一种基于广度优先分割的拓扑切分图神经网络训练机制的制作方法
1.本发明涉及新兴信息技术、人工智能领域,特别涉及一种基于广度优先分割的拓扑切分图神经网络训练机制。
背景技术:
2.图神经网络作为一种灵活的数据表征方式,已广泛应用于各种现实应用中的业务需求。尤其是对于非欧空间的场景数据,图神经网络有着显著的优势,如社交网络、知识图谱、生物网络等。
3.现有业务场景中图神经网络需要处理的拓扑图规模非常巨大,通常包含上亿级别的点和边,这对于传统的单机训练的方式无论内存资源还是计算资源都是无法承受的,因此对于图神经网络的训练效率提出了很高的要求。现有方法对图神经网络的分布式训练鲜有论述,其需要解决的问题有以下两个:1)寻找一种分布式训练框架,实现并行式梯度更新,提升网络训练效率;2)为了实现分布式训练,需要进行数据分片,由于拓扑图具有连通性,普通的数据分片方式将破坏拓扑图中节点的关系,造成信息丢失,降低了图神经网络学习的准确性。
4.本专利针对以上两点,提出了一种基于广度优先分割的拓扑切分图神经网络训练机制,使数据在各个服务器上实现均衡、无偏、高连通性的切分,确保原图拓扑信息能更完整的保存,并通过参数服务器架构实现分布式的训练,极大的提高模型训练效率,使得图神经网络在大规模图上的训练能够可行、高效、准确。
技术实现要素:
5.本发明要解决的技术问题是克服现有技术的缺陷,提供一种基于广度优先分割的拓扑切分图神经网络训练机制。
6.为了解决上述技术问题,本发明提供了如下的技术方案:
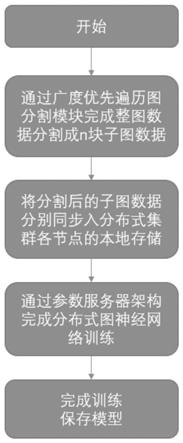
7.本发明提供一种基于广度优先分割的拓扑切分图神经网络训练机制,包括以下步骤:
8.一、存储资源预估分配模块:
9.假设图网络节点数总共为t,检测集群上各worker服务器s1,s2,
…
,sn的内存资源,预估内存可存储图节点数分别为n1,n2,
…
,nn。设置阈值k(0<k<1),若则集群上服务器si存储节点数若则集群上服务器si存储节点数为
10.二、广度优先遍历图分割模块:
11.为每台worker服务器si进行图划分前的初始化操作:1)存储图节点集设置为空集、2)当前节点集bn设置为空集、3)一阶近邻节点集bo设置为空集;候选节点集定义为bc={v1,v2,
…
,v
t
},即所有图节点的集合;
12.开始将整图数据划分成n个子图,从1至n循环执行如下操作:
13.1)若当前节点集bn为空集,则从候选节点集bc中随机选取节点vj加入服务器si存储图节点集与当前节点集bn,在候选节点集bc中剔除已在集合bn中的节点;
14.2)将当前节点集bn每个节点的一阶邻居节点加入一阶近邻节点集bo,并在其中剔除已在集合中的节点,即若bo为空集,则令bn为空集,并重复步骤1)-2);
15.3)若即服务器si仍有足够资源可存储一阶近邻节点集bo,则先令bn=bo,再令再令bc=b
c-bo,最后令重复步骤2)-3)直到不满足该操作可以使得在集群每台服务器si中存储的图达到最优的连通性,使得尽可能的避免或者减少图分割所造成的拓扑关系破坏及信息丢失;若则在一阶近邻节点集bo中随机选取个节点加入到集群服务器si存储图节点集并令当前节点集bn与一阶近邻节点集bo为空集;该操作中未将一阶近邻节点集bo中的节点从候选节点集bc中剔除,这样做可尽可能保留bo中节点的边信息,更有利于模型对于信息的学习;至此为worker服务器si准备的子图分割完成,继续为集群上其他worker服务器进行子图分割;
16.三、分割后子图分布式存储:
17.整图网络按上述方式进行图分割后,将划分后的子图分别存储于集群各台worker服务器si的本地存储中;
18.四、基于参数服务器架构进行分布式训练:
19.1)将图算法部署在每个worker节点,用于计算梯度;
20.2)将模型参数w进行分割,分别存储于k个server节点中,server集群维护完整的模型参数,初始化参数w;
21.3)每个worker节点读取本地的数据,计算得到邻接矩阵a,在每轮迭代过程中,根据邻接矩阵a从对应的server端pull下所需的参数w,异步方式进行学习训练,将计算好的新梯度push到server端,然后从server端pull下最新的参数w;
22.4)server端根据接收到的梯度信息更新全局参数w;
23.5)当训练到达终止条件即完成分布式的训练;
24.五、模型训练结束,保存模型。
25.与现有技术相比,本发明的有益效果如下:
26.本发明保证了切分后的数据在各个服务器上均衡、无偏、高连通,在有限的内存容
2);
41.3)若即服务器si仍有足够资源可存储一阶近邻节点集bo,则先令bn=bo,再令再令bc=b
c-bo,最后令重复步骤2)-3)直到不满足该操作可以使得在集群每台服务器si中存储的图达到最优的连通性,使得尽可能的避免或者减少图分割所造成的拓扑关系破坏及信息丢失;若则在一阶近邻节点集bo中随机选取个节点加入到集群服务器si存储图节点集并令当前节点集bn与一阶近邻节点集bo为空集;该操作中未将一阶近邻节点集bo中的节点从候选节点集bc中剔除,这样做可尽可能保留bo中节点的边信息,更有利于模型对于信息的学习;至此为worker服务器si准备的子图分割完成,继续为集群上其他worker服务器进行子图分割;
42.三、分割后子图分布式存储:
43.整图网络按上述方式进行图分割后,将划分后的子图分别存储于集群各台worker服务器si的本地存储中;
44.四、基于参数服务器架构进行分布式训练:
45.1)将图算法部署在每个worker节点,用于计算梯度;
46.2)将模型参数w进行分割,分别存储于k个server节点中,server集群维护完整的模型参数,初始化参数w;
47.3)每个worker节点读取本地的数据,计算得到邻接矩阵a,在每轮迭代过程中,根据邻接矩阵a从对应的server端pull下所需的参数w,异步方式进行学习训练,将计算好的新梯度push到server端,然后从server端pull下最新的参数w;
48.4)server端根据接收到的梯度信息更新全局参数w;
49.5)当训练到达终止条件即完成分布式的训练;
50.五、模型训练结束,保存模型。
51.具体的,实施过程如下所示:
52.1.存储资源预估分配模块:阈值k=0.8;
53.2.集群worker节点数20;
54.3.集群server节点数4;
55.4.运行图神经网络算法:gat(graph attention networks)、graphsage等。
56.本发明技术要点如下所示:
57.1.提出了一种基于广度优先分割的拓扑切分方式,保证切分后的子图数据均衡、无偏、高连通,使原图拓扑信息能更完整的保存,避免因信息丢失造成图神经网络学习准确性的降低。
58.2.提出了通过参数服务器架构来进行图神经网络的分布式训练,实现并行的梯度学习及更新,提升了图神经网络的学习效率,使得图神经网络在大规模图上的训练可行、高
效。
59.最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1