搜索结果分类模型的训练方法、装置、介质及设备与流程
1.本技术涉及人工智能技术领域,具体涉及一种搜索结果分类模型的训练方法、装置、介质及设备。
背景技术:
2.人工智能(ai,artificial intelligence)是计算机科学的一个综合技术,通过研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。人工智能技术是一门综合学科,涉及领域广泛,例如自然语言处理、机器学习、深度学习等几大方向。随着技术的发展,人工智能技术将在更多的领域得到应用,并发挥越来越重要的价值。
3.随着词向量嵌入表示技术的发展,文本预训练模型越来越成为众多自然语言处理任务及其上游应用场景的基础模块。如在搜索引擎中,通过预训练语言模型对用户输入的搜索查询词和候选的搜索结果的内容进行嵌入表示,根据向量之间的相似度确定搜索查询词和候选的搜索结果之间的相关性。目前这种语言模型可以较好捕捉句法和语义词汇的关系,但不满足搜索场景下搜索查询词与搜索结果相似度也要匹配的需求。
技术实现要素:
4.为了满足搜索结果与搜索查询词相似度更匹配的需求,本技术提供了一种搜索结果分类模型的训练方法、装置、介质及设备。所述技术方案如下:
5.第一方面,本技术提供了一种搜索结果分类模型的训练方法,所述方法包括:
6.获取训练数据集,所述训练数据集包括搜索查询词以及与所述搜索查询词对应的搜索结果;
7.基于目标文本匹配算法,确定所述搜索查询词和所述搜索结果的相似度;
8.根据预设的分类区间和所述相似度确定样本的分类标签,所述样本包括所述搜索查询词和所述搜索结果;
9.根据所述样本和对应的所述分类标签对预训练后的语言模型进行微调,得到搜索结果分类模型。
10.第二方面,本技术提供了一种搜索结果分类模型的训练装置,所述装置包括:
11.数据获取模块,用于获取训练数据集,所述训练数据集包括搜索查询词以及与所述搜索查询词对应的搜索结果;
12.相似度计算模块,用于基于目标文本匹配算法,确定所述搜索查询词和所述搜索结果的相似度;
13.分类标签确定模块,用于根据预设的分类区间和所述相似度确定样本的分类标签,所述样本包括所述搜索查询词和所述搜索结果;
14.模型微调模块,用于根据所述样本和对应的所述分类标签对预训练后的语言模型进行微调,得到搜索结果分类模型。
15.第三方面,本技术提供了一种计算机可读存储介质,所述计算机可读存储介质中
存储有至少一条指令或至少一段程序,所述至少一条指令或至少一段程序由处理器加载并执行以实现如第一方面所述的一种搜索结果分类模型的训练方法。
16.第四方面,本技术提供了一种计算机设备,所述计算机设备包括处理器和存储器,所述存储器中存储有至少一条指令或至少一段程序,所述至少一条指令或至少一段程序由所述处理器加载并执行以实现如第一方面所述的一种搜索结果分类模型的训练方法。
17.第五方面,本技术提供了一种计算机程序产品,所述计算机程序产品包括计算机指令,所述计算机指令被处理器执行时实现如第一方面所述的一种搜索结果分类模型的训练方法。
18.本技术提供的搜索结果分类模型的训练方法、装置、介质及设备,具有如下技术效果:
19.本技术提供的方案通过文本匹配算法计算搜索查询词与搜索结果的相似度,并基于相似度和预设的分档区间确定样本的分类标签,该样本包括搜索查询词和对应的搜索结果;进而通过样本和样本的分类标签对已有的预训练语言模型进行微调,获得搜索结果分类模型,并可以将该搜索结果分类模型应用于搜索应用,使得获得的搜索结果与搜索查询词在相似度维度上更为匹配,进一步满足用户的搜索需求,提升用户体验。具体地,在文本匹配算法中对bm25公式进行了改写,增加了语素覆盖率等因子,对语素权重、语素与搜索结果相似度的计算进行了改进,使得文本匹配算法更关注搜索查询词与搜索结果在内容上的相似度,以满足模型应用需求。此外,相比于从头开始训练模型,采用对预训练后的语言模型进行微调的训练方法可以减少所需的训练数据量,也节省了模型训练成本,提高了模型训练效率。
20.本技术的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本技术的实践了解到。
附图说明
21.为了更清楚地说明本技术实施例或现有技术中的技术方案和优点,下面将对实施例或现有技术描述中所需要使用的附图作简单的介绍,显而易见地,下面描述中的附图仅仅是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它附图。
22.图1是本技术实施例提供的一种语义模型训练方法的实施环境示意图;
23.图2是本技术实施例提供的一种语义模型训练方法的流程示意图;
24.图3是本技术实施例提供的一种确定搜索查询词与搜索结果相似度的流程示意图;
25.图4是本技术实施例提供的一种确定语素与搜索结果相似度的流程示意图;
26.图5是本技术实施例提供的一种确定语素的权重的流程示意图;
27.图6是本技术实施例提供的另一种确定搜索查询词与搜索结果相似度的流程示意图;
28.图7是本技术实施例提供的一种对语言模型进行微调的流程示意图;
29.图8是本技术实施例提供的一种确定文本特征的流程示意图;
30.图9是本技术实施例提供的另一种对语言模型进行微调的流程示意图;
31.图10是本技术实施例提供的一种搜索结果分类模型的训练装置的示意图;
32.图11是本技术实施例提供的用于实现一种搜索结果分类模型的训练方法的设备的硬件结构示意图。
具体实施方式
33.人工智能(artificial intelligence,ai)是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、操作/交互系统、机电一体化等技术。
34.本技术实施例提供的方案涉及人工智能的深度学习(deep learning,dl)、自然语言处理(nature language processing,nlp)等技术。
35.深度学习(deep learing,dl)是机器学习(machine learning,ml)领域中一个主要的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能。深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术。深度学习在搜索技术、数据挖掘、机器学习、机器翻译、自然语言处理、多媒体学习、语音、推荐和个性化技术,以及其他相关领域都取得了很多成果。深度学习使机器模仿视听和思考等人类的活动,解决了很多复杂的模式识别难题,使得人工智能相关技术取得了很大进步。
36.自然语言处理(nature language processing,nlp)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系。自然语言处理技术通常包括文本处理、语义理解、机器翻译、机器人问答、知识图谱等技术。
37.本技术实施例提供的方案可部署在云端,其中还涉及云技术等。
38.云技术(cloud technology):是指在广域网或局域网内将硬件、软件及网络等系列资源统一起来,实现数据的计算、储存、处理和共享的一种托管技术,也可理解为基于云计算商业模式应用的网络技术、信息技术、整合技术、管理平台技术及应用技术等的总称,可以组成资源池,按需所用,灵活便利。技术网络系统的后台服务需要大量的计算、存储资源,如视频网站、图片类网站和更多的门户网站,伴随着互联网行业的高度发展和应用,将来每个物品都有可能存在自己的识别标志,都需要传输到后台系统进行逻辑处理,不同程度级别的数据将会分开处理,各类行业数据皆需要强大的系统后盾支撑,因此云技术需要以云计算作为支撑。云计算是一种计算模式,它将计算任务分布在大量计算机构成的资源
池上,使各种应用系统能够根据需要获取计算力、存储空间和信息服务。提供资源的网络被称为“云”。“云”中的资源在使用者看来是可以无限扩展的,并且可以随时获取,按需使用,随时扩展,按使用付费。作为云计算的基础能力提供商,会建立云计算资源池平台,简称云平台,一般称为基础设施即服务(iaas,infrastructure as a service),在资源池中部署多种类型的虚拟资源,供外部客户选择使用。云计算资源池中主要包括:计算设备(可为虚拟化机器,包含操作系统)、存储设备和网络设备。
39.为了满足搜索结果与搜索查询词相似度匹配的需求,本技术实施例提供了搜索结果分类模型的训练方法、装置、介质及设备。下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本技术保护的范围。所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。
40.需要说明的是,本技术的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本技术的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或服务器不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
41.为了便于理解本技术实施例所述的技术方案及其产生的技术效果,本技术实施例对于涉及到的相关专业名词进行解释:
42.bert:bidirectional encoder representation from transformers,基于转换器的双向编码表示;是一个预训练的语言表征模型。
43.word2vec:word to vector,是用来一群产生词向量的相关模型,如词袋模型(bag-of-words model)、跳字模型(skip-gram)等。这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系。
44.tf-idf:term frequency
–
inverse document frequency,是一种用于信息检索与数据挖掘的常用加权技术。tf(term frequency)是词频,idf(inverse document frequency)是逆文档频率指数。
45.bm25:(bm,best matching),源于概率相关模型,是基于tf-idf改进的文本匹配算法,被称为下一代的tf-idf。
46.fine-tuning:可称为微调,是指在已经训练好的语言模型的基础上,加入少量的任务特定参数,例如对于分类问题在语言模型基础上加一层softmax网络,然后在新的语料上重新训练来完成微调。
47.请参阅图1,其为本技术实施例提供的一种搜索结果分类模型的训练方法的实施环境示意图,如图1所示,该实施环境可以至少包括客户端01和服务器02。
48.具体的,所述客户端01可以包括智能手机、台式电脑、平板电脑、笔记本电脑、车载
终端、数字助理、智能可穿戴设备、监控设备及语音交互设备等类型的设备,也可以包括运行于设备中的软体,例如一些服务商提供给用户的网页页面,也可以为该些服务商提供给用户的应用。具体的,所述客户端01可以用于针对搜索应用搜集所需的训练数据集,所述训练数据集可以包括搜索查询词以及与搜索查询词对应的搜索结果,可以通过历史搜索日志中获取。
49.具体的,所述服务器02可以是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、cdn(content delivery network,内容分发网络)以及大数据和人工智能平台等基础云计算服务的云服务器。所述服务器02可以包括有网络通信单元、处理器和存储器等等。终端以及服务器可以通过有线或无线通信方式进行直接或间接地连接,本技术在此不做限制。具体的,所述服务器02可以用于响应于客户端01的请求,获取训练数据集,并基于预设的目标文本匹配算法计算搜索查询词与搜索结果的相似度,并根据相似度对搜索结果分类,从而确定样本的分类标签,样本是搜索查询词与搜索结果的组合,最后通过样本和样本的分类标签对预训练后的语言模型进行微调,获得满足搜索场景下相似度需求的搜索结果分类模型。
50.本技术实施例还可以结合云技术实现,云技术(cloud technology)是指在广域网或局域网内将硬件、软件及网络等系列资源统一起来,实现数据的计算、储存、处理和共享的一种托管技术,也可理解为基于云计算商业模式应用的网络技术、信息技术、整合技术、管理平台技术及应用技术等的总称。云技术需要以云计算作为支撑。云计算是一种计算模式,它将计算任务分布在大量计算机构成的资源池上,使各种应用系统能够根据需要获取计算力、存储空间和信息服务。提供资源的网络被称为“云”。具体地,所述服务器02和数据库位于云端,所述服务器02可以是实体机器,也可以是虚拟化机器。
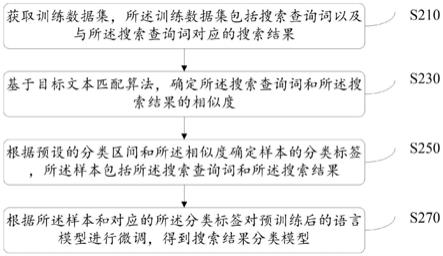
51.以下介绍本技术提供的一种搜索结果分类模型的训练方法。图2是本技术实施例提供的一种搜索结果分类模型的训练方法的流程图,本技术提供了如实施例或流程图所述的方法操作步骤,但基于常规或者无创造性的劳动可以包括更多或者更少的操作步骤。实施例中列举的步骤顺序仅仅为众多步骤执行顺序中的一种方式,不代表唯一的执行顺序。在实际中的系统或服务器产品执行时,可以按照实施例或者附图所示的方法顺序执行或者并行执行(例如并行处理器或者多线程处理的环境)。请参照图2,本技术实施例提供的一种搜索结果分类模型的训练方法可以包括如下步骤:
52.s210:获取训练数据集,所述训练数据集包括搜索查询词以及与所述搜索查询词对应的搜索结果。
53.可以理解的是,与搜索查询词对应的可以有多个搜索结果,由多个搜索结果构成与搜索查询词对应的搜索结果集。在本技术实施例中,以搜索查询词和对应的一个搜索结果作为一个训练样本,用于训练的数据均为历史数据。
54.s230:基于目标文本匹配算法,确定所述搜索查询词和所述搜索结果的相似度。
55.可以理解的是,目前的无监督预训练语言模型本质是一种基于神经网络的词嵌入技术,可以较好地捕捉句法和语义词汇的关系。预训练模型通过上下文学习单词的向量表示,实际就是要得到跟当前单词经常在相关语境中出现的词有哪些。如“北京”和“上海”这两个词在海量语料上下文中会经常一起出现,故其预训练模型所表达的向量相似度会标
高,从语义角度理解没有问题,但在搜索场景下,如果一个用户搜索“北京”,出“上海”相关的搜索结果则只是相关但并不相似的,即相关≠相似。从以上分析看现有预训练语言模型更强调词的上下文语境相关度,不适合搜索这类更强调query(搜索查询词)和doc(文档,或引申为搜索结果)相似度匹配的场景。
56.在本技术实施例中,通过计算搜索查询词与搜索结果的相似度,确定训练样本的分类标签,以对预训练后的语言模型进行调整,满足搜索场景下的需求。其中,所谓相似度与相关性不等同,本技术中的相似度更强调内容本身的相似,如搜索查询词为“背景”,则需要显示的搜索结果都是指向北京的信息。
57.在本技术实施例中,目标文本匹配算法用于计算搜索词和搜索结果在文本内容上的相似度,具体地,目标文本匹配算法可以为传统的字符匹配规则、bm25算法、jaccard相似度算法、余弦相似度算法等中的任一一种。
58.示例性的,可以采用传统的字符匹配规则计算搜索查询词和搜索结果的相似度,具体地,如果搜索结果为网页、文章等,可以计算搜索查询词与搜索结果的文本内容之间的相似度,文本内容可以是标题或者正文;如果搜索结果为图片、音频、视频等媒体资源,可以计算搜索查询词与搜索结果的标题之间的相似度。
59.示例性的,考虑到在搜索查询词与标题的相似度计算场景下,往往标题长度较短,且不同命中词的逆文档频率值的权重不同,故可以采用bm25算法计算相似度。bm25算法通常用来作搜索相关性评分,其主要思想是:对query(搜索查询词)进行语素解析,生成语素qi,然后对于搜索结果d,计算每个语素qi与d的相关性得分,最后,将qi与d的相关性得分进行加权求和,从而得到query与d的相关性得分。具体地,常用的bm25公式如公式(1)所示:
[0060][0061]
在公式(1)中的q表示query,也即用户输入的搜索查询词;s表示文档,在本技术中其即为当前文档的标题,在其他如视频搜索、图片搜索等的应用场景中,s也可以表示搜索结果的标题;idf(qi)表示q中第i个词qi的逆文档频率值,在公式(1)中作为了qi与d的相关性得分对应的权重;tf(qi)表示query q中第i个词qi的词频;length(s)表示当前文档标题的长度,avglength(s)表示对应的多个文档的标题平均长度;参数b的作用主要是调节文本标题长度对相似度的影响,k是针对词频的调节因子,如可以将k设置为2,b设置为0.75。
[0062]
基于上述公式(1),对bm25算法进行改进,增加了语素覆盖率等因子,对语素权重、语素与搜索结果相似度的计算进行了改进,语素覆盖率可以表征内容上的重合程度,使得计算结果更能体现相似度而不是相关性。
[0063]
在本技术的一个实施例中,具体地,如图3所示,所述步骤s230可以包括以下步骤:
[0064]
s310:对所述搜索查询词进行语素解析,确定所述搜索查询词中的一个或多个目标语素。
[0065]
具体地,对搜索查询词进行语素解析一般是做分词处理,得到目标语素组成的序列q1、q2......qn。在本技术实施例中,目标语素也被称为命中词。
[0066]
在一个示例性的实施方式中,对于英文文本,可以利用空格对文本进行分隔。对于中文文本,主要有两类方式:基于词典的分词算法和基于统计的分词算法,其中,基于词典
的分词算法本质上是字符串匹配,基于一定的匹配策略将待匹配的中文文本和一个词典进行字符串匹配,如果匹配成功则可以按匹配结果分词;基于统计的分词算法,本质上是一个序列标注问题,基于统计概率按照字在文本中的位置对其进行标注,得到中文文本的序列标注结果,进而根据序列标注结果对中文文本进行分词。
[0067]
s330:基于目标文本匹配算法,确定每个所述目标语素与所述搜索结果的目标相似度。
[0068]
在一种可行的实施方式中,如图4所示,在所述搜索查询词对应多个搜索结果的情况下,所述步骤s330可以包括以下步骤:
[0069]
s331:确定所述目标语素在多个搜索结果中的词频。
[0070]
具体地,多个搜索结果可作为一个搜索结果集,所述词频表征目标语素出现在搜索结果集中各搜索结果的标题中的次数。此外,若针对目标语素和搜索结果(如文档)的正文内容弄进行相似度的计算,词频可以是单个搜索结果中该目标语素出现的频数。针对词频可以根据具体的应用类别或业务需求适应性定义计算公式,此处不做赘述。
[0071]
s333:确定所述搜索查询词的第一词量和所述搜索结果的标题的第二词量;所述搜索结果是所述多个搜索结果中的任意一个。
[0072]
具体地,将搜索查询词中的目标语素的个数作为第一词量,将搜索结果的标题也做分词处理,得到的词的个数作为第二词量。
[0073]
s335:根据所述词频、所述第一词量和所述第二词量,得到所述目标语素与所述搜索结果的目标相似度。
[0074]
示例性的,目标语素qi与搜索结果s的目标相似度计算可以如公式(2)所示:
[0075][0076]
其中,tf(qi)表示目标语素qi在多个搜索结果中的词频,length(q)表示query中分词后的词个数,也即第一词量,length(s)表示搜索结果s的标题词个数,也即第二词量,引入参数b以调节s的标题长度对目标相似度的影响,引入参数k以调节词频tf(qi)对目标相似度的影响,如可以将k设置为2,b设置为0.75。
[0077]
s350:确定每个所述目标语素的归一化语素权重。
[0078]
在一种可行的实施方式中,利用目标语素的逆文档频率值来计算其权重,并对权重做归一化处理,使得数值可以落入一个相对的范围内,具体地,在所述搜索查询词对应多个搜索结果的情况下,如图5所示,所述步骤s350可以包括以下步骤:
[0079]
s351:确定每个所述目标语素在所述多个搜索结果中的逆文档频率值。
[0080]
具体地,以搜索结果为文档为例,idf的计算公式可以为公式(3)所示:
[0081][0082]
其中,n表示搜索结果集中搜索结果的个数,n(qi)也即标题中出现了该目标语素的搜索结果的个数。
[0083]
可选的,idf的计算公式还可以为公式(4)所示:
[0084][0085]
其中,分式中分子和分母中的0.5主要是用于做平滑处理。
[0086]
s353:根据每个所述目标语素的逆文档频率值,得到各所述目标语素的逆文档频率值之和。
[0087]
s355:根据每个所述目标语素的逆文档频率值与所述逆文档频率值之和,得到每个所述目标语素的归一化语素权重。
[0088]
具体地,将每个目标语素的逆文档频率值与逆文档频率值之和作商,得到的数值作为每个目标语素对应的归一化语素权重。
[0089]
s370:根据每个所述目标语素的归一化语素权重以及每个所述目标语素与所述搜索结果的目标相似度,确定所述搜索查询词与所述搜索结果的相似度。
[0090]
在一种可行的实施方式中,在语素与搜索结果的相似度的计算中,对公式(1)中avglength(s)改为了搜索查询词的词量,也增加了语素在搜索查询词和搜索结果的标题中的覆盖率,以使得计算结果更强调内容上的相似。具体地,如图6所示,所述步骤s370可以包括以下步骤:
[0091]
s371:确定所述一个或多个目标语素在所述搜索查询词中的第一占比。
[0092]
如上所述,目标语素也可以称为命中词。
[0093]
s373:确定所述一个或多个目标语素在所述搜索结果的标题中的第二占比。
[0094]
s375:根据所述第一占比、所述第二占比以及每个所述目标语素对应的目标相似度和归一化语素权重,确定所述搜索查询词与所述搜索结果的相似度。
[0095]
示例性的,以搜索结果为文档为例,改进后的bm25算法如公式(5)所示:
[0096][0097]
在公式(5)中的q表示query,也即用户输入的搜索查询词;s表示文档,在本技术中其即为当前文档的标题,在其他如视频搜索、图片搜索的应用场景中,s也可以表示搜索结果的标题;query_cover(q,s)表示命中词个数占query中所有词个数的比例,也即第一占比;sen_cover(q,s)表示命中词个数占标题中所有词的个数比例,也即第二占比;tf(qi)表示命中词qi在搜索结果合集中的词频;idf(qi)表示目标语素(也即命中词)qi在搜索结果合集中的idf值(即逆文档频率值);length(s)表示标题中词个数,也即第二词量;length(q)表示query中词个数,也即第一词量;表示qi与s的相似度得分,表示qi的归一化语素权重。此外参数b的作用主要是调节文本标题长度
对相似度性的影响,k针对词频的调节因子。
[0098]
经过公式(5)可以计算出query和当前文档标题的相似度分数,一般来说该分数取只为0~1之间,越小代表越不相似,越接近1则代表越相似。
[0099]
s250:根据预设的分类区间和所述相似度确定样本的分类标签,所述样本包括所述搜索查询词和所述搜索结果。
[0100]
在本技术的一个实施例中,基于前述位于0~1范围的相似度分数,可以根据人工经验或业务需求设定相应的区间划分规则,如可以将相似度分为3档,以便于构建后续预训练分类器模型,如:
[0101]
[0~0.3):表示不太相似;
[0102]
[0.3~0.6):表示一般相似;
[0103]
[0.6~1]:表示很相似。
[0104]
s270:根据所述样本和对应的所述分类标签对预训练后的语言模型进行微调,得到搜索结果分类模型。
[0105]
在本技术实施例中,预训练后的语言模型指通过大量样本数据训练后的通用型语言模型,为了使模型满足特定业务需求,常用特定业务相关的少量样本数据再次进行训练,从而对模型参数做适当调整。具体地,将样本输入至预训练后的语言模型,根据模型输出结果和样本对应的分类标签计算损失函数,继而根据损失函数对预训练后的语言模型的参数进行适当调整,得到最终的搜索结果分类模型。
[0106]
在本技术实施例中,搜索结果分类模型可以应用于搜索引擎中,以精确计算用户当前输入的搜索查询词与数据库中该搜索查询词对应的候选搜索结果的相似度,从而对候选搜索结果进行分类,将相似度高的一类候选搜索结果作为最终的搜索结果并提供给用户,进一步满足用户的实际搜索需求,提升用户的搜索体验。
[0107]
在本技术的一个实施例中,对预训练后的语言模型中最后一层分类网络进行微调,实现更加适用于特定业务的分类功能。
[0108]
在一种可行的实施方式中,具体地,如图7所示,所述可以包括以下步骤:
[0109]
s710:基于所述语言模型中的第一语言子模型对所述样本中的搜索查询词进行特征提取,得到第一文本特征。
[0110]
s730:基于所述语言模型中的第二语言子模型对所述样本中的搜索查询词进行特征提取,得到第二文本特征。
[0111]
第一语言子模型和第二语言子模型可以均采用bert模型或者均采用word2vec模型,以对文本特征进行提取。
[0112]
s750:根据所述第一文本特征和所述第二文本特征得到第三文本特征。
[0113]
在一种可行的实施方式中,特征提取后得到的文本特征在数据类型上表现为向量,具体地,如图8所示,所述步骤s750可以包括以下步骤:
[0114]
s751:根据所述第一文本特征和所述第二文本特征,得到文本差异特征。
[0115]
具体地,第一语言子模型对搜索查询词进行特征提取,输出第一特征向量,该第一特征向量表征搜索查询的第一文本特征,第二语言子模型对搜索查询词进行特征提取,输出第二特征向量,该第二特征向量表征搜索查询的第二文本特征,第一特征向量和第二特征向量在维度上相同,故可以将第一特征向量和第二特征向量作差,得到特征差异向量,该
特征差异向量用于表征文本差异特征,在向量维度上,该特征差异向量也与第一特征向量、第二特征向量相同。
[0116]
s753:将所述第一文本特征、所述第二文本特征和所述文本差异特征进行拼接,得到第三文本特征。
[0117]
具体地,将第一特征向量、第二特征向量和特征差异向量进行拼接(也即维度数增加),合并成表征第三文本特征的第三特征向量。
[0118]
s770:将所述第三文本特征输入至所述语言模型中的输出层,得到所述第三文本特征对应的预测分类标签。
[0119]
s790:根据所述预测分类标签和对应的所述分类标签对所述语言模型进行微调,得到搜索结果分类模型。
[0120]
示例性的,如图9所示,原始预训练语言模型模型可以采用bert,也可以采用word2vec模型,分别对搜索查询词query和文档标题title两个句子做初始化预训练向量表示,然后取bert输出的分类池化层(classification pooling,可简称为cls pooling)得到相应的第一特征向量u和第二特征向量v,然后把u、v与|u-v|拼接为第三特征向量向量(u-v表示u和v两个向量的差异),再给到输出层(也即分类器softmax classifier)进行分类。此处的分类标签可以为前述的三分类下的分类标签。通过预测的分类标签和真实的分类标签微调(fine-tuning)模型(主要是分类器),可以使文本相似度较高的句子在模型中表现为向量将更为接近,而文本相似度低的句子之间其向量之间更远。可选的,bert模型内部包括很多层转换器(transformer),除了从cls pooling层提取向量外,也可以取第一层transformer和最后一层transformer输出的向量做平均形成u和v。
[0121]
本技术实施例还提供了一种搜索结果分类模型的训练装置1000,如图10所示,所述装置1000可以包括:
[0122]
数据获取模块1010,用于获取训练数据集,所述训练数据集包括搜索查询词以及与所述搜索查询词对应的搜索结果;
[0123]
相似度计算模块1020,用于基于目标文本匹配算法,确定所述搜索查询词和所述搜索结果的相似度;
[0124]
分类标签确定模块1030,用于根据预设的分类区间和所述相似度确定样本的分类标签,所述样本包括所述搜索查询词和所述搜索结果;
[0125]
模型微调模块1040,用于根据所述样本和对应的所述分类标签对预训练后的语言模型进行微调,得到搜索结果分类模型。
[0126]
在本技术的一个实施例中,所述相似度计算模块1020可以包括:
[0127]
语素解析单元,用于对所述搜索查询词进行语素解析,确定所述搜索查询词中的一个或多个目标语素;
[0128]
语素相似度计算单元,用于基于目标文本匹配算法,确定每个所述目标语素与所述搜索结果的目标相似度;
[0129]
语素权重确定单元,用于确定每个所述目标语素的归一化语素权重;
[0130]
相似度计算单元,用于根据每个所述目标语素的归一化语素权重以及每个所述目标语素与所述搜索结果的目标相似度,确定所述搜索查询词与所述搜索结果的相似度。
[0131]
在本技术的一个实施例中,所述语素相似度计算单元可以包括:
[0132]
词频确定子单元,用于在与所述搜索查询词对应的搜索结果集包括一个或多个搜索结果的情况下,确定所述目标语素在所述搜索结果集中的词频;
[0133]
词量确定子单元,用于确定所述搜索查询词的第一词量和所述搜索结果的标题的第二词量;
[0134]
目标相似度计算子单元,用于根据所述词频、所述第一词量和所述第二词量,得到所述目标语素与所述搜索结果的目标相似度。
[0135]
在本技术的一个实施例中,所述语素权重确定单元可以包括:
[0136]
逆文档频率值确定子单元,用于在与所述搜索查询词对应的搜索结果集包括一个或多个搜索结果的情况下,确定每个所述目标语素在所述搜索结果集中的逆文档频率值;
[0137]
求和子单元,用于根据每个所述目标语素的逆文档频率值,得到各所述目标语素的逆文档频率值之和;
[0138]
归一化语素权重确定子单元,用于根据每个所述目标语素的逆文档频率值与所述逆文档频率值之和,得到每个所述目标语素的归一化语素权重。
[0139]
在本技术的一个实施例中,所述相似度计算单元可以包括:
[0140]
第一覆盖率确定子单元,用于确定所述一个或多个目标语素在所述搜索查询词中的第一占比;
[0141]
第二覆盖率确定子单元,用于确定所述一个或多个目标语素在所述搜索结果的标题中的第二占比;
[0142]
相似度计算子单元,用于根据所述第一占比、所述第二占比以及每个所述目标语素对应的目标相似度和归一化语素权重,确定所述搜索查询词与所述搜索结果的相似度。
[0143]
在本技术的一个实施例中,所述模型微调模块1040可以包括:
[0144]
第一特征提取单元,用于基于所述语言模型中的第一语言子模型对所述样本中的搜索查询词进行特征提取,得到第一文本特征;
[0145]
第二特征提取单元,用于基于所述语言模型中的第二语言子模型对所述样本中的搜索查询词进行特征提取,得到第二文本特征;
[0146]
第三特征确定单元,用于根据所述第一文本特征和所述第二文本特征得到第三文本特征;
[0147]
模型预测单元,用于将所述第三文本特征输入至所述语言模型中的输出层,得到所述第三文本特征对应的预测分类标签;
[0148]
微调单元,用于根据所述预测分类标签和对应的所述分类标签对所述语言模型进行微调,得到搜索结果分类模型。
[0149]
需要说明的是,上述实施例提供的装置,在实现其功能时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将设备的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的装置与方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。
[0150]
本技术实施例提供了一种计算机设备,该计算机设备包括处理器和存储器,该存储器中存储有至少一条指令或至少一段程序,该至少一条指令或该至少一段程序由该处理器加载并执行以实现如上述方法实施例所提供的一种搜索结果分类模型的训练方法。
[0151]
图11示出了一种用于实现本技术实施例所提供的一种搜索结果分类模型的训练方法的设备的硬件结构示意图,所述设备可以参与构成或包含本技术实施例所提供的装置或系统。如图11所示,设备10可以包括一个或多个(图中采用1002a、1002b,
……
,1002n来示出)处理器1002(处理器1002可以包括但不限于微处理器mcu或可编程逻辑器件fpga等的处理装置)、用于存储数据的存储器1004、以及用于通信功能的传输装置1006。除此以外,还可以包括:显示器、输入/输出接口(i/o接口)、通用串行总线(usb)端口(可以作为i/o接口的端口中的一个端口被包括)、网络接口、电源和/或相机。本领域普通技术人员可以理解,图11所示的结构仅为示意,其并不对上述电子装置的结构造成限定。例如,设备10还可包括比图11中所示更多或者更少的组件,或者具有与图11所示不同的配置。
[0152]
应当注意到的是上述一个或多个处理器1002和/或其他数据处理电路在本文中通常可以被称为“数据处理电路”。该数据处理电路可以全部或部分的体现为软件、硬件、固件或其他任意组合。此外,数据处理电路可为单个独立的处理模块,或全部或部分的结合到设备10(或移动设备)中的其他元件中的任意一个内。如本技术实施例中所涉及到的,该数据处理电路作为一种处理器控制(例如与接口连接的可变电阻终端路径的选择)。
[0153]
存储器1004可用于存储应用软件的软件程序以及模块,如本技术实施例中所述的方法对应的程序指令/数据存储装置,处理器1002通过运行存储在存储器1004内的软件程序以及模块,从而执行各种功能应用以及数据处理,即实现上述的一种搜索结果分类模型的训练方法。存储器1004可包括高速随机存储器,还可包括非易失性存储器,如一个或者多个磁性存储装置、闪存、或者其他非易失性固态存储器。在一些实例中,存储器1004可进一步包括相对于处理器1002远程设置的存储器,这些远程存储器可以通过网络连接至设备10。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
[0154]
传输装置1006用于经由一个网络接收或者发送数据。上述的网络具体实例可包括设备10的通信供应商提供的无线网络。在一个实例中,传输装置1006包括一个网络适配器(networkinterfacecontroller,nic),其可通过基站与其他网络设备相连从而可与互联网进行通讯。在一个实例中,传输装置1006可以为射频(radiofrequency,rf)模块,其用于通过无线方式与互联网进行通讯。
[0155]
显示器可以例如触摸屏式的液晶显示器(lcd),该液晶显示器可使得用户能够与设备10(或移动设备)的用户界面进行交互。
[0156]
本技术实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质可设置于服务器之中以保存用于实现方法实施例中一种搜索结果分类模型的训练方法相关的至少一条指令或至少一段程序,该至少一条指令或该至少一段程序由该处理器加载并执行以实现上述方法实施例提供的一种搜索结果分类模型的训练方法。
[0157]
可选地,在本实施例中,上述存储介质可以位于计算机网络的多个网络服务器中的至少一个网络服务器。可选地,在本实施例中,上述存储介质可以包括但不限于:u盘、只读存储器(rom,read-only memory)、随机存取存储器(ram,random access memory)、移动硬盘、磁碟或者光盘等各种可以存储程序代码的介质。
[0158]
本发明实施例还提供了一种计算机程序产品或计算机程序,所述计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计
算机设备执行上述各种可选实施方式中提供的一种搜索结果分类模型的训练方法。
[0159]
由上述本技术提供的搜索结果分类模型的训练方法、装置、介质及设备的实施例可见,
[0160]
本技术提供的方案通过文本匹配算法计算搜索查询词与搜索结果的相似度,并基于相似度和预设的分档区间确定样本的分类标签,该样本包括搜索查询词和对应的搜索结果;进而通过样本和样本的分类标签对已有的预训练语言模型进行微调,获得搜索结果分类模型,并可以将该搜索结果分类模型应用于搜索应用,使得获得的搜索结果与搜索查询词在相似度维度上更为匹配,进一步满足用户的搜索需求,提升用户体验。具体地,在文本匹配算法中对bm25公式进行了改写,增加了语素覆盖率等因子,对语素权重、语素与搜索结果相似度的计算进行了改进,使得文本匹配算法更关注搜索查询词与搜索结果在内容上的相似度,以满足模型应用需求。此外,相比于从头开始训练,采用对预训练后的语言模型进行微调的训练方法可以减少所需的训练数据量,也节省了模型训练成本,提高了模型训练效率。
[0161]
需要说明的是,微调是一种训练方式,是指在通过大量训练数据训练过的模型的基础上(此时的模型为通用型的,一般已开源),再利用与特定业务相关的一部分训练数据再对模型进行训练,使其更适合特定业务的需求,故一般只需要进行第二轮训练,实验证明也只需少量的特定训练数据就能使模型性能满足特定业务的需求;且训练数据量的减少,可以缩短训练时间,降低模型训练成本,从而提高了模型训练效率。
[0162]
上述本技术实施例先后顺序仅仅为了描述,不代表实施例的优劣。且上述对本技术特定实施例进行了描述。其它实施例在所附权利要求书的范围内。在一些情况下,在权利要求书中记载的动作或步骤可以按照不同于实施例中的顺序来执行并且仍然可以实现期望的结果。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
[0163]
本技术中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于装置、设备和存储介质实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
[0164]
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
[0165]
以上所述仅为本技术的较佳实施例,并不用以限制本技术,凡在本技术的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本技术的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1