针对长距离对话状态追踪的分层建模贡献感知的上下文的方法
1.本发明涉及自然语言处理以及任务型对话系统技术领域,具体为针对长距离对话状态追踪的分层建模贡献感知上下文的方法。
背景技术:
2.近年来,面向任务的对话系统在工业界和学术界都引起了广泛的关注,它已经被广泛应用于通过口语交互帮助用户完成任务,例如饭店预订、景点查询等。传统的任务型对话系统是一个管道式结构,由自然语言理解、对话状态追踪、对话策略学习和自然语言生成四个组件构成
1.。
3.其中,对话状态追踪的目标是在对话的每一轮保持对用户目标和意图的追踪,并把它们表示为一个对话状态,也就是一组槽以及它们对应的值
2.。由于对话策略学习和自然语言生成模块都需要依赖于对话状态追踪的结果进行下一个系统动作的选择和下一个系统回复的生成,因此一个准确的对话状态预测对于提升对话系统的整体表现十分关键
3.。
4.为了应对对话状态追踪任务中的挑战,近年来有许多方法被提出,这些方法主要可以被分为两类:基于预定义本体的方法和基于开放词汇表的方法。
5.(1)基于预定义本体的方法假设每个槽可能取到的所有值都被事先预定义在一个候选值集合中,对话状态预测过程实际上是每个槽关于候选值集合中全部元素的一次多分类过程。然而,在现实中,由于候选值的数量可能很大甚至是动态变化的,我们通常很难预定义这样一个候选值集合。
6.(2)生成式方法打破了预定义本体的假设,转而仅给定目标槽,直接根据上下文生成槽值。
7.然而,随着对话的进行,对话上下文不断累积,在对对话上下文进行建模的过程中很容易丢失距离当前对话轮较远的重要信息,导致对话状态预测失败,并且过多的上下文信息会导致对话状态追踪器很难聚焦到关键信息。
技术实现要素:
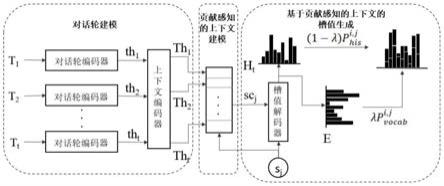
8.本发明的目的是为了克服现有技术中的不足,提供针对长距离对话状态追踪的分层建模贡献感知上下文的方法,其利用分层编码器以及注意力机制,建模槽特定的贡献感知的上下文表示,从而帮助模型更好地预测长距离条件下的对话状态,得到的对话状态预测准确度相较于基线模型在长文本条件下有明显提升。
9.本发明的目的是通过以下技术方案实现的:针对长距离对话状态追踪的分层建模贡献感知上下文的方法,包括以下步骤:
10.(1)构建对话轮建模模块:
11.对话轮建模模块利用一个分层结构(包含一个对话轮编码器和一个上下文编码
器)对训练语料中的对话上下文进行编码,得到包含了上下文信息的对话轮表示;该模块对给定对话上下文x
t
={t1,t2,t
k
,...,t
t
}进行编码,其中t表示对话上下文中对话轮的数量,t
k
={s
k
,u
k
} 表示对话轮t
k
中包含一个系统语句s
k
和一个用户语句u
k
,表示对话轮 t
k
的系统语句中有n
sk
个单词,表示对话轮t
k
的用户语句中有n
uk
个单词;
12.(2)构建贡献感知的上下文建模模块:
13.贡献感知的上下文建模模块利用了注意力机制,根据不同的槽s
j
为每个对话轮t
i
进行打分得到score
i,j
,衡量每个对话轮在当前槽值预测过程中可能做出的贡献,并据此得到槽特定的贡献感知的上下文表示sc
j
。
14.(3)构建基于贡献感知的上下文的槽值生成模块:
15.基于贡献感知的上下文的槽值生成模块利用了复制增广的解码器;该模块以各个槽嵌入s
j
作为初始输入,以槽特定的贡献感知的上下文表示sc
j
作为初始隐藏状态,在每一个解码步从对话历史或词汇表中进行选择得到当前解码步生成的单词,从而逐步生成槽值v
j
。
16.进一步的,步骤(1)中为得到训练语料包括以下步骤:
17.(101)对于每一个对话轮,将从对话开始至当前对话轮的全部语句作为对话历史;
18.(102)将(101)中得到的对话历史,按照对话轮进行分割,其中一个系统语句和一个用户语句作为一个对话轮(注意:第一轮对话中系统语句可能为空);
19.(103)统计训练预料中出现的全部域槽对,构造槽集合,具体格式为“域
‑
槽”;
20.(104)规范对话状态标注,如更正标注错误、拼写错误,统一意同词不同的标注等,并将规范化的对话状态中的槽值作为对应槽的训练标签。
21.进一步地,步骤(1)中,分层编码器包含一个低层的对话轮编码器和一个高层的上下文编码器。对话轮编码器由双向gru构成,针对上下文中每一个对话轮t
k
进行编码得到对话轮向量表示th
k
,此外,利用残差连接机制计算得到对话历史中所有单词的向量表示h
k
,其具体计算公式如下:
[0022][0023][0024][0025][0026][0027]
wh
k,i
=w
k,i
+h
k,i
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0028]
分别表示通过前向gru和后向gru编码得到的对话轮t
k
中第i个单词对应的隐藏状态,|t
k
|表示对话轮t
k
中单词的个数;表示低层对话轮编码器中的前向gru,表示低层对话轮编码器中的后向gru;h
k,i
表示对话轮t
k
中第i个单词通过双向gru 编码得到的隐藏状态向量;th
k
表示低层对话轮编码器编码得到的对话轮t
k
的向量表
示;wh
k,i
表示到对话轮t
k
为止的对话历史中第i个单词经过对话轮编码器得到的向量表示;|h
k
|表示到对话轮t
k
为止的对话历史中单词的个数;w
k,i
表示到对话轮t
k
为止的对话历史中第i个单词的词嵌入表示;
[0029]
高层上下文编码器由另一个双向gru构成,该结构将由按顺序排列好的对话轮向量表示构成的对话历史c
k
作为输入,之后利用残差连接机制计算得到包含了上下文信息的对话轮向量表示th
i
;具体计算公式如下:
[0030][0031][0032][0033]
th
i
=th
i
+th
′
i
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0034]
其中c
k
={th1,th2,...,th
k
}包含按顺序排列的由低层对话轮编码器得到的全部对话轮表示,k表示对话上下文中对话轮的个数;同上,表示高层上下文编码器中的前向gru,表示高层上下文编码器中的后向gru;分别表示前向gru和后向gru编码得到的对话上下文中第i个对话轮对应的隐藏状态;th
′
i
表示对话上下文中第i个对话轮通过双向gru编码得到的隐藏状态向量;th
i
表示对话上下文中第i个对话轮经过上下文编码器得到的包含了上下文信息的向量表示。
[0035]
进一步地,步骤(2)中,贡献感知的上下文建模模块利用注意力机制,根据不同的槽s
j
对对话上下文中的每一个对话轮t
i
进行打分得到score
i,j
,衡量在当前槽值预测过程中各个对话轮所能做出的贡献,并据此通过将全部对话轮表示进行加权求和,计算得到槽特定的贡献感知的对话上下文表示;具体计算公式如下:
[0036]
score
i,j
=s
j
th
i
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0037][0038][0039]
其中,score
i,j
表示槽s
j
对对话轮t
i
计算的注意力分数,衡量对话轮t
i
在槽s
j
的槽值生成过程中所能做出的贡献;s
j
表示第j个槽的词嵌入向量表示;th
i
表示由步骤(1)得到的对话轮 t
i
的向量表示;w
i,j
表示注意力分数score
i,j
经过softmax操作归一化后得到的结果;sc
j
表示槽s
j
特定的贡献感知的对话上下文向量表示。
[0040]
进一步地,步骤(3)中,基于贡献感知的上下文的槽值生成模块将槽嵌入s
j
作为初始输入,将步骤(2)中得到的槽s
j
特定的贡献感知的上下文表示sc
j
作为初始隐藏状态开始解码过程在每个时间步i:
[0041]
首先,解码器将前一步得到的单词嵌入dw
i
‑
1,j
作为当前时间步的输入,得到解码器状态 dh
i,j
:
[0042]
dh
i,j
=gru(dw
i
‑
1,j
,dh
i
‑
1,j
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(14)
[0043]
其中,dh
i,j
表示在槽s
j
的解码步i中得到的解码器隐藏状态;dw
i
‑
1,j
表示在槽s
j
的解码步 i
‑
1中得到的单词预测结果。
[0044]
之后,利用解码器状态dh
i,j
分别计算得到关于开放词汇表和对话历史的概率分布分别计算得到关于开放词汇表和对话历史的概率分布
[0045][0046][0047]
其中,表示在槽s
j
的解码步i中计算得到的关于词汇表的概率分布;表示在槽s
j
的解码步i中计算得到的关于对话历史的概率分布;softmax表示归一化指数函数;e表示词汇表对应的单词嵌入向量矩阵;h
t
表示步骤(1)中由低层对话轮编码器得到的对话历史对应的单词向量矩阵;|v|表示词汇表中包含单词的个数;|h
t
|表示对话轮t
t
的对话历史中包含单词的个数。
[0048]
最后,将得到的两个概率分布进行加权合并,得到关于整个词表的最终概率分布并选择概率最高的单词作为当前解码步的结果:
[0049][0050][0051][0052]
其中,表示词汇表和对话历史概率分布加权合并的最终概率分布结果;sigmoid表示激活函数;w为待学习的参数;wd
i,j
表示在槽s
j
的解码步i中学习到的对话上下文向量。
[0053]
上述解码过程中的损失函数表示如下:
[0054][0055]
其中,j表示数据集中包含域槽对的个数;|y
j
|表示在当前对话轮槽j对应的标注槽值中包含单词的个数;表示槽j对应的标注槽值中第i个单词的独热编码。
[0056]
有益效果:
[0057]
1.本发明解决了在使用单个序列模型建模长上下文时较早出现的关键信息丢失的问题。在步骤(1)进行上下文建模时,引入一个分层结构的编码器代替之前模型中使用的单个序列模型。使用单个序列模型作为编码器的模型中,将整个对话上下文进行拼接后直接送入序列模型中进行编码,当对话上下文很长时,出现较早的关键信息在编码过程中可能会被遗忘。
[0058]
因此,本发明中使用一种分层结构的编码器,将整个对话上下文按照对话轮分割为多个序列,在低层编码器中对每个对话轮语句进行编码得到每个对话轮的向量表示,在高层编码器中对对话上下文中包含的全部对话轮表示进行编码使得每个对话轮表示中能够包含上下文信息。通过减少送入每个编码器的序列长度,尽可能完整地在编码过程中保存对话上下文中每轮对话包含的信息。
[0059]
2.本发明避免了在多轮长对话上下文中,无关对话轮对模型预测的干扰。在步骤
(2)利用注意力机制,根据当前槽对对话上下文中的每个对话轮进行打分,衡量不同对话轮在当前槽值预测过程中可以做出的贡献,并根据不同的贡献分数将对话轮进行加权合并,得到槽特定的贡献感知的上下文表示,从而帮助模型更多地关注多轮长对话上下文中与当前槽相关的对话轮信息,而忽略无关对话轮信息。
[0060]
通过实验表明,上述两个改进方法可以有效提高模型在长对话上下文情况下的对话状态预测性能。
附图说明
[0061]
图1为本发明提供的针对长距离对话状态追踪的分层建模贡献感知的上下文的方法的总体框架图;
[0062]
图2为本发明提供的针对长距离对话状态追踪的分层建模贡献感知的上下文的方法中分层编码器的低层对话轮编码器的结构图;
[0063]
图3为本发明提供的针对长距离对话状态追踪的分层建模贡献感知的上下文的方法中分层编码器的高层上下文编码器的结构图。
具体实施方式
[0064]
以下结合附图和具体实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0065]
以多域数据集multiwoz2.0为例给出本发明的实施方法。该方法整体框架见图1所示。整个系统算法流程包括对话轮建模、贡献感知的上下文建模、槽值生成这3个步骤。
[0066]
具体步骤如下:
[0067]
(1)对话轮建模:
[0068]
本发明主要利用了multiwoz2.0数据集。该数据集为多域数据集,包含涉及景点、医院、警察、旅馆、饭店、出租车和火车7个域的10438段对话,由于医院和警察域只在训练集中出现,因此在实验过程中我们只使用剩余5个域的数据。本发明以该对话数据集为原始语料并做如下处理:
[0069]
(1)对于每一个对话轮,将从对话开始至当前对话轮的全部语句作为对话历史;
[0070]
(2)将(1)中得到的对话历史,按照对话轮进行分割,其中一个系统语句和一个用户语句作为一个对话轮(注意:第一轮对话中系统语句可能为空);
[0071]
(3)统计原始语料中出现的全部域槽对,构造槽集合,具体格式为“域
‑
槽”;
[0072]
(4)规范对话状态标注,如更正标注错误、拼写错误,统一意同词不同的标注等,并将规范化的对话状态中的槽值作为对应槽的训练标签。
[0073]
表1展示了该数据集的详细统计信息。该数据集中共包含对话71410轮,其中用于训练的对话56668轮,用于验证的对话7374轮,用于测试的对话7368轮。
[0074]
训练集中最长对话上下文包含879个单词,验证集中最长对话上下文包含659个单词,测试集中最长对话上下文包含615个单词。数据集中的对话数据主要分布在0
‑
300个单词的上下文长度范围内。
[0075]
表1对话数据集统计信息
[0076]
corpusalltrainingdevtest
total714105666873747368max length8798796596150
‑
99307972495429362907100
‑
199229561800524692482200
‑
299133301029315351502300
‑
39936162834382400400
‑
7115825277
[0077]
基于以上数据集,本发明利用由分别作为对话轮编码器和上下文编码器的两个双向gru 构成的对话轮建模模块(如图2、3),编码得到包含对话上下文信息的对话轮表示th
i
以及对话历史对应的单词向量矩阵h
k
:
[0078][0079][0080][0081][0082][0083]
wh
k,i
=w
k,i
+h
k,i
[0084][0085][0086][0087]
th
i
=th
i
+th
′
i
[0088]
分别表示低层对话轮编码器中前向gru和后向gru编码得到的对话轮t
k
中第 i个单词对应的隐藏状态,|t
k
|表示对话轮t
k
中单词的个数;表示低层对话轮编码器中的前向gru,表示低层对话轮编码器中的后向gru;h
k,i
表示对话轮t
k
中第i个单词通过双向gru编码得到的隐藏状态向量;th
k
表示低层对话轮编码器编码得到的对话轮 t
k
的向量表示;wh
k,i
表示到对话轮t
k
为止的对话历史中第i个单词经过对话轮编码器得到的向量表示;|h
k
|表示到对话轮t
k
为止的对话历史中单词的个数;w
k,i
表示到对话轮t
k
为止的对话历史中第i个单词的词嵌入表示;c
k
={th1,th2,...,th
k
}包含按顺序排列的由低层对话轮编码器得到的全部对话轮表示,k表示对话上下文中对话轮的个数;
[0089]
同上,表示高层上下文编码器中的前向gru,表示高层上下文编码器中的后向gru;分别表示高层上下文编码器中前向gru和后向gru编码得到的对话上下文中第i个对话轮对应的隐藏状态;th
′
i
表示对话上下文中第i个对话轮通过双向gru 编码得到的隐藏状态向量;th
i
表示对话上下文中第i个对话轮经过上下文编码器得到的包含了上下文信息的向量表示。
[0090]
(2)贡献感知的上下文建模过程:
[0091]
利用注意力机制,根据当前槽向量与上一步得到的全部对话轮表示计算贡献度分数,并以此作为权重将上下文中的对话轮向量表示进行加权求和得到贡献感知的上下文向量表示:
[0092]
score
i,j
=s
j
th
i
[0093][0094][0095]
其中,score
i,j
表示槽s
j
对对话轮t
i
计算的注意力分数,衡量对话轮t
i
在槽s
j
的槽值生成过程中所能做出的贡献;w
i,j
表示注意力分数score
i,j
经过softmax操作归一化后得到的结果;sc
j
表示槽s
j
特定的贡献感知的对话上下文向量表示。
[0096]
(3)生成回复
[0097]
将当前槽向量和上一步得到的当前槽特定的贡献感知的上下文向量表示分别作为解码器的初始输入和初始隐藏状态进行槽值生成。在每个时间步,利用解码器的隐藏状态分别计算对于词汇表和对话历史的概率分布,并得到关于词表的最终概率分布;
[0098]
dh
i,j
=gru(dw
i
‑
1,j
,dh
i
‑
1,j
)
[0099][0100][0101][0102][0103][0104]
其中,dh
i,j
表示在槽s
j
的解码步i中得到的解码器隐藏状态;dw
i
‑
1,j
表示在槽s
j
的解码步 i
‑
1中得到的单词预测结果;表示在槽s
j
的解码步i中计算得到的关于词汇表的概率分布;表示在槽s
j
的解码步i中计算得到的关于对话历史的概率分布;softmax表示归一化指数函数;e表示词汇表对应的单词嵌入向量矩阵;h
t
表示步骤(1)中由低层对话轮编码器得到的对话历史对应的单词向量矩阵;|v|表示词汇表中包含单词的个数;|h
t
|表示对话轮t的对话历史中包含单词的个数;表示上述两个概率分布加权合并的最终概率分布结果;
[0105]
sigmoid表示激活函数;w为待学习的参数;wd
i,j
表示在槽s
j
的解码步i中学习到的对话上下文向量。
[0106]
利用以下目标函数进行模型的训练:
[0107][0108]
其中,j表示数据集中包含域槽对的个数;|y
j
|表示在当前对话轮槽j对应的标注槽值中包含单词的个数;表示槽j对应的标注槽值中第i个单词的独热编码。
[0109]
在具体的实施过程中,该方法是基于pytorch实现的并在nvidia gpu上进行训练。提前设定了各种参数,使用glove embedding
[4]
和character
‑
wise embedding
[5]
拼接作为词嵌入向量,维度为400,编码器和解码器中的gru的隐藏层大小也被设置为400。
[0110]
使用adam
[6]
算法以0.001的初始学习率更新参数,在训练过程中,采用early
‑
stop strategy
[7]
,通过将patience设置为6,使训练过程在模型联合准确度连续6个epoch未提升之后结束。
[0111]
表2
‑
1显示了本模型(cache)、用本发明结构替换mlcsg中encoder
‑
decoder框架后的模型版本(cache+lm)以及其它基线模型(trade、comer、mlcsg)在multiwoz2.0数据集上关于两个评价指标(slot accuracy、joint accuracy)的结果。
[0112]
表2
‑
2显示了本模型(cache)、本模型的基线模型(trade)、一种最新的基于 encoder
‑
decoder框架的模型算法(mlcsg)以及将mlcsg中的encoder
‑
decoder替换为本发明结构的模型版本(cache+lm)、在multiwoz2.0测试集中不同上下文长度范围的数据上的joint accuracy结果及数据统计。
[0113]
表2
‑
1 multiwoz2.0测试集的整体结果
[0114]
modelslot accuracyjoint accuracytrade96.94%48.53%comer
‑
48.79%cache96.99%49.54%mlcsg97.18%50.72%cache+lm97.15%50.96%
[0115]
表2
‑
2 multiwoz2.0测试集中不同对话上下文长度范围的数据统计以及模型结果
[0116][0117]
表中的对比实验算法描述如下:
[0118]
trade:一种利用复制增广的encoder
‑
decoder框架从对话历史或词汇表中生成槽值的方法;
[0119]
comer:一种利用分层解码器按顺序生成对话状态中的域、槽和值的方法;
[0120]
mlcsg:一种在trade模型的基础上使用了以语言模型作为辅助任务的多任务学习
框架的方法;
[0121]
cache+lm:将mlcsg模型中的encoder
‑
decoder结构替换为本发明的模型结构后的版本;
[0122]
备注:本发明主要基于trade模型中的encoder部分进行改进,因此在实验中更加关注与trade模型在各项结果上的比较。当前有很多方法通过在encoder
‑
decoder框架的基础上添加不同功能模块结构的方式提高模型性能,本发明所提供的方法可以通过替换其中的encoder
‑
decoder结构被直接移植在这些方法中(例如移植到mlcsg模型中得到cache+lm),因此在实验中并未进行过多的比较,仅以cache+lm作为示例进行简单比较说明。
[0123]
从表2
‑
1的实验结果中可以看出,在槽准确度(slotaccuracy)方面,所有模型均取得了很好的结果,且表现非常接近,这是因为在每个对话轮中,大多数槽的值是空,这对于模型来说很容易预测,因此,我们更关注模型在联合准确度(jointaccuracy)上的表现。与trade模型相比,cache在联合准确度方面获得了1.01%的绝对提升,这说明本发明所提供方法
‑
利用分层编码器进行对话轮建模并通过注意力机制构建贡献感知的上下文表示
‑
对于对话状态追踪任务的完成很有帮助。此外,相较于mlcsg,cache+lm在联合准确度方面获得了0.24%的绝对提升,这说明本发明提供的方法移植到其他基于encoder
‑
decoder结构的对话状态追踪模型上后依然有效。
[0124]
从表2
‑
2的实验结果中可以看出,当对话上下文长度超过100个单词时,相较于trade和mlcsg,cache和cache+lm均获得了较大的提升。特别是在200
‑
299长度范围内,相较于trade,cache获得了最大3.59%的绝对提升。这说明,本发明所提供的方法,利用分层结构编码器,通过减少送入每个编码器的对话序列长度,能够有效缓解长对话上下文中较早出现的信息丢失的问题;并且,构建贡献感知的上下文表示能够帮助模型在冗长的对话上下文中关注到有用的信息。
[0125]
本发明并不限于上文描述的实施方式。以上对具体实施方式的描述旨在描述和说明本发明的技术方案,上述的具体实施方式仅仅是示意性的,并不是限制性的。在不脱离本发明宗旨和权利要求所保护的范围情况下,本领域的普通技术人员在本发明的启示下还可做出很多形式的具体变换,这些均属于本发明的保护范围之内。
[0126]
参考文献:
[0127]
[1]shany,liz,zhangj,etal.acontextualhierarchicalattentionnetworkwithadaptiveobjectivefordialoguestatetracking[c]//proceedingsofthe58thannualmeetingoftheassociationforcomputationallinguistics.2020:6322
‑
6333.
[0128]
[2]zhus,lij,chenl,etal.efficientcontextandschemafusionnetworksformulti
‑
domaindialoguestatetracking[j].arxivpreprintarxiv:2004.03386,2020.
[0129]
[3]yef,manotumruksaj,zhangq,etal.slotself
‑
attentivedialoguestatetracking[c]//proceedingsofthewebconference2021.2021:1598
‑
1608.
[0130]
[4]penningtonj,socherr,manningcd.glove:globalvectorsforwordrepresentation[c]//proceedingsofthe2014conferenceonempiricalmethodsinnaturallanguageprocessing(emnlp).2014:1532
‑
1543.
[0131]
[5]hashimotok,xiongc,tsuruokay,etal.ajointmany
‑
taskmodel:growinganeuralnetworkformultiplenlptasks[j].arxivpreprintarxiv:1611.01587,2016.
[0132]
[6]kingmadp,baj.adam:amethodforstochasticoptimization[j].arxivpreprintarxiv:1412.6980,2014.
[0133]
[7]caruanar,lawrences,gilesl.overfittinginneuralnets:backpropagation,conjugategradient,andearlystopping[j].advancesinneuralinformationprocessingsystems,2001:402
‑
408。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1