达到稳定时,所有用户都会选择对社区的健康发展有利的策略,能够达到提高群体的知识共享程度,提高网络共享数据量,促进社区网络健康发展的技术效果。
[0078]
综上,采用本发明提供的基于公共品演化博弈模型的群体知识共享方法能够促使用户向高收益的用户学习,能够使得群体能够达到较高的合作水平。
[0079]
最后所应说明的是,以上具体实施方式仅用以说明本发明的技术方案而非限制,尽管参照实例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1