网页数据获取方法、装置、电子设备及存储介质与流程
1.本发明实施例涉及互联网技术领域,尤其涉及一种网页数据获取方法、装置、电子设备及存储介质。
背景技术:
2.随着网络技术的迅速发展,互联网已经成为大量信息的重要载体,为了有效获取这些信息资源,爬虫技术应运而生。利用网络爬虫虽然可以爬取网站数据,却会消耗目标系统资源,因此,很多网站都设置了反爬机制来阻止爬虫批量获取网站信息。
3.现有技术中,爬取网站数据的方式通常包括以下两种。第一种方式为,利用预先编写的脚本爬取网站数据,然而,对于设置了反爬机制的网站来说,用户需要在爬取数据前花费大量精力去了解该网站的cookie和相关校验机制,同时,这种非人类操作的数据读取方式很容易被网站检测出来。第二种方式为,利用无头浏览器模拟用户真实浏览器的操作环境,再运行数据爬取脚本,对于这种方式,网站依然可以通过前端javascript校验出无头浏览器,进而检测出爬虫脚本。
4.因此,相关技术提供的方案中,用户利用脚本爬取网站数据时需要花费较多的精力,脚本很容易被检测出来,存在被网站封禁的风险。
技术实现要素:
5.本发明提供一种网页数据获取方法、装置、电子设备及存储介质,使用户可以控制浏览器行为,并为爬虫脚本的运行创造了真实用户的浏览器环境,保证了数据爬取的成功率。
6.第一方面,本发明实施例提供了一种网页数据获取方法,应用于浏览器中的插件,该方法包括:
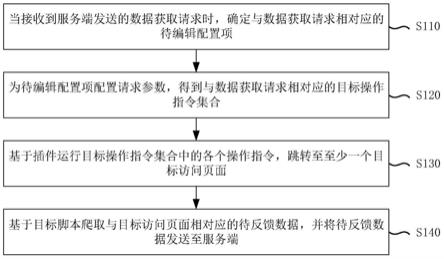
7.当接收到服务端发送的数据获取请求时,确定与所述数据获取请求相对应的待编辑配置项;
8.为所述待编辑配置项配置请求参数,得到与所述数据获取请求相对应的目标操作指令集合;其中,所述请求参数为所述数据获取请求中所携带的参数;
9.基于所述插件运行所述目标操作指令集合中的各个操作指令,跳转至至少一个目标访问页面;
10.基于目标脚本爬取与所述目标访问页面相对应的待反馈数据,并将所述待反馈数据发送至所述服务端。
11.第二方面,本发明实施例还提供了一种网页数据获取装置,该装置包括:
12.待编辑配置项确定模块,用于当接收到服务端发送的数据获取请求时,确定与所述数据获取请求相对应的待编辑配置项;
13.目标操作指令集合确定模块,用于为所述待编辑配置项配置请求参数,得到与所述数据获取请求相对应的目标操作指令集合;其中,所述请求参数为所述数据获取请求中
所携带的参数;
14.目标访问页面跳转模块,用于基于浏览器插件运行所述目标操作指令集合中的各个操作指令,跳转至至少一个目标访问页面;
15.待反馈数据爬取模块,用于基于目标脚本爬取与所述目标访问页面相对应的待反馈数据,并将所述待反馈数据发送至所述服务端。
16.第三方面,本发明实施例还提供了一种电子设备,所述电子设备包括:
17.一个或多个处理器;
18.存储装置,用于存储一个或多个程序,
19.当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如本发明实施例任一所述的网页数据获取方法。
20.第四方面,本发明实施例还提供了一种包含计算机可执行指令的存储介质,所述计算机可执行指令在由计算机处理器执行时用于执行如本发明实施例任一所述的网页数据获取方法。
21.本发明实施例的技术方案,应用于浏览器中的插件,当接收到服务端发送的数据获取请求时,确定与数据获取请求相对应的待编辑配置项;为待编辑配置项配置请求参数,得到与数据获取请求相对应的目标操作指令集合;基于插件运行目标操作指令集合中的各个操作指令,跳转至至少一个目标访问页面;基于目标脚本爬取与目标访问页面相对应的待反馈数据,并将待反馈数据发送至服务端,利用浏览器插件,为用户提供了控制浏览器行为的途径,进一步的,为爬虫脚本的运行创造了真实用户的浏览器环境,避免了直接运行脚本或基于无头浏览器运行脚本而被网站检测封禁的问题,保证了数据爬取的成功率。
附图说明
22.为了更加清楚地说明本发明示例性实施例的技术方案,下面对描述实施例中所需要用到的附图做一简单介绍。显然,所介绍的附图只是本发明所要描述的一部分实施例的附图,而不是全部的附图,对于本领域普通技术人员,在不付出创造性劳动的前提下,还可以根据这些附图得到其他的附图。
23.图1为本发明实施例一所提供的一种网页数据获取方法的流程示意图;
24.图2为本发明实施例二所提供的一种网页数据获取方法的流程示意图;
25.图3为本发明实施例二所提供的一种网页数据获取方法的流程图;
26.图4为本发明实施例三所提供的一种网页数据获取装置的结构框图;
27.图5为本发明实施例四所提供的一种电子设备的结构示意图。
具体实施方式
28.下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
29.实施例一
30.图1为本发明实施例一所提供的一种网页数据获取方法的流程示意图,本实施例可适用于利用爬虫脚本对网站数据进行爬取的情况,该方法可以由网页数据获取装置来执
行,该装置可以通过软件和/或硬件的形式实现,该硬件可以是电子设备,如移动终端、pc端或服务器等。
31.为了清楚地了解本发明实施例的技术方案,在此对本方案所使用的浏览器插件进行说明。
32.插件作为一种遵循一定规范的应用程序接口编写出来的程序,仅能够运行在程序规定的系统平台下,而不能脱离指定的平台单独运行。在实际应用过程中,很多软件都提供有插件功能,示例性的,在chrome浏览器中可以基于web技术开发或安装多种类型的插件,以此增强浏览器的功能。具体来说,在浏览器中加载的chrome插件可以是一个由超文本标记语言(hyper text markup language,html)、层叠样式表(cascading style sheets,css)、javascript以及图片等资源组成的一个.crx后缀的压缩包,进一步的,chrome插件可以配合c++编写动态链接库,从而实现一些更底层的功能,如全屏幕截图等。因此,本实施例的技术方案即是依靠浏览器中的插件来实现的。
33.如图1所示,该方法具体包括如下步骤:
34.s110、当接收到服务端发送的数据获取请求时,确定与数据获取请求相对应的待编辑配置项。
35.其中,服务端可以是向安装有浏览器(如chrome浏览器)的系统发送请求的后端服务器,即,服务端可以通过发送相应的消息控制浏览器模拟用户操作,并控制浏览器运行多种类型的应用程序或脚本。可以理解,数据获取请求即是用户根据工作任务的需要向浏览器中的插件发送的请求,例如,用户通过后端服务器发送的、基于超文本传输协议(hyper text transfer protocol,http)的请求,浏览器接收到数据获取请求后,至少可以利用预先编写并加载的插件执行相对应的操作,例如,接收到后端发送的请求后,chrome浏览器可以基于插件访问与该请求相对应的页面。
36.进一步的,由于浏览器插件是基于特定编程语言、并遵循一定规范的程序接口编写出来的,因此,在插件中还包含有多个待编辑配置项,每个待编辑配置项中的具体参数是根据数据获取请求来确定的。
37.在此继续以chrome浏览器中的插件为例进行说明。在接收到数据获取请求后,可以根据请求携带的信息确定出用户想要访问的页面的地址、浏览器访问该页面时需要等待的加载时长以及用户是否需要执行翻页操作等。对应的,根据数据获取请求中携带的上述信息,即可在基于javascript编写并加载于chrome浏览器的插件中,确定出页面地址、页面加载等待时长以及翻页操作控制指令这几项作为待编辑配置项,可以理解,在插件中确定出的待编辑配置项与数据获取请求中携带的信息一一对应。
38.s120、为待编辑配置项配置请求参数,得到与数据获取请求相对应的目标操作指令集合。
39.其中,请求参数是指数据获取请求中所携带的参数,进一步的,目标操作指令即是将请求参数赋值给插件中的待编辑配置项后所生成的至少一条操作指令,浏览器基于目标操作指令集合中的指令,即可按照用户的工作意图(数据爬取)执行多种类型的操作。
40.继续以上述示例进行说明,安装有chrome浏览器的系统提取出数据获取请求中携带的统一资源定位符(uniform resource locator,url)、页面加载等待时间以及翻页操作信息后,可以将这些信息作为请求参数,为待编辑配置项进行赋值,以此得到对应的目标操
作指令,进一步的,将这些指令进行汇聚即可得到目标操作指令集合。chrome浏览器基于集合中的指令,可以访问特定的页面,并按照用户设置的等待时长待页面加载完毕后执行翻页操作等。
41.本领域技术人员应当理解,待编辑配置项结合请求参数所生成的目标操作指令集合,至少可以反映用户的数据获取需求,也即是说,可以反映用户希望浏览器访问哪些网站,并在这些网站中执行哪些操作。
42.s130、基于插件运行所述目标操作指令集合中的各个操作指令,跳转至至少一个目标访问页面。
43.在本实施例中,接收到服务端发送的数据获取请求,并基于浏览器中的插件生成目标操作指令集合后,系统即可对这些指令进行响应。由于这些指令至少可以反映用户希望从哪些网站采集数据,因此,浏览器可以根据页面地址执行页面访问操作,即,向与页面地址对应的网页进行跳转,可以理解,在本实施例中,浏览器根据数据访问请求跳转的网页即是目标访问页面。
44.s140、基于目标脚本爬取与目标访问页面相对应的待反馈数据,并将待反馈数据发送至服务端。
45.其中,用于爬取数据的目标脚本可以是网络爬虫。网络爬虫作为一种按照一定规则,自动抓取互联网中信息的程序或脚本,可以将所访问的页面的数据保存下来,例如,网络搜索引擎等站点可以利用爬虫软件更新自身的网站内容或更新自身对其他网站的索引,以此为用户提供搜索服务。
46.在本实施例中,待目标访问页面加载完毕并根据用户需求执行对应的操作后,即可调用对应的爬虫脚本,并利用该脚本执行数据获取操作。可以理解,基于脚本在目标访问页面采集的数据即是用户所需要的待反馈数据。从目标访问页面中确定出待反馈数据并将其回传给服务端后,便完成了一次数据获取操作。
47.示例性的,chrome浏览器按照数据获取请求的需要跳转至目标访问页面,并待目标访问页面加载完毕后,可以根据目标操作指令在当前页面中执行翻页操作或验证码滑块的滑动操作等。进一步的,浏览器将上述操作执行完毕(即模拟用户行为)后,即可调用基于javascript编写的爬虫脚本,在当前页面执行数据爬取操作。本领域技术人员应当理解,在爬虫脚本中可以制定相应的字段匹配规则,以及新建文本或表格文件的指令,也即是说,爬虫脚本可以在网页的源码中匹配出符合要求的字符串,进而输出相应的匹配结果并将其作为待反馈数据,最后基于待反馈数据生成对应的文本文件或表格文件,将文件回传给服务端后,即完成本次数据获取操作。
48.本实施例的技术方案,应用于浏览器中的插件,当接收到服务端发送的数据获取请求时,确定与数据获取请求相对应的待编辑配置项;为待编辑配置项配置请求参数,得到与数据获取请求相对应的目标操作指令集合;基于插件运行目标操作指令集合中的各个操作指令,跳转至至少一个目标访问页面;基于目标脚本爬取与目标访问页面相对应的待反馈数据,并将待反馈数据发送至服务端,利用浏览器插件,为用户提供了控制浏览器行为的途径,进一步的,为爬虫脚本的运行创造了真实用户的浏览器环境,避免了直接运行脚本或基于无头浏览器运行脚本而被网站检测封禁的问题,保证了数据爬取的成功率。
49.实施例二
50.图2为本发明实施例二所提供的一种网页数据获取方法的流程示意图,在前述实施例的基础上,在服务端与浏览器插件之间建立基于websocket协议的通信通道,为用户提供了向浏览器发送数据获取请求的途径,同时,websocket协议中数据双向传输的机制便于后续的数据回传;根据数据获取参数与插件中配置项的对应关系,确定待编辑配置项,进而通过字段赋值的方式得到目标操作指令,使chrome浏览器在操作指令的控制下模拟用户的行为;利用浏览器调用爬虫脚本执行数据爬取操作,得到待反馈数据,并将数据回传给服务端存储于目标存储库中,实现了数据爬取操作的闭环。其具体的实施方式可以参见本实施例技术方案。其中,与上述实施例相同或者相应的技术术语在此不再赘述。
51.如图2所示,该方法具体包括如下步骤:
52.s210、向服务端发送通信连接请求;当接收到服务端反馈的响应信息时,与服务端建立基于websocket协议的通信通道。
53.在本实施例中,为了给用户提供向浏览器发送数据获取请求的途径,并为了在后续过程中实现数据回传,首先需要在后端服务器与浏览器插件之间建立通信通道,下面结合图3对这一过程进行具体说明。
54.参见图3可知,为了便于后端服务器发送指令给chrome插件,在服务端和浏览器之间需要建立基于websocket协议的通信通道,websocket是一种在单个传输控制协议(transmission control protocol,tcp)连接上进行全双工通信的协议,它使得浏览器和服务端之间的数据交换变得更加简单,并允许服务端主动向浏览器推送数据。在websocket的应用程序编程接口(application programming interface,api)中,浏览器和服务端只需要完成一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。在实际应用过程中,用户可以利用node的express以及socket.io库创建一个节点node服务支持长链接,以此实现本地websocket服务的创建。
55.进一步的,继续参见图3可知,用户在本地启用websocket服务后,浏览器即可向服务端发送基于http协议的通信连接请求,以此建立chrome插件与本地node服务的相互通信。为了更加详细的解释这一过程,在此对chrome插件中几种js的使用场景进行说明。对于content
‑
scripts来说,其主要功能为基于chrome插件向页面注入脚本,利用该文件可以在别的页面控制台中打印出用户期望的log content
‑
scripts和原始页面共享文档对象模型(document object model,dom);对于background.js来说,这是一个常驻页面,它的生命周期是插件中所有类型页面中最长的,随着浏览器的打开而打开,随着浏览器的关闭而关闭,因此,需要把需要一直运行的、全局的代码放在background里;对于popup.js来说,它是点击chrome浏览器右上角的插件图标所展示的弹窗,生命周期很短,因此可以将临时的交互写在popup.js中。
56.在实际应用过程中,用户可以将需要的js库和background.js引入到background.html中,并通过多种方式进行调试。例如,直接在chrome扩展中点击对应的按钮即可弹出调试窗口,或者,在浏览器中输入对应的地址进入调试窗口,本领域技术人员应当理解,具体的调试方案可以根据实际情况进行选择,本公开实施例在此不做具体的限定。
57.进一步的,继续参见图3可知,基于chrome浏览器中的插件需要使background.js与content
‑
script.js建立通信。具体的,可以对background.js中的代码进行修改,将从content
‑
script.js接收到的msg发送到node服务,并将从node服务接收到的msg发送到
content
‑
script.js,最后重启浏览器进行测试,如,向特定的接口发送消息,当与该接口对应的页面接收到该消息后,表明后端服务器与chrome插件之间已经建立了基于websocket协议的连接。
58.s220、当接收到服务端发送的数据获取请求时,提取数据获取请求中所携带的数据获取参数;根据数据获取参数与浏览器插件中配置项的对应关系,确定与数据获取参数相对应的待编辑配置项。
59.在本实施例中,在通过服务端发送的数据获取请求中,还可以携带多种类型的信息,这些信息即是数据获取参数,本领域技术人员应当理解,数据获取参数可以反映用户的数据采集意图。例如,请求中可以携带目标访问页面的url地址,表征用户想要采集的数据所在的目标网页,可以携带页面加载等待时长,表征浏览器模拟用户访问该页面后等待网页加载所需的时间,还可以携带翻页操作以及滑动验证码滑块操作的相关信息,表征用户希望在目标访问页面执行的特定操作。
60.进一步的,在安装有chrome浏览器的系统中,还预先存储有表征上述数据获取参数与浏览器插件配置项之间对应关系的映射表。基于此,在接收到服务端发送的数据获取请求,并解析得到请求携带的数据获取参数后,通过查表的方式即可确定出与这些数据获取参数相对应的待编辑配置项。
61.需要说明的是,在本实施例中,数据获取参数除了携带于数据获取请求中,还可以在服务端发送数据获取请求的同时,作为独立的信息通过消息队列依次发送给安装有chrome浏览器的系统,本领域技术人员应当理解,具体的数据获取参数的发送方式可以根据实际情况进行选择,本公开实施例并未做具体的限定。
62.s230、基于数据获取参数的字段对各待编辑配置项的字段进行赋值,得到目标操作指令集合中与各待编辑配置项相对应的目标操作指令。
63.在本实施例中,确定出数据获取参数以及与这些参数相对应的待编辑配置项后,可以基于参数信息向对应的待编辑配置项进行赋值,具体的,可以将参数中特定的字段赋值给浏览器插件的待编辑配置项,例如,将目标访问页面的url地址赋值给浏览器插件待编辑配置项中的地址项,将目标等待时长赋值给浏览器插件待编辑配置项中的加载等待时间项。
64.在本实施例中,chrome浏览器插件的待编辑配置项基于数据获取参数进行赋值后,即可生成对应的目标操作指令,并为这些指令构建目标操作指令集合,进一步的,基于集合中的操作指令,chrome浏览器可以在插件的控制下,按照服务端的要求,模拟真实用户对特定的页面进行访问,并在后续过程中调用爬虫脚本执行相对应的数据爬取操作。
65.s240、基于插件运行目标操作指令集合中的各个操作指令,跳转至至少一个目标访问页面。
66.s250、调用预先编写的基于javascript的目标脚本,对目标访问页面进行解析,得到全体数据;基于目标脚本中的数据提取方法,从全体数据中提取出待反馈数据。
67.在本实施例中,浏览器跳转至目标访问页面,并待该页面加载完毕后,即可调用基于javascript编写的爬虫脚本。具体来说,运行该爬虫脚本后,可以实现对当前网页的解析,进而在解析得到的全体数据中提取出用户需要的待反馈数据。
68.示例性的,根据数据获取请求所确定的目标访问页面为电影推荐网页,当该电影
推荐网页加载完毕、且在浏览器基于数据获取参数模拟用户执行相对应的操作后,即可调用预先编写的爬虫脚本,对该页面的数据进行解析,得到全体数据,在全体数据中包括多个电影的电影名称、上映年份、演员表以及网站评分等多个维度的信息。
69.进一步的,根据数据获取脚本中的数据获取方法,确定与数据获取方法相对应的数据返回值,并将数据返回值作为待反馈数据。
70.继续以上述示例进行说明,在浏览器调用的爬虫脚本中,还可以设置关键参数匹配机制,以此作为数据获取方法,可以理解为,浏览器利用脚本对当前页面进行解析并确定出全体数据后,可以通过参数匹配的方式得到数据返回值,并将所得到的数据返回值作为待反馈数据。具体到上述示例中,可以在爬虫脚本中设置电影名称和网站评分作为匹配的关键参数,基于此,在所确定的包含有电影名称、上映年份、演员表以及网站评分等多个维度的信息的全体数据中,可以筛选出电影名称和网站评分的相关数据进行爬取得,进而得到与上述两个参数相对应的数据返回值,并将其存储在特定的文本文件或表格文件中作为待反馈数据。
71.在本实施例中,待反馈数据包括结构化数据和/或非结构化数据,其中,结构化数据也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格遵循数据格式与长度规范,而非结构化数据则是数据结构不规则或不完整,没有预定义的数据模型,不便于用数据库二维逻辑来表现的数据,包括所有格式的办公文档、文本、图片、各类报表、图像和音频/视频信息等。本领域技术人员应当理解,对于结构化数据,爬虫脚本可以对其设置对应的结构化数据标记,对于不同类型的数据,脚本中也可以部署对应的数据爬取方法。在本实施例中,利用爬虫脚本爬取结构化数据和/或非结构化数据,增强了网页数据获取方案在实际应用过程中的适应性和灵活性。
72.s260、通过目标访问页面与浏览器之间的通信管道回传所获取的数据;基于websocket协议将回传的数据发送至服务端,并将数据存储于目标存储库中。
73.在本实施例中,浏览器调用爬虫脚本在目标访问页面爬取大量数据并将其作为待反馈数据后,可以利用通信管道将这些数据进行回传。其中,管道通信(communication pipeline)即是发送进以字符流形式将大量数据送入管道,接收进行从管道接收数据,二者利用管道进行通信的一种方式。这种通信方式拥有独特的优越性,并不会完全依赖某一种协议,而是对于任何只要能够实现通信的协议都适用,因此,可以对包括结构化数据和/或非结构化数据的待反馈数据实现很好的传输。
74.进一步的,当浏览器插件的一端基于通信管道接收到待反馈数据后,由于浏览器插件与后端服务之间还基于websocket协议建立了通信通道,同时,websocket又支持数据的双向传输。因此,浏览器插件可以利用基于websocket协议的通信通道将待反馈数据进一步回传给服务端。服务端接收到待反馈数据后,即可将数据存储在目标存储库(如分布式文件系统)中,从而使本次数据爬取操作实现闭环。
75.需要说明的是,后端服务接收到chrome浏览器插件回传的待反馈数据后,还可以对数据进行清洗操作,从而将其中不符合要求的数据剔除。进一步的,后端服务还可以根据不同的类型对这些数据进行分类,并将分类后的数据分别存储在分布式文件系统中的特定位置,本领域技术人员应当理解,具体的数据清洗以及分类方式应当根据实际情况进行选择,本公开实施例在此不再赘述。
76.本实施例的技术方案,在服务端与浏览器插件之间建立基于websocket协议的通信通道,为用户提供了向浏览器发送数据获取请求的途径,同时,websocket协议中数据双向传输的机制便于后续的数据回传;根据数据获取参数与插件中配置项的对应关系,确定待编辑配置项,进而通过字段赋值的方式得到目标操作指令,使chrome浏览器在操作指令的控制下模拟用户的行为;利用浏览器调用爬虫脚本执行数据爬取操作,得到待反馈数据,并将数据回传给服务端存储于目标存储库中,实现了数据爬取操作的闭环。
77.实施例三
78.图4为本发明实施例三所提供的一种网页数据获取装置的结构框图,可执行本发明任意实施例所提供的网页数据获取方法,具备执行方法相应的功能模块和有益效果。如图4所示,该装置具体包括:待处理项目代码编译模块310、待回收类确定模块320、目标数据处理方式确定模块330以及目标文件确定模块340。
79.待编辑配置项确定模块310,用于当接收到服务端发送的数据获取请求时,确定与所述数据获取请求相对应的待编辑配置项。
80.目标操作指令集合确定模块320,用于为所述待编辑配置项配置请求参数,得到与所述数据获取请求相对应的目标操作指令集合;其中,所述请求参数为所述数据获取请求中所携带的参数。
81.目标访问页面跳转模块330,用于基于浏览器插件运行所述目标操作指令集合中的各个操作指令,跳转至至少一个目标访问页面。
82.待反馈数据爬取模块340,用于基于目标脚本爬取与所述目标访问页面相对应的待反馈数据,并将所述待反馈数据发送至所述服务端。
83.在上述各技术方案的基础上,所述网页数据获取装置还包括通信通道建立模块。
84.通信通道建立模块,用于向所述服务端发送通信连接请求;当接收到所述服务端反馈的响应信息时,与所述服务端建立基于websocket协议的通信通道。
85.在上述各技术方案的基础上,待编辑配置项确定模块310包括数据获取参数提取单元以及待编辑配置项确定单元。
86.数据获取参数提取单元,用于当接收到所述服务端发送的数据获取请求时,提取所述数据获取请求中所携带的数据获取参数,其中,所述数据获取参数包括所述目标访问网页的地址。
87.待编辑配置项确定单元,用于根据所述数据获取参数与所述浏览器插件中配置项的对应关系,确定与所述数据获取参数相对应的待编辑配置项。
88.可选的,目标操作指令集合确定模块320,还用于基于所述数据获取参数的字段对各待编辑配置项的字段进行赋值,得到目标操作指令集合中与各待编辑配置项相对应的目标操作指令。
89.在上述各技术方案的基础上,待反馈数据爬取模块340包括解析单元、待反馈数据提取单元、数据回传单元以及数据存储单元。
90.解析单元,用于调用预先编写的基于javascript的目标脚本,对所述目标访问页面进行解析,得到全体数据。
91.待反馈数据提取单元,用于基于所述目标脚本中的数据提取方法,从所述全体数据中提取出所述待反馈数据。
92.可选的,待反馈数据提取单元,还用于根据所述数据获取脚本中的数据获取方法,确定与所述数据获取方法相对应的数据返回值,并将所述数据返回值作为所述待反馈数据;其中,所述待反馈数据包括结构化数据和/或非结构化数据。
93.数据回传单元,用于通过所述目标访问页面与浏览器之间的通信管道回传所获取的数据。
94.数据存储单元,用于基于websocket协议将回传的数据发送至所述服务端,并将数据存储于目标存储库中。
95.本实施例所提供的技术方案,应用于浏览器中的插件,当接收到服务端发送的数据获取请求时,确定与数据获取请求相对应的待编辑配置项;为待编辑配置项配置请求参数,得到与数据获取请求相对应的目标操作指令集合;基于插件运行目标操作指令集合中的各个操作指令,跳转至至少一个目标访问页面;基于目标脚本爬取与目标访问页面相对应的待反馈数据,并将待反馈数据发送至服务端,利用浏览器插件,为用户提供了控制浏览器行为的途径,进一步的,为爬虫脚本的运行创造了真实用户的浏览器环境,避免了直接运行脚本或基于无头浏览器运行脚本而被网站检测封禁的问题,保证了数据爬取的成功率。
96.本发明实施例所提供的网页数据获取装置可执行本发明任意实施例所提供的网页数据获取方法,具备执行方法相应的功能模块和有益效果。
97.值得注意的是,上述装置所包括的各个单元和模块只是按照功能逻辑进行划分的,但并不局限于上述的划分,只要能够实现相应的功能即可;另外,各功能单元的具体名称也只是为了便于相互区分,并不用于限制本发明实施例的保护范围。
98.实施例四
99.图5为本发明实施例四所提供的一种电子设备的结构示意图。图5示出了适于用来实现本发明实施例实施方式的示例性电子设备40的框图。图5显示的电子设备40仅仅是一个示例,不应对本发明实施例的功能和使用范围带来任何限制。
100.如图5所示,电子设备40以通用计算设备的形式表现。电子设备40的组件可以包括但不限于:一个或者多个处理器或者处理单元401,系统存储器402,连接不同系统组件(包括系统存储器402和处理单元401)的总线403。
101.总线403表示几类总线结构中的一种或多种,包括存储器总线或者存储器控制器,外围总线,图形加速端口,处理器或者使用多种总线结构中的任意总线结构的局域总线。举例来说,这些体系结构包括但不限于工业标准体系结构(isa)总线,微通道体系结构(mac)总线,增强型isa总线、视频电子标准协会(vesa)局域总线以及外围组件互连(pci)总线。
102.电子设备40典型地包括多种计算机系统可读介质。这些介质可以是任何能够被电子设备40访问的可用介质,包括易失性和非易失性介质,可移动的和不可移动的介质。
103.系统存储器402可以包括易失性存储器形式的计算机系统可读介质,例如随机存取存储器(ram)404和/或高速缓存存储器405。电子设备40可以进一步包括其它可移动/不可移动的、易失性/非易失性计算机系统存储介质。仅作为举例,存储系统406可以用于读写不可移动的、非易失性磁介质(图5未显示,通常称为“硬盘驱动器”)。尽管图5中未示出,可以提供用于对可移动非易失性磁盘(例如“软盘”)读写的磁盘驱动器,以及对可移动非易失性光盘(例如cd
‑
rom,dvd
‑
rom或者其它光介质)读写的光盘驱动器。在这些情况下,每个驱动器可以通过一个或者多个数据介质接口与总线403相连。存储器402可以包括至少一个程
序产品,该程序产品具有一组(例如至少一个)程序模块,这些程序模块被配置以执行本发明各实施例的功能。
104.具有一组(至少一个)程序模块407的程序/实用工具408,可以存储在例如存储器402中,这样的程序模块407包括但不限于操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。程序模块407通常执行本发明所描述的实施例中的功能和/或方法。
105.电子设备40也可以与一个或多个外部设备409(例如键盘、指向设备、显示器410等)通信,还可与一个或者多个使得用户能与该电子设备40交互的设备通信,和/或与使得该电子设备40能与一个或多个其它计算设备进行通信的任何设备(例如网卡,调制解调器等等)通信。这种通信可以通过输入/输出(i/o)接口411进行。并且,电子设备40还可以通过网络适配器412与一个或者多个网络(例如局域网(lan),广域网(wan)和/或公共网络,例如因特网)通信。如图所示,网络适配器412通过总线403与电子设备40的其它模块通信。应当明白,尽管图5中未示出,可以结合电子设备40使用其它硬件和/或软件模块,包括但不限于:微代码、设备驱动器、冗余处理单元、外部磁盘驱动阵列、raid系统、磁带驱动器以及数据备份存储系统等。
106.处理单元401通过运行存储在系统存储器402中的程序,从而执行各种功能应用以及数据处理,例如实现本发明实施例所提供的网页数据获取方法。
107.实施例五
108.本发明实施例五还提供一种包含计算机可执行指令的存储介质,所述计算机可执行指令在由计算机处理器执行时用于执行网页数据获取方法。
109.该方法包括:
110.当接收到服务端发送的数据获取请求时,确定与所述数据获取请求相对应的待编辑配置项;
111.为所述待编辑配置项配置请求参数,得到与所述数据获取请求相对应的目标操作指令集合;其中,所述请求参数为所述数据获取请求中所携带的参数;
112.基于所述插件运行所述目标操作指令集合中的各个操作指令,跳转至至少一个目标访问页面;
113.基于目标脚本爬取与所述目标访问页面相对应的待反馈数据,并将所述待反馈数据发送至所述服务端。
114.本发明实施例的计算机存储介质,可以采用一个或多个计算机可读的介质的任意组合。计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质。计算机可读存储介质例如可以是——但不限于——电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑磁盘只读存储器(cd
‑
rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本文件中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。
115.计算机可读的信号介质可以包括在基带中或者作为载波一部分传播的数据信号,
其中承载了计算机可读的项目代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读的信号介质还可以是计算机可读存储介质以外的任何计算机可读介质,该计算机可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。
116.计算机可读介质上包含的项目代码可以用任何适当的介质传输,包括——但不限于无线、电线、光缆、rf等等,或者上述的任意合适的组合。
117.可以以一种或多种程序设计语言或其组合来编写用于执行本发明实施例操作的计算机项目代码,所述程序设计语言包括面向对象的程序设计语言—诸如java、smalltalk、c++,还包括常规的过程式程序设计语言——诸如“c”语言或类似的程序设计语言。项目代码可以完全地在用户计算机上执行、部分地在用户计算机上执行、作为一个独立的软件包执行、部分在用户计算机上部分在远程计算机上执行、或者完全在远程计算机或服务器上执行。在涉及远程计算机的情形中,远程计算机可以通过任意种类的网络——包括局域网(lan)或广域网(wan)—连接到用户计算机,或者,可以连接到外部计算机(例如利用因特网服务提供商来通过因特网连接)。
118.注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1