基于聚合风险数据的巨灾保险损失模拟方法与流程
1.本发明涉及再保险领域,尤其涉及一种基于聚合风险数据的巨灾保险损失模拟方法。
背景技术:
2.近年来,全球多个国家和地区频繁受到严重灾害影响,导致大量人员伤亡并造成了严重的经济损失,成为区域经济社会可持续发展的重要障碍之一。从全球范围来看,巨灾保险是分散上述巨灾事故风险的重要手段之一。2016年,随着我国《建立城乡居民住宅地震巨灾保险制度实施方案》、《中国保险业发展“十三五”规划纲要》、《地震巨灾保险条例》等一系列政策陆续出台,巨灾保险再次受到关注并步入发展阶段。
3.在实际巨灾保险业务中,由于详细保单数据的质量和精度往往难以满足计算要求;特别是在再保险公司的业务中,考虑到风险不对称性,再保险公司通常拿到的业务数据是保险公司经过详细保单累加处理后的聚合风险累积数据。因此,再保险业务往往获得的是区域范围的总保额信息,如按照每个省或者市(较少能到区县级)给出一个总保额,即初始保险数据多为区域范围的聚合风险数据。由于聚合风险数据的保单中无具体标的信息,因此很难直接进行地震保险损失计算。
技术实现要素:
4.为了解决以上问题,本发明公开了一种基于聚合风险数据的巨灾保险损失模拟系统的构建方法,将聚合风险数据进行拆分,获得其空间位置和价值,并通过赋予拆分后标的聚合属性,计算其标的对应的聚合易损性曲线和住宅、商业和工业价值,然后结合已有的地震灾害强度,获得各拆分点标的的总损失,然后累加所有标的总损失得到最终的聚合风险数据总损失。包括以下步骤:
5.获取某一区域的总保额tiv和风险暴露数目n;
6.在行业风险暴露数据库中的所述区域内随机抽取n个网格点,每个所述网格点包括位置信息和位置权重;
7.将被抽出的n个网格点作为标的,按式i计算每个所述标的的新权重:
[0008][0009]
其中,w
k
_
new
为第k个标的的新权重,w
k
为第k个被抽出的网格点的位置权重,w
i
为第i个被抽出的网格点的位置权重;
[0010]
按式ii将所述总保额按照每个所述标的的新权重拆分成n个标的保额:
[0011]
tiv
k
=tiv
×
w
k_new
ꢀꢀꢀꢀꢀ
ii
[0012]
其中,tiv
k
为第k个标的保额,w
k_new
为第k个标的的新权重,tiv为所述总保额;
[0013]
根据所述位置信息赋予每个所述标的聚合属性,并得到每种所述聚合属性的综合占比系数,所述聚合属性包括若干易损属性;
[0014]
将每种所述聚合属性匹配相应财产的易损性数据,并将所述易损性数据按照所述
综合占比系数聚合,得到每个所述标的的聚合易损性数据;
[0015]
根据所述区域的地震强度分布,结合每个所述标的的所述位置信息、所述聚合易损性数据、所述标的保额,得到每个标的损失,将所有标的损失求和得到所述区域的总损失。
[0016]
此基础上,本发明还公开一种计算机程序产品,包括计算机程序/指令,该计算机程序/指令被处理器执行时实现本发明所有步骤。
[0017]
此基础上,本发明还公开一种基于聚合风险数据的巨灾保险损失模拟系统,其特征在于,被处理器执行时实现本发明所有步骤。
[0018]
本发明可以快速基于给出的聚合风险数据生成某区域内分布的空间位置和价值信息的标的数据,并通过赋予拆分后标的聚合属性,计算其标的对应的聚合易损性曲线和住宅、商业和工业价值,然后结合已有的地震灾害强度,获得各拆分点标的的总损失,然后累加所有标的总损失得到最终的聚合风险数据总损失。
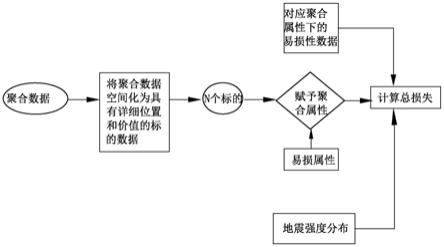
附图说明
[0019]
图1、一些较实施方式涉及的技术方案的流程示意图;
[0020]
图2、一些较实施方式涉及的地震强度计算的示意图。
具体实施方式
[0021]
一些实施方式涉及的基于聚合风险数据的巨灾保险损失模拟方法,包括以下步骤:
[0022]
获取某一区域的总保额tiv和风险暴露数目n;
[0023]
在行业风险暴露数据库中的所述区域内随机抽取n个网格点,每个所述网格点包括位置信息和位置权重;
[0024]
将被抽出的n个网格点作为标的,按式i计算每个所述标的的新权重:
[0025][0026]
其中,w
k_new
为第k个标的的新权重,w
k
为第k个被抽出的网格点的位置权重,w
i
为第i个被抽出的网格点的位置权重;
[0027]
按式ii将所述总保额按照每个所述标的的新权重拆分成n个标的保额:
[0028]
tiv
k
=tiv
×
w
k_new
ꢀꢀꢀꢀꢀꢀ
ii
[0029]
其中,tiv
k
为第k个标的保额,w
k_new
为第k个标的的新权重,tiv为所述总保额;
[0030]
根据所述位置信息赋予每个所述标的聚合属性,并得到每种所述聚合属性的综合占比系数,所述聚合属性包括若干易损属性;
[0031]
将每种所述聚合属性匹配相应财产的易损性数据,并将所述易损性数据按照所述综合占比系数聚合,得到每个所述标的的聚合易损性数据;
[0032]
根据所述区域的地震强度分布,结合每个所述标的的所述位置信息、所述聚合易损性数据、所述标的保额,得到每个标的损失,将所有标的损失求和得到所述区域的总损失。
[0033]
其中,术语“行业风险暴露数据库”包括基于多源基础数据和空间分布数据的融合
构建的数据库;其中的数据以表的形式(包括但不限于txt,xlsx,xls,jason等格式)存储,每个网格点通常采用1km
×
1km的空间精度的数据,每个网格点的数据包括但不限于每个网格的id或位置标识、经度、纬度、位置权重等信息。位置权重包括(但不限于)从区域内的人口空间分布数据、灯光指数、gdp分布数据、房屋建筑价值分布数据、风险暴露数据库中获取的数据。
[0034]
另一些实施方式,还包括以下步骤:
[0035]
将所述聚合属性的所有所述易损属性的比例系数相乘得到所述聚合属性的综合占比系数。
[0036]
另一些实施方式,还包括以下步骤还包括以下步骤:每个标的所述聚合易损性数据根据式iii得到:
[0037][0038]
其中,mixmdr表示所述聚合易损性数据,mdr
i
表示第i种聚合属性财产的易损性数据,r
i
表示第i种聚合属性的综合占比系数,m表示所述聚合属性个数。
[0039]
一些实施方式,还包括通过拉丁超立方抽样方法在所述区域内分层抽取所述n个网格的步骤,具体包括以下步骤:
[0040]
将所述行业风险暴露数据库中所有网格按照其位置权重排序;
[0041]
将所述行业风险暴露数据库中所有网格的位置权重相加得到w;
[0042]
设置每次抽样的步长为w/n,在排序后的行业风险暴露数据库中按照所述步长抽取所述n次得到所述n个网格。
[0043]
一些实施方式,还包括通过蒙特卡洛随机抽样方法在所述行业风险暴露数据库中的所述区域内抽取所述n个网格。
[0044]
一些实施方式,还包括以下步骤:
[0045]
根据所述位置信息赋予每个所述标的若干价值属性,每种所述价值属性标的具有聚合属性;
[0046]
按照每种所述价值属性的价值占比得到每种价值属性的价值;
[0047]
根据所述区域的地震强度分布,结合每个所述标的的位置信息、聚合易损性数据、每种价值属性的价值,得到每个所述标的损失,将所有所诉标的损失求和得到所述区域的总损失。
[0048]
一些实施方式中的风险暴露数目n通过以下方法得到:将行业风险暴露数据库中在目标区域内的公里网格数的二分之一作为风险暴露数目n输入。
[0049]
一些实施方式中,目标区域内的地震强度分布通过衰减关系计算地震峰值加速度pga影响场模拟得到。
[0050]
一些更具体的实施方式,流程如图1所示,通过某一区域的巨灾保险聚合风险数据总保额(total insured value,tiv)和风险暴露数量n,首先对区域范围的聚合保险数据进行拆分:
[0051]
将聚合数据空间化为具有详细位置和价值的标的数据。将其拆分的方法可采用蒙特卡洛方法随机抽样,或基于行业风险暴露数据的价值和空间分布为依据的抽样拉丁超立方抽样方法,具体拆分步骤如下:
[0052]
1)确定空间位置权重
[0053]
空间权重可以通过人口空间分布、灯光指数、gdp分布、房屋建筑价值分布等数据;或者多源数据的融合和空间叠加分析等方法进行处理获得。例如基于多源基础数据和空间分布数据的融合,构建行业标的风险暴露数据库(全国城乡住宅建筑造价分布、全国工、商业建筑造价分布),获得全国范围公里格网上的建筑总价值作为空间权重,为聚合数据的空间拆分提供空间权重依据。
[0054]
2)确定拆分后的标的个数n
[0055]
风险暴露数量n通常会作为已知的保单数据输入。当不能确认n时,将风险暴露行业标的数据库中在该地区划分的公里格网数的二分之一作为n的输入值。
[0056]
3)确认n个标的位置
[0057]
利用一定的拆分方法将聚合保单数据拆分到具体位置分布和价值分布,可视为基于行业风险暴露数据的随机抽样。如拉丁超立方抽样方法,根据行业风险暴露数据库中每个单位格网的价值权重w
k
和所需要抽样出来的风险暴露数量n,按照分层随机抽样抽出n个点,并确认其位置分布。
[0058]
4)确认n个标的价值
[0059]
利用抽样方法抽出的n个点的新权重可表示为:
[0060][0061]
根据上述新的权重,结合用户给出的总保额tiv,计算拆分后各点的保额tiv
k
:
[0062]
tiv
k
==tiv
×
w
k_new
[0063]
5)赋予拆分标的聚合属性
[0064]
房屋建筑在地震动作用下发生的平均损失率称为易损性,通常用横轴为地震动强度(比如峰值加速度、反应谱值等)、纵轴为平均损失率(mean damage rario,mdr)的易损性曲线来表示。不同功能用途、结构类型、建造年代、楼层数量和设防烈度的房屋建筑,在地震作用下发生破坏不同,其修复价值(或者重置价值)差异很大。因此需要除了将聚合风险数据数据拆分到具体位置和价值外,还需要赋予其足够的属性信息,以支持进行后续的损失计算。
[0065]
对拆分后的标的数据,赋予聚合属性信息(功能用途、结构类型、楼层数量、建造年代、设防烈度五个维度的综合属性),以便进行一步匹配数据库中相对应的易损性曲线(聚合属性中不同属性维度的组合其易损性曲线是不同的)。根据抽取出的n个单位格点中的位置,赋予每个单点k所代表区域范围(通常采用1km2的空间精度)的聚合属性信息(功能用途、结构类型、楼层数量、建造年代、设防烈度):包括住宅、商业和工业建筑权重占比(如表1所示),以及住宅、商业、工业所对应的结构类型、楼层数量、建造年代、设防烈度等属性信息(如表2所示)。
[0066]
表1不同位置的住宅商业工业价值占比信息
[0067][0068]
表2不同功能用途建筑的行业平均拆分参数
[0069][0070]
拆分标的的聚合易损性计算和地震保险损失计算。
[0071]
灾害模块计算地震动强度分布:基于地震随机事件集,计算地震动强度的空间分布范围(如通过衰减关系计算地震峰值加速度pga影响场),并考虑场地条件、地形效应等影
响,获得承保标的所在位置的地震动强度;
[0072]
易损性模块和风险暴露模块综合获取拆分点聚合易损性曲线:
[0073]
确认拆分后标的的聚合属性:拆分点的位置,住宅、工业、商业建筑承保价值占比信息,以及以及住宅、商业、工业所对应的结构类型、楼层数量、建造年代、设防烈度等属性信息。
[0074]
根据拆分标的位置和聚合属性,计算不同功能用途下各类属性组合(建筑结构类型*建筑高度类型*建造年代类型*设防烈度类型)的综合占比系数r
i
。
[0075]
结合表1和表2,对于某个拆分点k的聚合属性中,其商业用途的属性组合(建筑结构类型*建筑高度类型*建造年代类型*设防烈度类型)共有2
×3×2×
1=12类,则聚合属性中商业用途下第i个组合(i=1,2,3,...,12)的综合占比系数r
i
为:
[0076][0077]
通过每个承保标的聚合属性确认对应的易损性曲线。以商业建筑为例,如表3所示。
[0078]
表3商业用途下各组合及其匹配的易损性曲线
[0079]
[0080][0081][0082]
其中,表3中的易损性曲线图以数据表的形式存储,在本实施方式中以曲线图的形式表示,为了方便理解。
[0083]
将各组合的易损性曲线,通过综合占比系数进行聚合,获得聚合易损性曲线,以表3为例,则第k个拆分点的聚合易损性曲线mixmdrk:
[0084][0085]
6)计算损失值
[0086]
根据灾害强度计算的影响场,并根据聚合属性得到的聚合易损性曲线,如图2所示得到拆分点位置所对应的地震动强度。由此可以计算拆分点k在特定地震动强度x下的房屋建筑损失率(mdr
k
|im=x)
[0087]
估算单个承保标的在某种地震动强度(如pga)下的破坏程度和地震损失loss
i
。以商业建筑为例,第k个拆分点在聚合属性下的价值为:
[0088][0089][0090]
承保标的单点损失等于住宅、商业、工业建筑的总损失之和:
[0091][0092]
该区域的聚合风险总损失即为拆分后n个承保标的单点损失之和。
[0093][0094]
本说明书中描述的主题的实施方式可以被实施为一个或多个计算机程序,即,一个或多个有形非暂时性程序载体上编码的计算机程序指令的一个或多个模块,用以被数据处理设备执行或者控制数据处理设备的操作。计算机程序(还可以被称为或者描述为程序、软件、软件应用、模块、软件模块、脚本或者代码)可以以任意形式的编程语言而被写出,包括编译语言或者解释语言或者声明性语言或过程式语言,并且计算机程序可以以任意形式展开,包括作为独立程序或者作为模块、组件、子程序或者适于在计算环境中使用的其他单元。计算机程序可以但不必须对应于文件系统中的文件。程序可以被存储在保存其他程序或者数据的文件的一部分中,例如,存储在如下中的一个或多个脚本:在标记语言文档中;在专用于相关程序的单个文件中;或者在多个协同文件中,例如,存储一个或多个模块、子程序或者代码部分的文件。计算机程序可以被展开为执行在一个计算机或者多个计算机上,计算机位于一处,或者分布至多个场所并且通过通信网络而互相连接。本说明书中描述的主题的实施方式可以在巨灾保险计算系统中实施。
[0095]
虽然本说明书包含很多具体的实施细节,但是这些不应当被解释为对任何发明的范围或者对可以要求保护的内容的范围的限制,而是作为可以使特定发明的特定实施方式具体化的特征的说明。在独立的实施方式的语境中的本说明书中描述的特定特征还可以与单个实施方式组合地实施。相反地,在单个实施方式的语境中描述的各种特征还可以独立地在多个实施方式中实施,或者在任何合适的子组合中实施。此外,虽然以上可以将特征描述为组合作用并且甚至最初这样要求,但是来自要求的组合的一个或多个特征在一些情况
下可以从该组合去掉,并且要求的组合可以转向子组合或者子组合的变形。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1