缓存管理方法和装置、控制程序及控制器与流程
1.本技术涉及通信技术领域,具体而言,涉及一种缓存管理方法和装置、控制程序及控制器。
背景技术:
2.在以太网交换芯片的应用中,往往需要根据应用场景和成本等,选择不同型号的片外缓存单元,即缓存控制器,所以芯片的缓存管理单元(memory management unit,简称mmu)不仅要能够满足基本的功能需求,且要具有良好的兼容性和可移植性,以便在不同的应用场景下,根据存储大小、速率、功耗和成本等因素连接不同的缓存控制器,而不需要进行多次开发,从而节省人力和成本。
3.随着处理器和存储控制器频率和带宽的不断提升,其各自性能也在不断提高,但缓存访问效率却往往成为系统性能的瓶颈问题,而缓存访问效率与mmu的实现方式有关。在以太网交换芯片中,mmu的主要功能是负责报文(packet,pk)的数据、报文描述符(packet descriptor,pd)的写请求、写数据分发,并按照写请求保序释放;再将数据根据读请求保序读回,在这个过程中,通过片外地址管理、物理地址映射和拼包等技术尽可能最大化利用缓存带宽,以提高存储控制器的效率。当下主流的缓存控制器有ddr3/ddr4/ddr5(double data rate,ddr双倍速率)、hbm(high bandwidth memory)(高带宽存储器)等,如何在同一种框架下兼容不同的控制器且能够保证其存储效率是待解决的主要问题。
4.针对上述如何在同一种框架下兼容不同的控制器的问题,目前尚未提出有效的解决方案。
技术实现要素:
5.本技术实施例提供了一种缓存管理方法和装置、控制程序及控制器,以至少解决相关技术中如何在同一种框架下兼容不同的控制器的问题。
6.根据本技术的一个实施例,提供了一种缓存管理方法,包括:缓存管理单元mmu基于cpu配置信息,识别外接的缓存控制器类型;基于地址管理子模块和上述缓存控制器类型对应的地址区域,以查表的方式确认偏移地址;基于上述偏移地址计算出上述缓存控制器类型的逻辑地址;其中,不同的上述缓存控制器类型选通的对外连接通道数不同。
7.根据本技术的另一个实施例,提供了一种缓存管理装置,包括:识别单元,用于使缓存管理单元mmu基于cpu配置信息,识别外接的缓存控制器类型;确认单元,用于基于地址管理子模块和上述缓存控制器类型对应的地址区域,以查表的方式确认偏移地址;计算单元,用于基于上述偏移地址计算出上述缓存控制器类型的逻辑地址;其中,不同的上述缓存控制器类型选通的对外连接通道数不同。
8.根据本技术的又一个实施例,还提供了一种计算机可读存储控制程序,上述计算机可读存储控制程序中存储有计算机程序,其中,上述计算机程序被设置为运行时执行上述任一项方法实施例中的步骤。
9.根据本技术的又一个实施例,还提供了一种控制器,包括缓存器和处理器,上述控制器中存储有计算机程序,上述处理器被设置为运行上述计算机程序以执行上述任一项方法实施例中的步骤。
10.通过本技术,由于采用了缓存管理单元mmu基于cpu配置信息,识别外接的缓存控制器类型;基于地址管理子模块和上述缓存控制器类型对应的地址区域,以查表的方式确认偏移地址;基于上述偏移地址计算出上述缓存控制器类型的逻辑地址;其中,不同的上述缓存控制器类型选通的对外连接通道数不同;因此,实现了同一种框架下不同的控制器的切换,可以解决同一种框架下兼容不同的控制器的问题,进而在同一框架下可兼容多种控制器,以及提高存储效率的效果。
附图说明
11.图1是根据本技术实施例的缓存管理方法的移动终端的硬件结构框图;
12.图2是根据本技术实施例的缓存管理方法的流程图;
13.图3是根据本技术实施例的缓存管理系统的架构示意图;
14.图4是根据本技术实施例的缓存管理方法中的hbm的optione模式的示意图;
15.图5是根据本技术实施例的缓存管理方法中的地址对应关系的示意图一;
16.图6是根据本技术实施例的缓存管理方法中的地址对应关系的示意图二;
17.图7是根据本技术实施例的缓存管理方法中的地址对应关系的示意图三;
18.图8是根据本技术实施例的缓存管理方法中的地址对应关系的示意图四;
19.图9是根据本技术实施例的缓存管理方法中的地址映射的示意图一;
20.图10是根据本技术实施例的缓存管理方法中的地址映射的示意图二;
21.图11是根据本技术实施例的缓存管理方法中的地址映射的示意图三;
22.图12是根据本技术实施例的缓存管理方法的片外地址管理示意图;
23.图13是根据本技术实施例的缓存管理装置的结构示意图。
具体实施方式
24.下文中将参考附图并结合实施例来详细说明本技术的实施例。
25.需要说明的是,本技术的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。
26.本技术实施例中所提供的方法实施例可以在移动终端、计算机终端或者类似的运算装置中执行。以运行在移动终端上为例,图1是本技术实施例的缓存管理方法的移动终端的硬件结构框图。如图1所示,移动终端可以包括一个或多个(图1中仅示出一个)处理器102(处理器102可以包括但不限于微处理器mcu或可编程逻辑器件fpga等的处理装置)和用于存储数据的存储器104,其中,上述移动终端还可以包括用于通信功能的传输设备106以及输入输出设备108。本领域普通技术人员可以理解,图1所示的结构仅为示意,其并不对上述移动终端的结构造成限定。例如,移动终端还可包括比图1中所示更多或者更少的组件,或者具有与图1所示不同的配置。
27.存储器104可用于存储计算机程序,例如,应用软件的软件程序以及模块,如本技术实施例中的缓存管理方法对应的计算机程序,处理器102通过运行存储在存储器104内的
计算机程序,从而执行各种功能应用以及数据处理,即实现上述的方法。存储器104可包括高速随机存储器,还可包括非易失性存储器,如一个或者多个磁性存储装置、闪存、或者其他非易失性固态存储器。在一些实例中,存储器104可进一步包括相对于处理器102远程设置的存储器,这些远程存储器可以通过网络连接至移动终端。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
28.传输装置106用于经由一个网络接收或者发送数据。上述的网络具体实例可包括移动终端的通信供应商提供的无线网络。在一个实例中,传输装置106包括一个网络适配器(network interface controller,简称为nic),其可通过基站与其他网络设备相连从而可与互联网进行通讯。在一个实例中,传输装置106可以为射频(radio frequency,简称为rf)模块,其用于通过无线方式与互联网进行通讯。
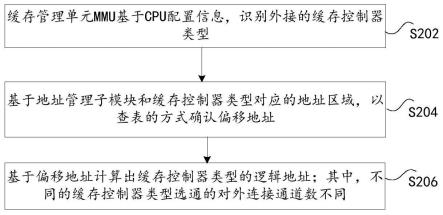
29.图2是根据本技术实施例的缓存管理方法的流程图,如图2所示,该流程包括如下步骤:
30.步骤s202,缓存管理单元mmu基于中央处理器cpu配置信息,识别外接的缓存控制器类型;
31.步骤s204,基于地址管理子模块和上述缓存控制器类型对应的地址区域,以查表的方式确认偏移地址;
32.步骤s206,基于上述偏移地址计算出上述缓存控制器类型的逻辑地址;其中,不同的上述缓存控制器类型选通的对外连接通道数不同。
33.通过本技术实施例,由于采用了缓存管理单元mmu基于cpu配置信息,识别外接的缓存控制器类型;基于地址管理子模块和上述缓存控制器类型对应的地址区域,以查表的方式确认偏移地址;基于上述偏移地址计算出上述缓存控制器类型的逻辑地址;其中,不同的上述缓存控制器类型选通的对外连接通道数不同;因此,实现了同一种框架下不同的控制器的切换,可以解决同一种框架下兼容不同的控制器的问题,进而同一框架下可兼容多种控制器,以及提高存储效率的效果。
34.在一个或多个实施例中,上述缓存管理方法还包括:上述mmu的地址映射子模块读取预设的地址映射关系;上述地址映射关系为将片内逻辑地址转换为能被缓存芯片接受的物理地址。
35.在一个或多个实施例中,上述缓存管理方法还包括:上述方法还包括:上述mmu的地址映射子模块读取预设的地址映射关系;上述地址映射关系为将片内逻辑地址转换为能被缓存芯片接受的物理地址;根据不同应用场景,通过cpu进行重配置,以获取重配置后与上述应用场景对应的地址映射关系。
36.在一个或多个实施例中,上述缓存管理方法还包括:根据片外缓存的需求和缓存控制器的结构属性,按照块单元block将cpu发送给上述mmu的数据包进行切分,其中,切分后的数据包与block地址相对应,一个数据包对应多个block地址,上述缓存控制器的类型不同时地址管理的区间不同。
37.在一个或多个实施例中,上述缓存管理方法还包括:上述mmu接收到报文缓存管理单元pmu发送的片外数据,其中,上述片外数据包括报文描述符pd和报文pk;提取上述pd的数据信息;将上述数据信息进行拼包得到拼包数据,并删除上述pk中的第一数据;这里,第一数据可以包括拼包数据中的无效数据。
38.对上述拼包数据进行移位拼接,提取出第二数据;这里,第二数据可以包括拼包数据中的有效数据。将上述拼包数据中的上述pd的数据信息和提取出的上述第二数据再次进行拼包,得到目标拼包数据。上述目标拼包数据发送至片外缓存进行存储。
39.在一个或多个实施例中,上述缓存管理方法还包括:在上述pd的数据位长度加上提取出的上述第二数据的数据位长度小于或等于总线位宽时,同时输出上述pd和上述第二数据;
40.在上述pd的数据位长度加上提取出的上述第二数据的数据位长度大于总线位宽时,将上述pd和上述第二数据拆分为第一拆分数据和第二拆分数据;
41.输出上述pd和上述第一拆分数据;
42.将上述第二拆分数据进行补零操作,得到数据位长度等于上述总线位宽的补零处理数据,并输出上述补零处理数据。
43.在一个或多个实施例中,上述缓存管理方法还包括:报文缓存管理单元pmu下发写报文;
44.上述pmu存储上述写报文,发送写释放命令给流量缓存管理单元tmmu;上述tmmu下发报文描述符至队列管理单元qmu;
45.上述qmu通过上述tmmu下发写命令,并透传给上述mmu,上述qmu完成存储上述写命令后向上述tmmu发写释放信号;
46.命令队列下发读报文命令,读取读报文数据并将上述读报文数据返回到上述pmu;
47.上述tmmu下发读命令,并读取报文描述符数据。
48.基于上述实施例,在一应用实施例中,本技术提供的缓存管理装置中,mmu位于片外存储控制器和片上控制模块之间,图3是根据本技术实施例的缓存管理系统的架构示意图,如图3所示,mmu位于pmu(packet memory unit)报文存储单元、tmmu(tm memory management unit内存管理单元)、cmd_fifo(command fifo,命令先进先出队列)和hbm(high bandwidth memory,高带宽存储器)/ddr之间,本技术实施例的缓存管理方法主要能实现功能如下:
49.1)负责多队列报文pk、报文描述符pd写请求和写数据的分发,写释放的保存;
50.2)负责多队列pk、pd读请求的分发,读数据的保存;
51.3)支持多类型的缓存控制器的模式切换;
52.4)逻辑地址到片外物理地址的映射可重配置。
53.上述pmu存储上述写报文,发送写释放命令给流量缓存管理单元tmmu;上述tmmu下发报文描述符至队列管理单元qmu;上述qmu通过上述tmmu下发写命令,并透传给上述mmu,上述qmu完成存储上述写命令后向上述tmmu发写释放信号;
54.命令队列下发读报文命令,读取读报文数据并将上述读报文数据返回到上述pmu;上述tmmu下发读命令,并读取报文描述符数据。在整个框架中,为了解决兼容性和提高片外访问带宽及效率,主要采用的技术有地址管理、pc均衡、片外地址映射和拼包技术,兼容性是贯穿整个缓存管理过程,从而兼顾所有支持控制器的功能和性能。
55.在一应用实施例中,上述缓存管理方法包括:
56.第一步,多控制器切换。通过cpu配置,缓存管理模块识别外接的缓存控制器类型,地址管理子模块根据控制器类型对应的地址区域,通过查表的方式确认偏移地址,从而计
算出该类型控制器的逻辑地址;配置不同的缓存控制器类型,选通的对外连接通道数不同。本技术根据片外缓存的需求,设计16个channel(通道)的片外缓存接口,每个channel均完整支持axi4总线的写地址、写数据、写响应、读地址和读数据五个通道。在mmu中,分hbm和ddr模式,支持模式切换可配置,默认为16channel的hbm。通过cpu配置,可切换到ddr模式下,用户根据自身的需求,可选择连接ddr4或ddr5等不同类型,只要连接的容量大小不小于地址管理的最大节点数对应的数据容量,连接的hbm/ddr空间均可被有效利用;
57.由于支持不同类型的缓存控制器,各类型的控制器的传输速率并不一定和mmu的系统时钟同步,为了适配不同的控制器和保证数据的线速传输,划分片上的部分缓存区域,以异步(先进先出队列)fifo的形式,先将数据缓存,同时通过自研逻辑的预读功能,将数据和命令预读出来进入ready等待状态,当有效缓存控制器到来的时候,通过握手机制同周期将数据送出,这样可以保证最大程度利用片外控制器的带宽,且可靠地将数据流跨时钟处理。
58.第二步,配置地址映射。地址映射子模块根据配置的类型,读取系统预设的地址映射关系,此地址映射关系可根据应用场景,通过cpu进行重配置,以调整最佳的映射方式;
59.由于逻辑地址不能直接索引到hbm/ddr的地址引脚上,经过mmu的处理,将逻辑地址转换为能被缓存芯片接受的地址,称为物理地址。因为缓存hbm/ddr的多层次结构,地址映射的方式和片外读写带宽、存储速率及效率有很大关系。
60.本技术的地址映射,是将每个物理通道(数据总线位宽128bit)分两个虚拟通道(pseudo channel,伪信道,简称pc,数据总线位宽64bit),两个虚拟通道共用一组地址和控制总线。
61.图4是根据本技术实施例的缓存管理方法中的hbm的optione模式的示意图,在hbm的optione模式下如图4所示,每个虚拟通道对应一个控制器,控制器以缓存频率的一半运行。psgnt代表的虚拟通道(ps),是控制器内部仲裁信号,控制器根据ps的物理接口确定psgnt的值。逻辑在处理的时候,只需把一个hbmstack的8个控制器当成16个控制器对待,一个控制对应一个物理ps。
62.sid是数据8hi的特有地址,可以当做一个bank(存储体)地址,8hi的bank数是4hi的二倍,分别是32个bank,16个bank。连续4个id的bank属于一个存储体集合bank_group。8hi、4hi分别是8个bank,4个bank。
63.laddr[n:0]是8byte地址(一个控制的总线位宽为128bit,划分为两个ps,每个ps的位宽为64bit),由于hbm控制器的预取倍为4,一次存储256bit,会占用4个地址,所以laddr[1:0]实际逻辑不会分配地址,实际默认为0,控制器也不用。
[0064]
mmu送出的地址为384b地址(实际地址为2的整数次幂送出),axi的地址为1字节,ps通道对应的颗粒每个地址存128bit数据,所以四者地址对应关系如下:
[0065]
图5是根据本技术实施例的缓存管理方法中的地址对应关系的示意图一,使用samsung hbm2 4hi4g时,每个ps的存储空间为4gb/16=2gb,对应关系如图5所示,{a[31:a28],a[4:0]}填充为0:
[0066]
图6是根据本技术实施例的缓存管理方法中的地址对应关系的示意图二,使用samsung hbm2 8hi8g时,每个ps的存储空间为8gb/16=4gb,对应关系如图6所示,{a[31:a29],a[4:0]}填充为0:
[0067]
图7是根据本技术实施例的缓存管理方法中的地址对应关系的示意图三,使用samsung hbm2e 4hi8g时,每个ps的存储空间为8gb/16=4gb,对应关系如图7所示,{a[31:a29],a[4:0]}填充为0:
[0068]
图8是根据本技术实施例的缓存管理方法中的地址对应关系的示意图四,使用samsung hbm2e 8hi16g时,每个ps的存储空间为8gb/16=4gb,对应关系如图8所示,{a[31:a30],a[4:0]}填充为0:
[0069]
图9是根据本技术实施例的缓存管理方法中的地址映射的示意图一,要充分发挥hbm的带宽,需均衡的使用16个ps,同时通道内增加bank切换,当前采用4hi4g的颗粒,逻辑地址和物理地址间的映射关系如图9所示。
[0070]
图10是根据本技术实施例的缓存管理方法中的地址映射的示意图二,外挂ddr5的时候,可配置连接3个通道的ddr5,其逻辑地址和物理地址的映射关系如图10所示。
[0071]
图11是根据本技术实施例的缓存管理方法中的地址映射的示意图三,外挂ddr4的时候,可配置连接3个通道的ddr5,其逻辑地址和物理地址的映射关系如图11所示。
[0072]
第三步,片外地址管理。根据片外缓存的需求,和缓存控制器的结构特点,片外缓存地址是以块block(可配置的固定大小数据单元)为单位进行管理,称为虚拟地址(也称作逻辑地址),处理器发送给mmu的一个数据包需按照block进行切分,以便与block地址进行对应,这样处理后,一个数据包有可能对应多个block数据,即需要产生多个block地址。根据片外缓存控制器的类型不同,地址管理的区间不同。
[0073]
图12是根据本技术实施例的缓存管理方法的片外地址管理示意图,如图12所示,trunk(中继端口)地址为128k,t[16:13]为16个大链表id,t[12:10]为每个大链表下面的子链表id,t[9:0]为每个子链表内链表编号,b[3:0]为每个trunk下面blk的个数,c[2:0]为每个blk下面的切片个数(数据+1代表切片个数)。链表id申请采用rr(round-robin(轮询))调度,当一条流进来时会先rr申请选中大链表,大链表内再rr选中一个子链表,然后从子链表内申请一个链表。同一条流会优先耗尽一个turnk中的blk,不同流会重新申请trunk。地址管理的{t[9:0],b[3:0],t[12:10],t[16:13]}可作为一个counter,此地址是连续变化。当外挂hbm的时候,t[16:13]个16个channel一一对应;当外挂ddr的时候,对应选通3个通道,使用t[14:13]作为channel_id,即选通0(4、8、12)、1(5、9、13)、2(6、10、14)通道,3、7、11、15通道可配置不使用。由于t[16:13]的低两bit的粒度更小,所以其变化更快,通过地址映射后的缓存访问效率会更好。根据设定的位宽大小,mmu可管理2(4+3+10+4)=2m个节点,总共可管理2mx3k(blk大小可配,以3k为例)=48g的数据。
[0074]
为了保证整体的性能和带宽,在地址管理模块需保证各伪信道pc间的均衡访问,避免出现短时间内个别pc频繁访问,而其余pc空闲的情况,如果出现某个pc返回较慢,反馈给mmu忙状态时候,可根据实时命令统计和单pc历史命令统计,减少一次调度,从数据流的整个过程分析,pc之间依然是均衡访问。
[0075]
第四步,小包拼接技术。将片上pd存储至片外,理论上因其包长的原因,会降低片外存储的带宽和效率,但因其存储数量较大,为了节省片上资源,将pd搬移至片外进行存储,此处采用拼包技术对其进行存储,拼包的目的是通过挤泡将片外需要拼包的pk和pd中的无效字节挤掉,然后将有效字节进行拼接,以此来提高片外缓存的利用率。
[0076]
拼包的步骤是mmu收到pmu送过来的片外包pd和pk,首先进行pd信息的提取和拼
包,同时将pk中的无效字节挤掉,对小包进行移位拼接,提取出有效数据,然后将拼包后的pd信息和提取出有效数据的pk再次进行拼包,将结果发送至片外进行存储。
[0077]
由于片外的总线位宽是384b,除了单包(不需要拼包),不同种类的拼包情况对于每一拍输出的结果也不一样,小包拼接分两种情况:小包拼小包(pd_len+pk_len≤384b);小包拼小包(pd_len+pk_len》384b)。当第一种小包拼小包时,pd的长度加上提取出的数据长度小于总线位宽,可以一拍输出;当第二种小包拼小包的时候,由于长度大于总线位宽,需要分两拍输出,第一拍输出高384b,剩下的部分在第二拍尾部补零输出,这样会对线速产生影响,需尽量规避。
[0078]
本技术的方案不仅能够兼容多种类型的缓存控制器,且能够提升片外读写带宽和访问效率。以下通过实测数据,分别举例说明外挂hbm/ddr5/ddr4三种类型控制器的情况下,带宽和效率提升前后的实测数据。
[0079]
使用标准地址映射的测试外挂hbm的结果如表1所示。本技术的效率提升方法测试结果如表2所示,表3为外挂ddr5的测试数据,表4为外挂ddr4的测试数据,经过实测结果对比分析,各模式下的片外总带宽和存储效率均有提升。
[0080]
表1
[0081]
用例编号片外存储包长(byte)总带宽(gbps)效率11288620.35219213520.55325616430.67428816070.65535217390.71638417690.72776816480.678115216340.679153616280.6610156816010.65
[0082]
表2
[0083][0084][0085]
表2(续)
[0086]
用例编号片外存储包长(byte)总带宽(gbps)效率776821690.888115221660.88
9153621330.8610156820280.83
[0087]
表3
[0088]
用例编号片外存储包长(byte)总带宽(gbps)效率1128136.890.592192154.220.673256163.540.714384168.490.735768170.630.7461152172.450.7571184169.610.7481536173.550.7591568169.950.741012288166.540.72
[0089]
表4
[0090]
用例编号片外存储包长(byte)总带宽(gbps)效率1128200.6465.352192247.8580.733256267.0386.984384272.2988.695768270.6188.1561152243.7879.4171536252.6882.3181568232.2575.6596144233.9976.221012288220.0571.68
[0091]
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到根据上述实施例的方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本技术的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,或者网络设备等)执行本技术各个实施例上述的方法。
[0092]
在本实施例中还提供了一种图形渲染的处理装置,该装置用于实现上述实施例及优选实施方式,已经进行过说明的不再赘述。如以下所使用的,术语“模块”可以实现预定功能的软件和/或硬件的组合。尽管以下实施例所描述的装置较佳地以软件来实现,但是硬件,或者软件和硬件的组合的实现也是可能并被构想的。
[0093]
图13本技术实施例的缓存管理装置的结构框图,如图13所示,该装置包括:
[0094]
识别单元1302,用于使缓存管理单元mmu基于cpu配置信息,识别外接的缓存控制器类型;
[0095]
确认单元1304,用于基于地址管理子模块和上述缓存控制器类型对应的地址区域,以查表的方式确认偏移地址;
[0096]
计算单元1306,用于基于上述偏移地址计算出上述缓存控制器类型的逻辑地址;其中,不同的上述缓存控制器类型选通的对外连接通道数不同。
[0097]
通过本技术,由于采用了缓存管理单元mmu基于cpu配置信息,识别外接的缓存控制器类型;基于地址管理子模块和上述缓存控制器类型对应的地址区域,以查表的方式确认偏移地址;基于上述偏移地址计算出上述缓存控制器类型的逻辑地址;其中,不同的上述缓存控制器类型选通的对外连接通道数不同;因此,实现了同一种框架下不同的控制器的切换,可以解决同一种框架下兼容不同的控制器的问题,进而同一框架下可兼容多种控制器,以及提高存储效率的效果。
[0098]
需要说明的是,上述各个模块是可以通过软件或硬件来实现的,对于后者,可以通过以下方式实现,但不限于此:上述模块均位于同一处理器中;或者,上述各个模块以任意组合的形式分别位于不同的处理器中。
[0099]
本技术的实施例还提供了一种计算机可读存储控制程序,该计算机可读存储控制程序中存储有计算机程序,其中,该计算机程序被设置为运行时执行上述任一项方法实施例中的步骤。
[0100]
在一个示例性实施例中,上述计算机可读存储控制程序可以包括但不限于:cpu和存储控制器的驱动程序、fpga与hbm/ddr3连接的控制程序等。
[0101]
本技术的实施例还提供了一种控制器,包括缓存器(缓存部分数据)和处理器,该控制器中存储有计算机程序,该控制器被设置为运行计算机程序以执行上述任一项方法实施例中的步骤。
[0102]
在一个示例性实施例中,上述控制器还可以包括协议转换的传输设备,其中,该传输设备和上述控制器连接,实现与缓存控制器的连接。
[0103]
本实施例中的具体示例可以参考上述实施例及示例性实施方式中所描述的示例,本实施例在此不再赘述。
[0104]
显然,本领域的技术人员应该明白,上述的本技术的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,并且在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本技术不限制于任何特定的硬件和软件结合。
[0105]
以上所述仅为本技术的优选实施例而已,并不用于限制本技术,对于本领域的技术人员来说,本技术可以有各种更改和变化。凡在本技术的原则之内,所作的任何修改、等同替换、改进等,均应包含在本技术的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1