一种基于神经网络的多数据中心动态副本放置方法
1.本发明主要涉及到云数据中心存储领域,具体涉及到多数据中心动态副本放置领域。
背景技术:
2.随着云计算技术的快速发展,数据密集型应用的出现,导致互联网应用的数据量呈爆发式增长。越来越多的用户和企业应用程序被托管在云中,以至于大部分用户数据都被存放在远程数据中心存储和管理,云计算服务提供商将虚拟化资源通过网络租赁给用户并按需求提供,此外资源通过按使用付费模式提供服务,用户可以根据自身的使用情况为所需资源付费。
3.对于大多数用户来说,数据中心的位置对用户是完全透明的,主要关心的是他们是否可以随时随地访问和快速检索所需的数据信息。而在这一方面互联网公司取得了很大进展,例如谷歌、亚马逊,它们的应用程序为分散在世界各地的数亿用户提供服务,其中谷歌在15个国家至少拥有30多个数据中心,大约有 900k服务器。因此为了提供可靠的服务以及高数据可用性和性能等要求,通常需要用到数据复制的概念,将数据放置到位于不同地理位置的数据中心,由于单一数据中心的数据副本不能满足大量用户的访问请求,导致用户数据的安全性和可靠性都得不到保障,也会提高服务提供商的经济成本,所以考虑将数据的多个副本放置在多个不同的数据中心,以保证数据的可靠性和安全性。但是在放置数据副本的时候需要考虑,什么时候创建副本,如何控制副本的数量,以及不同的数据中心通常具有不同的存储容量和性能,如何在保证数据的可用性,用户的响应延迟下找到一个合适的放置位置将服务提供商的利润最大化。
4.目前有较多的研究人员与相关学者提出了考虑文件的访问量来计算副本数,但都是检测文件当前的实际访问量来计算副本数,或者用预测算法来预测文件下一周期的访问量来计算副本数,但是在实际应用情况下的用户访问特征多变且规律模糊,预测算法无法准确的预测实际情况下的访问量,在副本放置方面,很多研究者只是考虑了固定的副本数,或者单一目标下的放置,而实际情况下文件副本数是动态变化的,数据中心之间存在异构性,副本放置的多个目标优化都是需要考虑的,因此,针对以上情况本发明设计了一种基于神经网络的多数据中心动态副本放置方法。
技术实现要素:
5.本发明公开了一种基于神经网络的多数据中心动态副本放置方法,它通过lstm神经网络提升文件访问量预测精度,再以降低违规惩罚,和数据中心的负载标准差为目标的动态副本放置方法。
6.本发明提供的基于神经网络的多数据中心动态副本放置方法,包括以下步骤:
7.步骤1、根据文件的历史访问记录,统计文件的各个周期的访问量;
8.步骤2、使用lstm神经网络预测文件下一周期的访问量;
9.步骤3、计算文件的可用性,可用性差值用来确定该文件的最小副本数;
10.步骤4、根据步骤2和步骤3计算各个文件的副本数;
11.步骤5、计算数据中心对文件访问请求的平均处理时间,建立惩罚代价目标函数;
12.步骤6、计算各个数据中心的负载,建立负载目标函数;
13.步骤7、以降低惩罚代价和标准差构建优化函数,对文件副本进行放置;
附图说明
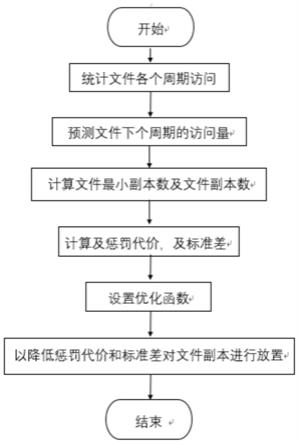
14.图1是本发明的流程图;
15.图2是本发明的放置步骤图;
具体实施方式
16.如图1所示,本发明方法的具体实施过程步骤为:
17.步骤1、周期性的采集各个文件的历史访问记录,以{f1,f2,
…
,f
k
}为文件数,文件f
i
的各个周期访问量以表示,以1小时为一周期,用t表示;
18.步骤2、使用lstm神经网络预测文件f
i
下一个时间段的访问量;
19.1)假设3个文件的11个周期的访问量如下:
[0020][0021]
2)使用lstm神经网络预测结果为:
[0022][0023]
步骤3、计算文件f
i
的最小副本数:
[0024]
1)计算文件文件f
i
可用性
[0025][0026][0027]
其中p
j
为数据中心j的节点可用概率,x(i,j)为0/1矩阵,文件i放置在数据中心j上则x(i,j)=1,否则为0,表示为文件i的副本数;
[0028]
2)计算文件f
i
的可用性差值δp
i
:
[0029][0030]
3)设置可用性差值阈值α,当可用性差值δp
i
<α时,则此时的设为文件f
i
的最优可用性,设为文件i的最小副本数
[0031]
步骤4、计算文件f
i
的副本数
[0032][0033][0034]
其中为文件f1的大小,ca
j
为数据中心j的存储总容量大小;
[0035]
步骤5、计算数据中心对文件访问请求的平均处理时间,及惩罚代价:
[0036]
1)假设数据中心j中访问文件f
i
的请求服从平均请求到达率为λ
j
的泊松分布,各请求的平均请求服务速率相互独立,服从于参数为μ
j
的指数分布,为文件f
i
分配到数据中心j的副本数,根据m/m/c排队模型对数据中心的请求处理时间问题进行模拟,则数据中心j对
文件f
i
的单位请求的平均处理时间dt
j
为:
[0037][0038][0039]
2)假设用户到数据中心端到端的平均延迟为d
avg
,则数据中心j单位请求的响应时间为:
[0040]
rt
j
=dt
j
+d
avg
[0041]
3)当rt
j
>rt
max
时就会产生惩罚代价,则对于数据中心j中所有文件的请求惩罚代价函数可以表示为:
[0042][0043]
其中λ
i,j
为数据中心j中文件i的请求访问量,β为数据中心j对单位请求的延迟惩罚代价系数,rt
max
表示为用户对文件的最大响应时间要求;
[0044]
4)则将k个文件放置到m个数据中心的惩罚代价目标函数sla表示为:
[0045][0046]
步骤6、计算各个数据中心的负载,及负载标准差:
[0047]
1)数据中心j的负载为:
[0048][0049]
2)所有数据中心的平均负载计算如下:
[0050][0051]
3)将所有数据中心的负载与平均负载的标准差作为衡量系统的负载均衡的标准,则负载目标函数表示为:
[0052][0053]
步骤7、以降低惩罚代价和标准差构建优化函数,对文件副本进行放置:
[0054]
优化函数表示为:
[0055]
min f=w1*sla+w2*l
s
[0056]
s.t.w1+w2=1
[0057]
s.t.w1,w2∈[0,1]
[0058]
1)设置最大迭代次数m,随机生成n个个体的种群,并计算惩罚代价及负载方差目
标函数值,每个个体代表对副本的一种分配方案;
[0059]
2)如果个体a的惩罚代价目标函数值及负载方差目标函数值都小于等于个体b的惩罚代价目标函数值及负载方差目标函数值,则称a支配b,首先在种群中随机选择两个个体a,b进行目标函数值比较,如果a支配b,则选择a生成新的种群,否则选择b,如果a,b不互相支配,则随机选择 a,b其中一个,生成新的种群;
[0060]
3)以w1=0.4,w2=0.6计算所有个体优化函数值,并按照非降序的顺序排列,选择最小优化函数值为最佳个体;
[0061]
4)判断是否达到最大迭代次数,如果没有达到最大迭代次数则继续返回1)执行,如果达到最大迭代次数则将最佳个体作为副本放置方案。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1