一种基于元学习的大规模多标签文本分类方法
1.本发明属于人工智能的多标签文本分类领域,涉及一种基于元学习的大规模多标签文本分类方法。
背景技术:
2.大规模多标签文本分类(large
‑
scale multi
‑
label text classification)是人工智能领域中一个重要且实用的技术。它被广泛应用于多个场景,例如对于大量的文章进行归集,根据病人的医疗记录自动诊断疾病,为法案赋予相关的法律概念标签等等。在这些任务中,由于标签集合庞大且人力标注资源有限,大规模多标签文本分类任务通常面临着标签长尾分布的挑战,即许多的标签只有很少量甚至没有标注的样本。
3.目前主流的多标签文本分类技术方案是先通过深度神经网络将每个文本编码为一个稠密的表示向量,再为每个标签分配一个二分类器进行预测。然而,这类方法需要由大量的文本和对应相关标签组成的标注数据进行训练,并且只能在事先确定的标签体系下才能保证准确识别。在真实的多标签文本分类任务场景中,标签往往呈现严重的长尾分布,即集合中许多的标签只有非常少量(少样本)甚至没有样本(零样本),并且随着标签体系的不断演化,会有新的标签加入进来,如何更好的应对这些标签也成为一个重要的挑战。
4.专利cn113076426a公开了一种多标签文本分类及模型训练方法、装置、设备及存储介质,该发明在训练多标签文本分类模型的过程中,会基于该模型输出的各标签的预测特征,来训练能够捕获标签间相关性的分类器,通过同步训练该分类器和多标签文本分类模型,使得训练出的多标签文本分类模型也能够更为精准的捕获标签间的相关性。但是由于没有利用到标签的先验信息,从而不能很好地预测那些少样本和零样本的标签。
5.rios a在论文中提出了一个基于文本匹配机制的多标签文本分类模型(rios a,kavuluru r.few
‑
shot and zero
‑
shot multi
‑
label learning for structured label spaces.proceedings of the conference on empirical methods in natural language processing.2020.),使用标签的描述信息与文本进行匹配来完成预测,并在标签的层次结构图上使用了图卷积神经网络挖掘了标签之间的相关性,从而能够应对那些少样本和零样本标签。lu j在论文中提出(lu j,du l,liu m,et al.multi
‑
label few/zero
‑
shot learning with knowledge aggregated from multiple label graphs.proceedings of the 2020conference on empirical methods innatural language processing.2020.),除了使用先验的标签层次图以外,还手动构建了标签间的描述相似度图以及共现矩阵图并使用了图神经网络挖掘了多个方面的标签关联信息。上述两篇论文中均使用了文本匹配模型来解决多标签文本分类问题,并结合了标签的描述信息和标签之间的关系图,能够应对少样本和零样本的标签。但是这些方法都只使用了普通的监督学习方法进行模型的训练,导致模型更倾向于预测正确那些样本数量巨大的常见标签,从而导致模型对于少样本和零样本标签的预测准确率较低。
技术实现要素:
6.发明目的:本发明所要解决的技术问题是针对现有技术中模型对于少样本和零样本标签的预测准确率较低的问题,提供一种基于元学习的大规模多标签文本分类方法。
7.为了解决上述技术问题,本发明公开了一种基于元学习的大规模多标签文本分类方法,包括:
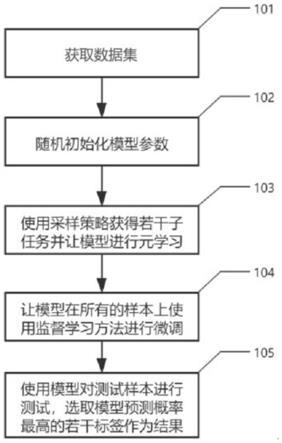
8.步骤s1:获取数据集,并将数据集按比例划分为训练集、验证集和测试集;所述数据集为样本的集合,所述样本由一段自然语言文本及其相关的标签组成;
9.步骤s2:随机初始化模型参数;
10.步骤s3:使用采样策略从训练集中采样获得若干样本,作为子任务的样本集合;基于采样获得的若干子任务由模型进行元学习;
11.步骤s4:元学习后的模型在原始数据集上使用监督学习方法进行微调;
12.步骤s5:对测试集中的测试样本进行测试,选取模型预测概率最高的若干标签作为预测结果。
13.优选地,所述步骤s1中,将数据集按照15:2:2的比例划分为训练集、验证集和测试集。
14.进一步地,所述步骤s2中,模型的参数一般为许多不同的张量,如果全部初始化为0则模型一般不会收敛,需要使用一些特定的随机策略进行初始化,所述随机策略包括均匀初始化和正态初始化。
15.进一步地,所述步骤s3中,采样策略包括基于样本的采样策略和基于标签的采样策略。
16.进一步地,所述步骤s3中,使用基于样本的采样策略,即从样本集合中无放回的均匀采样出若干样本作为子任务的样本集合。
17.进一步地,所述步骤s3中,使用基于标签的采样策略,即从样本集合中均匀采样出若干标签,从标注每个标签的样本集合中均随机选取一个样本,作为子任务的样本集合。
18.进一步地,所述均匀采样即采集到每一样本或者标签的概率相同。
19.进一步地,所述步骤s3中,将使用基于样本的采样策略采样获得的样本集合以及使用基于标签的采样策略采样获得的样本集合,分别按比例划分为支撑集和查询集。
20.优选地,基于样本的采样策略采样获得的样本集合按2:1的比例划分为支撑集和查询集;基于标签的采样策略采样获得的样本集合按2:1的比例划分为支撑集和查询集。
21.进一步地,所述步骤s3中,将基于样本采样获得的若干子任务以及基于标签采样获得的若干子任务按照一定比例混合,使模型基于若干子任务进行元学习。
22.进一步地,模型基于若干子任务进行元学习,包括:
23.步骤s31:使用二元交叉熵损失函数计算模型在支撑集上的损失函数值;
24.步骤s32:根据步骤s31计算的损失函数值,使用梯度下降算法更新模型参数若干步;
25.步骤s33:使用二元交叉熵损失函数计算经步骤s32更新后的模型在查询集上的损失函数值;
26.步骤s34:初始的模型根据步骤s32中查询集上的损失函数值选择使用特定的优化器进行学习。
27.优选地,考虑时间效率,更新模型参数的步数设置为1。
28.进一步地,所述步骤s4包括:
29.步骤s41:输入训练集、验证集以及元学习后得到的模型参数;
30.步骤s42:利用前向算法计算训练集中的样本,即根据自然语言文本预测出每个标签为正的概率;
31.步骤s43:使用二元交叉熵损失函数计算预测标签概率与真实标签的损失函数值;
32.步骤s44:计算损失函数值对于每个模型参数的梯度,使用反向传播算法更新模型参数;
33.步骤s45:使用特定的评估指标计算模型在验证集上的预测性能,对模型进行评估;
34.步骤s46:判断模型性能是否提升,如有提升则返回步骤s42继续迭代训练,否则执行步骤s47;
35.步骤s47:结束训练模型。
36.进一步地,所述步骤s45中,采用的评估指标为召回率。
37.优选地,选取排名前5的标签的召回率作为评估指标。
38.本发明提出了一种基于元学习的大规模多标签文本分类方法,将大规模多标签文本分类问题转化为一个元学习问题,通过构造大量含有少样本和零样本的多标签文本分类子任务并优化模型在这些任务上的泛化误差,让模型能够显式的学习如何更好的预测那些少样本和零样本标签。
39.有益效果:相对现有技术而言,本发明所具有的优点和效果有:
40.从技术层面来说,(1)首次提出将大规模多标签文本分类问题转化为元学习问题;(2)提出了一种新型的适合于大规模多标签文本分类场景的元学习算法,让模型显式的学习如何预测少样本和零样本标签。
41.从应用层面来说,(1)对于一段文本可以自动的预测出与其相关的多个标签,而不需要人工进行分类;(2)随着标签体系的不断演化,本发明对于新的标签只需要少量标注甚至不需要标注,就能够自动的对于这些标签进行精准预测,进一步减少了标注样本所需的人工成本。
附图说明
42.图1为本发明元学习大规模多标签文本分类算法流程图;
43.图2为本发明模型元学习算法流程图;
44.图3为本发明模型微调算法流程图。
具体实施方式
45.下面结合附图和具体实施方式对本发明做更进一步的具体说明。
46.如图1所示,一种基于元学习的大规模多标签文本分类方法,包括:
47.步骤s1:获取数据集,并将数据集按比例划分为训练集、验证集和测试集;所述数据集为样本的集合,所述样本由一段自然语言文本及其相关的标签组成;
48.本发明采用数据集eurlex57k进行实验,eurlex57k数据集是法律领域的大规模多
标签文本分类数据集,其包含57,000条法律文档以及4271个法律概念作为标签,平均每个文档会被标注约5个标签;其中,4271个标签被分为746个常见标签frequent(例如“国际事务”、“税收统一”)、3362个少样本标签few
‑
shot(例如“移民”、“营业执照”)和163个零样本标签zero
‑
shot(例如,“刑事责任”、“军事研究”),这取决于它们分别被分配到50个以上、50个以下但至少有一个,或者没有文档;将数据集按15:2:2的比例划分为训练集、验证集和测试集;
49.对于数据集中的文本和标签需要做相应的预处理,即将文本和标签描述中所有的词语提取出来,并使用一个embedding矩阵将所有的词语转化为一个向量;然后再分别将文档的词语向量和标签描述的词语向量输入文本encoder模块和标签encoder模块从而获得文本表示向量和标签表示向量,继而进行后续步骤;
50.步骤s2:随机初始化模型参数;模型的参数一般为许多不同的张量,如果全部初始化为0则模型一般不会收敛,需要使用一些特定的随机策略进行初始化,所述随机策略有均匀初始化和正态初始化;本发明使用了目前性能最优的agru
‑
kamg模型,该模型有约30,000,000个可训练参数;
51.步骤s3:如图2所示,使用采样策略从训练集中采样获得若干样本,形成若干子任务,基于采样获得的若干子任务由模型进行元学习;
52.所述采样策略包括基于样本的采样策略和基于标签的采样策略;其中,使用基于样本的采样策略,即从样本集合中无放回的均匀采样出若干样本作为子任务的样本集合;本发明均匀地采样出192个样本;
53.使用基于标签的采样策略,即从标注文本集合中均匀采样出若干标签,从标注每个标签的样本集合中均随机选取一个样本,作为子任务的样本集合;本发明均匀地采样出192个标签;
54.其中,均匀采样即采集到每一样本或者标签的概率相同;
55.将使用基于样本的采样策略采样获得的样本集合以及使用基于标签的采样策略采样获得的样本集合,均按2:1的比例划分为支撑集和查询集;
56.将基于样本采样获得的若干子任务以及基于标签采样获得的若干子任务按照1:1的比例混合,使模型基于若干子任务进行元学习;具体实现中采样了300个子任务进行元学习。
57.模型在基于采样获得的300个子任务上进行元学习,包括:
58.步骤s31:使用二元交叉熵损失函数计算模型在支撑集上的损失函数值;元学习收敛后模型在支持集上损失函数值大约为2.0;
59.步骤s32:根据步骤s31计算的损失函数值,使用梯度下降算法更新模型参数若干步;此过程中考虑时间效率,更新模型参数的步数为1;
60.步骤s33:使用二元交叉熵损失函数计算经步骤s32更新后的模型在查询集上的损失函数值;元学习收敛后模型在查询集上损失函数值大约为0.8;
61.步骤s34:初始的模型根据步骤s32中查询集上的损失函数值选择使用特定的优化器进行学习;本发明使用了adam优化器进行元学习。
62.步骤s4:如图3所示,元学习后的模型在原始数据集上使用监督学习方法进行微调,包括;
63.步骤s41:输入训练集、验证集以及元学习后得到的模型参数;
64.步骤s42:利用前向算法计算训练集中的样本,即根据自然语言文本预测出每个标签为正的概率;
65.步骤s43:使用二元交叉熵损失函数计算预测标签概率与真实标签的损失函数值;模型收敛后在验证集上的损失函数值大约为15;
66.步骤s44:计算损失函数值对于每个模型参数的梯度,使用反向传播算法更新模型参数;
67.步骤s45:使用特定的评估指标计算模型在验证集上的预测性能,对模型进行评估;本发明采用了前5召回率对模型进行评估;其中,前5召回率表示排名前5的标签的召回率;
68.步骤s46:判断模型性能是否提升,如有提升则返回步骤s42继续迭代训练,否则执行步骤s47;
69.步骤s47:结束训练模型。
70.步骤s5:对测试集中的测试样本进行测试,选取模型预测概率最高的若干标签作为预测结果;文本和每个标签向量之间的相似度用来对标签进行预测,即将多标签分类任务转化为了文本匹配任务,这样可以有效的应对少样本和零样本标签。
71.经过实验,本发明在测试集上的实验结果如下表所示:
[0072] overallfrequentfew
‑
shotzero
‑
shotagru
‑
kamg66.072.459.154.5agru
‑
kamg+ours67.774.264.359.0
[0073]
其中,agru
‑
kamg+ours是指在agru
‑
kamg模型的基础上使用基于特殊采样策略的元学习方法;表格中的四列数据分别为模型在全部标签(overall)、常见标签(frequent)、少样本标签(few
‑
shot)和零样本标签(zero
‑
shot)上的前5召回率(%),从实验结果中可以看出,在agru
‑
kamg模型的基础上使用基于特殊采样策略的元学习方法能对agru
‑
kamg模型带来显著的性能提升,特别是在少样本(few
‑
shot)和零样本(zero
‑
shot)标签上。
[0074]
本发明提供了一种基于元学习的大规模多标签文本分类方法的思路及方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1