一种面向内河航标的事故数据挖掘方法与系统
1.本发明属于数据处理领域,具体涉及一种面向内河航标的事故数据挖掘方法与系统。
背景技术:
2.内河水路交通系统是一个由人员、船舶、航道、助航设施、通航环境等多要素构成的复杂系统,各个因素间相互影响,导致内河航标、船舶等事故发生具有显著的不确定性,对内河通航安全监管、风险分析与防控等带来挑战。基于历史事故数据开展交通事故规则解析是目前该领域重要的研究方法之一,可为内河复杂通航环境下的航标事故配布优化、维护管理、预警预防等提供技术支撑。
3.内河航标事故关联规则挖掘,需要事先采集多个属性维度的航标事故数据并进行整合处理,步骤繁琐、工作量大。以内河航标为例,当前内河助航设施多维事故数据集缺失严重,缺少开源数据与平台,使得内河航标事故关联规则挖掘工作难以开展。
4.针对内河助航设施,对应河段某一时间下的事故关联信息包括:人员因素、设施因素、管理因素、环境因素等。各特征要素之间差异大,缺少助航设施事故的数据整合与挖掘算法;错误的数据集整合处理方式容易生成大量无意义的关联规则,极大程度的影响算法执行效率与结果准确性。
技术实现要素:
5.本发明的目的在于,提供一种面向内河航标的事故数据挖掘方法与系统,能够实现内河复杂通航环境下航标事故关联分析,为内河航标维护决策、事故预防提供技术支撑。
6.为解决上述技术问题,本发明的技术方案为:一种面向内河航标的事故数据挖掘方法,包括以下步骤:
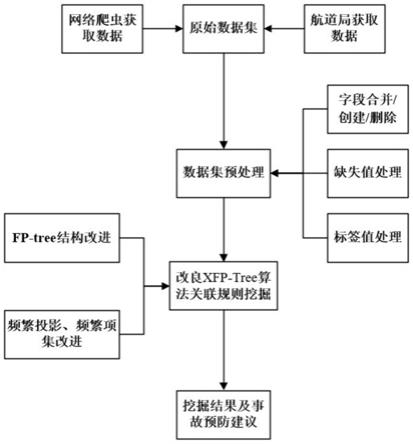
7.s1、获取多组内河航道任意指定河段发生事故前后的某一时间段的通航环境信息,并通过航道管理部门获取该时间段的航标属性信息、航道特征信息和事故报警信息,将以上信息汇总生成原始数据集;
8.s2、对原始数据集进行预处理,生成内河航标事故数据集;预处理至少包括字段的合并、创建及删除,缺失值处理和标签值处理;
9.s3、对内河航标事故数据集进行内在关联规则的挖掘;
10.s4、生成挖掘结果和事故预防建议。
11.所述s3具体为:
12.s3.1、以xfp
‑
tree关联规则挖掘算法为基础,对内河航标事故数据集进行内在关联规则的挖掘;
13.s3.2、针对fp
‑
tree结构,添加标签内容,通过标签协助算法判断频繁项对应前缀是否为单一路径,降低xfp
‑
tree算法工作量;
14.s3.3、对fp
‑
tree算法的树结构进行剪枝,同时对算法频繁投影、频繁项集,添加关
联规则挖掘的条件判断,抑制研究意义较小的关联规则生成,提升算法执行效率。
15.对fp
‑
tree算法的树结构进行剪枝的具体过程为:在遍历算法fp
‑
tree结构时,若树结构存在一个分枝,当该分枝的节点m在该分枝上的支持度计数小于事先设定的最小支持度阈值时,便搜索该节点在树结构中其他分枝的位置;判断节点m初始分枝上子节点的集合是否包含其在新分枝上的子节点集合,若包含,那么剪掉节点m的初始分枝,并将新旧分枝中相似节点的支持度计数相加,以更新新分支上节点的支持度计数。
16.所述s1具体为:通过python网页爬虫方式获取多组内河航道任意指定河段发生事故前后的某一时间段的通航环境信息,并通过航道管理部门获取该时间段的航标属性信息、航道特征信息和事故报警信息,将以上信息汇总生成原始数据集;所述通航环境信息至少包括水位、天气和风速风向等信息。
17.还提供一种用于实现上述的一种面向内河航标的事故数据挖掘方法的系统,包括:
18.采集模块,用于获取多组内河航道任意指定河段发生事故前后的某一时间段的通航环境信息,并通过航道管理部门获取该时间段的航标属性信息、航道特征信息和事故报警信息,将以上信息汇总生成原始数据集;
19.预处理模块,用于对原始数据集进行预处理,生成内河航标事故数据集;预处理至少包括字段的合并、创建及删除,缺失值处理和标签值处理;
20.挖掘模块,用于对内河航标事故数据集进行内在关联规则的挖掘;
21.输出模块,用于生成挖掘结果和事故预防建议。
22.所述挖掘模块的具体工作过程为以xfp
‑
tree关联规则挖掘算法为基础,对内河航标事故数据集进行内在关联规则的挖掘;针对fp
‑
tree结构,添加标签内容,通过标签协助算法判断频繁项对应前缀是否为单一路径,降低xfp
‑
tree算法工作量;对fp
‑
tree算法的树结构进行剪枝,同时对算法频繁投影、频繁项集,添加关联规则挖掘的条件判断,抑制研究意义较小的关联规则生成,提升算法执行效率。
23.对fp
‑
tree算法的树结构进行剪枝的具体过程为:在遍历算法fp
‑
tree结构时,若树结构存在一个分枝,当该分枝的节点m在该分枝上的支持度计数小于事先设定的最小支持度阈值时,便搜索该节点在树结构中其他分枝的位置;判断节点m初始分枝上子节点的集合是否包含其在新分枝上的子节点集合,若包含,那么剪掉节点m的初始分枝,并将新旧分枝中相似节点的支持度计数相加,以更新新分支上节点的支持度计数。
24.所述采集模块的具体工作过程为:通过python网页爬虫方式获取多组内河航道任意指定河段发生事故前后的某一时间段的通航环境信息,并通过航道管理部门获取该时间段的航标属性信息、航道特征信息和事故报警信息,将以上信息汇总生成原始数据集;所述通航环境信息至少包括水位、天气和风速风向等信息。
25.还提供一种计算机设备,包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述任一项所述方法的步骤。
26.还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如上述任一项所述方法的步骤。
27.与现有技术相比,本发明的有益效果为:
28.本发明能够实现内河复杂通航环境下航标事故关联分析,为内河航标维护决策、事故预防提供技术支撑。
附图说明
29.图1为本发明实施例方法的流程图;
30.图2为本发明实施例中xfp
‑
tree算法的xfp树结构图;
31.图3为本发明实施例中xfp
‑
tree算法位图矢量示意图;
32.图4为本发明实施例中xfp
‑
tree算法的头表结构改进图;
33.图5为本发明实施例中xfp
‑
tree算法的fp
‑
tree结构剪枝优化图;
34.图6为本发明实施例中的航标事故数据样例表。
具体实施方式
35.为使得本发明实施例的目的、技术流程和优越特性更加清楚,下面将结合本发明实施例附图,对本发明特征与技术方案进行进一步说明。需阐明的是,本文附图均采用简化易懂的形式展出,没有采用精确的比例,且为了便于清晰的描述流程与原理,仅展示了与本发明关联较大的因素。
36.在本发明说明中,需要了解的是,本文诸如“上”、“下”、“左”、“右”等方位术语仅表示附图中相关流程所示的位置关系,并不表明所指的设施平台或系统必须具有的特定位置或构造;诸如“一”、“所述”、“该”等词汇可包括复数形式;此外,术语“包括”、“包含”、“具有”是指存在所述特征、模块、步骤、操作,但并不排除存在或添加一个或数个个其他特征、模块、步骤、操作;应该理解“大于”、“小于”、“超越”等表示不包含本身,“以上”、“以内”等表示包含本身;“连接”、“连通”某一流程或模块时可表示直接连接或中间包含数个步骤或模块。
37.如图1所示,本发明的技术方案,包含以下步骤:
38.s1:通过python网页爬虫脚本,获取内河航道对应河段某一时间段的通航环境数据,并从航道管理部门获取航标属性信息与数据、航道特征信息;
39.s2:对获得的原始内河航标事故数据进行预处理,通过字段合并/创建/删除、缺失值处理、标签值处理三种方式整理数据;
40.s3.1:以xfp
‑
tree关联规则挖掘算法为基础,对内河航标事故数据集进行内在关联规则的挖掘;
41.s3.2:针对fp
‑
tree结构,添加标签内容,通过标签协助算法判断频繁项对应前缀是否为单一路径,降低xfp
‑
tree算法工作量;
42.s3.3:对fp
‑
tree算法的树结构进行剪枝,同时对算法频繁投影、频繁项集,添加关联规则挖掘的条件判断,抑制研究意义较小的关联规则生成,提升算法执行效率;
43.s4:通过总体因素与单个因素分析两个步骤,挖掘内河航标事故数据特征,揭示航标事故发生机理。本发明能够实现内河复杂通航环境下航标事故关联分析,为内河航标维护决策、事故预防提供技术支撑。
44.在本发明实施例中,原始数据集获取分为两部分。首先,在python3.7.4语言环境下,通过网页爬虫方式,获取对应河段某一时间段的通航环境数据,包括水位、天气、风速风向等信息;其次,通过航道管理部门获取航标属性信息、航道特征信息、事故报警信息等数
据;将上述数据整合构建原始航标事故数据集。
45.预处理方法包含字段合并/创建/删除、缺失值处理、标签值处理三种方式。
46.由于原始数据中“失常时间”字段格式包含了年、月、日、时刻等信息,如“2019/12/28 8:30”,为便于后续分析,对“失常时间”进行字段分割、分别创建月份、星期、时间段(白天、黄昏、夜晚等)三个字段,同时删除“失常时间”字段。
[0047]“事故地点”字段记录了航标事故发生的详细位置,但由于地段种类繁多,且文本形式不利于计算分析;因此,基于内河电子航道图与航道管理部门相关数据,对事故地点、经纬度等信息进行提取,得到其所属航道段,将“事故地点”字段改为“所属航道”字段,便于后续数据挖掘。
[0048]“航标电压”、“航标电流”、“航标形状”三项字段主要针对航标的运行状态与基础信息,电压与电流的异常可通过航标报警信息间接反映,难以表现事故规律与种类,在原始数据中删除上述三项字段。
[0049]“超时报警次数”、“电压报警次数”等报警信息字段,其信息时间与空间分布不均,直接进行关联分析难以体现其特性。因此,将对应字段改为“当天有无报警”与“当月报警次数”两项字段。
[0050]“流量”字段信息,由于航标事故数据集中于内河对应河段某一时间段,除支流汇入汇出,航道流量信息基本一致,对事故数据分析影响较小,将该字段删除。
[0051]
对于缺失“航标名称”、“事故地点”、“失常时间”、“失常原因”及“失常类型”的字段,采用直接删除的方法;对于“水位”、“风力”等信息,采用均值填补法进行填充;对于“事故地点”、“航标类型”等字段不完整信息,采用人工查询、填补的处理方法。
[0052]
原始数据中“水位”与对应“报警次数”的标签值具有多种类型的数值,如果不进行处理,难以挖掘内在的联系与共性。针对“水位”值,在同一基准面上,设立“0
‑
5m、5
‑
10m、10
‑
15m、15m以上”四个等级;针对“报警次数”,设立“0次、1
‑
10次、11
‑
50次、51
‑
100次、100次以上”五个等级,便于后续关联处理。经过上述处理后,内河航标事故数据集样本如图6所示。
[0053]
内河航标事故数据集具有事故数少、多维多层、属性值多等特点。采用apriori算法会多次遍历数据并生成大量候选项集,从而大幅降低挖掘效率;hotspot算法在连续性数值的关联规则挖掘中具有突出优势,但难以处理内河航标事故数据集;相类似的,在项集较大情况下eclat算法效率会大幅降低;relim算法虽然在时间与空间上优于上述算法,但不适用于航标事故长属性数据集;xfp
‑
tree算法汲取了fp
‑
growth的优点,两者类似的结构使得挖掘算法搜索开销较小,同时通过并行创立结构的特点,对于处理更大规模的内河航标事故数据集优势突出、可扩展性更高。
[0054]
xfp
‑
tree算法综合性能优于apriori、fp
‑
growth等算法,且不产生候选频繁项集,选择基于xfp
‑
tree算法改进并优化,可实现内河航标事故关联规则的挖掘。xfp
‑
tree算法基本流程如图2所示;其关联规则挖掘示例如图3所示。
[0055]
针对xfp
‑
tree结构,为提升算法执行速度,可以通过对前缀路径的链节点进行组合排列,并与对应前缀连接得到挖掘的频繁模式。为实现这一目的,在原算法的fp
‑
tree结构中,添加一个标签,通过标签标记协助程序判断该频繁项对应前缀是否为单一路径;若是单一路径则设置标签为true,反之为false;改进后的结构如图4所示。改进的fp
‑
tree结构中,对应头表的频繁项、支持度计数、对应指针内容保持不变;在此基础上添加了一项标签
属性,用于存储对应频繁项是否只存在单一的链接路径;通过标签,在算法循环遍历过程中,发现标记值为true,即可在后续其他频繁项链接时,在频繁投影中过滤该频繁项,达到速度的提升。
[0056]
进一步的,通过对本内河航标事故数据与xfp
‑
tree算法流程、结构的分析,可以提出fp
‑
tree数剪枝策略、频繁项集遍历生成关联规则的优化处理。
[0057]
针对算法fp
‑
tree树结构与频繁项集的改良方法。在遍历算法fp
‑
tree结构时,若树结构存在一个分枝,该分支节点m在该分枝上的支持度计数小于事先设定的最小支持度阈值时,便搜索该节点在树结构中其他分枝的位置。判断节点m初始分枝上子节点的集合是否包含其在新分枝上的子节点集合,若包含,那么剪掉节点m的初始分枝,并将新旧分枝中相似节点的支持度计数相加,以更新新分支上节点的支持度计数,达到简化结构的目的。
[0058]
同时,在算法生成频繁项集后,一般都通过交叉遍历的手段找到存在的关联规则;通过进一步分析内河航标事故数据集,对于生成的报警类信息、天气情况、水位信息等关联结果(如当天是否存在漂移报警、东南风、水位10
‑
15m等属性),实际研究意义较小;在关联规则挖掘中添加条件判断,抑制该类规则的生成。对于单项的先决条件,所获得的事故信息较少,可进行路径截断,进一步减少了算法的执行时间
[0059]
最终,通过全部因素及单个因素分析挖掘事故特征方法。单个因素主要针对人员因素、设施因素、管理因素、环境因素等方面;通过整体因素与单个因素总结关联规则挖掘结论,提出事故预防建议。
[0060]
以上描述仅为本技术的较佳的具体实施方式,本领域相关人员应当理解,本技术中所涉及的保护范围,并不限于上述技术特性特定组合而成的技术方案,同时也应涵盖简单的方法替换或变化上。因此,本发明的保护范围应该以权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1