一种基于分布式搜索引擎的区块链查询方法和存储介质与流程
1.本发明涉及区块链领域,具体涉及一种基于分布式搜索引擎的区块链查询方法和存储介质。
背景技术:
2.近年来,区块链技术随着比特币在投资市场的火热而被大家所熟知。从技术上来说,区块链本质上是存储数据记录的一种方式
‑
链式存储。从应用上来说,区块链是通过密码学的方式形成一个由集体维护的分布式账本。因此,区块链具有不可篡改、去中心化、全程留痕、可溯源、公开透明的特性。基于这些特性,区块链技术应用越来越广泛,而查询浏览作为每个应用最基本的操作,对系统的响应速度也提出了很高的要求。原生的区块链查询接口实现逻辑为每次查询都需遍历整条区块链,当上链数据越来越多的时候,查询的效率也越来越慢。同时由于区块链是基于文件系统的key
‑
value形式存储进行存储的,存储的数据之间没有传统关系型数据库的强关联关系,这使得原生区块链查询接口对复杂查询逻辑和特定查询条件的支持存在不足。
3.为解决这个问题,现行的解决方式是在区块链原有的架构体系中,部署关系型数据库,将链上数据下链到数据库中,实现一种区块链混合架构,通过查询关系型数据库来提高查询效率,满足应用的性能需求。然而,对于使用关系型数据库的方式来解决原生区块链查询功能和性能不足的问题,存在以下的缺点:关系型数据库通常是中心化的,与区块链去中心化的初衷背道而驰,容易在应用中造成单点故障,关系型数据库在达到亿级数据后,查询效率同样低下,通过将区块链数据全部下链到关系型数据库中,额外存储负担较重。
技术实现要素:
4.为解决现有技术存在的问题,本发明提供了一种基于分布式搜索引擎的区块链查询方法和存储介质。为实现本发明的目的,本发明的技术方案如下。
5.一种基于分布式搜索引擎的区块链查询方法,包括:
6.将文件写入区块链中;其中,所述文件包括文件id和文件内容;
7.对文件进行分词;
8.基于文件分词结果建立倒排索引,以使得文件分词结果的每个元素与文件id建立映射关系;
9.将倒排索引进行分片处理,以使得文件分词结果的每个元素与分片的编号建立映射关系;
10.搜索引擎根据输入的条件,在存储节点上查找匹配的文件内容。
11.优选的,对每个分片建立多个副本,且每个副本分布在不同的存储节点上,以使得分片损坏或丢失时可以从副本中恢复。
12.优选的,输入的条件包括文件分词结果的单词、词组或语句。
13.一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时使处理器执
行上述的方法。
14.相对于现有技术,本发明的有益技术效果在于:本发明的方法通过将文件写入区块链后,引入搜索引擎对文件进行分词,基于文件分词结果建立倒排索引,将倒排索引进行分片处理,进而可通过搜索引擎根据输入的条件获得符合条件的文件id,通过文件id在存储节点上查找匹配的文件内容。本发明通过引入分布式搜索引擎来替代关系型数据库,彻底解决区块链查询功能和效率的问题,同时因仅存储索引,减轻了额外的存储负担。
附图说明
15.为了更清楚地说明本技术实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本技术的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
16.图1为基于分布式搜索引擎的区块链查询方法流程图。
具体实施方式
17.为使本技术实施例的目的、技术方案和优点更加清楚,下面将结合本技术实施例中附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。
18.实施例一
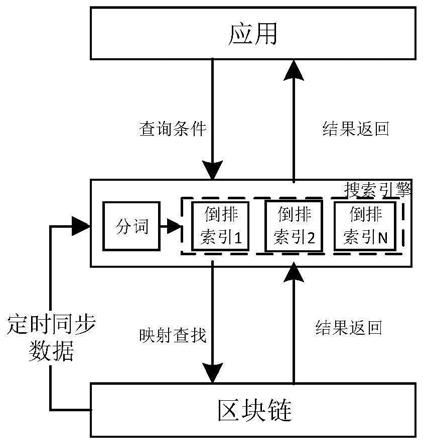
19.如图1所示,本实施例的基于分布式搜索引擎的区块链查询方法通过引入分布式搜索引擎,替换关系型数据库作为应用层和区块链的中间层,实现区块链的快速查询,本实施例的基于分布式搜索引擎的区块链查询方法同通过搜索引擎定时同步区块链中的最新数据,通过分词器对数据进行分词处理。搜索引擎建立分词与对应数据的倒排索引,并存储在搜索引擎中。搜索引擎响应应用层的查询需求,根据倒排索引定位区块链的数据并返回查询结果。
20.其中,倒排索引是相对于正排索引而言的。正排索引是以记录的文件id作为关键字,记录文件对应搜索词的形式。示例的如下表:
[0021][0022]
当搜索苹果时,正排索引则遍历文件id1
‑
4,最后查找出文件id1和2。这种搜索随着文件数量的增加,需要遍历的量也随之增加,效率较低。为了提升索引速度,将上表的对应关系进行转换,采用分词结果对应文件id的方式,形成倒排索引。示例的如下表:
[0023][0024]
当搜索苹果时,不用遍历整个结果,直接在倒排索引中找到苹果对应的文件1和2,极大提升了效率。
[0025]
分词是把文件内容转换成一系列单词的过程。分词器是专门处理分词的组件,主要由分词规则和单词加工组成。分词规则是分词时遵照的规则,如按空格、词典、去除数字等规则。单词加工是将切分的单词进行加工,如大写转小写,繁体转简体,同义词或形同词等。例如,“i love eat apple!”,经过分词器处理,形成i,love,eat,apple四个单词。中文的“我喜欢吃苹果!”,通过分词器处理,形成我,喜欢,吃、苹果四个单词。
[0026]
在实际应用中,搜索引擎可能遇到较多的同时查询的要求,为了降低单服务器的压力、提高整体查询效率、防范单点故障发生,搜索引擎支持部署在多个服务器上,实现索引分布式存储。搜索引擎通过将一个索引拆分成多个分片,分布到不同节点。通过对索引的分片进行精确复制,形成多个副本,分布在不同的节点上,提高系统的容错性。当某个节点某个分片损坏或丢失时可以从副本中恢复。例如:在上文倒排索引中,苹果对应存放在1,2号文件中,其索引分布式存储步骤如下:搜索引擎先将索引(苹果,(1,2))分片,拆解成分片1(苹果,1)和分片2(苹果,2);复制分片1和分片2,形成两个副本并分布存储到不同节点上。
[0027]
具体地,以区块链中已经写入如下文件为例:
[0028]
文件id文件内容1苹果和西瓜2香蕉和苹果3西瓜和葡萄4荔枝和西瓜
[0029]
本实施例的基于分布式搜索引擎的区块链查询方法包括:
[0030]
步骤1:搜索引擎定时同步区块链中的新写入文件,通过分词器对文件1和文件2进行分词,得到文件1
‑
4的分词结果;
[0031][0032]
步骤2:建立文件1
‑
4分词结果的倒排索引;
[0033][0034]
步骤3:将索引进行分片处理;
[0035][0036][0037]
步骤4:对索引分片建立多个副本(通常为2个),并分布在多个存储节点上;
[0038][0039]
至此搜索引擎已完成文件1
‑
4的处理。
[0040]
在业务进行查询时,搜索引擎根据输入的条件,在节点上进行匹配,如搜索苹果,则直接在节点1上搜索到文件1和文件2,于是就返回苹果对应的文件1和文件2的内容。
[0041]
实施例二
[0042]
一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时使处理器执行实施例一的方法。
[0043]
以上所述实施例,仅为本技术的具体实施方式,用以说明本技术的技术方案,而非对其限制,本技术的保护范围并不局限于此,尽管参照前述实施例对本技术进行了详细的说明,本领域的普通技术人员应当理解:任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,其依然可以对前述实施例所记载的技术方案进行修改或可轻易想到变化,或者对其中部分技术特征进行等同替换;而这些修改、变化或者替换,并不使相应技术方案的本质脱离本技术实施例技术方案的精神和范围。都应涵盖在本技术的保护范围之内。因此,本技术的保护范围应以所述权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1