一种基于专业生成内容的产品替代性信息抽取方法
1.本发明涉及发现专业生成内容中产品替代性关系相关的主题挖掘技术领域,具体涉及一种基于专业生成内容的产品替代性信息抽取方法。
背景技术:
2.竞争情报是营销和商业战略中的一个重要研究领域,并在文献中引起了相当大的关注。为了促进公司的的健康成长,公司试图设计有效的方法获取大量可用数据来挖掘竞争信息。显然,将关键数据转化为竞争情报是帮助企业增强竞争力、塑造竞争优势的核心任务。
3.近年来社交媒体平台(如twitter)的快速发展使营销人员和消费者能够产生和传播大量有价值的信息。这些信息包含一系列与公司品牌和产品高度相关的有价值的数据。挖掘这些数据为市场研究人员提供了独特的视角来了解市场竞争,并得出有意义的品牌营销和传播见解。关于如何使用用户生成内容(ugc)进行竞争分析的研究被越来越多的研究人员关注。例如,liu等通过挖掘论坛帖子,从客户的角度使用情感分析来衡量产品竞争优势。jaeger和利用社交媒体上的口碑数据,用共现现象来检测食品零售行业的非对称竞争。这些研究大多是从普通消费者的角度来理解竞争,而对于某些产品,大量普通的消费者的见解可能不如部分专业知识丰富的专家的看法更有影响。在传统的产品竞争替代关系研究领域中,研究人员通常基于调查数据、扫描面板数据和品牌选择数据,使用多维标度法、潜类别模型和聚类方法推断竞争关系。尽管这些研究提供了独特且有用的见解,但这些研究也受到一些与数据可用性相关的限制。例如,调查很费时、无法及时的跟踪消费者的行为等问题,而且有限的调查数量通常会导致竞争偏见,因为调查可能会引入不确定性,消费者可以迅速召回所有他们想要购买的产品。此外,现有的主题模型方法使用吉布斯采样算法学习模型参数,但是在大量的专业生成内容数据中,由于需要经过上千次迭代导致挖掘主题的速度很慢,效率低下。
技术实现要素:
4.本发明为了克服现有技术存在的不足之处,提出了一种基于专业生成内容的产品替代性信息抽取方法,以期能在应对大规模的专业生成内容时,能够有效、快速、准确地发现市场中竞争性产品间的替代关系,从专业的角度构建更准确的市场结构,以获得更精确的产品间竞争替代关系,从而帮助企业识别直接或间接竞争对手。
5.本发明为达到上述发明目的,采用如下技术方案:
6.本发明一种基于专业生成内容的产品替代性信息抽取方法的特点是按如下步骤进行:
7.步骤1、数据集合的获取;
8.步骤1.1、获取社交媒体中专业生成内容的数据集合,并将所述数据集合的索引标记d={1,2,
…
,d},d表示专业生成内容的总篇数;对于任意第d篇专业生成内容有(w
d
,t
d
),
其中,w
d
表示第d篇专业生成内容中的文本集合,t
d
表示第d篇专业生成内容中的产品名称集合;
9.步骤1.2、构建社交媒体中专业生成内容的文本内容集合:
10.对所述数据集合中所有的文本集合去除所有停用词后得到专业生成内容的文本内容集合,其中,第d篇专业生成内容的文本内容集合表示为w
di
表示第d篇专业生成内容的文本内容中第i个单词,n
d
表示第d篇文本内容中的单词数;
11.步骤1.3、构建专业生成内容的产品名称集合:
12.对于第d篇专业生成内容的产品名称集合记为其中,t
dj
表示第d篇专业生成内容中的第j个产品名称,l
d
表示第d篇专业生成内容中的产品名称数量;
13.步骤2、构建竞争子市场、产品竞争子市场以及相关主题子市场;
14.步骤2.1、将产品市场中的所有产品划分为k个竞争子市场,再按照所述数据集合中的产品名称和文本内容,得到第k个产品竞争子市场及其相关的第k个相关主题子市场,从而构成第k个竞争子市场;k∈{1,2,
…
,k};
15.步骤2.2、对k个竞争子市场中的产品编号有l={1,2,
…
,l},l表示专业生成内容的产品名称集合中不重复的产品总数;
16.令σ
k
表示产品竞争子市场的产品名称在第k个竞争子市场下的产品分布,且σ
k
服从参数为β的狄利克雷分布的概率分布,且β是一个l维向量;σ
kl
表示第l个产品被划分为第k个竞争子市场中的概率;
17.步骤2.3、对k个竞争子市场中相关主题的词编号有v={1,2,
…
,v},v表示专业生成内容的文本内容集合中不重复的词总数;
18.令表示相关主题子市场的相关主题在第k个竞争子市场下的词分布,且服从参数为γ的狄利克雷分布的概率分布,且γ是一个v维向量;表示第v个词被划分到第k个竞争子市场中的概率;
19.步骤3、构建专业生成内容中的偏好分布;
20.定义第d篇专业生成内容对k个竞争子市场的偏好分布表示为θ
d
={θ
d1
,θ
d2
,
…
,θ
dk
,
…
,θ
dk
},且θ
d
服从参数为α的狄利克雷分布的概率分布,且α是一个k维向量,其中,θ
dk
表示第d篇专业生成内容对第k个竞争子市场的偏好分布;
21.步骤4、设计有参贝叶斯模型,分析专业生成内容中的产品名称和文本内容信息,并生成产品名称对应的产品竞争子市场和文本对应的相关主题子市场;
22.步骤4.1、定义x
dj
∈{1,2,
…
,k}为第d篇专业生成内容中第j个产品名称t
dj
所代表的产品所归属的竞争子市场编号;且x
dj
服从参数为θ
d
的多项式分布,第j个产品名称t
dj
在编号为x
dj
的产品子市场下服从参数为的多项式分布;
23.步骤4.2、定义y
di
∈{1,2,
…
,k}为第d篇专业生成内容中第i个单词w
di
所代表的主题所归属的竞争子市场的编号;且y
di
服从参数为θ
d
的多项式分布,第i个单词w
di
所代表的主题在编号为y
di
的相关主题子市场下服从参数为的多项式分布;
24.步骤5、基于所述专业生成内容的数据集合,利用每篇专业生成内容中产品名称和文本内容间的关联关系,对第k个竞争子市场下的产品分布σ
kl
、相关主题在第k个竞争子市
场下的词分布以及第d篇专业生成内容对竞争子市场的偏好分布θ
dk
进行参数推断;
25.步骤5.1、利用坍塌式变分贝叶斯推断算法对产品名称和文本内容的生成过程进行后验推断,从而得到如式(8)所示的变分后验推断结果:
[0026][0027]
式(8)中,表示第j个产品名称t
dj
所代表的产品在编号为x
dj
的产品子市场下分配的近似后验概率,表示的多项式分布的变分参数,表示子市场编号为x和y的概率分布,表示子市场编号为x和y所对应的参数为θ,σ,的后验概率分布,表示参数为θ,σ,的条件下子市场编号为x和y的联合概率分布,表示第i个词w
di
在编号为y
di
的相关主题子市场下分配的近似后验概率,表示的多项式分布的变分参数;
[0028]
步骤5.2、由变分推断确定如式(9)所示的证据下界
[0029][0030]
式(9)中,表示联合概率密度的后验期望,表示信息熵;t
1:d
表示专业生成内容集合中的所有产品名称,w
1:d
表示专业生成内容集合中的所有的词;
[0031]
在变分推断过程中,根据文档偏好分布θ、产品子市场分布σ和主题词分布的边缘似然,得到如式(10)所示的坍塌式变分自由能结果:
[0032][0033]
步骤5.3、基于专业生成内容的数据集合中的产品名称集合和文本内容,设计采样方法,推断潜在变量σ
k
、和θ
d
的条件后验分布:
[0034]
步骤5.3.1、利用式(11)所示的贝叶斯法则和共轭先验,得到联合概率分布p(x,y|α,β,γ):
[0035][0036]
式(11)中,表示所有的产品分配到第k个产品子市场中的数量,且表示所有的产品分配到第k个产品子市场中的数量,且表示第l个产品分配到第k个产品竞争子市场的数量;表示所有的词分配到第k个主题子市场中的数量,且市场中的数量,且表示文本内容中第v个词分配到第k个产品竞争子市场的数量;表示所有的产品分配到第d篇专业生成内容中的数量,且表示所有的产品分配到第d篇专业生成内容中的数量,且表示第l个产品分配到第d篇专业生成内容中的数量;表示所有的词分配到第d篇专业生成内容中的数量,且量,且表示文本内容中第v个词分配到第d篇专业生成内容中的数量;δ(α)、δ(β)、δ(γ)是三个归一化因子,并有:
其中,γ表示伽马函数,α
k
表示α中的第k个向量,β
l
表示β中的第l个向量,γ
v
表示γ中的第v个向量;
[0037]
步骤5.3.2、利用中心极限定理,对式(10)和式(11)进行高斯近似,得到如式(12)和式(13)所示的更新公式,并分别用于更新变分参数和
[0038][0039][0040]
式(12)和式(13)中,式(12)和式(13)中,表示第d篇专业生成内容中第j个产品名称分配到第k个子市场中的概率,分配到第k个子市场中的概率,表示第d篇专业生成内容中第i个词分配到第k个子市场中的概率,和表示除去t
dj
和w
di
外的产品名称或主题词的期望数,表示第d篇文档的产品名称中属于第k个竞争子市场的数量;表示第d篇文档的词中属于第k个主题子市场的数量;表示第l个产品在第k个产品竞争子市场中出现次数的期望;表示第i个词在第k个主题子市场中出现次数的期望;表示第k个产品竞争子市场中所有产品名称出现的次数的期望,表示第k个主题子市场中所有词出现的次数的期望;
[0041]
步骤5.4、将更新后的变分参数赋值给和并返回步骤5.1顺序执行,直至产品分布σ
kl
、词分布和偏好分布θ
dk
收敛为止;
[0042]
步骤5.5、利用式(14)、式(15)、式(16)分别得到收敛后的偏好分布θ
′
dk
、词分布和产品分布σ
′
kl
;从而得到第d篇文档对总的竞争市场的偏好分布θ
′
d
={θ
′
d1
,θ
′
d2
,
…
,θ
′
dk
,
…
,θ
′
dk
},同理得到第k个产品竞争子市场下的产品分布σ
′
k
={σ
′
k1
,σ
′
k2
,
…
,σ
′
kl
,
…
,σ
′
kl
},相关主题在第k个竞争子市场下的词分布
[0043][0044][0045][0046]
式(14)、式(15)、式(16)中,分别为迭代更新后的
[0047]
步骤6、利用文档主题分布θ
′
d
、竞争子市场下的产品分布σ
′
k
和相关主题下的主题词分布从专业生成内容的数据集合中发现市场竞争结构并抽取产品替代性信息。
[0048]
与现有技术相比,本发明的有益效果在于:
[0049]
1.本发明联合建模社交媒体中pgc两方面的数据:产品名称和文本内容。建模过程中注重联合解释产品和文本间的关系,建模结果可以同时得到产品的竞争子市场和与该子市场对应的相关主题子市场,不同主题下的主题词能体现出对应子市场的特点,同时因为pgc的专业性,会使建模结果中的产品替代性信息更具有专业性,说服力更强,能够有效挖掘市场中产品间替代性关系与替代性信息,进而有助于分析专业视角下的产品的市场环境与竞争结构,为分析者提供更为专业的竞争情报。
[0050]
2.本发明在分析市场环境时将竞争市场分为了两个竞争子市场,即与产品相关的产品竞争子市场和与该子市场对应的相关主题子市场,通过本发明提出的关联主题模型link
‑
lda(link latent dirichlet allocation)模型,有效结合pgc的产品名称数据文本生成内容,成功得到两个竞争子市场,从而能够全面地刻画出在pgc中市场环境的特征,相较于已有的研究得到更加专业精准的产品间替代性关系。
[0051]
3.本发明设计了坍塌式变分贝叶斯推断方法,使得方法的可扩展性更高,在挖掘文档主题分布时更高效、更准确、更容易扩展到大数据。在应对大规模的专业生成内容时,能够更快速地挖掘专业生成内容中对市场中竞争性产品的关注度分布的市场中产品相关的焦点话题,帮助企业快速识别竞争对手。
附图说明
[0052]
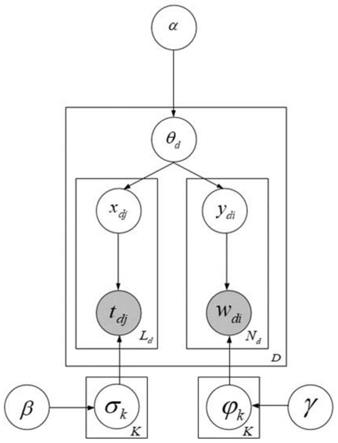
图1为本发明一种基于专业生成内容的产品替代性信息抽取方法的模型图。
具体实施方式
[0053]
本实施例中,一种基于专业生成内容(professional
‑
generated content,pgc)的产品替代性信息抽取方法,融合了专业生成内容中的产品名称和文本内容数据,考虑了内容生成者对产品市场的注意力分布、产品名称与描述性文本间的相关性,采用坍塌式变分贝叶斯推断进行近似估计,适用于发现潜在的产品竞争子市场即对应的相关主题,抽取出市场中产品间的替代性信息。具体的说是按如下步骤进行:
[0054]
步骤1、数据集合的获取;
[0055]
步骤1.1、获取社交媒体中专业生成内容的数据集合,并将所述数据集合的索引标记d={1,2,
…
,d},d表示专业生成内容的总篇数;对于任意第d篇专业生成内容有(w
d
,t
d
),其中,w
d
表示第d篇专业生成内容中的文本集合,t
d
表示第d篇专业生成内容中的产品名称集合;
[0056]
步骤1.2、构建社交媒体中专业生成内容的文本内容集合:
[0057]
对所述数据集合中所有的文本集合去除所有停用词后得到专业生成内容的文本内容集合,其中,第d篇专业生成内容的文本内容集合表示为w
di
表示第d篇专业生成内容的文本内容中第i个单词,n
d
表示第d篇文本内容中的单词数;
[0058]
步骤1.3、构建专业生成内容的产品名称集合:
[0059]
对于第d篇专业生成内容的产品名称集合记为,其中,t
dj
表示第d篇专业生成内容中的第j个产品名称,l
d
表示第d篇专业生成内容中的产品名称数量;
[0060]
步骤2、构建竞争子市场、产品竞争子市场以及相关主题子市场;
[0061]
步骤2.1、将产品市场中的所有产品划分为k个竞争子市场,每个竞争子市场中的产品之间存在着竞争关系,相同市场中的产品彼此具有替代关系;再按照所述数据集合中的产品名称和文本内容,得到第k个产品竞争子市场及其相关的第k个相关主题子市场,从而构成第k个竞争子市场;k∈{1,2,
…
,k};
[0062]
步骤2.2、对k个竞争子市场中的产品编号有l={1,2,
…
,l},l表示专业生成内容的产品名称集合中不重复的产品总数;
[0063]
令σ
k
表示产品竞争子市场的产品名称在第k个竞争子市场下的产品分布,且σ
k
服从参数为β的狄利克雷分布的概率分布,β是一个l维向量;σ
kl
表示第l个产品被划分为第k个竞争子市场中的概率;
[0064]
步骤2.3、针对市场中的k个竞争子市场,专业生成内容中的文本内容数据集合关注k个与竞争子市场对应的主题;在对产品进行市场划分时,不同的市场会有不同的相关主题,例如,新能源汽车市场会关注新能源、纯电动汽车等相关主题,这些主题中的主题词包含产品间的替代性信息;
[0065]
专业生成内容的文本内容中会包含大量的噪声信息,所以为了更有效地推断与竞争子市场相关的主题,会根据研究问题定义一个背景主题,基于此来过滤文本内容中的噪音单词;对k个竞争子市场中相关主题的词编号有v={1,2,
…
,v},v表示专业生成内容的文本内容集合中不重复的词总数;
[0066]
令表示相关主题子市场的相关主题在第k个竞争子市场下的词分布,且服从参数为γ的狄利克雷分布的概率分布,γ是一个v维向量;表示第v个词被划分到第k个竞争子市场中的概率;
[0067]
步骤3、构建专业生成内容中的偏好分布;
[0068]
专业生成内容的生成者通常只会对一个或几个子市场中的产品发表见解,而忽略其他市场中的产品的信息。定义第d篇专业生成内容对k个竞争子市场的偏好分布表示为θ
d
={θ
d1
,θ
d2
,
…
,θ
dk
,
…
,θ
dk
},且θ
d
服从参数为α的狄利克雷分布的概率分布,α是一个k维向量,其中,θ
dk
表示第d篇专业生成内容对第k个竞争子市场的偏好分布;
[0069]
步骤4、设计有参贝叶斯模型,分析专业生成内容中的产品名称和文本内容信息,并生成产品名称对应的产品竞争子市场和文本对应的相关主题子市场;
[0070]
步骤4.1、定义x
dj
∈{1,2,
…
,k}为第d篇专业生成内容中第j个产品名称t
dj
所代表的产品所归属的竞争子市场编号;且x
dj
服从参数为θ
d
的多项式分布,第j个产品名称t
dj
在编号为x
dj
的产品子市场下服从参数为的多项式分布;
[0071]
步骤4.2、定义y
di
∈{1,2,
…
,k}为第d篇专业生成内容中第i个单词w
di
所代表的主题所归属的竞争子市场的编号;且y
di
服从参数为θ
d
的多项式分布,第i个单词w
di
所代表的主题在编号为y
di
的相关主题子市场下服从参数为的多项式分布;
[0072]
步骤5、图1为本发明所提出的产品名称集合与文本内容集合的生成过程图,该图描绘了本发明提出的有参贝叶斯模型,对专业生成内容的产品名称集合与文本内容进行联合建模,从而推断产品竞争子市场和相关主题子市场对应的主题;
[0073]
基于所述专业生成内容的数据集合,利用每篇专业生成内容中产品名称和文本内容间的关联关系,对第k个竞争子市场下的产品分布σ
kl
、相关主题在第k个竞争子市场下的词分布以及第d篇专业生成内容对竞争子市场的偏好分布θ
dk
进行参数推断;
[0074]
步骤5.1、利用坍塌式变分贝叶斯推断算法对产品名称和文本内容的生成过程进行后验推断,从而得到如式(8)所示的变分后验推断结果:
[0075][0076]
式(8)中,表示第j个产品名称t
dj
所代表的产品在编号为x
dj
的产品子市场下分配的近似后验概率,表示的多项式分布的变分参数,表示子市场编号为x和y的概率分布,表示子市场编号为x和y所对应的参数为θ,σ,的后验概率分布,表示参数为θ,σ,的条件下子市场编号为x和y的联合概率分布,表示第i个词w
di
在编号为y
di
的相关主题子市场下分配的近似后验概率,表示的多项式分布的变分参数;
[0077]
步骤5.2、由变分推断确定如式(9)所示的证据下界
[0078][0079]
式(9)中,表示联合概率密度的后验期望,表示信息熵;t
1:d
表示专业生成内容集合中的所有产品名称,w
1:d
表示专业生成内容集合中的所有的词;
[0080]
在变分推断过程中,根据文档偏好分布θ、产品子市场分布σ和主题词分布的边缘似然,得到如式(10)所示的坍塌式变分自由能结果:
[0081][0082]
步骤5.3、基于专业生成内容的数据集合中的产品名称集合和文本内容,设计采样方法,推断潜在变量σ
k
、和θ
d
的条件后验分布:
[0083]
步骤5.3.1、利用式(11)所示的贝叶斯法则和共轭先验,得到联合概率分布p(x,y|α,β,γ):
[0084][0085]
式(11)中,表示所有的产品分配到第k个产品子市场中的数量,且表示所有的产品分配到第k个产品子市场中的数量,且表示第l个产品分配到第k个产品竞争子市场的数量;表示所有的词分配到第k个主题子市场中的数量,且市场中的数量,且表示文本内容中第v个词分配到第k个产品竞争子市场的数量;表示所有的产品分配到第d篇专业生成内容中的数量,且表示所有的产品分配到第d篇专业生成内容中的数量,且表示第l个产
品分配到第d篇专业生成内容中的数量;表示所有的词分配到第d篇专业生成内容中的数量,且量,且表示文本内容中第v个词分配到第d篇专业生成内容中的数量;δ(α)、δ(β)、δ(γ)是三个归一化因子,并有:其中,γ表示伽马函数,α
k
表示α中的第k个向量,β
l
表示β中的第l个向量,γ
v
表示γ中的第v个向量;
[0086]
步骤5.3.2、利用中心极限定理,对式(10)和式(11)进行高斯近似,得到如式(12)和式(13)所示的更新公式,并分别用于更新变分参数和
[0087][0088][0089]
式(12)和式(13)中,式(12)和式(13)中,表示第d篇专业生成内容中第j个产品名称分配到第k个子市场中的概率,分配到第k个子市场中的概率,表示第d篇专业生成内容中第i个词分配到第k个子市场中的概率,和表示除去t
dj
和w
di
外的产品名称或主题词的期望数,表示第d篇文档的产品名称中属于第k个竞争子市场的数量;表示第d篇文档的词中属于第k个主题子市场的数量;表示第l个产品在第k个产品竞争子市场中出现次数的期望;表示第i个词在第k个主题子市场中出现次数的期望;表示第k个产品竞争子市场中所有产品名称出现的次数的期望,表示第k个主题子市场中所有词出现的次数的期望;
[0090]
步骤5.4、将更新后的变分参数赋值给和并返回步骤5.1顺序执行,直至产品分布σ
kl
、词分布和偏好分布θ
dk
收敛为止;
[0091]
步骤5.5、利用式(14)、式(15)、式(16)分别得到收敛后的偏好分布θ
′
dk
、词分布和产品分布σ
′
kl
:
[0092][0093]
[0094][0095]
式(14)、式(15)、式(16)中,分别为迭代更新后的分别为迭代更新后的
[0096]
步骤5.6、从而得到第d篇文档对总的竞争市场的偏好分布θ
′
d
={θ
′
d1
,θ
′
d2
,
…
,θ
′
dk
,
…
,θ
′
dk
},同理得到第k个产品竞争子市场下的产品分布σ
′
k
={σ
′
k1
,σ
′
k2
,
…
,σ
′
kl
,
…
,σ
′
kl
},相关主题在第k个竞争子市场下的词分布
[0097]
步骤6、利用文档主题分布θ
′
d
、竞争子市场下的产品分布σ
′
k
和相关主题下的主题词分布从专业生成内容的数据集合中发现市场竞争结构并抽取产品替代性信息。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1