一种基于图卷积网络的两阶段行为识别细分类方法
1.本发明属于行为识别领域,具体涉及一种基于图卷积网络的两阶段行为识别细分类方法。该方法在单流行为识别分类任务上优于现有单流模型方法。
背景技术:
2.行为识别是计算机视觉领域的热点研究任务:行为识别的目标是识别出图像或视频中人的行为。基于深度学习的行为识别方法可分为基于rnn的方法、基于cnn的方法、基于gcn的方法。基于gcn的方法由于其准确率较高,成为众多研究者的选择,也是本发明采用的方法。目前,主流方法大多集中于提高行为识别模型的总体分类准确率,而大部分行为识别模型对于动作类中部分动作的错分率十分高,比如,模型难以分类高度相似的动作类别,这成为限制提高行为识别准确率的一大因素。本发明所提出的方法针对现有行为识别模型难以分类高度相似动作的问题,提出粗分类—细分类两阶段模型架构,在一定程度上缓解了高度相似动作难分类的问题,提高了行为识别的准确率,且在公开数据集上取得了较好的结果。
技术实现要素:
3.为解决现有技术存在的问题,本发明提出了一种基于图卷积网络的两阶段行为识别细分类方法。该方法是针对现有模型没有很好分类高度相似动作这一缺陷进行的改进。本发明提出的两阶段模型架构:即先进行粗分类,再根据粗分类结果进行细分类。
4.本发明主要通过再分类困难类别集中的动作类别进行行为识别,本发明的技术方案具体介绍如下。
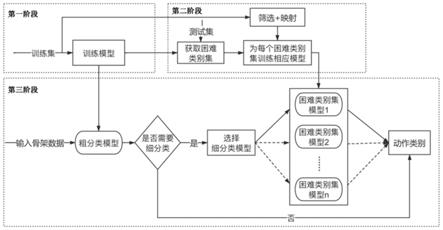
5.本发明提供一种基于图卷积网络的两阶段行为识别细分类方法,分为三个阶段进行:第一阶段:训练粗分类模型
6.训练好的粗分类模型将用于之后的两个阶段;
7.第二阶段:困难类别集的获取以及困难类别集模型的训练
8.利用粗分类模型在测试集上的混淆矩阵以及并查集算法获取困难类别集,之后分别为不同的困难类别集训练困难类别集模型,困难类别集模型的网络结构与粗分类模型的网络结构一致,训练好的模型将用于最后的在线推断阶段;
9.第三阶段:在线推断
10.根据粗分类模型的推断结果,将需要进行细分类的样本输入困难类别集模型进行推断,即再分类,推断结果即为最终的行为识别结果。
11.各个阶段的工作流程具体如下。
12.第一阶段:训练粗分类模型
13.粗分类网络由bn层、10个卷积单元(u1
‑
u10)以及全连接层组成。其中,每个卷积单元都包括空间图卷积模块和时间图卷积模块。空间图卷积模块由一个bn层和relu层组成,时间图卷积模块由两个bn层、relu层和二维卷积层组成,二维卷积的卷积核大小为1,步长
为1。其中,在第1个卷积单元(u1)、第5个卷积单元(u5)和第8个卷积单元(u8)的空间图卷积模块前加入一个改变维度的二维卷积层,二维卷积的卷积核大小为1,步长为1,并且在第5个卷积单元和第8个卷积单元加入残差块,残差块由一个二维卷积层(二维卷积的卷积核大小为1,步长为2)和一个bn层组成。
14.粗分类网络的工作流程为:首先,输入骨架序列数据(维度为n
×3×
t
×
v)到bn层,得到归一化后的骨架序列数据,之后将其依次输入到10个卷积单元中,卷积操作提取骨架序列数据的特征,对提取的特征(卷积单元110的输出维度为n
×
256
×
t
×
v)在维度t和维度v上求平均,得到维度为n
×
256的特征,最后将该特征输入到全连接层进行分类,得到动作类别。
15.整个粗分类网络涉及的输入输出维度列举如下:
16.bn层的输入维度为n
×3×
t
×
v,输出维度为n
×3×
t
×
v;
17.卷积单元u1的输入维度为n
×3×
t
×
v,输出维度为n
×
64
×
t
×
v;
18.卷积单元u2的输入维度为n
×
64
×
t
×
v,输出维度为n
×
64
×
t
×
v;
19.卷积单元u3的输入维度为n
×
64
×
t
×
v,输出维度为n
×
64
×
t
×
v;
20.卷积单元u4的输入维度为n
×
64
×
t
×
v,输出维度为n
×
64
×
t
×
v;
21.卷积单元u5的输入维度为n
×
64
×
t
×
v,输出维度为n
×
128
×
t
×
v;
22.残差块的输入维度为n
×
64
×
t
×
v,输出维度为n
×
128
×
t
×
v;
23.卷积单元u6的输入维度为n
×
128
×
t
×
v,输出维度为n
×
128
×
t
×
v;
24.卷积单元u7的输入维度为n
×
128
×
t
×
v,输出维度为n
×
128
×
t
×
v;
25.卷积单元u8的输入维度为n
×
128
×
t
×
v,输出维度为n
×
256
×
t
×
v;
26.残差块的输入维度为n
×
128
×
t
×
v,输出维度为n
×
256
×
t
×
v;
27.卷积单元u9的输入维度为n
×
256
×
t
×
v,输出维度为n
×
256
×
t
×
v;
28.卷积单元u10的输入维度为n
×
256
×
t
×
v,输出维度为n
×
256
×
t
×
v;
29.全连接层的输入维度为n
×
256,输出维度为n
×
60;
30.其中,t为输入骨架序列的帧数;v=25为人体关节点数;n为样本数量。
31.粗分类网络在训练过程中将保存准确率最高的模型m,用于第三阶段中的在线测试。
32.第二阶段:困难类别集的获取以及困难类别集模型的训练
33.一、困难类别集的获取
34.困难类别集指模型容易混淆分类的动作类别标签的集合。困难类别集的获取分为两步,首先,输入测试集到粗分类模型m进行推断,得到测试集上的混淆矩阵。其次,根据混淆矩阵获取困难类别集其中,s
ib
指困难类别集s
i
中的第b个动作类标签,n
si
为s
i
中包含的动作类别标签个数。具体操作分为2步:
35.1)计算混淆率矩阵r。对于给定的混淆矩阵c,(c
ij
∈c,1<=i,j<=n
c
,n
c
是模型m分类的动作类别数量),混淆率矩阵r的计算公式如下,其中,r
ij
∈r,i≠j,是r的第i行第j列,指模型m推断错误的样本数占该类别总数的比例。c
ij
∈c是混淆矩阵c的第i行第j列,表示模型m将真实标签i推断为j的样本个数;
[0036][0037]
2)使用经典并查集算法,得到困难类别集s
i
。具体操作为:首先,初始化n
c
个集合{0},{1},...,{i},...,{n
c
‑
1},集合{i}代表相应的真实动作类别标签,之后根据第1)步计算得到的混淆率矩阵r合并n
c
个集合,合并操作具体为:若r
ij
的值大于阈值θ,则将i所在的集合与j所在的集合合并,得到新的集合;初始时,即合并集合{i}与集合{j}得到集合{i,j},之后的合并操作,以此类推,直至遍历完混淆率矩阵r。最终保留的集合即为困难类别集其中所有满足条件n
si
>=2的困难类别集构成类别集n
s
为s中困难类别集的个数。
[0038]
二、困难类别集模型的训练
[0039]
困难类别集模型的训练分为困难样本集的获取和模型训练两个部分:
[0040]
步骤一,困难样本集的获取,又可细分为数据的筛选和标签的映射两个部分。首先,数据的筛选即根据获取到的困难类别集得到困难样本集l。困难样本集为数据集中动作类标签属于s
i
中动作标签的样本的集合,为数据集中动作类标签为s
ib
的样本集合,构建l的过程即为数据的筛选过程。标签的映射是指将困难类别集中动作标签为s
ib
的类别映射为b
‑
1,具体表述为:将s
i
映射到集合映射后的动作类别标签集困难样本集l中的标签映射与s
i
的映射相同,映射后的困难样本集l
b
为l中动作类标签为s
ib
的样本集合。困难样本集ma
l
即为困难类别集模型的训练集;
[0041]
步骤二,为每个困难类别集s
i
训练相应的困难类别集模型。模型的网络结构与阶段1中粗分类模型的网络结构基本一致,二者不同之处在于,粗分类模型中全连接层的输出维度为n
×
60,也即粗分类模型是60分类模型,而困难类别集模型是q分类模型,全连接层的输出维度为n
×
q,q为相应困难类别集s
i
包含的类别数,即q=n
si
。模型的输入训练数据为步骤一中获得的相应的困难样本集ma
l
。阶段2最终训练得到细分类模型集a,a
i
为困难类别集s
i
对应的困难类别集模型,n
s
为困难类别集的个数。
[0042]
第三阶段:在线推断
[0043]
在线推断的流程分为三个步骤:
[0044]
步骤一,粗分类模型m的推断:输入骨架序列数据x={x1,x2,...,x
t
}到阶段1中训练好的粗分类模型m,得到推断标签p;
[0045]
步骤二,选择困难类别集模型a
i
:判断粗分类模型m的推断标签p是否需要细分类,判断的逻辑为:若类别集s中存在s
i
,使得p在集合s
i
里,则需要细分类,将进一步选择s
i
所属的困难类别集模型a
i
,进入步骤三;反之,则p即为最终的动作分类结果;
[0046]
步骤三,困难类别集模型a
i
的推断:将推断标签p对应的x输入到困难类别集模型中进行进一步推断,得到推断标签p
*
。对p
*
进行逆映射,最终分类结果即为
[0047]
与现有技术相比,本发明的有益效果在于:
[0048]
通过对高度相似的动作类别即困难类别进行再分类,使得细分类模型专注于困难类别间的特殊特征,而粗分类模型更关注动作类的一般特征,两阶段的模型架构更全面更充分的挖掘了特征信息,从而提高了行为识别模型的准确率。作为网络基础的卷积单元包含空间图卷积和时间图卷积两个部分,其中空间图卷积部分关注单个骨架各关节之间的联系,时间图卷积关注骨架序列中相邻骨架的联系,这种空间图卷积和时间图卷积分离的设计能够更好地解耦骨架序列空间、时间特征提取的过程。此外,串联多个卷积单元,能够扩大卷积的感受野,更好地提取骨架序列的全局、长距离特征,从而提高行为识别的准确率。
附图说明
[0049]
图1是本发明所提的一种基于图卷积的两阶段行为识别细分类方法的流程图。
[0050]
图2是本发明所提方法的具体网络结构。
具体实施方式
[0051]
以下结合附图和实施例对本发明的技术方案进行详细阐述。
[0052]
一种基于图卷积网络的两阶段行为识别细分类方法,其具体流程如图1所示,主要分为三个阶段,第一阶段:训练粗分类模型,粗分类模型的网络结构如图2所示。训练好的粗分类模型m将用于之后的两个阶段。第二阶段:困难类别集的获取以及困难类别集模型的训练。利用模型m在测试集上的混淆矩阵以及并查集算法获取困难类别集,之后分别为不同的困难类别集训练困难类别集模型,模型的网络结构如图2所示。训练好的模型将用于最后的在线推断阶段。第三阶段:在线推断。根据粗分类模型m的推断结果,将需要进行细分类的样本输入困难类别集模型进行推断,推断结果即为最终的行为识别结果。
[0053]
实施例1
[0054]
本发明提出的一种基于图卷积网络的两阶段行为识别细分类方法,在公开数据集ntu
‑
rgb+d 60上进行了实验,并和当前主流方法的结果进行对比。按照主流做法,实验在x
‑
sub和x
‑
view两个benchmark上进行,使用top1作为评价指标。本实施例中仅使用单流数据(关节数据)进行实验,且仅与单流模型进行实验结果对比。
[0055]
本发明的实验参数设置为:
[0056]
本发明的实验环境为:处理器为intel(r)xeon(r)cpu e5
‑
2603 v4@1.70ghz,显卡为nvidia titan xp 12gb,内存64gb,操作系统为ubuntu 16.04(64位),编程语言为python3.7.4,深度学习框架为pytorch1.2.0。
[0057]
在模型的训练和测试过程中,使用连续的300帧的人体骨架关节数据作为输入,即t=300。在训练过程中,采用sgd优化器,学习率设置为0.1,每隔50个轮次将学习率缩小10倍,批次大小设置为64,总计训练200个轮次。粗分类模型m的分类样本数量n
c
=60。在获取困难类别集时,阈值θ=0.1。
[0058]
在本实施例中,获取到三个困难类别集s1={9,33},s2={5,15,16},s3={10,11,28,29},其对应的动作类别如表1所示,以s2为例,从动作骨架上来看,捡东西、穿鞋、脱鞋没有很大的区分性,因此粗分类模型同大多数主流方法一样,容易错分高度相似的动作类别,为提高准确率,需对其进行再分类。最终得到的实验结果如表2所示,可以看出,本发明所提
方法在两个benchmark上的指标均优于既有方法,证实了本发明所提的两阶段行为识别细分类方法的有效性。
[0059]
表1困难类别集对应的动作
[0060]
困难类别集动作{9,33}{鼓掌,摩擦双手}{5,15,16}{捡东西,穿鞋,脱鞋}{10,11,28,29}{阅读,写字,玩手机,敲键盘}
[0061]
表2基于ntu
‑
rgb+d 60数据集上的对比结果
[0062]
方法名称x
‑
subx
‑
viewst
‑
gcn[1]81.588.31s shift
‑
gcn[2]87.895.1本发明所提方法89.495.5
[0063]
参考文献
[0064]
[1]sijie yan,yuanjun xiong,and dahua lin.spatial temporal graph convolutional networks for skeleton
‑
based action recognition.in thirty
‑
second aaai conference on artificial intelligence,2018
[0065]
[2]k.cheng,y.zhang,x.he,w.chen,j.cheng and h.lu.skeleton
‑
based action recognition with shift graph convolutional network.2020ieee/cvf conference on computer vision and pattern recognition(cvpr),2020。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1