一种快速全量解析STDF文件的方法和设备与流程
一种快速全量解析stdf文件的方法和设备
技术领域
1.本发明属于半导体测试技术领域,具体涉及一种解析stdf文件的方法和设备。
背景技术:
2.stdf(standard test data format)即标准测试数据文件,是半导体行业芯片测试数据的存储规范,广泛应用于cp(chip probe)、ft(final test)测试中。其以二进制字节流的形式,采用统一格式保存芯片测试过程中产生的各种类型的数据,解决了不同测试机所生成的测试数据格式不统一的问题。因此,在半导体行业,测试机供应商、芯片测试公司、芯片设计公司都非常重视且愿意接受该规范。
3.通过全量解析stdf中的数据,可以对芯片测试结果进行全方位的分析,包括lot、wafer、die、测试项等。基于这些数据,一方面,可以从不同维度,以不同的统计图表的形式,快速查找出异常lot,找到改善点;另一方面,可以实现全方位制程管控的系统,辅助测试机截停异常的lot和产品,探测制程异常的原因。因此,stdf中的数据非常重要且有价值,而快速全量解析出stdf中的数据对后续的分析和管控起着至关重要的作用。
4.现有的stdf解析技术大都是以单进程的方式对单个stdf文件进行顺序读取,然后将数据保存成需要的形式。该方式在解析较大的stdf文件时,需要耗费很长时间,且会消耗大量内存导致程序容易崩溃,因此只能选择解析其中一部分数据,无法做到全量解析,严重制约了对stdf数据的分析与应用。
技术实现要素:
5.发明目的:针对现有技术的不足,本发明提供一种解析stdf文件的方法,对stdf文件实现高效快速的全量解析。
6.本发明还提供一种快速全量解析stdf文件的设备。
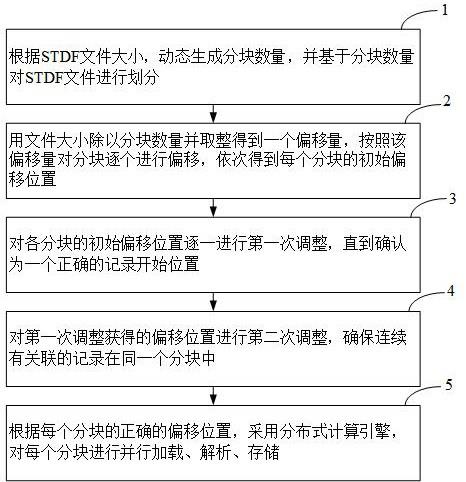
7.技术方案:为了实现上述发明目的,本发明采用如下技术方案:第一方面,提供一种快速全量解析stdf文件的方法,包括以下步骤:根据stdf文件大小,动态生成分块数量,并基于分块数量对stdf文件进行划分;用文件大小除以分块数量并取整得到一个偏移量,按照该偏移量对分块逐个进行偏移,依次得到每个分块的初始偏移位置;对各分块的初始偏移位置逐一进行第一次调整,直到确认为一个正确的记录开始位置;对第一次调整获得的偏移位置进行第二次调整,确保连续有关联的记录在同一个分块中;根据每个分块的正确的偏移位置,采用分布式计算引擎,对各个分块进行并行解析。
8.根据第一方面的某些实施方式,对各分块的初始偏移位置逐一进行第一次调整包括:
从初始偏移位置开始,加载65540*3个字节;从当前位置读取4个字节进行头部解析,判断里面的记录类型是否是有效的类型,如果不是有效的类型,向后移动1个字节,继续从当前位置读取4个字节进行有效类型判断;如果是有效的类型,则判断是否已经有2个连续的完整记录;如果没有2个连续的完整记录,向后移动1个字节,继续从当前位置读取4个字节进行有效类型判断;如果已经有2个连续的完整记录,输出正确的偏移位置值。
9.根据第一方面的某些实施方式,对第一次调整获得的偏移位置进行第二次调整包括:从第一次调整输出的偏移位置开始,每次加载65536*10个字节;从加载的数据中读取1个记录,如果读取失败,向后偏移65536*10个字节继续加载;判断读出来的记录类型是否满足以下条件之一:当前记录是pir且前一个记录不是pir,或者当前记录不是prr且前一个记录是prr;如果条件不满足,继续从加载的数据中读取下一个记录进行类型判断;如果条件满足,输出最终的偏移位置值。
10.根据第一方面的某些实施方式,采用分布式计算引擎,对各个分块进行并行解析包括:对于分布式计算引擎,在主程序中分配并行分区任务数,将其值设置为分块数量,并根据分区任务数设定需要的集群资源;每个分区任务内,从第二次调整输出的偏移位置开始加载文件内容;每个分区任务内,对加载的文件内容进行解析,生成相应的记录数据,并存储到对应的存储系统中;所有分区任务都完成后,由分布式计算引擎的主程序负责最终状态的更新,将数据交付给下游业务应用系统使用。
11.第二方面,提供一种快速全量解析stdf文件的设备,包括:文件分块模块,用于根据stdf文件大小,动态生成分块数量,并基于分块数量对stdf文件进行划分;初始偏移计算模块,用于用文件大小除以分块数量并取整得到一个偏移量,按照该偏移量对分块逐个进行偏移,依次得到每个分块的初始偏移位置;偏移位置第一调整模块,用于对各分块的初始偏移位置逐一进行第一次调整,直到确认为一个正确的记录开始位置;偏移位置第二调整模块,用于对第一次调整获得的偏移位置进行第二次调整,确保连续有关联的记录在同一个分块中;分布式解析模块,用于根据每个分块的正确的偏移位置,对各个分块进行并行解析。
12.根据第二方面的某些实施方式,所述偏移位置第一调整模块包括第一加载单元,用于从初始偏移位置开始,加载65540*3个字节;第一分析处理单元,用于从当前位置读取4个字节进行头部解析,判断里面的记录
类型是否是有效的类型,如果不是有效的类型,向后移动1个字节,并重新读取4个字节进行有效类型判断;如果是有效的类型,判断是否已经有2个连续的完整记录;如果没有2个连续的完整记录,向后移动1个字节,并重新读取4个字节进行有效类型判断;第一输出单元,用于当第一分析处理单元确定已经有2个连续的完整记录时,输出正确的偏移位置值。
13.根据第二方面的某些实施方式,所述偏移位置第二调整模块包括:第二加载单元,用于从偏移位置第一调整模块输出的偏移位置开始,每次加载65536*10个字节;第二分析处理单元,用于从第二加载单元加载的数据中,读取1个记录,如果读取失败,则调用第二加载单元向后偏移65536*10个字节继续加载;并判断读出来的记录类型是否满足以下条件之一:当前记录是pir且前一个记录不是pir,或者当前记录不是prr且前一个记录是prr;如果条件不满足,则重新从加载数据中读取1个记录进行类型判断;第二输出单元,用于当第二分析处理单元确定读出来的记录类型满足条件时,输出最终的偏移位置值。
14.根据第二方面的某些实施方式,所述分布式解析模块包括:分配单元,用于根据分块数量分配并行分区任务数,并设定需要的处理资源;执行单元,用于每个分区任务内,根据偏移位置第二调整模块输出的偏移位置,对加载的文件内容进行解析,生成相应的记录数据,并存储到对应的存储系统中;同步单元,用于在所有分区任务都完成后,进行最终状态的更新,将数据交付给下游业务应用系统使用。
15.第三方面,提供一种快速全量解析stdf文件的系统,包括若干测试机台和分布式计算集群,测试机台产生的stdf文件上传至分布式计算集群,由分布式计算集群实现根据本发明第一方面所述的快速全量解析stdf文件的方法。
16.与现有技术相比,本发明具有以下有益效果:本发明通过将大的stdf文件分块,用分布式计算集群来对分块并行解析,大大降低了解析单个stdf文件的时间,以实际生产中的一个8.4 gb的stdf原始文件为例,原来单进程解析需要15分钟以上,采用本发明的方案只需要3分钟(使用集群资源100 gb内存和80 vcores)。从而为后续的数据分析和应用提供了坚实的基础,帮助及时发现测试生产中的异常问题。
17.本发明可以实现全量解析stdf文件中的数据,不会因为文件过大而无法解析,或者解析程序崩溃而只能解析一部分数据。通过全量的数据,可以对芯片测试结果进行全方位的分析,最大程度的发挥stdf中数据的价值。
18.本发明的系统可以根据stdf文件大小动态调整硬件资源,通过横向扩展机器来提高解析的性能,不会受限于单台机器的性能瓶颈。横向扩展只需要低成本的计算、存储单元即可,相比传统的高性能小型机成本低。
附图说明
19.图1为本发明的stdf文件全量解析方案整体示意图;图2为本发明中全量解析stdf文件的方法的流程图;
图3为本发明中将偏移量调整到正确的记录位置的流程图;图4为本发明中将偏移量调整到正确的touchdown位置的流程图。
具体实施方式
20.下面结合附图对本发明的技术方案作进一步说明。
21.stdf,标准测试数据文件,是以二进制字节流的形式,采用统一格式保存芯片测试过程中产生的各种类型的数据。数据由一个一个的记录(record)组成,每个记录(record)包含4个字节的头部(header)和长度不固定的信息。为了对不同类型的数据做出区分,记录分为多种类型,通过记录类型(record type)来标识,常见的类型有mir(master information record)、mrr(master results record)、pir(part information record)、prr(part results record)等等。
22.参照图1,根据本发明的构思,对stdf文件进行快速全量解析主要包括两个核心步骤:对stdf文件进行分块,根据规则找到每个块的起始解析位置;基于分布式计算引擎,对分割出来的块进行并行解析。
23.参照图2,快速全量解析stdf文件的方法,具体包括以下步骤:步骤1,根据stdf文件大小,动态生成分块数量,分块数量决定了划分为多少个并行解析任务。根据获得的分块数量,对stdf文件进行划分,分为多个分块。
24.步骤2,用文件大小除以分块数量并取整,可以得到一个偏移量,按照该偏移量对分块逐个进行偏移,依次得到每个分块开始的位置,记为初始偏移位置。
25.步骤3,初始偏移位置并不一定是一个记录的开始位置,因此需要逐一进行调整,直到确认为一个正确的记录开始位置,这里称为偏移位置的第一次调整。
26.参照图3,第一次调整具体包括以下步骤:步骤31,从初始偏移位置开始,加载65540*3个字节。这里加载65540*3个字节的原因是,一个完整的头部 header+一个record有效记录信息的最大长度为4+65536=65540,读取3个这样的最大长度,可以保证里面至少有2个完整的记录。
27.步骤32,从当前位置读取4个字节进行头部解析,判断里面的记录类型是否是有效的类型。根据当前记录类型是否为stdf定义的25个类型之一来判断是否为有效类型,步骤33,如果不是有效的类型,向下移动1个字节,回到步骤32循环处理。
28.步骤34,如果是有效的类型,判断是否已经有2个连续的完整记录。这里判断有2个连续的记录的原因是,有效的记录类型主要有25个,那么一个记录有25/65536的概率会误判,连续2个都误判的概率是千万分之1.5,可以满足需求。
29.步骤35,如果没有2个连续的完整记录,移动1个字节,回到步骤32循环处理。
30.步骤36,如果已经有2个连续的完整记录,输出正确的偏移位置值。
31.步骤4,对第一次调整获得的偏移位置进行第二次调整,确保连续有关联的记录在同一个分块中。
32.因为记录之间存在一定的关联性,需要确保连续有关联的记录在同一个分块里面,这样不同分块的记录可以独立解析、存储,这里称为偏移位置的第二次调整。
33.参照图4,第二次调整具体包括以下步骤:步骤41,从步骤3获取的偏移位置开始,每次加载65536*10个字节。
34.步骤42,从步骤41中加载的数据中,读取1个记录,如果读取失败,回到步骤41循环处理,向后偏移65536*10个字节继续加载。
35.步骤43,判断读出来的记录类型是否满足以下条件之一:当前记录是pir & 前一个记录不是pir,或者当前记录不是prr & 前一个记录是prr。
36.步骤44,如果步骤43的条件不满足,回到步骤42循环处理,读取下一个记录。
37.步骤45,如果步骤43的条件满足,输出最终的偏移位置值。
38.步骤5,获取到每个分块的正确的偏移位置后,采用分布式计算引擎,对每个分块进行并行加载、解析、存储。
39.该步骤具体包括:步骤51,对于分布式计算引擎,在主程序中分配并行分区任务数,将其设置为步骤1中的分块数,并根据任务数设定需要的集群资源,从而可以实现整体的并行执行。
40.步骤52,每个分区任务内,从步骤4中获取到的偏移位置开始加载文件内容。
41.步骤53,每个分区任务内,对步骤52中加载的内容进行解析,生成相应的记录数据,并存储到对应的存储系统中。
42.步骤54,所有分区任务都完成后,由分布式计算引擎的主程序负责最终状态的更新,将数据交付给下游的业务应用系统(如生产执行控制管理系统)使用。
43.步骤55,如果在分区任务处理过程中出现异常,分布式计算引擎会自动进行重试,回到步骤52和53继续执行。
44.在一个实施例中,采用spark作为分布式计算引擎。由代理(proxy)程序在测试机台运行,将stdf文件上传到中心服务器。应用服务程序对上报的stdf文件进行监听,发现有新的文件后,按照如下方式进行实施:(1)在应用服务程序中,根据文件大小生成分块数,生成规则示例如下表1所示。以实际生产中的一个8.4 gb的stdf文件为例,将划分为20个分块。也可以自行设置分块规则数。
45.表1 文件分块方法文件大小划分方法0~250mb每50mb分一个块250mb~1gb每100mb分一个块1gb~5gb统一划分为15个块超过5gb统一划分为20个块(2)根据划分的文件分块数,计算需要的spark集群资源,主要考虑需要多少个执行器(executor),每个执行器分配多少内存和cpu资源。以实际生产中的一个8.4 gb的stdf文件为例,需要20个执行器,每个执行器拥有5 gb内存和4个cpu vcores。
46.(3)按照步骤(2)中的资源启动spark程序,在其driver程序中计算偏移量,获得每个分块的起始偏移位置。以实际生产中的一个8.4 gb文件为例,初始的偏移位置如下表2所示。
47.(4)针对步骤(3)中的起始偏移位置,逐一进行调整,直到确认为一个正确的记录开始位置,获得每个分块调整后的偏移位置。以实际生产中的一个8.4 gb文件为例,调整后
的偏移位置如下表2所示。
48.(5)针对步骤(4)中的调整后的偏移位置,进一步逐一调整,将每个touchdown的测试项相关的记录放到一个分块中,获得每个分块最终的偏移位置,touchdown(缩写td)是指机台的一次测试作业,在stdf文件中,一个touchdown包含了一次测试测试作业所有芯片相关的测试数据。以实际生产中的一个8.4 gb文件为例,最终的偏移位置如下表2所示。
49.表2 偏移位置序号初始偏移位置调整后偏移位置最终偏移位置1000244797015644797015844830218138959403128962723438972513194134391046813452215111346224784517918806241794194949179505133762239850780224302152922438336807268782093626918038942692579433831357910923140549647314154917993583761248358951941035905308561040317314044038501041403939482511447970156044873649834488403378124927671716493637353549373363461353756418725385306550538616272514582361202858341329525834760043156271582184628273022062837928531667195523406731763031673276162817716752249671807318337181581105187615492652762955126776304273711980634628088078397532807916265720851143296485271328888528045232(6)在spark的驱动(driver)程序中,根据并行任务数进行分区,通过映射(map)方式启动并行任务,驱动器将当前偏移量和下个偏移量作为参数传递给每个任务的执行器,每个任务负责一个偏移量,对从该偏移量开始到下个偏移量之间的数据进行加载、解析、存储。
50.基于和上述方法相同的技术构思,根据本发明的另一实施例,提供一种快速全量解析stdf文件的设备,包括:文件分块模块,用于根据stdf文件大小,动态生成分块数量,并基于分块数量对stdf文件进行划分;初始偏移计算模块,用于用文件大小除以分块数量并取整得到一个偏移量,按照该偏移量对分块逐个进行偏移,依次得到每个分块的初始偏移位置;偏移位置第一调整模块,用于对各分块的初始偏移位置逐一进行第一次调整,直到确认为一个正确的记录开始位置;
偏移位置第二调整模块,用于对第一次调整获得的偏移位置进行第二次调整,确保连续有关联的记录在同一个分块中;分布式解析模块,用于根据每个分块的正确的偏移位置,对各个分块进行并行解析。
51.其中,偏移位置第一调整模块具体包括:第一加载单元,用于从初始偏移位置开始,加载65540*3个字节;第一分析处理单元,用于从当前位置读取4个字节进行头部解析,判断里面的记录类型是否是有效的类型,如果不是有效的类型,向后移动1个字节,并重新读取4个字节进行有效类型判断;如果是有效的类型,判断是否已经有2个连续的完整记录;如果没有2个连续的完整记录,向后移动1个字节,并重新读取4个字节进行有效类型判断;第一输出单元,用于当第一分析处理单元确定已经有2个连续的完整记录时,输出正确的偏移位置值。
52.进一步地,偏移位置第二调整模块具体包括:第二加载单元,用于从偏移位置第一调整模块输出的偏移位置开始,每次加载65536*10个字节;第二分析处理单元,用于从第二加载单元加载的数据中,读取1个记录,如果读取失败,则调用第二加载单元向后偏移65536*10个字节继续加载;并判断读出来的记录类型是否满足以下条件之一:当前记录是pir且前一个记录不是pir,或者当前记录不是prr且前一个记录是prr;如果条件不满足,则重新从加载数据中读取1个记录进行类型判断;第二输出单元,用于当第二分析处理单元确定读出来的记录类型满足条件时,输出最终的偏移位置值。
53.分布式解析模块具体包括:分配单元,用于根据分块数量分配并行分区任务数,并设定需要的处理资源;执行单元,用于每个分区任务内,根据偏移位置第二调整模块输出的偏移位置,对加载的文件内容进行解析,生成相应的记录数据,并存储到对应的存储系统中;同步单元,用于在所有分区任务都完成后,进行最终状态的更新,将数据交付给下游业务应用系统使用。
54.可选地,分布式解析模块还包括异常处理单元,用于在分区任务处理过程中出现异常时自动进行重试,调用执行单元继续执行任务。
55.应当理解,本实施例提供的一种快速全量解析stdf文件的设备可以实现上述方法实施例中的全部技术方案,其各个功能模块的功能可以根据上述方法实施例中的方法具体实现,其具体实现过程可参照上述实施例中的相关描述,不再赘述。
56.根据本发明的另一实施例,提供一种快速全量解析stdf文件的系统,包括若干测试机台和分布式计算集群,测试机台产生的stdf文件上传至分布式计算集群,由分布式计算集群实现本发明所提出的快速全量解析stdf文件的方法。
57.根据本发明,可以利用多台机器对单个stdf文件进行分布式并行解析,大大降低了stdf文件的解析时间,从而提高了对stdf文件中数据的使用效率。以实际生产中的一个8.4 gb的stdf原始文件为例,原来单进程解析需要15分钟以上,采用本发明的方案只需要3分钟(使用集群资源100 gb内存和80 vcores)。从而为后续的数据分析和应用提供了坚实
的基础,帮助及时发现测试生产中的异常问题。通过快速全量解析stdf中的数据,可以对芯片测试结果进行全方位的分析。一方面,可以从不同维度,以不同的统计图表的形式,快速查找出异常lot,找到改善点;另一方面,可以实现全方位制程管控的系统,辅助测试机截停异常的lot和产品,探测制程异常的原因。此外,系统可以根据stdf文件大小动态调整硬件资源,通过横向扩展机器来提高解析的性能,不会受限于单台机器的性能瓶颈。横向扩展只需要低成本的计算、存储单元即可,相比传统的高性能小型机成本低。
58.本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd
‑
rom、光学存储器等)上实施的计算机程序产品的形式。
59.以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1