实体和证据引导的关系预测系统及其使用方法与流程
实体和证据引导的关系预测系统及其使用方法
1.交叉引用
2.在本公开的描述中引用和讨论了一些参考文献,其可能包括专利、专利申请和各种出版物。提供此类参考文献的引用和/或讨论仅用于阐明本公开的描述,并不承认任何此类参考是本文所述公开的“现有技术”。在本说明书中引用和讨论的所有参考文献均通过引用整体并入本文,其程度与每个参考文献均单独通过引用并入相同。
技术领域
3.本公开一般涉及关系提取,更具体地,涉及实体和证据引导的关系提取(e2gre,entity and evidence guided relation extraction)。
背景技术:
4.在此提供的背景描述是为了概括地呈现本公开的上下文。目前发明人的工作,就其在本背景部分中描述的范围而言,以及在提交申请时可能不符合现有技术的描述的方面,均未明示或暗示承认为本公开的现有技术。
5.关系提取(re,relation extraction)提取纯文本中实体对之间的关系,是自然语言处理(nlp,natural language processing)中的一项重要任务。它具有对许多其他nlp任务的下游应用,例如知识图谱构建、信息检索、问答和对话系统。re可以通过手动构建的模式、引导方法、监督方法、距离监督和无监督方法来实现。这些方法通常涉及使用神经模型来学习关系。re的神经模型已经取得了进展。然而,这些神经模型和相关数据库只考虑语句内关系。
6.因此,在本领域中存在解决上述缺陷和不足的未解决的需求。
技术实现要素:
7.在一些方面,本公开涉及系统。在一些实施例中,系统包括计算设备,计算设备包括处理器和存储有计算机可执行代码的存储设备。计算机可执行代码在由处理器执行时被配置为:
8.提供头实体和包含所述头实体的文档;
9.通过语言模型处理所述头实体和所述文档,得到与所述头实体对应的头提取、与所述文档中的尾实体对应的尾提取以及与所述文档中的语句对应的语句提取;
10.使用第一双线性层预测所述头提取和所述尾提取之间的头实体-尾实体关系;
11.使用第二双线性层将所述语句提取和与所述头提取和所述尾提取对应的关系向量进行组合,得到语句-关系组合;
12.基于所述语句-关系组合和从所述语言模型中提取的注意力,使用第三双线性层从所述文档中预测证据语句,其中所述证据语句支持所述头尾关系;以及
13.基于预测的所述头实体-尾实体关系、预测的所述证据语句以及所述文档的标签,更新所述语言模型、所述第一双线性层、所述第二双线性层和所述第三双线性层的参数,其
中所述文档的标签包含真实头实体-尾实体关系和真实证据语句。
14.在一些实施例中,使用多个标注文档来训练所述语言模型、所述第一双线性层、所述第二双线性层和所述第三双线性层,所述标注文档中的至少一个标注文档具有e个实体,所述至少一个标注文档扩展为e个样本,所述e个样本中的每个样本包括所述至少一个标注文档和与所述e个实体之一对应的头实体,e为正整数。
15.在一些实施例中,所述计算机可执行代码被配置为基于损失函数更新所述参数,所述损失函数由定义,l
re
是关系预测损失、是语句预测损失、λ1是权重因子,所述权重因子具有等于或大于0的值。
16.在一些实施例中,所述语言模型包括以下至少之一:生成式预训练模型gpt、gpt-2、基于变换器的双向编码器表示bert、稳健优化的bert方法roberta以及重新参数化的变换器-xl网络xlnet。
17.在一些实施例中,所述计算机可执行代码被配置为从所述语言模型的最后2至5层提取所述注意力。在一些实施例中,所述计算机可执行代码被配置为从所述语言模型的最后3层提取所述注意力。
18.在一些实施例中,所述第一双线性层由定义,是头实体h和第k尾实体tk之间的多个关系中的第i关系的预测值,δ表示sigmoid函数,wi是所述第一双线性层的学习权重,bi是所述第一双线性层的偏置。在一些实施例中,所述第二双线性层由定义,是所述文档中的第j语句sj是对于第i关系ri的支持语句的预测概率,和是是所述第二双线性层关于所述第i关系的可学习参数。在一些实施例中,所述第三双线性层由定义,是所述文档中的第j语句是对关于所述第k尾实体的所述第i关系的支持语句的预测概率,δ表示sigmoid函数,是所述第三双线性层的学习权重,是所述第三双线性层的偏差。
19.在一些实施例中,在训练之后,所述语言模型、所述第一双线性层、所述第二双线性层和所述第三双线性层被配置为针对查询条目提供关系预测和证据预测,其中所述查询条目具有查询头实体和包含所述查询头实体的查询文档。
20.在一些实施例中,所述计算机可执行代码还被配置为提供所述文档的尾实体。
21.在一些方面,本公开涉及一种方法。在一些实施例中,方法包括:
22.由计算设备提供头实体和包含所述头实体的文档;
23.由所述计算设备中存储的语言模型处理所述头实体和所述文档,得到与所述头实体对应的头提取、与所述文档中的尾实体对应的尾提取以及与所述文档中的语句对应的语句提取;
24.由所述计算设备中存储的第一双线性层预测所述头提取和所述尾提取之间的头尾关系;
25.由所述计算设备中存储的第二双线性层将所述语句提取和与所述头提取和所述尾提取对应的关系向量进行组合,得到语句-关系组合;
26.由存储在所述计算设备中的第三双线性层基于所述语句-关系组合和从所述语言
模型中提取的注意力,从所述文档中预测证据语句,其中所述证据语句支持所述头尾关系;以及
27.基于预测的所述头实体-尾实体关系、预测的所述证据语句以及所述文档的标签,更新所述语言模型、所述第一双线性层、所述第二双线性层和所述第三双线性层的参数,其中所述文档的标签包含真实头实体-尾实体关系和真实证据语句。
28.在一些实施例中,更新参数的步骤是基于损失函数来执行的,所述损失函数由定义,l
re
是关系预测损失、是语句预测损失、λ1是权重因子,所述权重因子具有等于或大于0的值。
29.在一些实施例中,所述语言模型包括以下至少之一:生成式预训练模型gpt、gpt-2、基于变换器的双向编码器表示bert、稳健优化的bert方法roberta以及重新参数化的变换器-xl网络xlnet。
30.在一些实施例中,从所述语言模型的最后3层提取所述注意力。
31.在一些实施例中,其中所述第一双线性层由定义,是头实体h和第k尾实体tk之间的多个关系中的第i关系的预测值,δ表示sigmoid函数,wi是所述第一双线性层的学习权重,bi是所述第一双线性层的偏置;其中所述第二双线性层由是所述第一双线性层的偏置;其中所述第二双线性层由定义,是所述文档中的第j语句sj是第i关系ri的支持语句的预测概率,和是是所述第二双线性层关于所述第i关系的可学习参数;以及其中所述第三双线性层由定义,是所述文档中的第j语句是对关于所述第k尾实体的所述第i关系的支持语句的预测概率,δ表示sigmoid函数,是所述第三双线性层的学习权重,是所述第三双线性层的偏差。
32.在一些实施例中,方法还包括在训练好之后:针对查询条目提供关系预测和证据预测,其中所述查询条目具有查询头实体和包含所述查询头实体的查询文档。
33.在一些方面,本公开涉及一种存储有计算机可执行代码的非暂时性计算机可读介质,所述计算机可执行代码被计算设备的处理器执行时,被配置为执行上述方法。
34.本公开的这些方面和其他方面将通过结合以下附图及其标题对优选实施例的以下描述变得显而易见,尽管在不脱离本公开的新颖概念的精神和范围的情况下可以在其中进行变化和修改。
附图说明
35.附图示出了本公开的一个或多个实施例并与说明书一起用于解释本公开的原理。在可能的情况下,使用相同的附图标记来指代实施例的相同或相似元件。
36.图1示意性示出了根据本公开的一些实施例的证据引导的多任务学习框架。
37.图2示意性示出了根据本公开的一些实施例的证据引导的关系提取系统。
38.图3示出了来自docred数据库的条目的示例。
39.图4示意性示出了根据本公开的一些实施例的对证据引导的关系提取进行训练的过程。
40.图5示意性示出了根据本公开的一些实施例的关系预测的过程。
41.图6示出了docred上为首的公共排行榜数字,其中我们的e2gre方法使用roberta-large。
42.图7示出了对于docred的监督设置上的关系提取结果,其中以bert-base作为预训练语言模型,对e2gre和验证集上的其他已发布模型进行了比较。
43.图8示出了对实体引导的re与证据引导的re的消融研究,其中bert+联合训练是bert基线结合对re和证据预测的联合训练,并且在验证集上评估了结果。
44.图9示出了对来自bert的用于证据预测的不同数量的注意力概率层的消融研究。在开发集上评估了结果。
45.图10示出了docred示例的令牌化文档上的基线bert注意力热图。
46.图11示出了e2gre在docred示例的令牌化文档上的注意力热图。
具体实施方式
47.在以下示例中更具体地描述本公开,这些示例仅旨在作为说明,其中的许多修改和变化对于本领域技术人员来说将是显而易见的。现在详细描述本公开的各种实施例。参考附图,相同的数字指示相同的组件。除非上下文另有明确规定,否则本文的描述中和随后的权利要求中使用的“一”、“一个”和“所述”的含义包括复数参考。此外,如在本文的描述和随后的权利要求书中所使用的,“在...中”的含义包括“在...中”和“在...上”,除非上下文另有明确规定。并且,说明书中为了方便读者可以使用标题或副标题,而不影响本发明的范围。此外,本说明书中使用的一些术语在下文有更具体的定义。
48.本说明书中使用的术语在本领域中、在本公开的上下文中以及在使用每个术语的特定上下文中通常具有它们的普通含义。用于描述本公开的一些术语在下文或说明书中的其他地方讨论,以向从业者提供关于本公开的描述的额外指导。可以理解,同样的事情可以用不止一种方式说出来。因此,替代语言和同义词可用于此处讨论的任何一个或多个术语,并且对于此处是否详细阐述或讨论术语没有任何特殊意义。提供了某些术语的同义词。一个或多个同义词的使用不排除使用其他同义词。本说明书中任何地方的示例的使用,包括本文讨论的任何术语的示例,仅是说明性的,决不限制本公开内容或任何示例性术语的范围和含义。同样,本公开不限于本说明书中给出的各种实施例。
49.除非另有定义,本文使用的所有术语(包括技术和科学术语)与本公开内容所属领域的普通技术人员通常理解的含义相同。还应当理解,术语,例如在常用词典中定义的那些术语,应当被解释为具有与其在相关领域和本公开的上下文中的含义一致的含义,除非在此明确定义,否则不会以理想化或过于正式的意义进行解释。
50.如本文所用,术语“模块”可指代专用集成电路(asic)的一部分或包括专用集成电路(asic)、电子电路、组合逻辑电路、现场可编程门阵列(fpga)、执行代码的处理器(共享的、专用的或处理器组)、提供所描述功能的其他合适的硬件组件,或以上部分或全部的组合,例如在片上系统中。术语“模块”可以包括存储由处理器执行的代码的存储器(共享的、专用的或处理器组)。
51.在此使用的术语“代码”可以包括软件、固件和/或微代码,并且可以指程序、例程、函数、类和/或对象。上文使用的术语“共享”意味着可以使用单个(共享的)处理器执行来自多个模块的部分或全部代码。此外,来自多个模块的部分或全部代码可以存储在单个(共享
的)存储器中。上文使用的术语“组”意味着可以使用一组处理器执行来自单个模块的部分或全部代码。此外,可以使用一组存储器来存储来自单个模块的一些或全部代码。
52.如本文所用,术语“接口”通常是指在组件之间的交互点处通信工具或设备,用于执行组件之间的数据通信。通常,接口可以应用于硬件和软件层面,可以是单向或双向接口。物理硬件接口的示例可以包括电连接器、总线、端口、电缆、终端和其他i/o设备或组件。与接口通信的组件可以是例如计算机系统的多个组件或外围设备。
53.本公开涉及计算机系统。如图所示,计算机组件可以包括物理硬件组件,其显示为实线块,以及虚拟软件组件,其显示为虚线块。本领域普通技术人员将理解,除非另有说明,否则这些计算机组件可以以包括但不限于软件、固件或硬件组件或其组合的形式来实现。
54.在此描述的装置、系统和方法可以通过由一个或多个处理器执行的一个或多个计算机程序来实现。计算机程序包括存储在非暂时性有形计算机可读介质上的处理器可执行指令。计算机程序还可包括存储的数据。非暂时性有形计算机可读介质的非限制性示例包括非易失性存储器、磁存储和光存储。
55.现在将在下文中参考附图更全面地描述本公开,其中示出了本公开的实施例。然而,本公开可以以许多不同的形式体现并且不应被解释为限于这里阐述的实施例;相反,提供这些实施例是为了使本公开彻底和完整,并将本公开的范围充分传达给本领域技术人员。
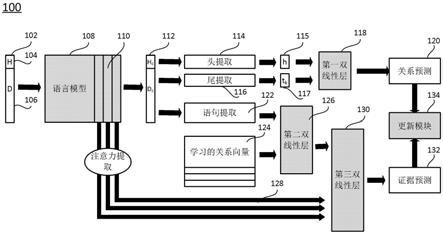
56.在一些方面,本公开涉及联合训练框架e2gre。在一些实施例中,首先,本公开引入实体引导序列作为预训练语言模型(lm,language model)的输入,例如基于变换器的双向编码器表示(bert,bidirectional encoder representaition from transformers)和稳健优化的bert方法(roberta,robustly optimized bert approach)。实体引导序列帮助lm关注与实体相关的文档区域。其次,本公开通过使用预训练的lm的内部注意力概率作为证据预测的附加特征来引导预训练的lm的微调。因此,公开的方法鼓励预训练的lm专注于实体和支持/证据语句。在一些实施例中,在docred上评估所公开的e2gre,其中docred是最近发布的用于关系提取的大规模数据集。e2gre能够在所有指标方面在公共排行榜上取得先进的结果,这表明e2gre在关系提取和证据预测方面既有效又协同。
57.具体地,在e2gre中,对于文档中的每个实体,本公开通过将实体附加到文档的开头来生成新的输入序列,然后将其馈送到预训练的lm。因此,对于具有ne个实体的每个文档,本公开生成ne个实体引导输入序列用于训练。通过引入这些新的训练输入,本公开鼓励预训练的lm关注附加到文档开头的实体。本公开通过直接使用内部注意力概率作为证据预测的附加特征进一步开拓预训练的lm。关系提取和证据预测的联合训练有助于模型对关系提取所需的正确语义进行定位。这两种策略都利用了预训练的lm,以便在我们的任务中充分利用预训练的lm。e2gre方法的主要贡献包括:(1)对于每个文档,本公开生成多个新输入以输入到预训练的语言模型中:本公开将每个实体与该文档连接起来,并将其作为输入序列提供给lm。这允许对来自要由实体引导的预训练的lm的内部表示进行微调。(2)本公开还使用内部bert注意力概率作为用于证据预测的附加特征。这允许对来自还将由证据/支持语句来引导的预训练的lm的内部表示进行微调,。
58.这些策略中的每一个策略都显著提高了性能,并且通过将它们结合起来,本公开能够在docred排行榜上实现先进的结果。
59.图1示意性示出了根据本公开的一些实施例的e2gre框架。如图1所示,框架100包括语言模型108、第一双线性层118、第二双线性层126、第三双线性层130和更新模块134。语言模型108、第一双线性层118、第二双线性层126、第三双线性层130和更新模块134也统称为模型或e2gre模型。可以向语言模型108提供样本102,样本102可以是训练样本或查询样本。在一些实施例中,本公开通过将头实体104附加到文档或上下文106的开头来组织样本102。头实体104也包含在文档106中。在一些实施例中,本公开还可以将样本组织成头实体104、尾实体和文档106。但是,有利的是在准备样本时不定义尾实体,这使得样本的准备和框架的运行更加高效。在一些实施例中,样本被制备成以下序列:“[cls]”+h+“[sep]”+d+“[sep]”,其中[cls]为放置在实体引导输入样本的开头的类令牌,[sep]为分隔符,h为单个实体第一次提及的令牌,d为文档令牌。文档d中共有ne个实体,包括头实体h和n
e-1个尾实体,其中ne是正整数。
[0060]
在一些实施例中,语言模型108是bert。bert只能处理最大长度为512个令牌的序列,由于这种限制,如果训练输入的长度大于512,本公开在文档上使用滑动窗口方法。如果输入序列长度大于512,则实施例将输入序列分解为两个序列或两个文档。在一些实施例中,这些实施例可以将更长的通道分成更多的窗口。第一序列是原始输入序列,最多有512个令牌。第二序列与第一序列的格式相同,在文档中添加了一个偏移量,以便第二序列可以到达末尾。这看起来像“[cls]”+h+“[sep]”+d[offset:end]+“[sep]”。实施例通过对令牌的嵌入和bert注意力概率进行平均(其中嵌入和bert注意力概率在模型中被计算了两次),将这两个输入序列组合在我们的模型中。
[0061]
在一些实施例中,当样本102是训练样本时,训练样本102还包括尾实体的标签、关系的标签和支持关系的证据语句的标签。例如,这些标签可以被第二双线性层126用于检索对应于头实体和尾实体的关系向量,或者被更新模块134用于计算与训练样本、所预测的关系、以及所预测的证据语句对应的损失函数。
[0062]
样本102被输入到语言模型108。在一些实施例中,语言模型108是预训练的语言模型(lm)。lm是近年来出现的极其强大的工具。最近的预训练lm是基于变换器的,并使用大量数据进行训练。在一些实施例中,语言模型108可以是任何一种语言模型,例如生成式预训练模型(gpt,generative pre-training model)、gpt-2、基于变换器的双向编码器表示(bert)、稳健优化的bert方法(roberta)、以及重新参数化的变换器-xl网络(xlnet)。
[0063]
语言模型108处理输入102,并产生输出序列112。可以通过头提取114从输出序列112中提取头实体115,可以通过尾提取116从输出序列112中提取尾实体117。头提取114对级联的头实体令牌上的嵌入进行平均以获得头实体嵌入h。尾提取116从输出序列中提取一组尾实体嵌入。对于第k尾实体嵌入tk,尾提取116定位第k尾实体的令牌的索引,并对这些索引处的bert的输出嵌入求平均以获得tk。
[0064]
在获得实体引导序列中的头实体嵌入和所有尾实体嵌入后,其中1≤k≤n
e-1和是具有d个维度的实数,实施例使用具有sigmoid激活函数的第一双线性层118来预测头实体h和第k尾实体tk之间的第i关系的概率,用表示,如下:
[0065][0066]
其中,δ是sigmoid函数,h
t
中的t是转置,wi和bi是第i关系对应的可学习参数,1≤i
≤nr,nr是表示关系总数的正整数。
[0067]
还可以通过如下的多标签交叉熵损失来微调诸如bert之类的语言模型108:
[0068][0069]
其中,y
ik
是训练样本中第i关系的真实值或标签,是关于头实体h和第k尾实体tk的第i关系的预测值。
[0070]
在推理过程中,关系提取的目标是预测文档中每对头/尾实体的关系。对于给定的实体引导输入序列“[cls]”+实体+“[sep]”+文档+“[sep]”,模型的输出是一组n
e-1个关系预测。本实施例将从同一文档中以不同头实体生成的每个序列的预测组合起来,从而得到对文档的所有关系预测。
[0071]
第一双线性118的输出是关系预测120。在一些实施例中,当预测值等于或大于0.5时,该关系被定义为预测关系。在一些实施例中,当所有关系的预测值都小于0.5时,表明对应的头实体和尾实体没有关系。在一些实施例中,通过关系提取预测的关系用于在推理/测试期间查询正确的关系向量。
[0072]
参考图1,语句提取122与获得的关系预测120可以一起用于预测证据/支持语句。证据语句包含支持事实,这些事实对于模型预测头实体和尾实体之间的正确关系很重要。因此,证据预测任务对于关系提取来说是一个很好的辅助任务,为多任务模型提供了可解释性。
[0073]
证据预测的目标是预测给定的语句是否是给定关系的证据/支持。给定一个语句s,实施例首先通过对语句s中所有词的嵌入求平均得到语句嵌入这些嵌入是从语言模型108的输出计算的语句提取122。同时,对于第i关系(1≤i≤nr),实施例将向量ri∈rd定义为关系嵌入。随机地初始化这些关系嵌入ri或关系向量124,并从模型中学习这些关系嵌入ri或关系向量124。在这里,rd是具有d个维度的实数。
[0074]
然后,实施例采用使用语句嵌入122和关系嵌入124的第二双线性层126。具体地,具有sigmoid激活函数的第二双线性层126用于预测第j语句sj是对于给定的第i关系ri的支持语句的概率,如下:
[0075][0076]
其中,sj和ri分别表示第j语句和第i关系的嵌入,是文档中的第j语句sj是对于第i关系ri的支持语句的预测概率,和是第二双线性层关于第i关系的可学习参数。在一些实施例中,可学习参数和称为权重,可学习参数和称为偏差。
[0077]
最后,假设给定上下文中有ns个语句,实施例如下定义了给定关系i下的证据预测损失:
[0078][0079]
其中,当语句j是用于推断第i关系的证据语句时,需要注意的是,在训练阶段,模型使用了等式(3)中真实关系的嵌入。在测试阶段,该模型使用等式
(1)中由关系提取模型预测的关系的嵌入。
[0080]
还可以用诸如bert之类的语言模型108的内部注意力概率来微调该模型。在一些实施例中,bert注意力概率确定bert模型将关注文档中的哪个位置。因此,这些注意力概率可以引导语言模型108关注文档中的相关区域以进行关系提取。在一些实施例中,本公开发现具有较高注意力值的区域通常来自支持语句。因此,在一些实施例中,这些注意力概率有助于证据预测。对于每对头h和尾tk,本公开利用从最后l个内部bert层中提取的注意力概率进行证据预测。
[0081]
在一些实施例中,令为查询,令为多头自注意层的关键字,nh是vaswani et al.,2017(通过引用整体并入本文)中描述的注意力头的数量,l是实体引导输入序列的长度,d是嵌入维度。本公开首先从bert中的给定层提取多头自注意力(mhsa,multi-headed self-attention)的输出,如下(图1中的注意力提取128):
[0082][0083][0084]
a=concat(att-headi,...,att-headn)
ꢀꢀ
(7)
[0085]
对于每对头h和尾tk,本公开的一些实施例提取与头和尾标记对应的注意力概率来帮助关系。具体地,实施例将等式(7)提取的最后l个bert层的mhsa级联起来,形成一个注意力概率张量:
[0086]
然后,实施例如下计算给定头-尾实体对下每个语句的注意力概率表示。
[0087]
1.实施例首先在上沿注意力头维度(即第二维度)应用最大池化层。最大值有助于显示特定注意力头可能正在查看的位置。之后,实施例在最后l层上应用平均池化。实施例从这两个步骤中获得
[0088]
2.然后,实施例根据文档中[第5页第483行-请定义“什么”]的开始和结束位置,从头实体标记和尾实体标记中提取注意力概率张量。实施例对头和尾嵌入的所有令牌的注意力概率进行平均以获得
[0089]
3.最后,实施例通过对文档中给定语句中的每个令牌的注意力进行平均来从生成语句表示,得到
[0090]
得到注意力概率α
sk
后,实施例将α
sk
与来自等式(3)的语句s的证据预测结果结合,形成新的语句表示,并将其馈入带有sigmoid的双线性层进行证据语句预测,如下:
[0091][0092]
其中是针对给定头/尾实体对的语句嵌入和关系嵌入的融合表示向量。
[0093]
最后,实施例基于注意力概率表示来定义给定第i关系下的证据预测损失,如下:
[0094]
[0095]
其中,是由等式(8)计算的的第j个值。
[0096]
实施例将关系提取损失和注意力概率引导的证据预测损失相结合,作为用于联合训练的最终目标函数:
[0097][0098]
其中l
re
是关系预测损失,是证据预测损失,λ1≥0是权重因子,用于在两个损失之间进行权衡,这两个损失是数据相关的。换言之,本公开不使用等式(2)和(9)的损失函数,而是将等式(10)的损失函数,即等式(2)和(9)的组合,用于整个模型。
[0099]
图2示意性示出了根据本公开的一些实施例的e2gre系统。e2gre执行关系预测和证据预测。如图2所示,系统200包括计算设备210。在一些实施例中,计算设备210可以是服务器计算机、集群、云计算机、通用计算机、无头计算机或专用计算机,计算设备210提供关系预测和证据预测。计算设备210可以包括但不限于处理器212、存储器214和存储设备216。在一些实施例中,计算设备210可以包括其他硬件组件和软件组件(未示出)以执行其对应的任务。这些硬件和软件组件的示例可以包括但不限于其他所需的存储器、接口、总线、输入/输出(i/o)模块或设备、网络接口和外围设备。
[0100]
处理器212可以是中央处理单元(cpu),其被配置为控制计算设备210的操作。处理器212可以执行计算设备210的操作系统(os)或其他应用程序。在一些实施例中,计算设备210可以具有多个cpu作为处理器,例如两个cpu、四个cpu、八个cpu或任何合适数量的cpu。
[0101]
存储器214可以是易失性存储器,例如随机存取存储器(ram),用于在计算设备210的操作期间存储数据和信息。在一些实施例中,存储器214可以是易失性存储器阵列。在一些实施例中,计算设备210可以在一个以上的存储器214上运行。在一些实施例中,计算设备210还可以包括图形卡以辅助处理器212和存储器214进行图像处理和显示。
[0102]
存储设备216是用于存储操作系统(未示出)和计算设备210的其他应用程序的非易失性数据存储介质。存储设备216的示例可以包括非易失性存储器,例如闪存、存储卡、usb驱动器、硬盘驱动器、软盘、光驱、固态驱动器或任何其他类型的数据存储设备。在一些实施例中,计算设备210可以具有多个存储设备216,这些存储设备可以是相同的存储设备或不同类型的存储设备,并且计算设备210的应用程序可以存储在计算设备210的一个或多个存储设备216中。
[0103]
在该实施例中,处理器212、存储器214和存储设备216是计算设备210的组件,例如服务器计算设备。在其他实施例中,计算设备210可以是分布式计算设备,处理器212、存储器214和存储设备216是来自预定义区域中的多个计算设备的共享资源。
[0104]
存储设备216尤其包括多任务预测应用程序218和训练数据240。在一些实施例中,e2gre应用程序218也被命名为e2gre模型,包括可以使用训练数据训练的模型权重,模型可用于使用受过良好训练的模型权重进行预测。训练数据240对于计算设备210是可选的,只要e2gre应用程序218可以访问存储在其他设备中的训练数据。
[0105]
如图2所示,e2gre应用程序218包括数据准备模块220、语言模型222、关系预测模块224、语句-关系组合模块226、注意力提取模块228、证据预测模块230和更新模块232。在一些实施例中,e2gre应用程序218可以包括e2gre应用程序218的操作所必需的其他应用程序或模块,例如用于用户向e2gre应用程序218输入查询的接口。应当注意,模块220~232都
是由计算机可执行代码或指令、数据表或数据库、或硬件和软件的组合来实现的,它们共同构成一个应用程序。在一些实施例中,每个模块还可以包括子模块。或者,一些模块可以组合为一个堆栈。在其他实施例中,一些模块可以被实现为电路而不是可执行代码。在一些实施例中,模块也可以统称为模型,可以使用训练数据对模型进行训练,训练好之后可以使用模型进行预测。
[0106]
数据准备模块220用于准备训练样本或查询数据,并将准备好的训练样本或查询数据发送给语言模块222。输入到语言模块222的准备好的训练样本包括头实体和包含头实体的文档或上下文。在一些实施例中,输入的训练样本的格式为“[cls]”+头实体+“[sep]”+文档+“[sep]”。头实体可以是一个词或几个词,如头实体“纽约市”或头实体“北京”。准备好的查询数据或查询样本与训练样本的格式相同。虽然每个训练样本中只有头实体和文档被用作语言模型222的输入,但尾实体的标签、尾实体、头实体和尾实体之间的关系以及证据语句都可用于在训练过程中计算损失函数和反向传播,从而优化模型的参数。这里的模型对应于e2gre应用程序218。
[0107]
在一些实施例中,训练数据集的示例可以是包含多个实体和实体之间的多个关系的文档,数据准备模块220被配置为将示例拆分为多个训练样本。例如,如果示例包括具有20个实体的文档,则数据准备模块220可以被配置为提供20个训练样本。每个训练样本包括20个实体之一,作为20个实体中的头实体、文档、头实体和相应尾实体之间的关系以及文档中支持该关系的证据语句。如果一个头实体与任何其他实体没有关系,则样本也可以作为负样本提供。几个样本中的每一个都可以单独用于训练过程。本公开通过将一个示例扩展为多个训练样本,提高了训练效率。
[0108]
图3示出了用于训练的docred样本。如图3所示,文档包括七个语句,头实体为“the legend of zelda”,尾实体为“link”。头实体和尾实体之间的关系是“发布者”。该关系得到语句0、3和4的支持。
[0109]
继续参考图2,在一些实施例中,数据准备模块220可以以“[cls]”+头实体+“[sep]”+尾实体+“[sep]”+文档+“[sep]”的形式准备输入样本”,而不是用“[cls]”+头实体+“[sep]”+文档+“[sep]”的形式。然而,没有定义尾实体的样本是优选的。通过只定义头实体和文档作为输入,加快了训练过程,并且模型参数收敛得更快。在一些实施例中,数据准备模块220被配置为将准备好的训练样本存储在训练数据240中。
[0110]
语言模型222被配置为在接收到来自数据准备模块220的训练样本之一后,对训练样本进行处理以获得输出序列,并将输出序列提供给关系预测模块224和语句-关系组合模块226.在一些实施例中,输出序列是多个向量,这些向量对应于头实体、文档中的词以及[cls]或[sep]令牌。向量也称为嵌入,这些嵌入是上下文化的。语言模型222可以是任何预训练的语言模型,例如gpt(radford et al.,2018,improving language understanding by generative pre-training)、gpt-2(radford et al.,2019,language models are unsupervised multitask learners)、bert(devlin et al.,2018,bert:pre-training of deep bidirectional transformers for language understanding)、roberta(liu et al.,2019,roberta:a robustly optimized bert pretraining approach)、以及xlnet(yang et al.,2019,xlnet:generalized autoregressive pretraining for language understanding),所引用的参考文献通过引用整体并入本文。在一些实施例中,语言模型
222是基于bert的,其中l=12,h=768,a=12。l是堆叠编码器的数量,h是隐藏大小,a是多头注意力层中的头的数量。在一些实施例中,语言模型222是bert large,其中l=24,h=1024,a=16。向量表示单词的特征,例如单词的含义和单词的位置。
[0111]
关系预测模块224用于当输出序列可用时,从输出序列中提取头实体,从输出序列中提取尾实体,对提取的头实体和尾实体的向量进行第一双线性分析,得到关系预测,并将关系预测提供给语句-关系组合模块226和更新模块232。在一些实施例中,提取的头实体是向量。当头实体包含多个词,输出序列中头实体的表示为多个向量时,将这些向量取平均值作为提取的头实体表示。在一些实施例中,可以使用例如命名实体识别器(named entity recognizer)来执行尾实体的提取。提取的尾实体是一个向量。由于文档中可能存在多个尾实体,因此存在多个尾实体表示。这些表示为向量,对输出序列中的多个向量求平均得到提取的尾实体。因此,尾实体的向量由其文本及其位置决定。在一些实施例中,从提取的尾实体中排除提取的头实体。在一些实施例中,当提取头实体和尾实体时,关系预测模块224被配置为使用上述等式(1)执行关系预测。提取的头实体和提取的尾实体形成多个头实体-尾实体对,对每一对进行关系预测。对于每个头实体-尾实体对,双线性分析将为每个关系提供结果。如果关于头实体-尾实体对的任何关系的结果在0至1的范围内。在一些实施例中,当结果等于或大于0.5时,表明头实体-尾实体对有对应关系。否则,头实体-尾实体对不存在对应关系。在一些实施例中,如果关于头实体-尾实体对的多于一种关系的结果等于或大于0.5,则表明头实体-尾实体对具有多于一种关系。如果头实体-尾实体对的所有关系结果都小于0.5,则说明头实体和尾实体之间没有关系。在训练期间,关系预测模块224不需要将头实体和尾实体之间的预测关系提供给语句-关系组合模块226,因为语句-关系组合模块226会使用训练样本的标签来确定头实体和尾实体是否有关系,如果有,会确定是什么关系。相反,在实际预测期间,关系预测模块224将向语句-关系组合模块226提供预测关系。具体地,预测/真实关系是用于查询使用哪个正确关系向量的索引。
[0112]
语句-关系组合模块226用于当输出序列可用时,从输出序列中提取语句,提供关系向量,将提取的语句与对应的关系向量通过第二双线性层组合,并将该组合提供给证据预测模块230。文档包括多个语句,输出序列包括语句中单词的向量。一般一个词对应一个向量,但是一个长词或者一个特殊词也可以拆分成两个或多个向量来表示。语句提取是通过对该语句中的词对应的词向量进行平均,得到该语句的一个向量。关系向量与模型中定义的关系相对应,关系向量的值可以在训练过程开始时随机初始化。然后可以在训练过程中更新关系向量的值。每个关系都有一个对应的关系向量。在训练过程中,当头实体-尾实体对与一个关系进行分析和预测时,可以从训练数据标签中得到头实体-尾实体对对应的真实关系,为组合选择真实关系对应的关系向量。在真实预测中,当头实体-尾实体对被分析预测有关系时,预测关系对应一个关系向量,针对组合来选择与预测关系对应的关系向量。在选择关系向量之后,语句-关系组合模块226被配置为使用上述等式(3)对语句提取和所选择的关系向量进行组合。例如,如果有4个语句,并且选择的真实关系或预测关系对应的关系向量有100个维度,则组合将是4个100维的语句向量。组合后,语句-关系组合模块226还用于将组合发送给证据预测模块230。
[0113]
注意力提取模块228被配置为在语言模型222的操作之后,从语言模型222的最后l层提取注意力概率,并将提取的注意力概率发送到证据预测模块230。在一些实施例中,语
言模型222是bert base,l在2至5的范围内。在一个实施例中,语言模型222是bert base,l是3。在一些实施例中,取决于具体的语言模型使用,l可以是其他值。在一些实施例中,本公开使用来自bert多头注意力层的注意力概率值作为注意力提取。
[0114]
证据预测模块230被配置为在接收到来自语句-关系组合模块226的语句提取和关系向量的组合以及来自注意力提取模块228的提取的注意力概率后,对该组合和提取的注意力概率进行第三双线性分析。以获得证据预测,并将证据预测提供给更新模块232。证据预测提供与对应关系最相关的语句。在一些实施例中,使用等式(9)执行第三双线性分析。
[0115]
更新模块232用于当关系预测模块224得到关系预测,证据预测模块230得到证据预测时,利用关系预测结果、证据预测结果和真实关系和真实证据语句的训练数据标签来计算损失函数,进行反向传播,以更新语言模型222、关系预测模块224、语句-关系组合模块226、注意力提取模块228和证据预测模块230的模型参数。在一些实施例中,损失函数是等式(12)的形式。在一些实施例中,在模型参数更新之后,可以使用新参数再次执行使用相同训练样本的训练过程。换句话说,对于每个训练样本,可能会有多轮训练以获得优化的模型参数。对于一个训练样本,可以在预定的轮数之后或在模型参数收敛之后结束重复的多轮训练。
[0116]
图4示意性示出了根据本公开的一些实施例的用于多任务预测的训练过程。在一些实施例中,训练过程由图2所示的服务器计算设备实现。需要特别说明的是,除非本公开中另有说明,训练过程或方法的步骤可以按照不同的顺序排列,因此不限于图4所示的顺序。
[0117]
如图4所示,在步骤402,数据准备模块220准备训练样本,并将训练样本发送到语言模型222。输入到语言模型222的训练样本是头实体和文档的形式,例如“[cls]”+头实体+“[sep]”+文档+“[sep]”。此外,训练样本中尾实体的标签、关系的标签和证据语句的标签可供更新模块232计算损失函数和反向传播。在一些实施例中,数据准备模块220可以以头实体、尾实体和文档的形式来准备输入样本,而不是头实体和文档的形式。但是没有定义尾实体的训练样本是优选的。
[0118]
在步骤404,语言模型222收到输入的训练样本后,对输入的训练样本进行处理得到输出序列,并将输出序列提供给关系预测模块224和语句-关系组合模块226。输入样本为文本格式,输出序列为向量格式。输出序列有头实体对应的向量、文档中单词对应的向量、以及[cls]或[sep]令牌对应的向量,表示样本的开始,样本的结束,头实体与上下文之间的分离,以及上下文中语句之间的分离。语言模型222可以是任何合适的预训练语言模型,例如gpt、gpt-2、bert、roberta和xlnet。继续参考图1,语言模型具有多层,最后k层110用于注意力提取。
[0119]
在步骤406,关系预测模块224从输出序列中提取头实体,并从输出序列中提取尾实体。提取的头实体和尾实体是向量。由于头实体在输入样本中定义并放置在[cls]标记之后,因此可以直接从输出序列中提取头实体。关系预测模块224还从输出序列的上下文部分提取多个尾实体。在一些实施例中,还可以在准备训练样本时提供尾实体。在一些实施例中,关系预测模块224将来自上下文的关键元素识别和分类为尾实体。例如,尾实体可以对应于位置、公司、人名、日期和时间。在一些实施例中,使用命名实体识别器提取尾实体。在一些实施例中,从提取的尾实体中排除提取的头实体。
[0120]
在步骤408,在提取头实体和尾实体后,关系预测模块224预测所提取的头实体和每个提取的尾实体之间的关系,将头-实体-尾实体对提供给语句-关系组合模块226,并将预测的关系提供给更新模块232。在一些实施例中,关系预测模块224执行头实体和每个尾实体之间的成对关系预测。对于每个头实体-尾实体对,关系预测模块224使用双线性层来产生每个关系的预测值。关系的总数可以不同,例如docred中列出97个关系。当头实体-尾实体对的多个关系之一的值等于或大于0.5时,将头实体-尾实体定义为具有该关系。在一些实施例中,头实体-尾实体对可以具有不止一种关系。当头实体-尾实体对的多个关系中没有一个值等于或大于0.5时,定义头实体-尾实体没有关系。在一些实施例中,多个关系可以包括一个关系为“无关系”,在头实体-尾实体对没有关系时给出该关系。在一些实施例中,使用等式(1)来执行关系预测。请注意,关系预测模块224在训练时不必向语句.关系组合模块226提供预测关系,但需要在预测时向语句-关系组合模块226提供预测关系。
[0121]
在步骤410,当输出序列可用时,语句-关系组合模块226从输出序列中提取语句。具体地,上下文包括多个语句,语句中的每个词在输出序列中由一个或几个向量表示。对于输出序列中的每个语句,将语句中的词对应的词向量取平均得到一个向量,称为语句向量。因此,所提取的语句包括多个语句向量,每个语句向量代表文档中的一个语句。
[0122]
在步骤412,语句-关系组合模块226提供关系向量,将提取的语句与关系向量之一组合,并将组合发送到证据预测模块230。关系向量对应于模型中所有待分析的关系,组合中使用的关系向量之一对应于步骤408中的头实体-尾实体对的标注关系。在一些实施例中,使用等式(3)执行语句-关系组合。请注意,语句-关系组合模块226从训练样本中获取实体之间的关系,即从训练期间的真实关系标签中获取。对于docred,关系向量的数量可以是97。在训练过程开始时,可以随机生成关系向量的值,并在接下来的训练过程中更新关系向量的值。在一些实施例中,关系向量的值也可以存储在训练数据240中。语句-关系组合模块226使用第二双线性层126来执行语句向量和与真实关系对应的关系向量的组合。
[0123]
在步骤414,在执行语言模型222之后,注意力提取模块228从语言模型222的最后l层提取注意力概率,并将注意力概率提供给证据预测模块230。在一些实施例中,l的值取决于语言模型222的复杂度和训练数据的复杂度。在一些实施例中,当语言模型222是bert base模型时,l在2~5的范围内。在一个实施例中,l是3。
[0124]
在步骤416,在从语句-关系组合模块226接收语句提取和关系向量的组合,以及从注意力提取模块228接收注意力概率后,证据预测模块230使用第三双线性层130预测支持该关系的证据语句。在一些实施例中,使用等式(9)执行证据预测。
[0125]
在步骤418,当关系预测和证据预测完成时,更新模块232使用预测和训练数据标签计算损失函数,并基于损失函数更新模型的参数。在一些实施例中,使用等式(10)计算损失函数。
[0126]
在步骤420,在更新模型参数之后,可以使用相同的训练样本再次执行训练步骤402~418以优化模型参数。使用相同样本的训练迭代可以在预先确定的迭代次数之后完成,或者直到模型参数收敛。在使用一个训练样本进行训练之后,使用另一训练样本重复上述训练步骤402~420。当模型的参数在使用一组样本训练后收敛时,模型就被微调并准备好进行预测。在一些实施例中,训练过程也可以在执行预定轮次的训练过程时停止。
[0127]
图5示意性示出了根据本公开的一些实施例的用于关系预测和证据预测的方法。
在一些实施例中,预测过程由图2所示的服务器计算设备实现。需要特别说明的是,除非本公开中另有说明,训练过程或方法的步骤可以按照不同的顺序排列,因此不限于图5所示的顺序。
[0128]
如图5所示,方法500包括步骤502~516,其与步骤402~416基本相同。但是,查询样本包括头实体和上下文,但不包括尾实体标签、关系标签和证据语句标签。进一步地,在步骤412中,所提取的序列和关系向量的组合使用了来自训练样本的与步骤408中分析的头实体-尾实体对相对应的真实标注关系,而在步骤512中,组合使用了与步骤508中预测的关系对应的关系向量。
[0129]
在一些实施例中,当用户只需要关系预测而不需要证据预测时,该模型也可以被用来只操作关系预测部分,使得预测速度更快。虽然包括步骤510~516的证据预测不是必需的,但是经过良好训练的模型仍然通过语言模型参数考虑证据预测的贡献。具体地,关系预测仍然考虑了它应该赋予更多权重的语句,因此关系预测比不考虑证据预测更准确。
[0130]
在一些实施例中,模型还可以为样本定义头实体、尾实体和上下文,而不是为样本定义头实体和上下文。然而,这会消耗更多的计算资源,因此头实体和上下文格式化的训练样本和查询样本比头实体、尾实体和上下文格式化的样本更优选。
[0131]
在某些方面,本公开涉及一种存储计算机可执行代码的非暂时性计算机可读介质。在一些实施例中,计算机可执行代码可以是存储在如上所述的存储设备216中的软件。计算机可执行代码在被执行时可以执行上述方法之一。
[0132]
进行了证明本公开实施例的优点的实验。实验中使用的数据集是docred。docred是用于关系提取和证据语句预测任务的大型文档级数据集。它由从维基百科文章中挖掘的5053个文档、132375个实体和56354个关系组成。对于每个(头,尾)实体对,有97种不同的关系类型作为要预测的候选关系类型,其中第一关系类型是两个实体之间的“na”关系(即没有关系),其余对应于一个wikidata关系名称。每个包含有效关系的头/尾对还包括一组支持证据语句。我们遵循(yao et a1.,2019)中的相同设置将数据拆分为训练/验证/测试进行模型评估以进行公平比较。训练/验证/测试中的文档数量分别为3000/1000/1000。
[0133]
使用关系提取指标re f1和证据evi f1对数据集进行评估。还存在在验证和训练集中出现有关系的事实的情况,因此我们还评估了ign re f1,其中删除了这些有关系的事实。
[0134]
实验设置如下。首先是超参数设置。bert-base模型的配置遵循(devlin et al.,2019)中的设置。将学习率设置为1e-5
,λ1设置为1e-4
,关系向量的隐藏维度设置为108,并从最后三个bert层中提取内部注意力概率。
[0135]
通过微调bert-base模型来进行大部分实验。该实现基于bert的pytorch(paszke et al.,2017)实现。在单个v100gpu上将我们的模型运行60次迭代(epoch),得到大约一天的训练。docred基线和我们的e2gre模型有1.15亿个参数。
[0136]
将我们的模型与以下四个已发布的基线模型进行比较。
[0137]
1.上下文感知bilstm。yao et al.,2019在他们的论文中介绍了docred的原始基线。他们使用上下文感知bilstm(+附加功能,如实体类型、共指和距离)对文档进行编码。然后提取头和尾实体以进行关系提取。
[0138]
2.bert两步法。wang et al.,(2019)在两步过程中引入了微调bert,其中模型首
先预测na关系,然后预测其余关系。
[0139]
3.hin。tang et al.,(2020)介绍了使用分层推理网络来帮助聚合从实体到语句并进一步到文档级别的信息,以获得对整个文档的语义推理。
[0140]
4.bert+lsr。nan et al.,(2020)介绍了使用诱导潜在图结构来帮助学习信息应该如何在文档中的实体和语句之间流动。
[0141]
如图6的表1所示,我们的方法e2gre是docred公共排行榜上当前先进的模型。
[0142]
图7的表2将我们的方法与基线模型进行了比较。从表2中可以看出我们的e2gre方法不仅与开发集上之前的最佳方法相比具有竞争力,而且与之前的模型相比还具有以下优势:(1)与hin模型和bert+lsr模型相比,我们的方法在设计上更直观、更简单。此外,我们的方法提供了具有支持证据预测的可解释关系提取。(2)我们的方法在ign re f1指标上也优于所有其他模型。这表明我们的模型不会记住实体之间的关系事实,而是检查文档中的相关区域以生成正确的关系提取。
[0143]
与原始bert基线相比,由于多个新的实体引导输入序列,我们的训练时间略长。我们研究了基于每个头尾实体对生成新序列的想法,但这种方法将与文档中的实体数量成二次方扩展。使用我们的实体引导方法可以在性能和训练时间之间取得平衡。
[0144]
我们还进行了消融研究。图8的表3示出了我们的方法对实体引导和证据引导的训练的有效性的消融研究。这里的基线是采用bert-base的情况下关系提取和证据预测的联合训练模型。我们看到实体引导的bert比这个基线提高了2.5%,证据引导的训练进一步将方法提高了1.7%。这表明我们方法的两个部分对整个e2gre方法都很重要。与此基线相比,我们的e2gre方法不仅在关系提取f1上获得了改进,而且在证据预测方面也获得了显着改进。这进一步表明我们的证据引导的微调方法是有效的,与证据引导的联合训练更有助于关系提取。
[0145]
我们还进行了实验来分析用于获得注意力概率值的bert层数的影响。如图9的表4所示,可以看出使用更多层不一定对关系提取更好。一个可能的原因可能是bert模型在中间层编码了更多的句法信息(clark et al.,2019)。
[0146]
图3示出了我们模型验证集中的一个示例。在图3的例子中,“the legend of zelda”和“link”之间的关系依赖于给定文档中多个语句的信息。
[0147]
图10示出了简单地应用bert进行关系提取的注意力热图。这张热图显示了从“the legend of zelda”和“link”中得到的每个词的注意力。可以看出模型能够定位到“link”和“legend of zelda series”的相关区域,但对文档其余部分的注意力值非常小。因此,该模型在提取文档中的信息以生成正确的关系预测方面存在困难。
[0148]
相比之下,图11示出我们的e2gre模型突出了证据语句,特别是在该模型找到相关信息的区域。与“link”和“the legend of zelda series”相关的短语被分配了更高的权重。将这些短语连接在一起的词(例如“protagonist”或“involves”)也具有很高的权重。此外,e2gre的注意力概率的规模也远大于基线的规模。所有这些短语和连接词都位于证据语句中,使我们的模型也能更好地进行证据预测。
[0149]
总之,为了针对文档级re更有效地拓展预训练的lm,提供了一种新的实体和证据引导的关系提取(e2gre)方法。首先生成新的实体引导序列以馈入lm,使模型关注于文档中的相关区域。然后利用从最后l层提取的内部注意力来帮助引导lm关注于文档的相关区域。
我们的e2gre方法提高了docred数据集上的re和证据预测方面的性能,并在docred公共排行榜上实现了先进的性能。
[0150]
在一些实施例中,还将我们关于使用注意力引导的多任务学习的构思与具有证据语句的其他nlp任务结合起来。在一些实施例中,将我们的方法与针对nlp任务的基于图形的模型相结合。在一些实施例中,还将我们的方法与图形神经网络相结合。
[0151]
本公开的示例性实施例的前述描述仅出于说明和描述的目的而呈现并且不旨在穷举或将本公开限制为所公开的精确形式。根据上述教导,许多修改和变化是可能的。
[0152]
选择和描述实施例是为了解释本公开的原理及其实际应用,从而使本领域的其他技术人员能够利用本公开和各种实施例以及适合于预期的特定用途的各种修改。在不脱离本公开的精神和范围的情况下,替代实施例对于本公开所属领域的技术人员将变得显而易见。因此,本公开的范围由所附权利要求而不是前述描述和其中描述的示例性实施例限定。
[0153]
参考文献(通过引用整体并入本文):
[0154]
1.christoph alt,marc hubner,and leonhard hennig,improving relation extraction by pre-trained language representations,2019,arxiv:1906.03088.
[0155]
2.livio baldini soares,nicholas fitzgerald,jeffrey ling,and tom kwiatkowski,matching the blanks:distributional similarity for relation learning,proceedings of the 57th annual meeting of the association for computational linguistics,2019,2895-2905.
[0156]
3.razvan bunescu and raymond mooney,a shortest path dependency kernel for relation extraction,proceedings of human language technology conference and conference on empirical methods in natural language processing,.2005,724-731.
[0157]
4.rui cai,xiaodong zhang,and houfeng wang,bidirectional recurrent convolutional neural network for relation classification,proceedings of the 54th annual meeting of the association for computational linguistics,.2016,1:756-765.
[0158]
5.fenia christopoulou,makoto miwa,and sophia ananiadou,connecting the dots:document-level neural relation extraction with edge-oriented graphs,proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing(emnlp-ijcnlp),.2019,4924-4935.
[0159]
6.kevin clark,urvashi khandelwal,omer levy,and christopher d.manning,what does bert look at?an analysis of bert’s attention,2019,arxiv,abs/1906.04341.
[0160]
7.jacob devlin,ming-wei chang,kenton lee,and kristina toutanova,bert:pre-training of deep bidireetional transformers for language understanding,proeeedings of the 2019 conferenee of the north american chapter of the association for computational linguistics:human language technologies,.2019a,1:4171-4186.
minlie huang,augmenting end-to-end dialog systems with commonsense knowledge,thirty-second aaai conference on artificial intelligence,2018,4970-4977.
[0184]
31.mo yu,wenpeng yin,kazi saidul hasan,cicero dos santos,bing xiang,and bowen zhou,improved neural relation detection for knowledge base question answering,proceedings of the 55th annual meeting of the association for computational linguistics,2017,1:571-581.
[0185]
32.dmitry zelenko,chinatsu aone,and anthony richardella,kernel methods for relation extraction,journal of machine learning research,.2003,3:1083-1106.
[0186]
33.daojian zeng,kang liu,siwei lai,guangyou zhou,and jun zhao,relation classification via convolutional deep neural network,proceedings of coling 2014,the 25th international conference on computational linguistics:technical papers,2014,2335-2344.
[0187]
34.yuhao zhang,victor zhong,danqi chen,gabor angeli,and christopher d.manning,position-aware attention and supervised data improve slot filling,proceedings of the 2017 conference on empirical methods in natural language processing(emnlp2017),2017,35-45.
[0188]
35.yi zhao,huaiyu wan,jianwei gao,and youfang lin,improving relation classification by entity pair graph,proceedings of the eleventh asian conference on machine learning,proceedings of machine learning research,2019,10l:1156-1171。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1