基于流形学习的数据嵌入方法
1.本发明涉及深度流形学习,尤其涉及基于流形学习的数据嵌入方法。
背景技术:
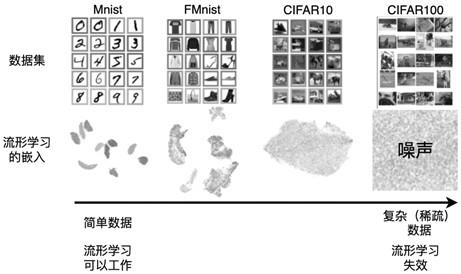
2.数据嵌入任务常常借助于流形学习方法,流形学习是一类无监督的估计器,旨在将为嵌入高维空间的低维流形映射到合理的低维空间完成多种下游任务 (如聚类、可视化、社群发现等)。深度流形学习期望使用深度神经网络提高流形学学习的嵌入和泛化能力。不过目前大多数流形学习方法不能处理不充分流形观测数据(复杂、文本等数据这是因为大多数复杂的流形数据具有超高的维度(超过10000维),而且只有非常不充分的观测;例如,imagenet的维度是 224*224*3,但样本总数只有1280k,平均每个维度只有1280k/(224*224*3)=8.5 pic/dim个图片。而在实际情况高维空间的指数广阔性性会使得不充分更为严重,导致在高维空间中获得足够的采样样本成为一个伪命题。经典(深度)流形学习假设流形局部具有连通性,因此当流形复杂、采样不充分时经典流形学习往往不能有效工作。以图1中的高维图像数据为例:随着流形数据逐渐复杂化(维度变高、流形结构变复杂、相对采样变不充分),对流形制定次数的观测逐渐变得不充分,导致所有的深度流形学习方法逐渐失效。
3.综上,目前大多数(深度)流形学习方法不能处理复杂的流形数据(图像、文本等),这是因为大多数复杂的流形数据具有超高的维度(超过10000维),而且只有非常不充分的观测;当前方法可以应用于多种数据(流形数据、图像数据、图结构数据等),需要针对不同种类的数据特异性设计算法步骤完成嵌入。
技术实现要素:
4.本发明的目的在于克服现有技术中的不足,提供一种通过生成样本保证流动性,进而完成深度流形学习的基于流形学习的数据嵌入方法。
5.本发明是通过以下技术方案实现的:一种基于流形学习的数据嵌入方法,包括以下步骤,
6.s1,设计语义网络,所述语义网络用于将数据从输入空间映射到语义空间;
7.s2,设计嵌入网络,所述嵌入网络用于将数据从语义空间映射到嵌入空间;
8.s3,数据增广,对数据[x1,x2,
…
,x
n
]进行u次数据增广获得增广后的数据 v={[v
1,1
,v
1,2
,
…
,v
1,n
],
…
,[v
u,1
,v
u,2
,
…
,v
u,n
]};[v
1,1
,v
1,2
,
…
,v
1,n
]为1次数据增广后的结果;
[0009]
s4,从v中取任意b组数据,b为网络训练的batch数量一般设定为256,每一组数据为两个个增广后的数据v
b,i
,v
b,j
,将数据通过语义网络映射到语义空间,得到数据z
b,i
,z
b,j
,b为组的索引;
[0010]
s5,将数据z
i
,z
j
通过嵌入网络映射到嵌入空间中,得到数据e
b,i
,e
b,j
;
[0011]
s6,计算在语义空间中两个点z
b,i
,z
b,j
的距离
[0012]
s7,进行距离的语义缩放,判断两个点z
b,i
,z
b,j
对应的两个点v
b,i
,v
b,j
是否是来自
同一个原始数据,如果来自于同一个原始数据,则计算语义距离,拉近z
b,i
,z
b,j
的语义距离其中m为拉近系数,否则正常通过旅行距离计算语义距离;
[0013]
s8,使用核函数一将语义距离转化为语义相似度
[0014]
s9,计算在嵌入空间中两个点e
b,i
,e
b,j
的距离
[0015]
s10,使用核函数将二距离转化为语义相似度
[0016]
s11,使用损失函数l
b
度量第b组数据的两个相似度的差异,然后将b组数据的损失函数求和得到总的损失函数:
[0017]
s12,使用反向传播方法,求l关于语义网络、嵌入网络的参数的偏导数,然后根据偏导数调整语义网络、嵌入网络的参数,至语义网络、嵌入网络收敛,得到嵌入空间的嵌入。
[0018]
进一步地,步骤s1中,所述语义网络选用mlp、cnn、rnn其中的一种。
[0019]
进一步地,步骤s2中,所述嵌入网络选用mlp、cnn、rnn其中的一种。
[0020]
进一步地,步骤s3中,所述数据增广基于列表数据的mixup增广方式、rc(
·
)、 cj(
·
)、gb(
·
)其中的一种或者多种,其中rc(
·
)为随机切割、cj(
·
)为颜色扰动、 gb(
·
)为高斯模糊。
[0021]
进一步地,步骤s6中,距离的计算选用d
e
(a,b)、d
c
(a,b)、d
m
(a,b)其中的一种,其中d
e
(a,b)为欧式距离、d
c
(a,b)为余弦距离、d
m
(a,b)为曼哈顿距离。
[0022]
进一步地,步骤s7中,语义缩放的方法为其中m为超参数, 取值m=10。
[0023]
进一步地,步骤s8中,所述核函数一选用s
g
(
·
)、s
t
(
·
)、s
γ
(
·
)其中的一种,其中s
g
(
·
)为高斯核函数、s
t
(
·
)为t分布核函数、s
γ
(
·
)为gamma函数。
[0024]
进一步地,步骤s9中,距离的计算选用d
e
(a,b)、d
c
(a,b)、d
m
(a,b)其中的一种。
[0025]
进一步地,步骤s10中,所述核函数二选用s
g
(
·
)、s
t
(
·
)、s
γ
(
·
)其中的一种。
[0026]
本发明的有益效果在于:基于流形学习的数据嵌入方法,设计语义网络和嵌入网络,在潜在空间中定义样本间的语义相似度,避免直接在输入空间中定义相似度引起的错误负样本问题,使用数据增强手段,生成样本的近邻样本,进而保证流形的连通性,为深度流形学习提供基础,设计语义缩放模块,迫使来自相同源数据的两个增强数据有更小的语义距离和更高的语义相似度,进而学习数据增强带来的先验知识。
附图说明
[0027]
图1为传统流形学习的效果图;
[0028]
图2为传统流形学习的计算框架;
[0029]
图3为实施例1的计算框架;
[0030]
图4为基于基线方法的可视化效果图;
[0031]
图5为实施例1的可视化效果图。
具体实施方式
[0032]
下面将结合发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0033]
实施例1
[0034]
如图3所示,一种基于流形学习的数据嵌入方法,其特征在于,包括以下步骤,
[0035]
s1,设计语义网络,语义网络用于将数据从输入空间映射到语义空间,本实施例中,语义网络为cnn1(
·
);
[0036]
s2,设计嵌入网络,嵌入网络用于将数据从语义空间映射到嵌入空间,本实施例中,嵌入网络为cnn2(
·
);
[0037]
s3,数据增广,对数据[x1,x2,
…
,x
n
]进行u次数据增广获得增广后的数据 v={[v
1,1
,v
1,2
,
…
,v
1,n
],
…
,[v
u,1
,v
u,2
,
…
,v
u,n
]};[v
1,1
,v
1,2
,
…
,v
1,n
]为1次数据增广后的结果,本实施例中,数据增广通过公式一实现,公式一, v1=cj(gb(rc(x1)));
[0038]
s4,从v中取任意b组数据,b为网络训练的batch数量,设定为256,每一组数据为两个增广后的数据v
b,i
,v
b,j
,将数据通过语义网络映射到语义空间,得到数据z
b,i
,z
b,j
,b为组的索引,语义网络选用cnn网络;
[0039]
s5,将数据z
i
,z
j
通过嵌入网络映射到嵌入空间中,得到数据e
b,i
,e
b,j
,e
i
=cnn1(z
i
),e
j
=cnn1(z
j
);
[0040]
s6,计算在语义空间中两个点z
b,i
,z
b,j
的距离
[0041]
s7,进行距离的语义缩放,判断两个点z
b,i
,z
b,j
对应的两个点v
b,i
,v
b,j
是否是来自同一个原始数据,如果来自于同一个原始数据,则计算语义距离,拉近z
b,i
,z
b,j
的语义距离其中m为拉近系数,取值m=10,否则正常通过旅行距离计算语义距离;
[0042]
s8,使用核函数一将语义距离转化为语义相似度核函数一为
[0043]
s9,计算在嵌入空间中两个点e
b,i
,e
b,j
的距离
[0044]
s10,使用核函数二将距离转化为语义相似度核函数二为
[0045]
s11,使用损失函数l
b
度量第b组数据的两个相似度的差异,
然后将b组数据的损失函数求和得到总的损失函数:
[0046]
s12,使用反向传播方法,求l关于语义网络、嵌入网络的参数的偏导数,然后根据偏导数以传统神经网络训练方式调整语义网络、嵌入网络的参数,至语义网络、嵌入网络收敛,得到嵌入空间的嵌入,传统神经网络训练方式可以选用梯度下降法。
[0047]
传统流形学习方法,假设流形进行了非常充分的采样,当我们不能拿到充分的采样数据时,就没有办法完成学习,本方法使用数据增强手段,人工生成样本的近邻样本,通过人工生成的样本保证流行的连通性,完成深度流行学习。
[0048]
本方法,设计了两个子网络,并且在潜空间中定义样本间的语义相似度,这样定义由于直接在输入空间定义相似度。因为在输入空间中定义会遇到对比学习常见的错误负样本问题。本专利可以避免错误负样本问题。
[0049]
算法可以应用到表格数据,生物数据图像数据等数据,不需要改变算法结构。
[0050]
本实施例提供的基于流形学习的数据嵌入方法,在表格数据和生物学数据上的嵌入任务上,我们提出的方法在分类acc和流形完整性指标上有优秀的表现,如附表1和附图5。
[0051]
附表1
[0052][0053]
由附表1及附图4、5可以知道,本专利方法在acc指标在5个测试数据集优于大部分先进方法,在可视化上可以有效的发现数据的全局和局部结构。
[0054]
本实施例提供的基于流形学习的数据嵌入方法,在图像嵌入任务上,线性测试分类acc指标见附表2,聚类指标见附表3。
[0055]
附表2
[0056][0057]
附表3
[0058][0059]
由附表2和附表3可以知道,本发明在线性测试分类acc和聚类上,均有优异的表现。
[0060]
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1