基于Pipeline处理和ES储存问答系统构建方法与流程
基于pipeline处理和es储存问答系统构建方法
技术领域
1.本发明涉及自然语言处理,具体涉及基于pipeline处理和es储存问答系统构建方法。
背景技术:
2.问答系统是自然语言处理领域中一项比较复杂和困难的任务,该任务就是给定一个问题,系统能够给出合理准确的答案。按照目前国内外研究进展,依据答案来源划分,可以把问答系统划分为基于结构化的问答系统、基于文本的问答系统、基于faq问答对的问答系统。
3.基于结构化的问答系统,就是将问题带入提前准备好的结构化知识库寻求答案,它能够解析输入的自然语言问句,并将解析结果转化为对应的sparql查询语句来获取答案。这样的问答系统,回答问题准确,逻辑性强,但是构造系统的难度特别大,需要构建一个高质量的知识图谱。而经常能获取到的数据都是非结构化的,要想从非结构化数据中提取出结构化数据,这显然是一个巨大的工程,需要高额的成本。
4.基于文本的问答系统中给定问题,能够从答案集中检索出对应答案,需要对问题的语义理解非常准确,同时抽取的答案也要准确合理,然而目前是不太容易做到的。
5.基于faq问答对的问答系统预先将问题和答案进行匹配,构建了一个常见问答对库,进行问题检索时只需要判定问题和库内候选问题是否相似就可以。
6.常见的faq问答系统在构建问答对库时,仅仅只是维护了问答对,没有维护其他的特征,推荐的准确性就很依赖问题和库内候选问题相似判定的准确度。目前,问题和库内候选问题的相似判定大多采用bert模型进行语义表征来计算余弦相似度,需要大量标注相似语句,并且针对一些实例采用bert模型进行语义表征来计算余弦相似度并不能准确判定语句是否相似,对于这些难题并不能很好地解决,这样构建的问答系统就不是那么高效和可控了,后续的优化也无法很好地持续进行下去。
技术实现要素:
7.(一)解决的技术问题
8.针对现有技术所存在的上述缺点,本发明提供了基于pipeline处理和es储存问答系统构建方法,能够有效克服现有技术所存在的缺乏对问答对库的全面维护、对输入问题与库内候选问题的相似判定不够准确的缺陷。
9.(二)技术方案
10.为实现以上目的,本发明通过以下技术方案予以实现:
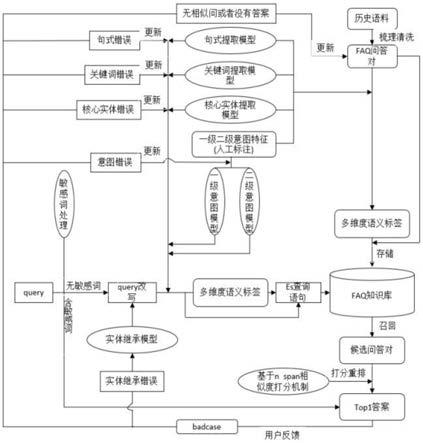
11.基于pipeline处理和es储存问答系统构建方法,包括以下步骤:
12.s1、对行业领域数据问答对进行收集清洗,并针对问答对中的问题构建多维度语义特征标签;
13.s2、将问答对中的问题及与其对应匹配的多维度语义特征标签、答案批量存入es
数据库;
14.s3、判断输入问题语句中是否包含敏感词,若包含敏感词则直接给出答案,否则对输入问题语句进行改写;
15.s4、对改写后的问题语句进行多维度语义特征标签抽取,并将改写后的问题语句与得到的多维度语义特征标签转化为查询语句,在es数据库中经过查询和搜索,召回候选问答对;
16.s5、对改写后的问题语句与候选问答对中的问题进行相似度打分重排,推荐最优答案。
17.优选地,s1中对行业领域数据问答对进行收集清洗,包括:
18.收集行业领域数据问答对,对问答对进行噪声清洗和质量审查,形成原始模板数据,并对原始模板数据进行扩充。
19.优选地,所述对原始模板数据进行扩充,包括:
20.将行业领域内历史对话语料逐条存入es数据库中进行检索,设定检索结果的得分阈值,选取与原始模板数据相似的行业领域内历史对话语料,进行噪声清洗和质量审查后直接扩充至对应原始模板数据中。
21.优选地,所述多维度语义特征标签包括句式特征、核心实体特征、关键词特征和一级意图特征、二级意图特征。
22.优选地,所述核心实体特征的构建方法包括:
23.对问题语句进行句法分析,得出问题语句的句法组成成分以及分词单位的词性,根据每个分词单位的词性、句法关系类型数目以及句法关系类型的权重进行累计打分,提取分值最高的分词单位作为核心实体。
24.优选地,所述关键词特征的构建方法包括:
25.人工收集问题语句中特征明显的词汇,针对每个具体业务场景梳理出关键词列表;
26.采用字典树存储关键词列表中的关键词,并将关键词分为must强匹配类型和should弱匹配类型,当问题语句中具有相同must强匹配类型的关键词才会被召回,而should弱匹配类型的关键词用于调节被召回的可能性大小;
27.输入问题语句后,以字符为单位在字典树上进行强匹配,匹配到一个完整路径就可以视为关键词。
28.优选地,s3中对输入问题语句进行改写,包括:
29.基于相似词列表将输入问题语句替换成同一表达方式,并进行噪声清洗;
30.对噪声清洗后的问题文本进行标注,对判断是否需要继承上一轮核心实体的实体继承模型进行训练;
31.当实体继承模型检测到继承核心实体意图时,将上一轮的核心实体直接拼接在当前问题语句的句尾。
32.优选地,s4中对改写后的问题语句进行多维度语义特征标签抽取,包括:
33.采用pipeline方式对改写后的问题语句进行多维度语义特征标签抽取,在第一节点中分别通过句式提取模型、核心实体提取模型、关键词提取模型、一级意图模型对句式特征、核心实体特征、关键词特征、一级意图特征进行提取;在第二节点中通过二级意图模型
提取二级意图特征。
34.优选地,s5中对改写后的问题语句与候选问答对中的问题进行相似度打分重排,推荐最优答案,包括:
35.基于停用词列表去掉没有实际意义的停用词,提取改写后的问题语句、候选问答对中的问题中的n_span单位集合,计算改写后的问题语句与候选问答对中的问题的相似度得分,按照相似度得分对候选问答对进行排序,并将大于相似度阈值的相似度得分最高的候选问答对中的答案作为最优答案进行推荐。
36.优选地,还包括在系统线上部署后,根据用户使用后的不合理反馈,分析不合理原因,并对系统进行更新优化。
37.(三)有益效果
38.与现有技术相比,本发明所提供的基于pipeline处理和es储存问答系统构建方法,具有以下有益效果:
39.1)通过梳理行业领域内历史对话语料,构建faq问答对,提取包含句式特征、核心实体特征、关键词特征和一级意图特征、二级意图特征的多维度语义特征标签,能够快速构建知识库;
40.2)在答案召回阶段通过对输入问题语句的句式特征、核心实体特征、关键词特征、一级意图特征和二级意图特征的提取,以及对是否需要继承上一轮核心实体的准确判断,保证了答案召回结果更加合理;
41.3)在最优答案推荐阶段,通过基于n_span的相似性度量方法,不需要模型训练,能够快速对答案召回结果进行打分,保证了答案匹配的精准性;
42.4)同时该方法保证了系统优化和迭代的速度,对于用户的不合理反馈,只需要通过调整对应模型或者新增知识库中的问答对就能解决,保证了问答系统的可控性。
附图说明
43.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
44.图1为本发明的流程示意图;
45.图2为本发明中核心实体特征构建方法的示例图。
具体实施方式
46.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
47.基于pipeline处理和es储存问答系统构建方法,如图1所示,s1、对行业领域数据问答对进行收集清洗,并针对问答对中的问题构建多维度语义特征标签。
48.其中,对行业领域数据问答对进行收集清洗,包括:
49.收集行业领域数据问答对,对问答对进行噪声清洗和质量审查(主要对问答对中的错别字进行更正,以及对问题与答案之间进行准确匹配,保证原始模板数据的准确性),形成原始模板数据,并对原始模板数据进行扩充。
50.其中,对原始模板数据进行扩充,包括:
51.将行业领域内历史对话语料逐条存入es数据库中进行检索,设定检索结果的得分阈值,选取与原始模板数据相似的行业领域内历史对话语料,进行噪声清洗和质量审查后直接扩充至对应原始模板数据中。
52.本技术技术方案中,多维度语义特征标签包括句式特征、核心实体特征、关键词特征和一级意图特征、二级意图特征。
53.句式主要涉及:what/where/when/how/why/if/which/long/其他。为了答案召回时,从知识库中检索的问题更加精准,可以使用该特征进行判定,使用强逻辑关系。句子的句式一般使用正则表达式就可以得到很高的准确率,举例如下:
54.新生儿低血糖是什么/什么是优质母乳/用什么储存母乳最合适——what——是什么/什么是/什么
[0055]0‑
6月宝宝抵抗力不好体现在哪里/罐装的奶粉生产日期印在什么地方的?——where——哪里/什么地方(地点地址)
[0056]
百白破接种月龄在什么时候?/转奶的最佳时间——when——什么时候/时间(时机/周几/几号)
[0057]
怎么测量宝宝身高体重是否标准?/如何刺激婴儿听力发育?/新生儿宝宝不爱喝奶瓶怎么办——how——怎么/如何/怎么办
[0058]
宝宝睡觉为什么总出汗/母乳性腹泻的原因/3段奶粉为何这么潮湿/——why——为什么/原因/为何
[0059]
早产宝宝需要喝早产奶粉吗?/奶粉中是否添加转基因原料?——if——吗?/是否
[0060]
母乳多久喂养合适?/甲肝疫苗有效期——long——多久/有效期
[0061]
美素和港版的区别/宝宝多大会翻身/宝宝大便干燥/奶粉发现异物/奶粉比较黄/6个月宝宝的奶量——其他。
[0062]
核心实体特征的构建方法包括:
[0063]
对问题语句进行句法分析,得出问题语句的句法组成成分以及分词单位的词性,根据每个分词单位的词性、句法关系类型数目以及句法关系类型的权重进行累计打分,提取分值最高的分词单位作为核心实体。
[0064]
具体算法如下:
[0065]
如图2所示,采用ddparser对问题语句进行分词和句法依存分析,得到分词结果:['我','不','明白','座位险','是','做','什么','的']
[0066]
'partspeech':['r','d','nr','n','v','v','r','uj']
[0067]
'relations':{1:['sbv'],2:['adv'],3:['sbv','adv','hed','vob'],4:['sbv'],5:['sbv','vob','vob'],6:['att','vob'],7:['vob'],8:['att','vob']}
[0068]
根据每个分词单位的词性、句法关系类型数目以及句法关系类型的权重进行累计打分,具有hed关系的那个分词单位如果不是名词则score为0,其他情形的评分规则如下:
[0069]
对每个分词单位具有句法关系类型的权重求和:
[0070][0071]
其中,relationsweights
j
表示第j个分词单位具有的关系类型权重的集合,每个关系的权重值是提前设定的;
[0072]
上一步score
j
乘以该分词单位具有的关系类型数目权重:
[0073][0074]
其中,r表示所有关系类型的数目,r
j
表示第j个分词单位具有的关系类型数目;
[0075]
上一步score
j’乘以分词单位的词性权重:
[0076]
score
j”=score
j
'*p
j
[0077]
其中,p
j
表示j个分词单位具有的词性权重,词性权重是提前设定的,可以根据业务修改。
[0078]
此外,对于句子成分不全,提取不到核心实体的问题语句,需要其他方法进行补充。
[0079]
关键词特征的构建方法包括:
[0080]
人工收集问题语句中特征明显的词汇,针对每个具体业务场景梳理出关键词列表;
[0081]
采用字典树存储关键词列表中的关键词,并将关键词分为must强匹配类型和should弱匹配类型,当问题语句中具有相同must强匹配类型的关键词才会被召回,而should弱匹配类型的关键词用于调节被召回的可能性大小;
[0082]
输入问题语句后,以字符为单位在字典树上进行强匹配,匹配到一个完整路径就可以视为关键词。
[0083]
具体示例如下:
[0084]
漆 must强匹配类型
‑
漆
[0085]
机场停车 must强匹配类型
‑
机场停车
[0086]
道路救援 must强匹配类型
‑
道路救援
[0087]
便宜 should弱匹配类型(价格相关)
‑
议价
[0088]
多少钱 should弱匹配类型(价格相关)
‑
议价
[0089]
费用 should弱匹配类型(价格相关)
‑
议价
[0090]
道路救援、机场停车、漆这些关键词在它们所在的语境下都是能充分体现本质区别,具有很明显的区分性;费用、多少钱、便宜它们所在的语境下就不是本质特征了,但是它们能在相似度体现上体现作用。
[0091]
根据现有的问题语句数据,进行业务梳理,标注出一级、二级意图,其中一级意图之间最好界限比较明显,每一个一级意图有相应的二级意图。当达到一定数据量后,就可以训练相应的意图分类模型,作为意图提取器在答案召回阶段进行意图提取。具体示例如下:
[0092]
一级意图:信息咨询、询价、赠品
[0093]
二级意图:
[0094]
信息咨询——保险标志、过户、产品信息、退保
[0095]
询价——报价、比价、砍价
[0096]
赠品——索要、置换、操作、过期、何时到达。
[0097]
s2、将问答对中的问题及与其对应匹配的多维度语义特征标签、答案批量存入es数据库。
[0098]
在完成多维度语义特征标签的抽取后,每个问题具有与之匹配的多个标签——句式特征标签、核心实体特征标签、关键词特征标签和一级意图特征标签、二级意图特征标签,还有对应匹配的答案。把问题之外的所有字段都设置为keyword类型,问题设置为text类型,然后批量写入es数据库。
[0099]
s3、判断输入问题语句中是否包含敏感词,若包含敏感词则直接给出答案,否则对输入问题语句进行改写。
[0100]
其中,对输入问题语句进行改写,包括:
[0101]
基于相似词列表将输入问题语句替换成同一表达方式,并进行噪声清洗(例如句末的标点符号以及句中微信表情包转成的特殊文本等);
[0102]
对噪声清洗后的问题文本进行标注,对判断是否需要继承上一轮核心实体的实体继承模型进行训练;
[0103]
当实体继承模型检测到继承核心实体意图时,将上一轮的核心实体直接拼接在当前问题语句的句尾。
[0104]
s4、对改写后的问题语句进行多维度语义特征标签抽取,并将改写后的问题语句与得到的多维度语义特征标签转化为查询语句,在es数据库中经过查询和搜索,召回候选问答对。
[0105]
其中,对改写后的问题语句进行多维度语义特征标签抽取,包括:
[0106]
采用pipeline方式对改写后的问题语句进行多维度语义特征标签抽取,在第一节点中分别通过句式提取模型、核心实体提取模型、关键词提取模型、一级意图模型对句式特征、核心实体特征、关键词特征、一级意图特征进行提取;在第二节点中通过二级意图模型提取二级意图特征。
[0107]
s5、对改写后的问题语句与候选问答对中的问题进行相似度打分重排,推荐最优答案,具体包括:
[0108]
基于停用词列表去掉没有实际意义的停用词,提取改写后的问题语句、候选问答对中的问题中的n_span单位集合,计算改写后的问题语句与候选问答对中的问题的相似度得分,按照相似度得分对候选问答对进行排序,并将大于相似度阈值的相似度得分最高的候选问答对中的答案作为最优答案进行推荐。
[0109]
具体示例如下:
[0110]
对改写后的问题语句“安检怎么搞”提取3_span单位集合:
[0111]
[
‘
安’,
‘
检’,
‘
怎’,
‘
么’,
‘
搞’,
‘
安检’,
‘
检怎’,
‘
怎么’,
‘
么搞’,
‘
安检怎’,
‘
检怎么’,
‘
怎么搞’];
[0112]
计算改写后的问题语句与候选问答对中的问题的相似度得分:
[0113][0114]
其中,s
q
为改写后的问题语句的3_span单位集合,s
c
为候选问答对中的问题中的3_
span单位集合;
[0115]
按照相似度得分对候选问答对进行排序,并将大于相似度阈值的相似度得分最高的候选问答对中的答案作为最优答案(top1答案)进行推荐。
[0116]
本技术技术方案中,还包括在系统线上部署后,根据用户使用后的不合理反馈(图中为badcase),分析不合理原因,并对系统进行更新优化。
[0117]
若知识库中缺乏对应匹配答案时,对知识库中的问答对进行更新。
[0118]
若对改写后的问题语句进行关键词特征抽取错误,则调整更新关键词列表;若对改写后的问题语句进行一级意图特征、二级意图特征抽取错误,则更新一级意图模型、二级意图模型的训练集,并进行模型训练。
[0119]
若在对输入问题语句进行改写过程中,对是否需要继承上一轮核心实体判断错误,则更新实体继承模型的训练集,并进行模型训练。
[0120]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不会使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1