一种基于全局和局部注意力机制的文本识别方法
1.本发明涉及模式识别与人工智能技术领域,特别是涉及一种基于全局和局部注意力机制的文本识别方法。
背景技术:
2.随着计算机技术的迅猛发展,人工智能技术也成为生产和生活中不可缺少的驱动力。近年来,深度学习技术的进步和相关硬件的发展,使得深度神经网络的实际应用成为可能。
3.文本在日常生活中随处可见,是信息传递的载体。人类从视觉中获得的信息,大部分来自于文本。同时,文本也是人类文明和知识传承的载体。因而,如何自动地从文本图片或者联机笔迹中识别出文本信息成为一项具有极大价值和意义的研究。但是,文本识别中存在很多难点。首先,复杂多样的背景使得识别模型受到极大的干扰。其次,多种多样的书写风格和印刷体风格对识别模型的鲁棒性提出了极大的挑战。最后,字符种类较多(例如中文)和不同种类间的样本数量不平衡问题增加了模型训练的难度。设计一种高效准确的文本识别方法势在必行。
4.随着深度学习的兴起,学者们已经提出了一些行之有效的文本识别方法。对于脱机文本行图片,通常采用卷积神经网络提取特征。在提取的特征的基础上,采用循环神经网络结合注意力机制或ctc解码得到识别结果。对于联机笔迹,通常采用转为脱机特征或直接使用循环神经网络处理。但是这些方法在建模全局关系和模型前向速度上存在弱点。
5.因此,亟需一种基于全局和局部注意力机制的文本识别方法来保证模型前向时的并行性成为现今需要解决的问题。
技术实现要素:
6.本发明的目的是提供一种基于全局和局部注意力机制的文本识别方法,通过有效地、交替地建模全局和局部注意力来提取特征,同时保证了模型前向时的并行性,极大地提高了效率。
7.为实现上述目的,本发明提供一种基于全局和局部注意力机制的文本识别方法,包括以下步骤:
8.s1、将合成文本行和公开文本行作为训练样本;将真实场景下采集的文本行作为测试样本;
9.s2、对所述训练样本和所述测试样本进行预处理;
10.s3、基于预处理后的训练样本,确定训练标签;
11.s4、采用卷积层和自注意力层结构构建识别网络;
12.s5、将预处理后的训练样本输入到所述识别网络中进行训练,结合所述训练标签,并采用ctc损失进行网络优化,得到训练好的识别网络;
13.s6、将预处理后的测试样本输入到所述训练好的识别网络中,输出文本识别结果。
14.优选地,所述s2包括:
15.s2.1、在保持宽高比固定的情况下,将所述训练样本和所述测试样本中的脱机文本图片高度归一化为128个像素,得到预处理后的图片;
16.s2.2、将所述训练样本和所述测试样本中的联机文本的联机笔迹旋转为水平状态,再对水平状态的联机笔迹进行特征提取,得到预处理后的笔迹特征。
17.优选地,所述s2.2包括:
18.s2.21、将所述联机笔迹中的所有点通过线性回归得到一条直线;
19.s2.22、计算直线的斜率,并通过所述斜率得到所述联机笔迹的倾斜角度θ;
20.s2.23、将所述联机笔迹顺指针旋转θ角到水平位置,得到旋转后的联机笔迹;
21.s2.24、基于所述旋转后的联机笔迹,得到多维的笔迹特征。
22.优选地,所述s3包括:
23.s3.1、对于预处理后的训练样本中的公开文本行,直接记录文本标签;
24.s3.2、对于预处理后的训练样本中的合成文本行,记录合成数据时返回的文本标签。
25.优选地,所述s4包括:
26.s4.1、构建全局和局部注意力模块;
27.s4.2、基于所述s4.1,通过分类器构建识别网络。
28.优选地,所述s4.1包括:
29.s4.11、基于训练样本的输入特征,通过卷积层提取局部特征;
30.s4.12、基于所述局部特征,通过多头自注意力机制建模全局特征;
31.s4.13、所述多头自注意力机制建模全局特征通过fnn两层全连接层网络和layernorm层归一化操作,得到中间特征;所述中间特征再通过卷积二次提取局部特征,得到全局和局部注意力模块。
32.优选地,所述s4.2包括:
33.通过若干个串联的所述s4.1中的全局和局部注意力模块进行特征提取,得到一维特征;基于所述一维特征,通过分类器输出分类概率,从而构建出识别网络。
34.优选地,所述s5包括:
35.s5.1、对所述识别网络进行参数设置,并将预处理后的训练样本输入到所述识别网络中进行训练;
36.s5.2、基于所述分类概率和所述训练标签,通过ctc方法计算识别网络损失,通过自适应的梯度下降法优化网络参数,得到训练好的识别网络。
37.优选地,所述识别网络采用有监督方法来训练识别网络。
38.优选地,所述s6包括:
39.将预处理后的测试样本输入到所述训练好的识别网络中,输出分类概率;基于所述分类概率,得到长度为l的字符序列,去除连续重复字符和空类别字符后,得到最终的识别结果。
40.与现有技术相比,本发明具有以下技术效果:
41.(1)本发明采用基于全局和局部注意力机制的特征提取方法,可以有效地建模输入数据的全局和局部关联,提升特征的表征能力。
42.(2)本发明采用可以并行计算的模块,摒弃了循环神经网络等结构,大大提升了模型的前向速度。
43.(3)本发明识别准确率高、鲁棒性强。
附图说明
44.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
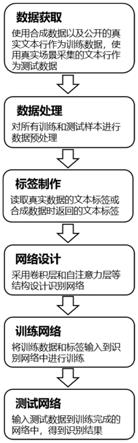
45.图1为本发明实施例的方法流程图;
46.图2为本发明实施例的数据处理流程图;
47.图3为本发明实施例的文本识别流程图;
48.图4为本发明实施例的通道数为n
c
的全局和局部注意力模块的结构图。
具体实施方式
49.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
50.为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
51.实施例1
52.参照图1所示,本发明提出一种基于全局和局部注意力机制的文本识别方法,具体包括以下步骤:
53.s1、数据获取:将合成文本行和公开的真实文本行作为训练样本数据,将真实场景下采集的文本行作为测试样本数据。
54.其中,合成数据为边训练边合成。
55.s2、数据处理:对训练样本和测试样本进行数据预处理操作,参照图2所示。
56.其中,训练样本和测试样本中均包括脱机文本和联机文本;对于脱机文本,在保持宽高比的同时,将脱机文本图片高度归一化为128个像素,记为图片i;
57.对于联机文本,将联机笔迹旋转为水平,再进行特征提取操作,具体为:
58.联机笔迹s为多个点的坐标组成的序列,针对所有点的(x,y)坐标,通过线性回归得到一条直线;接着通过该直线的斜率得到文本的倾斜角度θ;然后再将联机笔迹s顺时针旋转θ角到水平位置,得到旋转后的联机笔迹s1,其表达式为:
59.s1={(x
i
,y
i
,s
i
)|1≤i≤n}
60.其中,s
i
为当前点所属笔画的序号,(x
i
,y
i
)为当前点的坐标,n为点的总数量。
61.基于联机笔迹s1,得到6维的笔迹特征序列f,如下:
62.f={(x
i
,y
i
,x
i+1
‑
x
i
,y
i+1
‑
y
i
,s
i+1
=s
i
,s
i+1
≠s
i
)|1≤i≤n
‑
1}
63.s3、标签制作:由于本发明采用有监督方法来训练识别模型,所以每个训练文本行
都有对应的文本信息。对于公开文本行数据集,直接读取其记录的文本标签;对于合成的文本行,合成数据的同时会返回对应的文本行标签。
64.其中,使用公开的文本语料和单字数据,合成联机和脱机文本行,在合成的同时返回标签信息;对于公开文本行数据集,读取其记录的文本行标签。
65.s4、网络设计:采用卷积层和自注意力层等结构构建识别网络,以交替地提取输入文本行的全局和局部特征,参照图4所示,具体为:
66.s4.1、构建全局和局部注意力模块。
67.首先,对于输入特征f1,通过卷积层提取局部特征f2:
68.f2=conv(f1)
69.其中,conv表示卷积操作。
70.接着,对于局部特征f2,通过多头自注意力机制建模全局特征f3,其表达式为:
71.f3=multihead(q,k,v)=concat(head1,head2,
…
,head
h
)w
o
[0072][0073][0074]
式中,q,k,v均等于f2;;;其中d
model
为f2的维度且d
k
=d
v
=d
model
/h。
[0075]
然后,对于特征f3,进行如下操作:
[0076]
f4=layernorm(f3+f2)
[0077]
f5=layernorm(ffn(f4)+f4)
[0078]
其中,layernorm为层归一化操作(layer normalization),ffn为两层全连接层组成的网络。
[0079]
最后,对于特征f5,再次通过卷积提取局部特征:
[0080]
f6=conv(f5)
[0081]
上述操作共同组成一个全局和局部注意力模块。
[0082]
s4.2、构建识别网络。识别网络由多个全局和局部注意力模块和分类器组成。
[0083]
首先,对于输入图片i或从联机笔记中提取的特征f,经由多个串联的全局和局部注意力模块提取出一维特征其中,l为特征的长度,d
cls
为特征的维度。
[0084]
接着,分类器基于特征f
cls
,输出分类概率其中n
cls
为字符类别数,多出的一类为空类别:
[0085]
p
cls
=softmax(f
cls
w
cls
+b
cls
[0086]
其中,
[0087]
最后,通过分类概率p
cls
得到长度为l的字符序列,去除连续重复字符和空类别字符后,得到最终的识别结果。
[0088]
s5、训练网络:把准备好的训练数据及标签输入到识别网络中训练。采用
connectionist temporal classification(ctc)损失进行网络优化。
[0089]
s5.1、训练参数设定:对所述识别网络进行参数设置,将训练样本数据送入识别网络训练,学习率为0.0001,每次迭代送入32条数据,其中50%为真实数据,50%为合成数据。
[0090]
s5.2、训练卷积神经网络:结合分类概率p
cls
和文本标签,通过ctc方法计算网络损失,通过自适应的梯度下降法(adamw)优化网络参数。
[0091]
s6、输入测试数据到训练完成的网络中,得到识别结果,参照图3所示,把测试集中的图片以及标签输入到已训练好的识别网络中,进行识别测试。识别完成后,程序计算准确率。
[0092]
以上所述的实施例仅是对本发明的优选方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案做出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1