一种用于车辆重识别的全局注意力网络模型
1.本发明涉及车辆识别技术领域,具体地涉及一种用于车辆重识别的全局注意力网络模型。
背景技术:
2.车辆重识别是指在不同摄像头下对目标车辆的识别,它在智能交通和智慧城市中起着重要作用,它在现实生活中有很多应用。例如,在真实的交通监控系统中,车辆重识别可以对目标车辆起到定位、监督和刑事侦查的作用。随着深度神经网络的兴起和大数据集的提出,提高车辆重识别的准确性已成为近年来计算机视觉和多媒体领域的研究热点。然而,由于多台摄像机下视角不同,以及光照、遮挡等方面的影响,导致类内特征距离变大,类间特征距离变小,进一步增加了识别的难度。
3.行人重识别和车辆重识别本质上是相同的,都属于图像检索任务。近年来,基于卷积神经网络(cnn)的方法在行人重识别上取得了很大的进展。因此,应用于行人重识别的cnn模型在车辆识别中也具有良好的性能。大多数先进的基于cnn的行人重识别方法采用在imagenet上预先训练的cnn模型,并在不同的损失的监督下,在重识别数据集上对它们进行调整。
4.基于cnn的车辆和行人的重识别通常侧重于提取人或车辆图像的全局特征。这样可以从全局上获得完整的特征信息,但全局特征不能很好地描述视角等因素引起的类内差异。为了提取细粒度的局部特征,带有局部分支的pcb(part
‑
based convolutional baseline,基于部分卷积基线)和mgn(multiple granularity network,多粒度网络)等行人重识别网络模型被设计出来。这些网络把特征图分成若干条来提取局部特征。另外,后者将局部特征与全局特征相结合,进一步提高了模型的性能。对于车辆重识别,同一车型的车辆在全局外观上基本相同。而在一些小区域,如检验标志、装饰和使用痕迹等,它们可能有很大的差异。因此,汽车局部细微信息对车辆重识别任务同样至关重要。
5.然而,这些基于局部的模型一方面有一个共同的缺点:为了学习显著的局部特征,它们需要为同一个人提供相对对齐的身体部位。虽然车辆重识别和行人重识别本质上都是图像检索问题,但是车辆的车身部位界限不像行人的那么清晰,并且从不同角度观察到同一辆车的车身差异很大。另一方面,特征图的严格均匀划分破坏了局部内一致性。并且局部一致性的破坏程度一般与局部划分的数量成正比,即划分数量越多,越容易破坏局部内一致性。这将使深度神经网络难以从局部中获取有意义的细粒度局部信息,从而降低了性能。因此,将行人重识别任务中的局部划分方法简单地应用到车辆上是不可行的。
6.注意机制在人类感知系统中起着重要的作用,它帮助人们专注于识别有用的显著的鉴别性特征,消除一些噪音和背景干扰。对于网络模型,注意力机制可以使模型聚焦于目标主体而不是背景,在重识别任务中得到了广泛的应用。因此,许多带有注意力模块的网络被提出。然而,它们主要是通过在自身信息上直接卷积来构建结点(通道、空间位置)的注意力,或使用结点之间的成对关系来直接重构结点,没有考虑到结点与结点之间的全局关系
对构建结点的注意力(重要性)具有重要的指导作用。
7.在车辆重识别任务中,不同的相机位置会产生光照变化、透视变化和分辨率差异,导致同一车辆在不同视角下的类内差异较大,或由于同一车型而导致不同车辆的类间差异较小。这大大增加了车辆重识别任务的难度。车辆再识别的关键在于车辆辨别性特征的提取。为了更好地从车辆图像中提取此类特征,提高识别的准确率,有必要提出一种用于车辆重识别的全局注意力网络模型。
技术实现要素:
8.本发明的目的在于克服现有技术存在的缺点,提出设计一种用于车辆重识别的全局注意力网络模型,既能简单地提取出局部的细微信息,在很大程度上解决局部不对齐和局部一致性破坏问题;又能根据结点与结点之间的全局关系构建结点的可靠注意力,从而提取用于车辆重识别的更加可信的显著性信息。
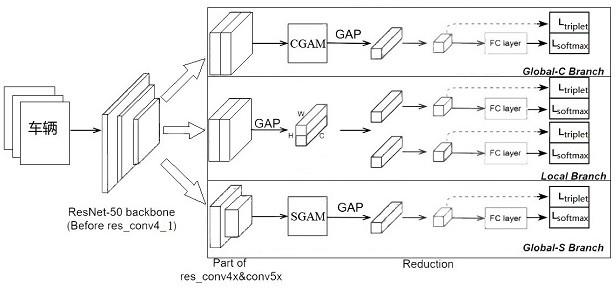
9.本发明解决其技术问题所采取的技术方案是:一种用于车辆重识别的全局注意力网络模型,包括一个骨干网、一个将特征图划分成两部分的局部分支和两个具有全局注意力模块的全局分支;所述骨干网络分裂为3个分支;所述全局注意力网络模型在每个分支输出的最终特征图上使用全局平均池化gap来提取得到特征向量,以覆盖车辆图像的整个车身信息;所述局部分支,仅将车辆特征图水平划分成两部分,能够很大程度上解决不对齐和局部一致性破坏的问题。
10.两个全局分支分别具有通道全局注意力模块cgam(channel globle attention module)和空间全局注意力模块sgam(spatial globle attention module),用于提取更加可靠的显著性信息。骨干网采用resnet50网络模型。
11.为了提高分辨率,将全局分支global
‑
c branch和局部分支local branch的res_conv5_1块的降采样的步长由2改为1,然后,在两个全局分支的res_conv5块后分别添加空间全局注意力模块、通道全局注意力模块,以提取可靠的显著性信息,增强特征鉴别能力,其中res_cov5表示resnet50网络模型的第四层;res_cov5_1表示resnet50网络模型的第四层中的第一个组成块。
12.在每个分支上使用全局平均池化gap来提取特征向量后,包含1*1卷积、bn层和relu函数的特征降维模块,将特征向量维度降至256,从而提供紧凑的特征表示。通过在每个分支上都施加三元组损失和交叉熵损失来训练网络模型,具体的,直接在256维特征向量上施加三元组损失,在256维特征向量后面追加一个全连接层再施加交叉熵损失。在测试阶段,将三个分支的全连接层之前的特征连接,作为最终的输出特征。
13.所述cgam体系结构:设张量为cgam输入的特征图,其中为通道数,和分别为张量的空间高度和宽度;从函数和中得到张量和,并且将变形为, 将变形为,和体系结构相同,均由两个1*1卷积和两个3*3分组卷积以及两个batchnormal层和两个relu激活函数组成。所述体系结构,利用两个3*3分组卷积来增加感受野,并减少参数的数量。随后,利用矩阵乘法得到矩阵,它表示了所有通道的两两成对关系。写成:;
此外,矩阵的每一行元素表示每个通道和所有其他通道之间的成对关系。对通道的平均成对关系进行建模,以获得通道的全局关系。然后,利用一个通道相对于其他通道的全局关系重要性来获得该通道在所有通道中的权重。
14.利用一个通道相对于其他通道的全局关系重要性来获得该通道在所有通道中的权重的过程为:将关系平均池化rap应用于矩阵,得到一个向量, 其中为通道数,此时,向量r的每个元素表示每个通道和所有通道之间的全局关系,将向量r的第个元素定义为。
15.;采用softmax函数将所有全局关系转换为每个通道的权重。
16.;为了获得注意力图,先将向量变形为,然后广播为,即为得到的注意图。最后,对原始特征图应用相同位置的两个元素相乘element
‑
wise multiplication和相同位置的两个元素相加element
‑
wise sum来获得最终的特征图。可以表示为:。
17.所述sgam体系结构:空间注意力和通道注意力分别利用位置之间和通道之间的全局关系来确定每个位置和通道的重要性,它们的工作方式是相似的。但与cgam相比,sgam有三个不同之处。首先,设张量为sgam输入的特征图,与体系结构相同,均包含一个1*1卷积,一个bn层和一个relu函数,将通道的数量减少为,为缩减因子,在实验中设为2;由函数和得到张量和,并将变形为,将变形为;然后,采用矩阵乘法来确定位置间的成对关系且获得矩阵,。
18.其次,为了确定一个位置的重要程度,对矩阵应用关系平均池化rap得到向量;向量的第个元素可以表示为:。
19.第三,本发明先将softmax函数生成的向量变形为,然后将其广播为。
20.在cgam和sgam中,将应用注意力后的特征图和原始特征图相加,得到最终的输出特征图。这里使用加法操作有两个原因。首先,这里使用的归一化函数是softmax, softmax函数是将权值映射到0到1的范围,并且所有权值之和为1。由于大量权值的存在,注意力模块输出的特征映射元素值可能较小,这将打破原有网络的特征,若不加上原始特征图,将给训练带来很大困难。其次,这一加法操作也突出了中的可靠的显著性信息。实验也表明,通过这种残差结构,模型具有很好的性能。与没有加法操作的模型相比,模型在map和top
‑
1上分别提高了1.2%/1.5%。
21.对于损失函数,使用最常见的交叉熵损失函数(cross entropy loss)和三元组损失函数(triplet loss)。
22.交叉熵表示真实概率分布和预测概率分布之间的差异。可以表示为:;其中表示小批量中的图像数量,表示id的真实标签,表示第类的id预测对数。
23.三元组损失的目的是使具有相同标签的样本在嵌入空间中尽可能靠近,而具有不同标签的样本保持尽可能远的距离。本发明采用了硬批三元组损失batch
‑
hard triplet loss,对每个小批量随机抽取个身份和个图像,以满足batch
‑
hard triplet loss的要求。损失可以定义为;其中,,,是分别从锚点、正样本、负样本提取的特征,将的值设置为1.2,这有助于减少类内差异并扩大类间差异以提高模型性能。
24.总的训练损失是交叉熵损失和三元组损失的和,由;其中和是平衡两个损失项的超参数,实验中都设置为1,是分支数量。
25.本发明的技术效果:与现有技术相比,本发明的一种用于车辆重识别的全局注意力网络模型,具有以下优点:本发明构建了一个具有三个分支的全局注意网络,以提取大量的鉴别性信息;基于结点的全局关系,本发明构建了cgam和sgam两个全局注意力模块;通过对结点与所有其他结点之间的平均成对关系进行建模,得到结点的全局关系,进而推断出结点的全局重要性,这样做一方面不仅减轻了注意力学习的难度,降低了计算复杂度,另一方面通过群体评价可以获得更加可信的结点重要性度量,进而提取更可靠的显著性信息;本发明在局部分支上,将车辆图像仅水平分割成两部分,这样可以在很大程度上解决部位不对齐和局部一致性破坏的问题。本发明在两个车辆重识别数据集上的实验验证了该算法的有效性。该方法的性能优于sota方法。
附图说明
26.图1为本发明整体网络架构示意图;图2为本发明cgam体系结构图;
图3为本发明体系结构图;图4为本发明sgam体系结构图。
具体实施方式
27.为使本发明实施例的目的、技术方案和优点更加清楚,下面结合说明书附图,对本发明实施例中的技术方案进行清楚、完整地描述。
28.如图1所示,一种用于车辆重识别的全局注意力网络模型,包括一个骨干网、一个将特征图分成两部分的局部分支和两个具有全局注意力模块的全局分支;所述骨干网络,使用resnet50作为特征图提取的基础,通过调整阶段并去除原始的全连接层来进行多损失训练,resnet50骨干网在res_conv4_1残块后分裂为3个分支;所述全局注意网络模型使用全局平均池化gap来覆盖车辆图像的整个车身部位;所述局部分支,仅将车辆特征图水平划分成两部分,能够很大程度上解决不对齐和局部一致性被破坏的问题。
29.为了提高分辨率,将全局分支global
‑
c branch和局部分支local branch的res_conv5_1块的降采样的步长由2改为1,然后,在两个全局分支的res_conv5块后分别添加空间全局注意力模块、通道全局注意力模块,以提取可靠的显著性信息,增强特征鉴别能力。
30.特征降维模块包含一个1*1卷积、一个bn层和一个relu函数,它将特征向量维度降至256,从而提供紧凑的特征表示。通过在每个分支上都施加三元组损失和交叉熵损失来训练网络模型,具体的,直接在256维特征向量上施加三元组损失,在256维特征向量后面追加一个全连接层再施加交叉熵损失。在测试阶段,将三个分支的全连接层之前的特征连接,作为最终的输出特征。
31.两个全局分支分别具有通道全局注意力模块cgam(channel globle attention module)和空间全局注意力模块sgam(spatial globle attention module),用于提取更加可靠的显著性信息。
32.如图2所示,展示了cgam体系结构,设张量为cgam输入的特征图,其中为通道数,和分别为张量的空间高度和宽度;从函数和中得到张量和,并且将变形为, 将变形为,和体系结构相同,由两个1*1卷积和两个3*3分组卷积以及两个batchnormal层和两个relu激活函数组成。所述体系结构,利用两个3*3分组卷积来增加感受野,并减少参数的数量。随后,利用矩阵乘法得到矩阵,它表示了所有通道的成对关系,写成:;此外,矩阵的每一行元素表示每个通道和所有其他通道之间的成对关系。对通道的平均成对关系进行建模,以获得通道的全局关系。然后,利用一个通道相对于其他通道的全局关系重要性来获得该通道在所有通道中的权重。
33.具体的如图3所示,先通过1*1卷积将输入张量的通道数量减少一半,然后通过3*3的分组卷积将特征图分为32个组,让每个组分别进行卷积,并填充一个值使特征图大小保持不变。另外,此3*3卷积保持通道数量不变。batchnormal(bn)层用来进行归一化,且利用relu激活函数增加非线性因素。之后,再利用1*1和3*3卷积使得通道数量与原始输入张量保持一致。
34.利用一个通道相对于其他通道的全局关系重要性来获得该通道在所有通道中的权重的过程为:将关系平均池化(rap)应用于矩阵,得到一个向量, 其中为通道数,此时,向量r的每个元素表示每个通道和所有通道之间的全局关系,将向量r的第个元素定义为。
35.。
36.采用softmax函数将所有全局关系转换为每个通道的权重。
37.;为了获得注意力图,先将向量变形为,然后将其广播为。最后,对原始特征图应用element
‑
wise multiplication和element
‑
wise sum来获得最终的特征。可以表示为:。
38.如图4所示,展示了sgam体系结构,空间注意力和通道注意力分别利用位置之间和通道之间的全局关系来确定每个位置和通道的重要性,它们的工作方式是相似的。但与cgam相比,sgam有三个不同之处。首先,设张量为sgam输入的特征图,与体系结构相同,均包含一个1*1卷积,一个bn层和一个relu函数,将通道的数量减少为,为缩减因子,在实验中设为2;由函数和得到张量和,并将变形为,将变形为;然后,采用矩阵乘法来确定位置间的成对关系且获得矩阵,。
39.其次,为了确定一个位置的重要程度,本发明对矩阵应用关系平均池化rap得到向量。向量的第个元素可以表示为:。
40.第三,本发明先将softmax函数生成的向量变形为,然后将其广播为。
41.在cgam和sgam中,将应用注意力后的特征图和原始特征图相加,得到最终的输出特征图。这里使用加法运算有两个原因。首先,这里使用的归一化函数是softmax, softmax函数是将权值映射到0到1的范围,并且所有权值之和为1。由于大量权值的存在,注意力模块输出的特征映射元素值可能较小,这将打破原有网络的特征,若不加上原始特征图,将给训练带来很大困难。其次,这一加法操作也突出了中的可靠的显著性信息。实验也表明,通过这种残差结构,模型具有很好的性能。与没有加法操作的模型相比,模型在map和top
‑
1上分别提高了1.2%/1.5%。
42.对于损失函数,使用最常见的交叉熵损失函数(cross entropy loss function)和三元组损失函数(triplet loss)。
43.交叉熵表示真实概率分布和预测概率分布之间的差异。可以表示为
;其中表示小批量中的图像数量,表示id的真实标签,表示第类的id预测对数。
44.三元组损失的目的是使具有相同标签的样本在嵌入空间中尽可能靠近,而具有不同标签的样本保持尽可能远的距离。本发明采用了batch
‑
hard triplet loss,对每个小批量随机抽取个身份和个图像,以满足batch
‑
hard triplet loss的要求。损失可以定义为;其中,,,是分别从锚点、正样本、负样本提取的特征,将的值设置为1.2,这有助于减少类内差异并扩大类间差异以提高模型性能。
45.总的训练损失是交叉熵损失和三元组损失的和,由;其中和是平衡两个损失项的超参数,实验中都设置为1,是分支数量。
46.实验:数据集:在两个常用的车辆重识别数据集上评估了本发明的模型,包括veri776和vehicleid。
47.veri776:它由大约5万张776辆汽车的图像组成,这些图像是由20个摄像头在不同的位置、不同的视角拍摄的。训练集包含576辆车,测试集包含剩下的200辆车。
48.vehicleid:它包含了分布在中国一个小城市的多个真实监控摄像头捕捉到的白天的数据。整个数据集中有26267辆汽车(221763张图片)。根据测试集的大小,提取出小、中、大三个测试集。在推理阶段,对每辆车随机选取一幅图像作为图库集,其他图像作为查询图像。
49.评估指标:在对每个数据集进行综合评价的基础上,采用cmc和map两指标,与现有方法进行了比较。cmc是在返回结果的前k中找到正确匹配的估计。map是一种综合考虑查询结果准确率和查全率的综合指标。
50.实施细则:选择resnet50作为生成特征的骨干网络。本发明对两个数据集采用相同的训练策略。每个像素的rgb三通道被归一化,图像大小在输入到网络之前被调整为256*256。从每个mini
‑
batch中随机抽取个身份,每个身份随机抽取个图像,以满足三元组损失的要求。在实验中,设置和来训练本发明提出的模型。对于三元组损失的margin参数,本发明在所有的实验中都设置为1.2。用adam作为优化器。对于学习率策略,设置初始学习率为2e
‑
4,在120 epoch后衰减到2e
‑
5,在220、320 epoch进一步下降到2e
‑
6、
2e
‑
7,以便更快地收敛。整个训练过程持续450个epoch.采用交叉熵损失和batch
‑
hard triplet loss一起来训练各分支。
51.在测试阶段,veri776数据集以image
‑
to
‑
track的形式进行测试。通过计算查询图像与图库集中所有图像之间的距离,将图像到图像的最小距离作为image
‑
to
‑
track的距离。对于vehicleid数据集,分别对其三个测试集进行测试。将三个分支的全连接层之前的特征连接,作为最终的输出特征。
52.实验结果:将所提出的模型与其他最先进的模型在两个数据集上的结果进行了比较。现有技术设计了局部最大遮挡表示(lomo)来解决视觉和光线变化的问题。为了在compcars数据集上获得更好的结果,对googlenet模型进行了微调,微调后的模型称为googlenet。然后采用sift、color name和googlenet特征对联合域的车辆进行识别。ram首先将图像水平分割成三部分,然后在这些局部区域嵌入详细的视觉线索。为了提高识别细微差异的能力,prn在车辆重新识别任务中引入了局部归一化(local normalization, pr)约束。基于解析的视图感知嵌入网络(pven)可以避免不同视图下局部特征的不匹配。生成式对抗网络(generative adversarial networks, gan)使用生成式模型和判别式模型相互学习以产生良好的输出。vami在gan的帮助下生成不同视图的特性。tamr提出了两级注意网络,以逐渐关注车辆视觉外观中细微但明显的局部细节,并提出了多粒排名损失学习结构化深度特征嵌入。
53.在veri776和vehicleid上的实验结果分别如表1和表2所示。在所有基于视觉的方法中,本发明的tgra方法取得了最好的效果,优于其他方法。由表1发现,首先,与pven相比,tgra在map上提高了2.7%,在cmc@1上提高了0.1%。其次,本发明的方法的cmc@5已经超过了99.1%,这在真实车辆重识别场景中是一个很有前景的性能。表2显示了在三个不同规模的测试数据集上的比较结果。本发明tgra在cmc@5上在不同的测试数据上比prn提高了4.0%+。需要注意的是,一些先进的网络模型需要利用其他辅助模型,这增加了算法的复杂度。例如,pven使用u
‑
net将一辆车解析成四个不同的视图。prn把yolo作为局部定位的检测网络。tamr采用stn自动定位挡风玻璃和车头部位。但是,本发明的模型在没有利用任何辅助模型的情况下仍具有更好的性能。
54.本发明模型在veri776的测试集上报告map为82.24%,cmc@1为95.77%,cmc@5为99.11%。在vehicleid的三个测试集上报告cmc@1为81.51%,95.54%,72.81%,cmc@5为96.38%,93.69%,91.01%。所有结果都是在单查询模式下获得的,没有进行重排序。表1:
表2:消融研究:在两个数据集上进行了大量实验,验证了tgra中关键模块的有效性。通过比较不同结构的性能,以确定所提模型的最优结构。
55.cgam和sgam的有效性:cgam和sgam分别是通道全局注意模块和空间全局注意模块。在veri776的测试集上的结果如表3所示。表3:
如表4所示,在 veri 776上验证局部分支的有效性。“w/o”是指没有;“local”是指tgra的局部分支;“part
‑3”ꢀ
和“part
‑
4”是指将特征图分别分成三或四部分的参考。
56.表4:本发明模型由三个分支组成,在两个全局分支上,通道全局注意力和空间全局注意力被用来提取可靠的显著性信息。本发明分别验证了sgam和cgam对模型的影响(表3)。从表3可以看出,在veri776的测试集上,与baseline相比,“baseline+sgam
”ꢀ
在map和cmc@1分别提高了0.6%和0.6%。此外,与baseline相比,“global
‑
c (branch)”在map上提高了1.7%,在cmc@1上提高了1.0%。然后,当带有cgam和sgam的两个分支同时训练时,与baseline相比,模型在map和cmc@1上得到5.0%和1.6%的提高。
57.此外,本发明还对全局注意力模块进行了定性分析,以便更直观地看到其有效性。实验结果表明带有全局注意力模块的网络可以准确地找到相同的车辆图像。当查询图像和目标图像处于不同视角时识别同一辆车是非常困难的,但本发明的模型也可以很好地识别同一辆车。因此,本发明的全局注意力模块在增强区别像素和抑制噪声像素方面具有很好的表现。
58.局部分支验证:tgra w/o local表示没有局部分支的tgra模型。为了充分验证本发明提出的局部分支的有效性,本发明还进行了两个实验,一个是将特征图划分为三部分,另一个是将其分为四部分。由表4可知,首先,在四个模型中,没有局部分支的tgra的性能最差,说明局部细节信息在车辆再识别任务中是至关重要的。第二,与“tgra (part
‑
3)”相比,“tgra (our)”在veri776的测试集上在map中提高了0.5%,在cmc@1中提高了0.6%。另外,可以看出划分数量越多,性能越差。这是由于不对齐和局部一致性破坏造成的。然而,本发明提出的局部分支可以在很大程度上解决这些问题。消融实验证明了该方法的有效性。
59.本发明提出了一个带有三分支的全局注意网络用于车辆重识别,该模型可以从多个角度提取车辆的有用特征。此外,在局部分支上,为了在很大程度上解决不对齐和局部一致性破坏的问题,本发明只将车辆特征图均匀地分成两部分。最后,通过全局注意力模块,该网络可以在车辆重识别任务中专注于最显著的部分,学习到更多的识别性和鲁棒性特
征。在测试阶段,将这三个分支的特征连接起来,以获得更好的性能。实验表明,在veri776和vehicleid数据集上,本发明的模型明显优于当前最好的模型。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1