1.本发明涉及大数据的市场分析技术领域,具体为一种基于大数据的市场分析方法。
背景技术:2.大数据(big data),或称巨量资料,指的是所涉及的资料量规模巨大到无法透过目前主流软件工具,在合理时间内达到撷取、管理、处理、并整理成为帮助企业经营决策更积极目的的资讯。
3.但是现有的大数据在进行预处理时,通常是将数据从一种格式转换为另一种格式、通过删除冗余特征来消除多余数据等,但是这些方法通常考虑不够周全,无法彻底消除数据质量问题。
技术实现要素:4.(一)解决的技术问题
5.针对现有技术的不足,本发明提供了一种基于大数据的市场分析方法,解决了传统的大数据在进行预处理时不便对多余数据进行彻底消除的问题。
6.(二)技术方案
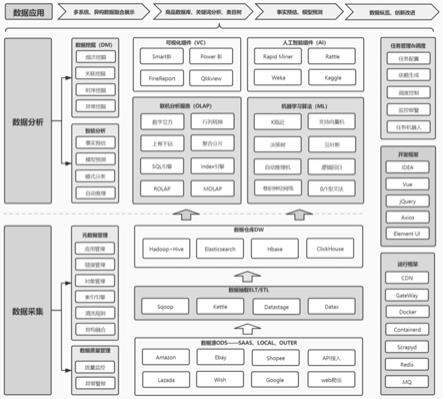
7.为实现以上目的,本发明通过以下技术方案予以实现:一种基于大数据的市场分析方法,包括品类分析市场、技术架构和创新模式,所述品类分析市场由类目初步筛选和类目报告详情筛选组成,所述创新模式由大数据预处理与质量控制、商品匹配算法、大数据挖掘技术、大数据可视分析技术和大数据决策支持技术组成。
8.优选的,所述类目初步筛选操作方法如下:
9.a.打开大数据展示系统并定位到amazon接口数据》类目搜索页面;
10.b.选择1级类目,点击查看叶子类目的平均排名趋势图,找出排名上升的叶子类目;
11.c.点击“类目分析”进入该叶子类目下的商品top100商品详情统计页面,点击“top100链接”可以进入到该叶子类目的销售排行榜。
12.优选的,所述类目报告详情筛选操作方法如下:
13.a.点击“类目列表”选项卡,选择类目结构查看类目top100详细报告。
14.b.点击“详情”即可生成一份针对该叶子类目市场的分析报告,其分析报告内容如下5点组成,分别为:品牌数据展示、品牌集中度、卖家类型分布、评分值分布和价格分布。
15.优选的,所述技术架构主要由数据采集、数据存储、数据分析和网络服务组成,其中:
16.a.数据采集:主要通过web爬虫和api的方式接入数据,利用sqoop、kettle、datastage、datax四种工具进行数据抽取;
17.b.数据存储:主要由hive+hdfs、elasticsearch、hbase、clickhouse这4个组件;
18.c.数据分析:主要由数据挖掘和智能分析两个方面,其中智能分析方面提供了smartbi等可视化组件和index引擎等联机分析服务;
19.d.网络服务:采用的是cdn进行分发,在用户访问相对集中的地区或网络采用更多的缓存服务器(cdn边缘节点)。
20.优选的,所述大数据挖掘技术主要由文本大数据挖掘、视频图像数据挖掘和大规模并行数据的挖掘组成。
21.优选的,所述大数据决策支持技术主要由以下4点组成,分别是:
22.a.面向多源异构数据源的知识图谱构建和融合;
23.b.海量知识数据的存储和查询等数据管理;
24.c.智能知识检索和分析;
25.d.知识图谱的构建和分析的基础上。
26.有益效果
27.本发明提供了一种基于大数据的市场分析方法。具备以下有益效果:
28.(1)、该基于大数据的市场分析方法,通过生成一份针对该叶子类目市场的分析报告,然后依次观看生成后报告中的品牌数据展示、品牌集中度、卖家类型分布、评分值分布和价格分布,其通过品牌数据展示,可以直观看到展示该类目下前5产品的核心流量词最近排名走势,该指标可以判断该市场的淡旺季、市场趋势,通过观看品牌集中度,可以清楚的看见头部品牌在类目中,占比越高,品牌的垄断程度越高,或用户对品牌的关注程度越高,通过卖家类型分布,可以清楚的看见样本范围内,左右侧纵坐标按卖家类型分布的商品数量和评论数占比;该指标可以帮助寻找合适的发货方式,以及方便判断来自amazon自营的竞争影响程度,通过评分值分布,可以观看到该月不同评分值区间的商品分布情况,柱体表示商品数量,曲线表示该区间商品评论数与总评论数的占比情况,每个区间代表着一类细分产品,通过平均值比较各区间的优劣势会更加直观,还有观察该类目下商品,被市场的认可的程度,以及评分值的分布情况,如分值高的商品占比较大,说明现有商品被认可程度高,该市场较为成熟分值低的商品占比大,说明商品存在较大可改进空间,工厂型卖家,最后通过观看价格分布,可以展示出该月不同价格的商品分布情况,柱体表示该价格区间内商品数量,曲线表示该价格区间商品的评论数与总评论数的占比情况。每个区间代表着一类细分产品,比如单价$5和单价$50的产品面向的是不同的购买人群,通过平均值比较各区间的优劣势会更加直观。
29.(2)、该基于大数据的市场分析方法,通过对于技术架构上,数据采集方面,通过web爬虫和api的方式接入数据,利用sqoop、kettle、datastage、datax四种工具进行数据抽取。其中sqoop主要用于在hadoop+hive与传统的数据库(如mysql)之间的数据传递。kettle工具主要用于结构化数据全量抽取或增量标识的数据增量抽取、复制和迁移,它以一种指定的格式流出,数据抽取高效稳定。datastage为整个etl过程提供了一个图形化的开发环境。datax主要用于异构数据源之间高效的数据同步。数据存储方面,包括hive+hdfs、elasticsearch、hbase、clickhouse这4个组件。hive+hdfs在提供分布式数据仓库和离线计算服务。clickhouse提供即使查询和多维汇总计算能力。elasticsearch结合hbase提供分布式关系数据库服务,用于海量结构化的数据存储。数据分析方面,包括数据挖掘和智能分析两个方面。其中智能分析方面提供了smartbi等可视化组件和index引擎等联机分析服
务。用于数据自助分析和报表可视化展示。数据挖掘利用了人工智能组件和机器学习算法,对数据样本进行泛化,预测未来“出现”的数据和解释之前从未“见过”的数据。网络服务方面,使用cdn进行分发,在用户访问相对集中的地区或网络采用更多的缓存服务器(cdn边缘节点),当用户访问网站时,利用全局负载技术,将用户的访问指向距离最近的缓存服务器上,由缓存服务器响应用户请求,缩短用户的等待时间。
30.(3)、该基于大数据的市场分析方法,通过大数据预处理与质量控制,时通过在对数据清洗的过程中加入了异常点检测的功能,从而实现数据质量监控和异常报警;在数据变换的过程中,采用了归一化、缺失值处理、特征选择等方法,针对不同特征的异常数据采取不同的预处理方法。在对在大数据挖掘技术方面,主要关注文本、视频图像等数据类型的处理,以及大规模并行数据的挖掘。在对文本大数据挖掘时,使用深度语义分析、大规模高精度文本知识挖掘、语义搜索引擎来实现文本数据挖掘。其中语义搜索引擎可以实现规模化、定制化地采集多个网址、网页和文档信息,通过构建语义索引,自动汇聚,从而筛选出有价值的信息。在对视频图像数据挖掘时,是基于人工智能、机器学习等技术,对海量视频图像数据的特性进一步扩展与增强现有的模型和算法,并在公开的数据集上评测其性能。实现图像分类、图像快速索引、视频语义标注等问题的突破。在对大规模并行数据的挖掘时,是利用分布式数据的特点,结合多样的存储和计算环境,采用云计算的数据模型、分布式数据挖掘算法(包括分类算法、关联规则算法等),对大规模并行数据进行挖掘。在可视分析技术的目标是使数据分析过程透明化。它结合了可视化、人机交互和自动分析技术。传统的数据分析任务主要是针对单个或者一类数据进行的分析,随着大数据的出现,各式各样具有隐性相关关系的数据涌现出来。例如:在一些复杂任务中,往往需要同时对不同类别的数据进行采集、监控、分析以及响应。最后面在向大数据的决策支持技术主要包括4个方面的内容:一是面向多源异构数据源的知识图谱构建和融合,将不同的数据源的数据进行有效的整合,形成面向一个领域或者开放领域的完备的知识图谱;二是海量知识数据的存储和查询等数据管理,一个面向海量知识数据的高效的知识图谱数据管理系统是提供知识服务和支撑上层决策的基础;三是智能知识检索和分析,为用户提供一种基于可视化技术的、交互式的知识数据访问和分析的平台接口,方便普通用户使用知识图谱;四是在上述知识图谱的构建和分析的基础上,针对复杂的问题提出定性定量综合集成建模体系,从而有效支持相关决策。
附图说明
31.图1为本发明整体技术架构结构示意图;
32.图2为本发明大数据预处理与质量控制结构示意图;
33.图3为本发明商品匹配算法流程结构示意图;
34.图4为本发明大数据可视分析技术结构示意图;
35.图5为本发明大数据决策支持技术结构示意图。
具体实施方式
36.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
37.请参阅图1-5,本发明提供一种技术方案:一种基于大数据的市场分析方法,包括品类分析市场、技术架构和创新模式,品类分析市场由类目初步筛选和类目报告详情筛选组成,所述创新模式由大数据预处理与质量控制、商品匹配算法、大数据挖掘技术、大数据可视分析技术和大数据决策支持技术组成。
38.本实施例中,类目初步筛选操作方法如下:
39.a.打开大数据展示系统并定位到amazon接口数据》类目搜索页面;
40.b.选择1级类目,点击查看叶子类目的平均排名趋势图,找出排名上升的叶子类目;
41.c.点击“类目分析”进入该叶子类目下的商品top100商品详情统计页面,点击“top100链接”可以进入到该叶子类目的销售排行榜
42.本实施例中,类目报告详情筛选操作方法如下:
43.a.点击“类目列表”选项卡,选择类目结构查看类目top100详细报告。
44.b.点击“详情”即可生成一份针对该叶子类目市场的分析报告,其分析报告内容如下5点组成,分别为:品牌数据展示、品牌集中度、卖家类型分布、评分值分布和价格分布。
45.本实施例中,技术架构主要由数据采集、数据存储、数据分析和网络服务组成,其中:
46.a.数据采集:主要通过web爬虫和api的方式接入数据,利用sqoop、kettle、datastage、datax四种工具进行数据抽取;
47.b.数据存储:主要由hive+hdfs、elasticsearch、hbase、clickhouse这4个组件;
48.c.数据分析:主要由数据挖掘和智能分析两个方面,其中智能分析方面提供了smartbi等可视化组件和index引擎等联机分析服务;
49.d.网络服务:采用的是cdn进行分发,在用户访问相对集中的地区或网络采用更多的缓存服务器(cdn边缘节点)。
50.本实施例中,大数据挖掘技术主要由文本大数据挖掘、视频图像数据挖掘和大规模并行数据的挖掘组成。
51.本实施例中,大数据决策支持技术主要由以下4点组成,分别是:
52.a.面向多源异构数据源的知识图谱构建和融合;
53.b.海量知识数据的存储和查询等数据管理;
54.c.智能知识检索和分析;
55.d.知识图谱的构建和分析的基础。
56.工作时,当后期需要观看大数据时,首先生成一份针对该叶子类目市场的分析报告,然后依次观看生成后报告中的品牌数据展示、品牌集中度、卖家类型分布、评分值分布和价格分布,其通过品牌数据展示,可以直观看到展示该类目下前5产品的核心流量词最近排名走势,该指标可以判断该市场的淡旺季、市场趋势,通过观看品牌集中度,可以清楚的看见头部品牌在类目中,占比越高,品牌的垄断程度越高,或用户对品牌的关注程度越高,通过卖家类型分布,可以清楚的看见样本范围内,左右侧纵坐标按卖家类型分布的商品数量和评论数占比;该指标可以帮助寻找合适的发货方式,以及方便判断来自amazon自营的竞争影响程度,通过评分值分布,可以观看到该月不同评分值区间的商品分布情况,柱体表示商品数量,曲线表示该区间商品评论数与总评论数的占比情况,每个区间代表着一类细
分产品,通过平均值比较各区间的优劣势会更加直观,还有观察该类目下商品,被市场的认可的程度,以及评分值的分布情况,如分值高的商品占比较大,说明现有商品被认可程度高,该市场较为成熟分值低的商品占比大,说明商品存在较大可改进空间,工厂型卖家,最后通过观看价格分布,可以展示出该月不同价格的商品分布情况,柱体表示该价格区间内商品数量,曲线表示该价格区间商品的评论数与总评论数的占比情况。每个区间代表着一类细分产品,比如单价$5和单价$50的产品面向的是不同的购买人群,通过平均值比较各区间的优劣势会更加直观。
57.在对于技术架构上,数据采集方面,通过web爬虫和api的方式接入数据,利用sqoop、kettle、datastage、datax四种工具进行数据抽取。其中sqoop主要用于在hadoop+hive与传统的数据库(如mysql)之间的数据传递。kettle工具主要用于结构化数据全量抽取或增量标识的数据增量抽取、复制和迁移,它以一种指定的格式流出,数据抽取高效稳定。datastage为整个etl过程提供了一个图形化的开发环境。datax主要用于异构数据源之间高效的数据同步。数据存储方面,包括hive+hdfs、elasticsearch、hbase、clickhouse这4个组件。hive+hdfs在提供分布式数据仓库和离线计算服务。clickhouse提供即使查询和多维汇总计算能力。elasticsearch结合hbase提供分布式关系数据库服务,用于海量结构化的数据存储。数据分析方面,包括数据挖掘和智能分析两个方面。其中智能分析方面提供了smartbi等可视化组件和index引擎等联机分析服务。用于数据自助分析和报表可视化展示。数据挖掘利用了人工智能组件和机器学习算法,对数据样本进行泛化,预测未来“出现”的数据和解释之前从未“见过”的数据。网络服务方面,使用cdn进行分发,在用户访问相对集中的地区或网络采用更多的缓存服务器(cdn边缘节点),当用户访问网站时,利用全局负载技术,将用户的访问指向距离最近的缓存服务器上,由缓存服务器响应用户请求,缩短用户的等待时间。
58.但是在对于大数据预处理与质量控制,时通过在对数据清洗的过程中加入了异常点检测的功能,从而实现数据质量监控和异常报警;在数据变换的过程中,采用了归一化、缺失值处理、特征选择等方法,针对不同特征的异常数据采取不同的预处理方法。
59.在对在大数据挖掘技术方面,主要关注文本、视频图像等数据类型的处理,以及大规模并行数据的挖掘。在对文本大数据挖掘时,使用深度语义分析、大规模高精度文本知识挖掘、语义搜索引擎来实现文本数据挖掘。其中语义搜索引擎可以实现规模化、定制化地采集多个网址、网页和文档信息,通过构建语义索引,自动汇聚,从而筛选出有价值的信息。在对视频图像数据挖掘时,是基于人工智能、机器学习等技术,对海量视频图像数据的特性进一步扩展与增强现有的模型和算法,并在公开的数据集上评测其性能。实现图像分类、图像快速索引、视频语义标注等问题的突破。在对大规模并行数据的挖掘时,是利用分布式数据的特点,结合多样的存储和计算环境,采用云计算的数据模型、分布式数据挖掘算法(包括分类算法、关联规则算法等),对大规模并行数据进行挖掘。
60.在可视分析技术的目标是使数据分析过程透明化。它结合了可视化、人机交互和自动分析技术。传统的数据分析任务主要是针对单个或者一类数据进行的分析,随着大数据的出现,各式各样具有隐性相关关系的数据涌现出来。例如:在一些复杂任务中,往往需要同时对不同类别的数据进行采集、监控、分析以及响应。
61.最后面在向大数据的决策支持技术主要包括4个方面的内容:一是面向多源异构
数据源的知识图谱构建和融合,将不同的数据源的数据进行有效的整合,形成面向一个领域或者开放领域的完备的知识图谱;二是海量知识数据的存储和查询等数据管理,一个面向海量知识数据的高效的知识图谱数据管理系统是提供知识服务和支撑上层决策的基础;三是智能知识检索和分析,为用户提供一种基于可视化技术的、交互式的知识数据访问和分析的平台接口,方便普通用户使用知识图谱;四是在上述知识图谱的构建和分析的基础上,针对复杂的问题提出定性定量综合集成建模体系,从而有效支持相关决策。
62.需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。