一种以近邻熵为查询策略的主动学习方法
1.本发明公开了一种以近邻熵为查询策略的主动学习方法,具体涉及数据挖掘及信息处理技术领域。
背景技术:
2.针对实际应用中只有少量已标记数据和大量未标注记数据的情况,主动学习(active learning)是有效的解决方法。主动学习的过程是迭代进行的,每次训练都会从未标记数据池中挑选出信息量最大的样本进行标记,然后将这些数据添加到已标记数据集中进行训练,不断提升分类器的分类效率。主动学习不需要标记大量的数据,而只需要标记其中少量的对提高模型性能有帮助的数据,这样不仅可以减少大批量标记数据的人力和物力,降低标记成本,同时还可以提高模型的分类性能。
3.基于池的主动学习方法(pool
‑
based active learning)是主动学习中适用性最广、研究最为充分的一种方法。该方法的数据是直接从未标记数据池中挑选的,且每次都能从中挑选出对当前分类器贡献最大的数据交由分类器进行判断,当判断有误时就交给专家进行人工标记,然后将新标记的数据加入到训练集中。由评判数据“价值”的标准不同,基于池的主动学习方法主要可以分为三种:基于不确定性缩减、基于版本空间缩减以及基于泛化误差缩减的方法。
4.熵方法是基于不确定性缩减的主动学习中的一种方法。熵是一种信息论度量,他表示对分布进行“编码”所需要的信息量。在数学领域中,常常用信息熵来衡量一个系统的不确定性或是描述某些信息的不纯度等。在主动学习领域中,可以使用熵来衡量数据的不确定性,熵值越大代表数据的不确定性越大,对熵值最大的未标记数据进行标记可以有效提升分类器的性能。
5.k近邻算法是机器学习算法中最简单的算法之一。在进行分类时,通常利用“同类相聚,异类相离”的思想,将当前数据归类为邻近数据多数属于的类别。而基于不确定性的主动学习方法通常忽略了数据的先验分布,k近邻算法的算法原理正好可以弥补这个不足,这为本发明提供了可能。
技术实现要素:
6.针对当前不确定性采样策略忽略了数据先验分布的问题,考虑将k近邻算法的思想融入到基于熵的不确定性方法中,提出一种基于近邻熵的主动学习方法。该方法同时考虑当前未标注数据及其邻近的k个未标注数据的分类情况,以当前数据与邻近的k个数据的平均熵值作为度量方式,最后倾向于选择近邻熵值最大的数据进行标记并且加入到训练集中。这样不仅可以避免挑选到处于分类边界的孤立点,还有效降低了数据标记的代价,训练出更加有效的分类器。
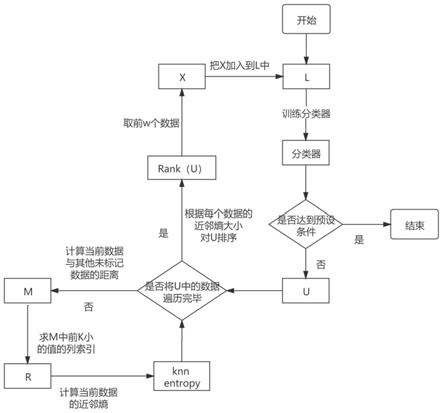
7.本发明思路:使用初始化训练集训练分类器;用训练好的分类器对测试集中的数据进行分类预测;计算当前未标记数据及其邻近的k个未标记数据的熵值,得到当前未标记
数据的近邻熵;循环执行以上操作,直到将测试集中的未标记数据都遍历一遍,最后得到每一个未标记数据的近邻熵;按照近邻熵值的大小对测试集中的数据进行排序,选取前w个近邻熵值大的未标记数据进行标记;将新标记的数据添加到训练集中用于分类器的下一次训练;循环以上操作,直到满足终止学习。
8.具体步骤为:
9.步骤1使用初始训练集l对分类器进行训练。
10.步骤2利用训练好的分类器对测试集中的所有数据进行分类预测。
11.步骤3使用基于近邻熵的查询策略在测试集中挑选出信息量最大的未标记数据进行标记;计算测试集u中当前未标记数据与u中其他未标记数据之间的欧式距离,得到行向量m;取m中前k小的值的列索引,形成行向量r;由向量r得到u中距离当前未标记数据最近的k个未标记数据,形成l1;计算当前未标记数据与l1中数据的熵值,随后计算得到近邻熵;根据所有未标记数据的近邻熵值大小对u按从大到小的顺序排序;选取前w个近邻熵值大的的未标记数据并标记。
12.步骤4在u中删掉标记后的数据,并将这些数据加入到训练集中,使用更新后的训练集训练分类器。
13.步骤5循环以上操作,直到满足预设的停止条件时结束算法。
14.本发明融入了k近邻算法思想,是基于近邻熵的不确定性主动学习查询策略。该策略以近邻熵的值衡量未标记数据的不确定性,同时考虑当前未标记数据及其邻近的k个未标记数据的分类情况。近邻熵值越大表示该数据的不确定性越高,标记这样的数据不仅可以避免挑选到处于分类边界的孤立点,还有效降低了数据标记的代价,训练出分类性能以及泛化能力更好的分类器。
附图说明
15.图1是本发明实施例的具体步骤流程图。
16.图2是本发明实施例在digits数据集上的实验对比。
17.图3是本发明实施例在accuracy评价指标上的实验对比。
18.图4是本发明实施例在f1
‑
score评价指标上的实验对比。
19.图5是本发明实施例在auc评价指标上的实验对比。
具体实施方式:
20.本发明选取uci上公开的几个常见数据集进行实验。为了测试分类器的性能,实验使用逻辑回归分类器对测试集进行分类预测,分别选用acc、f1
‑
score和auc作为评价指标。为了保证实验结果的可靠性,分别使用不同的数据集以及评价指标各进行10次实验,取所有实验的平均值作为结果。设未标记数据集为u={x1,x2,...,x
n
},已标记数据集为l={<x
i
,f(x
i
)>|x
i
∈u,i=1,2,...,k},其中f为x
i
与所属类别的映射。
21.具体步骤为:
22.步骤1初始化测试集u和训练集l。
23.步骤2使用训练集l对分类器进行训练。
24.步骤3将训练好的分类器对测试集u中的所有数据进行分类预测。
25.步骤4使用近邻熵查询策略在测试集中挑选最有价值的数据x进行标记。
26.步骤4.1计算u中当前未标记数据与其他未标记数据的欧氏距离,得到行向量m如下:
27.m=[m
m1 m
m2 ... m
ml ... m
mn
]
[0028]
其中m
ml
表示当前未标记数据x
m
与未标记数据x
l
之间的欧氏距离。欧式距离公式为x
i
和x
j
为u中的两个数据,l为向量空间维数。
[0029]
步骤4.2取m中前k小值的列索引,形成行向量r为:
[0030]
r=index([v
m1 v
m2 ... v
mk
])
[0031]
其中v
mk
为距离未标记数据x
m
最近的第k个未标记数据。
[0032]
步骤4.3由逻辑回归分类器得到u中未标记数据的类别概率p
θ
(y
i
|x)。
[0033]
步骤4.4计算当前未标记数据x
m
与由r中列索引对应的k个未标记数据的熵值,得到当前数据的近邻熵如下:
[0034][0035]
步骤5循环执行步骤4.1至步骤4.4的操作,直到将u中的数据遍历完毕。若已获得u中所有数据的近邻熵,则跳到步骤6继续执行算法。
[0036]
步骤6根据近邻熵值的大小对测试集u中的所有数据按从大到小的顺序排序。
[0037]
步骤7选取前w个近邻熵值大的未标记数据进行人工标记,将标记之后的数据从测试集u中删除,同时将这些数据添加到l中,使用更新后的训练集l训练分类器。
[0038]
步骤8循环迭代执行以上操作,直到分类器性能、数据挑选数目等满足预设条件则停止学习。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1