基于属性异构网络表示学习的专利交易推荐方法
:
1.本发明可应用于专利交易推荐领域,包括为组织推荐专利和交易 伙伴。
背景技术:
2.专利交易是专利价值实现的重要途径,在支持企业专利运营战略、 提升企业创新能力、促进产业高质量发展等方面起着重要作用。随着 全球知识产权的激烈竞争,授权专利的数量不断增加,但专利交易率 低的问题不容忽视。专利交易推荐是融合用户属性以及用户搜索、交 易等行为信息,挖掘用户偏好,并在海量技术供给中快速匹配出符合 偏好的专利或交易伙伴的复杂过程,是基于多源异构信息融合以促进 专利交易的重要手段。基于海量的专利以及交易数据,开展智能化专 利交易推荐,对促进专利成果转化应用具有重要价值。
3.(1)专利交易推荐方法
4.现有专利交易推荐方法主要包括两类:第一类是基于同构信息 网络链路预测的交易推荐,该类方法首先基于组织间历史交易数据, 构建组织间专利交易网络。然后针对未连接的组织对进行链路预测, 即:通过已知的网络节点以及结构等信息预测网络中尚未产生连边的 两个节点之间产生链接的可能性,实现为组织推荐交易伙伴的目的。 该类方法难以融合专利、组织等多类型对象及对象间多维关系信息, 推荐结果的可解释性和精确度有待提高。
5.第二类是基于异构信息网络(heterogeneous informationnetwork,hin)进行交易推荐,该类方法首先融合多类型对象以及 对象间的多维关系,其中包括专利之间的语义相似关系、对象间的历 史合作关系等,构建异构信息网络。然后人工规划元路径,并通过元 路径遍历、嵌入表示以及相似度计算,进行专利交易推荐。该类方法 能显著提高推荐精度,但常常忽略组织、专利等多类型对象的属性信 息,或者是将对象的部分属性看作是新的节点类型,使得异构网络拓 扑的复杂性大大增加。基于此,如何在异构信息网络中直接融合多类 型对象的属性信息,构建属性异构信息网络,并开展专利交易推荐, 需要提出新的解决方法。
6.(2)属性异构信息网络表示学习方法
7.基于属性异构信息网络(attributed heterogeneous network, ahn)进行专利交易推荐的一个关键技术难点在于如何进行网络表 示学习,将网络中的多类型节点用一个低维稠密的向量空间表示,并 能够保持原有网络的结构关系特征。
8.目前,基于hin表示学习的研究成果较为丰富,有关ahn表 示学习的成果较少,具体有:基于矩阵分解的ahn融合模型,通过 构造基因
‑
疾病属性异构网络,并将网络的多个邻接矩阵和属性矩阵 分解为低秩矩阵,以进行疾病关联预测;利用ahn对暗网论坛用户 及关系进行建模,并使用player2vec方法高效学习ahn的节点表示, 以识别论坛关键参与者;vendor2vec方法,基于元路径的随机游走并 结合深度神经网络(dnn)学习ahn的节点表示。
9.上述研究将ahn中的节点表示为低维连续空间中的点向量, 但由于节点属性复杂
多样,这些属性可能相互冲突甚至相互矛盾,使 得节点表示具有不确定性。例如:在专利交易ahn中,组织o分别 在技术领域t1和t2转让专利p1和p2,当t1、t2属于不同的技术 领域或p1、p2具有不同的属性时,将它们分别引入组织o的表示时 会产生不同的效果。通过将每个节点嵌入为高斯分布(gaussiandistribution),为本发明解决专利交易ahn中节点表示不确定性问题 提供了思路,即每个节点在低维潜在空间中由一个高斯分布表示,其 中,高斯分布中的均值反映节点的位置,方差反映节点的不确定性。 此外,专利交易ahn中不同类型节点间的距离还存在非对称性问 题,例如,当提到某组织时,它涉及的技术领域自然会被提及,但当 提到某技术领域时,会想到该领域的领先企业,而非该组织,即组织 与技术领域的距离不等于技术领域与组织之间的距离。已有研究多采 用点积、余弦距离或欧氏距离等方法衡量节点间距离,但难以准确衡 量具有非对称性的节点间距离。采用kl散度(kullback
‑
leiblerdivergence)衡量不同高斯分布间的差异,可以解决节点间非对称性 问题。
10.综上,专利交易推荐方法面临的主要问题包括:如何在异构信 息网络中融合属性信息,而不增加拓扑结构复杂性;如何实现属性异 构信息网络的表示学习,以解决节点嵌入不确定性问题和不同类型节 点之间的非对称问题;如何在解决上述问题的基础上提升推荐结果的 精度。
技术实现要素:
11.1、本发明需要且能够解决的技术问题。
12.本发明提出的基于属性异构信息网络表示学习的专利交易推荐 方法,在一定程度上能解决如下问题:第一,在异构信息网络中融合 属性信息,并开展交易推荐,提升推荐结果的准确性;第二,不将属 性转化为节点并映射新的关系,可以降低网络拓扑结构的复杂性;第 三,利用多维高斯分布对网络中节点进行表示学习以解决节点嵌入中 的不确定性问题,利用kl散度测度不同类型节点间的距离,以解决 不同类型节点之间距离的非对称性问题。
13.2、本发明具体的技术方案:
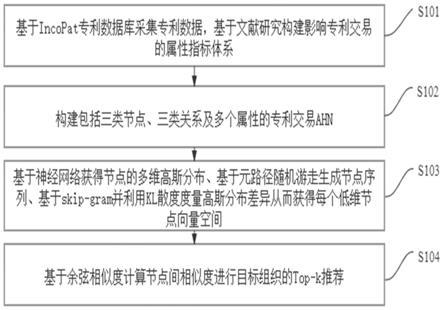
14.为达到上述目的,本发明提出了一种基于属性异构信息网络表示 学习的专利交易推荐方法,主要包括以下步骤:(1)属性体系构建: 基于incopat专利数据库采集专利数据,基于文献研究构建影响专利 交易的属性指标体系;(2)专利交易ahn构建:构建包括三类节点、 三类关系及多个属性的专利交易ahn;(3)专利交易ahn的表示 学习:包括基于神经网络获得节点的多维高斯分布、基于元路径随机 游走生成节点序列、基于skip
‑
gram并利用kl散度度量不同节点高 斯分布间的差异,获得每个节点的低维向量空间;(4)目标组织的 top
‑
k推荐:基于余弦相似度计算节点间相似度进行目标组织的top
‑
k 推荐。
15.本发明实施的基于属性异构信息网络表示学习的专利交易推荐 方法,考虑多类型节点的属性,丰富了组织、专利的向量表示,提高 推荐结果的可解释性;利用多维高斯分布及kl散度解决嵌入中的不 确定性问题及不同类型节点间距离的不对称性问题,能够实现专利交 易的精准推荐。
16.3、本发明所能达到的效果:
17.第一,本发明基于文献梳理,将组织及专利属性融入专利交易 ahn中,与传统方法
metapath2vec、tadw相比,推荐精度大幅提 高,说明组织及专利属性对交易具有重要影响,弥补了传统基于hin 的专利交易推荐中属性融合不足、计算复杂度高及计算精度低等局限。
18.第二,通过准确率指标评价发现,本发明的5个准确性指标值均 在86%以上,且高于其他对比的4个方法。说明在专利交易ahn的 表示学习中,考虑属性嵌入的不确定性和节点距离的非对称性能提高 推荐精度。
19.第三,通过非准确率指标评价发现,本发明的推荐结果更具有多 样性,且在推荐小众冷门专利上具有优势。
附图说明:
20.图1为根据本发明实施例的基于属性异构信息网络表示学习的 专利交易推荐方法流程图;
21.图2为根据本发明实施例的构建专利交易属性异构信息网络模 式;
22.图3为本发明实施例的专利交易ahn表示学习示例图;
23.图4为根据本发明实施例的步骤s102中神经网络处理节点属性 的示意图。
具体实施方式:
24.下面参照附图描述根据本发明实施例提出的基于属性异构信息 网络表示学习的专利交易推荐方法。图1是本发明一个实施例的专利 交易推荐方法流程图,包括以下步骤:
25.在步骤s101中,基于专利数据库获取专利和组织信息,首先基 于incopat专利数据库检索2003
‑
2019年某大湾区的有效发明授权专 利,由于incopat的专利转让记录中没有转让方和受让方的具体城市 信息,因此限制“转让或受让人所属区域为湾区城市”,通过转让专 利的申请人地址、受让人地址、当前专利权人地址进行模糊匹配检索。 获得初步信息为:转让专利48640项,未转让71272项。数据处理过 程如下:
26.(1)针对一条转让记录中存在多个转让或受让组织的记录,按 照将o1→
o2o3结构拆分为o1→
o2和o1→
o3;将o1o2→
o3结构拆分为o1→
o3和o2→
o3的规则拆分(其中:o1,o2,o3代表专利转受让组织,
→
代表转 让方向),数据拆分后提取组织列表,删除转、受让方为个人的记录。
27.(2)利用javascript连接百度地图api和谷歌地图api,进行组 织所属城市的模糊查询。在此基础上,删除转让方和受让方均不在湾 区城市的转让记录,最后,得到转让专利32304项。
28.(3)去掉当前专利权为个人的3553项,去掉字段缺失记录35061 项,得到未转让专利32658项。统计数据集共64962项(转让:32304 项,未转让:32658项)。
29.基于文献梳理构建影响专利交易的专利及组织属性指标体系,如 表1。
30.表1属性指标体系
36.此外,新颖性的计算方法通过专利摘要相似度表征,公式如下:
[0037][0038]
pm表示数据库中申请时间在专利p之前,与p相似度大于等于 相似水平α的专利数量,α=0.2。
[0039]
针对上述数据集,计算属性指标,并标注分类标签,发生转让标 注为1,未发生转让标注为0;对连续型指标进行归一化。
[0040]
在步骤s102中,构建专利交易ahn,给出如下定义:
[0041]
定义1(属性异构网络,ahn),给定ahn,g={v,e,a},其中 v表示节点集合,|v|为节点数量,e是网络中边的集合,a是节点的 属性矩阵。e仅存在于节点之间,即表示节点v
i
的属性 向量,
[0042]
本发明构建的专利交易ahn中,节点集合表示为 v={v1,v2,...,v
o
,v
o+1
,...,v
p
,v
p+1
,...,v
t
},映射为节点类型集合为 v
type
={o,p,t},o表示组织、p表示专利、t表示ipc。|o|表示组织节 点的数量。e={e1,e2,e3}为关系类型集合,e1表示组织转出专利、e2表 示组织转入专利、e3表示专利与ipc的隶属关系。ao表示组织属性 集合、ap表示专利属性集合,图2为专利交易ahn的网络模式。假 设ao={ao1,ao2},ap={ap1,ap2},对于每个节点v
i
∈v,其属性向量可 以表示为则属性矩阵可以表示为 [0043]
定义2(元路径meta path),是网络模式t
g
={v,e}上的路径,定 义为:在不同类型节点之间的一系列关系序列组成的路径。例如: 表示o到t之间的复合关系
[0044]
定义3(ahn表示学习)给定ahn,g={v,e,a},a∈r
m
×
n
为属 性矩阵,其中m为节点数,m=|v|,n为属性数,目标是学习映射函 数f:v
→
r
d
,将g中每个节点映射为d维向量,且d<<m,n,本发明 d取值为200。
[0045]
图3为专利交易ahn表示学习的示例。图中左侧为专利交易 ahn,包括网络的拓扑结构以及节点的属性信息,右侧为该网络节 点在低维空间的表示。在拓扑结构上有直接连接即存在显式关系的节 点在低维空间中有相似表示,如节点对(p1,t1);节点对(p2,p3)不存在 显式关系,但它们均与节点o3相连,即存在隐式关系,因此它们在 低维空间接近;节点对(o2,o4)不直接相连,但因其属性相似故在低维 空间中接近。
[0046]
在步骤s103中,专利交易ahn的表示学习过程包括:基于神 经网络得到节点的多维高斯分布;基于元路径随机游走遍历ahn生 成节点序列;基于skip
‑
gram并利用kl散度衡量不同节点高斯分布 间的差异,从而获得每个节点的低维向量空间。具体如下:
[0047]
(1)首先,将专利属性矩阵输入神经网络,通过第一层神经网 络处理节点属性并
输出中间隐藏表示;然后,经过第二层神经网络输 出得到节点的均值和协方差矩阵。公式如下:
[0048][0049]
其中,是节点v
i
的属性向量,为第一层输出的中间隐藏表示, w和b分别为该层的权重矩阵与偏置向量,和分别表示输出得 到的节点v
i
的均值和协方差矩阵,w
μ
和b
μ
分别表示均值的权重矩阵和 偏执向量,w
∑
和b
∑
分别为协方差矩阵的权重矩阵与偏置向量,relu 和elu是两个激活函数。
[0050]
(2)本发明采用为元路径进行随机游走,其含 义为某组织转出的专利与另一组织转入的专利同属一个技术领域时, 组织间更易发生交易。给定专利交易ahn和元路径,在随机游走的 第k+1步的转移概率为:
[0051][0052]
公式含义为已知第k步游走到节点v
i
,且已知预定义的元路径 path。首先获取节点v
i
的类型,如果节点v
i
是p类型,那么根据上述 元路径中不同类型节点间的关系路径,v
i
的邻居节点的类型应为o类 型或t类型,同理,如果节点v
i
是o类型,那么其邻居节点的类型应 为p类型。那么第k+1步游走到节点v
j
需要满足两个条件:节点v
i
、 v
j
之间存在连接,即(v
i
,v
j
)∈e,且节点v
j
的类型为节点v
i
的邻居节点 类型t类型,即φ(v
j
)=t,t为v
i
在元路径中所有邻居节点对应的类型。 此时第k+1步游走到节点v
j
的概率为:n
t
(v
i
)表示节点v
i
的邻 居中类型为t的邻居节点集。当节点v
i
、v
j
之间存在连接,即(v
i
,v
j
)∈e, 但v
j
不属于节点v
i
的邻居节点类型t类型,即φ(v
j
)≠t,转移概率为0。 当节点v
i
、v
j
之间不存在连接,即其转移概率也为0。
[0053]
本发明实施例中,每个节点随机游走50次,行走长度为10步, 最终得到节点序列(本发明取得随机游走次数和步长的数值能够保证 覆盖网络中的每个节点,如果网络规模变化,取值也应该有所改变)。
[0054]
(3)采用skip
‑
gram模型对专利交易ahn网络进行训练, skip
‑
gram是主流的神经网络语言模型,核心思想是使用当前单词预 测其周围的单词,在网络中,即使用当前节点预测其周围邻居节点, 节点看作单词,节点序列相当于句子。具体步骤如下:
[0055]
skip
‑
gram模型基于中心节点嵌入最大化观察邻域节点的概率, 目标函数即
[0056][0057]
其中,v
type
表示节点的类型集合,n
t
(v
i
)表示节点v
i
的邻居中类型 为t的邻居节点集,是一个映射函数,将节点映射成向量,含义为在随机游走中,当给定
一个节点v
i
时,在它的窗 口范围内出现t类型节点的概率。基于条件独立性假设,将上式中的 条件概率近似如下:
[0058][0059]
其中,v
j
∈n
t
(v
i
)表示节点v
j
属于节点v
i
的t类型邻居。
[0060]
采用softmax函数针对节点v
j
的节点类型进行规范化。给定v
i
后, 邻居v
j
出现的概率为:
[0061][0062]
其中,函数exp(x)表示自然对数e的x次方,和分别表示中 心节点和其邻居的嵌入,表示网络中任意节点的嵌入,即即是二者的点积,可以看作它们之间的相 似性度量。然而,点积只考虑均值而不考虑协方差的合并。考虑到不 同类型节点之间的“距离”可能不对称,因此,使用kullback
‑
leibler (kl)散度将协方差矩阵合并到模型中。kl散度又被称为相对熵 (relative entropy)或信息散度(information divergence),是两个概率 分布(probability distribution)间差异的非对称性度量。公式如下:
[0063][0064]
其中,和分别表示两个节点的多维高斯分布,表 示两个分布的kl散度,值越小,表明两个分布越相似。和分 别表示两个分布的均值,和分别表示两个协方差矩阵的行列 式,r表示向量,l表示嵌入的维度,和tr(
·
)分别表示 协方差矩阵的逆和迹。通过这种方式,公式(7)可以重新写为:
[0065][0066]
但上述方法由于存在求和项,效率较低。为提高计算速度,利用 负采样重新定义损失函数,和词嵌入类似,在对每一个中心节点的训 练中,不需要对所有节点进行softmax计算,而是通过对节点进行随 机采样,因此,每次训练的时候,在选择一个正样本的同时,随机生 成k个负样本,共训练k+1个样本。相对于hierarchical softmax模 型来说,可以大幅提高性能。优化目标变化后,不宜再使用softmax, 因此利用sigmoid函数归一化。损失函数计算如式(10):
[0067]
[0068]
其中,σ是sigmoid函数,即表示为节点v
j
的 嵌入,节点v
j
属于节点v
i
的t类型邻居,即v
j
∈n
t
(v
i
)。负样本表示不 包含在n
t
(v
i
)中的节点,表示负样本节点v
k
的嵌入,v
k
的类型和v
j
相 同。p
neg
(v)表示中心节点的噪声分布,在e限制的情况下服从具有 指定均值和偏差的正态分布,初始的均值和偏差随机生成,负样本节 点v
k
是从分布中取得的向量,即v
k
~p
neg
(v),k为从p
neg
(v)中收集的负 样本总数量。具体而言,首先初始化节点向量,分别对正负样本中的 每一个节点初始化一个低维向量作为该节点的向量表示,然后利用梯 度下降法最小化损失函数,其本质为最大化不断更新节点的向量,直到收敛或训练阶段结束。首先,在5
‑
100之 间,随机设定skip
‑
gram模型中的epoch参数值大小,若训练次数小 于epoch值,且损失函数已经达到收敛条件,则提前结束训练,否则 直到达到训练次数,即epoch参数值时结束训练。
[0069]
在步骤s104中,基于余弦相似度计算节点相似度,对相似度值 进行top
‑
k排序,得到top
‑
k个专利作为目标组织的推荐结果。
[0070]
通过表示学习训练完成后提取出组织及专利的表示向量,如华为 技术有限公司:[
‑
0.2869007,
‑
0.45726693,0.08010134,0.96499217, 0.65272784,
…
],专利cn101813636b:[0.6562854,0.77058595, 0.910496,0.02038962,
…
]。每个向量长度为200,采用余弦相似度 衡量两个节点间相似程度,如果两个向量的余弦相似度越大,那么它 们越相似。计算组织o
i
和专利p
j
间余弦相似度如式(11):
[0071][0072]
其中l为向量长度,分别代表组织o
i
和专利p
j
的向量, 对计算出的余弦值进行降序排列,得到top
‑
k专利交易推荐结果。
[0073]
本发明采用7个指标来评价推荐算法的性能,包括五个准确率指 标(accuracy、precision、recall、f1和auc)和两个非准确率指标 (intrasim和popularity)。
[0074]
(1)accuracy:对于给定的测试集,推荐模型正确推荐的样本 数与全部样本数之比:
[0075][0076]
(2)precision:表示发生过的交易记录占推荐结果的比例:
[0077][0078]
(3)recall:表示被推荐出的交易记录占实际交易的比例:
[0079]
[0080]
(4)f1:precision和recall的调和平均值:
[0081][0082]
其中,nr表示正确推荐的数目,ns表示全部样本数,nr
tran
表示 交易的专利中被正确推荐的数目,nm
tran
表示推荐可能发生交易的数 目,na
tran
表示实际发生过交易的数目。
[0083]
(5)auc:使用roc曲线下面积(area under roc curve,auc) 来评测推荐系统性能。具体计算时为降低计算复杂度,采用公式如下:
[0084][0085]
组织和专利存在交易关系的作为正样本集合,其余为负样本集合。 其中,pos表示正样本集合,rank
pos
表示正样本pos在正样本集合中 的排序值,∑
pos∈pos
rank
pos
为所有正样本的rank值之和,n
p
表示正样 本数量,n
n
负样本数量。auc值越接近1,说明效果越好。
[0086]
(6)intrasim:该指标源于电商中用户
‑
商品推荐,衡量推荐结 果的多样性,本发明将其引入专利交易推荐中。对于组织o∈o的专利 推荐列表,如果专利间相似度越大,说明推荐给组织的专利比较单一, 推荐算法难以推荐新的专利;反之,如果该值越小,则表明推荐的专 利越丰富,推荐多样性越高:
[0087][0088]
其中,o表示所有组织集合,|o|表示所有组织数量,表示组织 o
i
的前c个专利推荐结果集合,p
i
、p
j
表示两个专利,其余弦相似度 为(计算公式参照式(11))。
[0089]
(7)popularity:该指标也源于用户
‑
商品推荐,旨在衡量推荐算 法产生新颖(不太流行)和意外结果的能力。本发明将其引入专利交 易推荐评价中,用来评价推荐结果的热门程度。若其值越高,说明推 荐算法倾向于推荐交易“热度”较高的专利,属于热门推荐;反之, 则越倾向于为组织推荐“热度”较低但又符合组织偏好的小众或冷门 专利。
[0090][0091]
其中,o表示所有组织集合,|o|表示所有组织数量,表示组织 o
i
的前c个专利推荐结果集合,表示专利p
i
的交易次数,代表该专 利的热度。
[0092]
本发明选取不同的基线方法进行性能对比:
①
metapath2vec:仅 利用网络结构信息,基于元路径随机游走得到节点序列,不考虑属性;
ꢀ②
tadw:基于ahn矩阵分解的表示学习方法;
③
ahnvec
‑
ptr: 为本发明的变体方法,将网络节点表示为点向量而非潜在空间的高斯 分布;
④
ahnsy
‑
ptr:为本发明的变体方法,采用对称的内积衡量 节点距离而非kl散度。对比结果如表2。
[0093]
表2推荐方法对比
[0094][0095]
表2中,通过准确率指标评价发现,本发明ahnrl
‑
ptr的5个准 确性指标值均在86%以上,且4个指标均高于其他4个方法。另外 ahnrl
‑
ptr的intrasim和popularity指标值小于metapath2vec、 ahnvec
‑
ptr和ahnsy
‑
ptr方法,说明该发明的推荐结果更具有多 样性且在推荐小众冷门专利上具有优势。同时,也说明在专利交易 ahn的表示学习中,考虑属性嵌入的不确定性和节点距离的非对称 性能提高推荐精度。基于该模型,计算非准确性指标如下表所示。
[0096]
表3本发明性能(非准确率指标)
[0097][0098]
表3中,通过改变推荐列表长度发现,intrasim指标值在2左右, 说明推荐给组织的专利比较丰富,但随着推荐列表长度增加,出现小 幅增长趋势,说明推荐的专利越多,多样性下降。随着推荐列表长度 增加,popularity指标值大幅降低,表明推荐专利越多,本发明越倾 向于推荐不太活跃的专利或冷门专利,可见本发明在挖掘用户潜在专 利技术交易兴趣方面具有优势。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1