一种面向百科数据的作战事件抽取方法
1.本发明属于自然语言处理的技术领域,涉及面向百科数据的作战事件抽取方法,以百科文本的作战事件抽取为问题出发点。
背景技术:
2.当今我国的军队建设已经进入信息化时代,军队信息化建设需要解决的一个重要问题是智能决策。指挥员在快节奏、高强度的对抗环境下,难以在有限时间内充分分析战局的各种可能情况,导致方案制定不精确、时效性不满足实际作战要求(根据战役规模,持续数月不等)、战时各种风险考虑不够全面等问题。当前主要依靠人定性研判,难以量化指标,急需智能决策系统辅助指挥员进行“精算”和“妙算”。而通过分析大量的历史军事作战事件,自动从中学习作战决策的规律成为了实现智能决策系统的重要途径。因此,抽取大量的军事作战事件以及它们之间的关联关系成为构建智能决策系统的基础工作。百科数据中存储着大量的历史战役数据,利用自然语言处理技术从中自动抽取大量作战事件将为后续智能决策系统的构建提供数据基础。
技术实现要素:
3.通过对相关百科数据的分析,发现作战事件相关的军事实体(装备、作战单位等)的后缀具有明显特点;包含军事实体的句子中更容易产生作战事件等特点。针对上述特征,本发明提供一个面向百科数据的作战事件抽取方法,其中通过后缀特征的引入提高军事实体抽取效果;利用识别出的军事实体,通过引入军事实体信息注意力机制提高作战事件触发词的抽取效果。
4.为了实现上述目的,本发明提出一种面向百科数据的军事事件抽取方法,包括步骤:
5.(1)军事实体抽取:
6.对于输入的一段百科文本数据,识别出其中存在的军事实体(装备、作战单位、作战任务、战役名称等)。军事实体的后缀具有较明显的特点,而且重复率较高。例如,装备实体后缀包含:“战斗机”、“舰”等等;作战单位实体的后缀包括:“营”、“旅”、“中队”等等。如果一段文本描述以上述后缀结尾,该文本属于军事实体的可能性较高。因此,提出了后缀特征,提升军事实体识别的准确率。
7.首先,通过人工分析与总结,构建军事实体后缀库。利用该后缀库,识别出输入句子中包含的所有后缀。对于输入的句子中每个字符,首先生成对应的后缀特征向量,即表示该字符是否属于某个后缀。然后,将产生的后缀特征与将句子输入到bert产生的字向量拼接,生成完整特征向量。最后,将拼接向量输入到bi
‑
gru+crf模型进行实体识别,标记出一个句子中存在的相关军事实体。抽取得到的军事实体将作为后续事件触发词识别中注意力机制提供参考信息。
8.其中,bert模型是由谷歌团队在自然语言处理顶会naacl
‑
hlt 2019上发表的论文
成果(bert:pre
‑
training of deep bidirectional transformers for language understanding)。bert被广泛应用到大量自然语言处理任务中,用于生成包含上下文信息的向量表示。本方法利用bert模型得到输入句子中每个字对应的包含上下文信息的向量表示。bi
‑
gru+crf模型是经典的序列标注模型,在2019年《活力与指挥控制》期刊、第44卷、第9期发表的论文成果(基于bi
‑
gru
‑
crf模型的中文分词法)中,用于解决中文分词问题。本方法中利用bi
‑
gru+crf方法对输入的bert向量进行处理,标记出输入句子中的军事实体。
9.(2)事件触发词抽取:
10.包含军事实体的句子中更容易产生作战事件,即作战事件的描述往往需要武器装备、作战单位等军事实体的参与;对此,本发明提出了基于军事实体信息注意力机制的事件触发词抽取方法。
11.首先,将句子依次输入到bert模型和bi
‑
gru模型,生成包含丰富信息的特征向量。
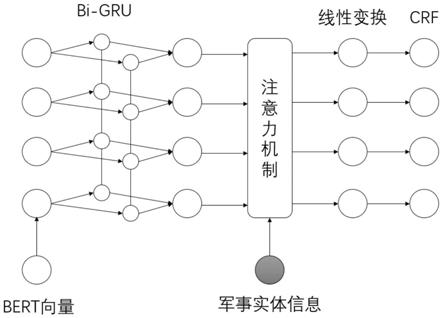
12.对于军事实体及特征向量,利用军事实体注意力机制生成对军事实体的注意力权重;利用对军事实体的注意力权重与特征向量进行相乘,得到军事实体注意力权重的特征向量;即与军事实体相关性较高的输入将在后续作战事件触发词识别任务中具有较高的权重,被正确识别的可能性更高。
13.军事实体注意力机制的计算过程如下式所示:
[0014][0015]
其中,q
mei
(mei,military entity information)为军事实体注意力权重的特征向量,k和v为输入文本经过bert和bi
‑
gru的计算得到的特征向量,d
k
为k向量的维度。可以看出,每个字对应的特征向量与该句子中包含的军事实体向量q
mei
进行内积计算相似度。然后除以实现归一化,保证梯度的稳定性。最后利用softmax得到注意力权重。
[0016]
最后,将军事实体注意力权重的特征向量输入到crf模型完成军事作战事件触发词的识别。
[0017]
优选的是,所述后缀特征由所述输入的句子与后缀库比对生成,所述后缀库由人工标注百科语料的方法建立。
[0018]
优选的是,所述军事实体的类型包括装备、任务、单位和战争名称。
[0019]
优选的是,所述步骤(2)中,所述k向量与所述v向量是相同的特征向量。
[0020]
本发明的有益效果如下:
[0021]
与现有技术相比,本发明能够使面向百科数据的作战事件抽取方法适应百科文本中的军事事件抽取,通过后缀特征和军事实体注意力机制的引入,分别在军事实体识别和事件触发词抽取任务上提升2%和1.3%的f
‑
值。
[0022]
本发明的方法可以应用于军事作战事理图谱构建等多个领域,利用该方法产生的作战事件数据为作战规律分析、智能作战决策系统研发提供数据支持。
附图说明
[0023]
图1为本发明军事实体抽取模型结构图。
[0024]
图2为本发明军事实体抽取中后缀特征生成示意图。
[0025]
图3为本发明事件触发词抽取模型结构图。
[0026]
图4为本发明事件触发词抽取中实体信息生成示意图。
具体实施方式
[0027]
下面结合附图和实施例详细说明本发明的实施方式。
[0028]
通过图1~4,对本发明的设计思路进行简要说明。
[0029]
图1为本发明军事实体抽取模型结构图。抽取过程如下:
[0030]
首先,对大量军事实体中常见的“装备”、“任务”、“单位”、“战争名称”等四种类型军事实体构建后缀库。然后,对于每个输入句子生成相应的后缀特征。后缀特征的抽取过程如图2所示,将句子与后缀库进行字符串匹配,利用匹配结果生成对应后缀特征。句子中每个字将用4维0
‑
1向量表示后缀特征,4个维度分别表示4种实体类型,当某个字出现在某种类型实体后缀中,则对应维度置为1,否则置为0。之后,将后缀特征与bert字向量进行拼接输入到具体模型中。模型自下而上分别经过双向gru层、自注意力层、crf层,得到最终的bio标签信息。标签信息标记出一段文本中哪些字符在一起形成一个军事实体。
[0031]
图3为本发明事件触发词抽取模型结构图。抽取过程如下:
[0032]
对于一个句子的输入,通过bert模型转换成对应的词向量,输入到触发词抽取模型进行抽取。该模型自下而上分别经过双向gru层、实体注意力层、线性变换成、crf层,得到最终bio标签信息。标签信息标记出一段文本中哪些字符在一起形成一个作战事件触发词。
[0033]
其中,实体注意力机制是本发明的重要组成部分。首先,通过上述的军事实体抽取方法抽取出相关实体,得到“装备”、“任务”、“单位”、“战争名称”等四种类型实体在句子中的位置。然后,对于输入的句子,利用上述实体抽取结果生成相应的军事实体信息,为后续注意力机制做准备。
[0034]
实体信息生成过程如图4所示,每个句子对应每种类型实体生成与句子长度相同维度的0
‑
1向量,其中实体出现位置对应的值置为1,其余位置的值置为0。将军事实体信息进行线性变换得到注意力机制中的q
mei
,将bi
‑
gru的输出进行线性变换得到注意力机制中的k和v(k=v)。最后,利用下面的公式进行计算,得到注意力机制的输出。
[0035][0036]
实施例1
[0037]
在本实施例中,在gtx 1080 8g显卡上,采用深度学习框架pytorch。
[0038]
首先,为作战事件抽取模型的训练准备数据集。利用网络爬虫工具爬取头条百科中军事装备相关词条。装备词条的服役动态部分具有该装备参与过的战役的描述。因此,本方法每个词条的服役动态部分进行人工标记,将文本描述中包含的军事实体和作战事件触发词标记出来。最终,完成3573条句子的标注。
[0039]
将标记好的3573条句子集合分成两份,分别包含2858条(80%)句子和715条(20%)句子。其中2858条句子用于模型的训练,715条句子用于模型性能的测试。
[0040]
军事实体抽取实验:为证明军事实体后缀特征在军事实体抽取任务中的有效性,
在2858条训练集上进行模型训练,在715条测试集上进行测试,并计算测试集上的f
‑
值。表1给出了军事实体识别模型的超参数设置情况。通过后缀特征的增加,在测试集上的f
‑
值从76.8%提升到78.8%,证明了后缀特征的有效性,同时,也为后续事件触发词识别模型中军事实体注意力机制部分提供了高精度的实体识别结果。
[0041]
表1 军事实体识别模型超参数
[0042]
参数名称参数值bert字向量维度768bi
‑
gru状态层维度512自注意力机制输出维度512dropout概率0.5学习率1e
‑5[0043]
作战事件触发词抽取实验:为证明军事实体注意力机制在事件触发词抽取上的有效性,以上述军事实体识别结果为基础,在2858条训练集上进行模型训练,在715条测试集上进行测试,并计算测试集上的f
‑
值。
[0044]
表2和表3分别展示了作战事件抽取模型中超参数的设置情况和事件触发词实验结果对比分析。通过军事实体注意力机制的增加,在测试集上的事件触发词识别f
‑
值从78.8.%提升到80.1%,证明了军事实体注意力机制的有效性。同时,与其它当前先进的触发词抽取方法进行了测试结果对比分析,证明了本发明方法在军事百科数据作战事件抽取任务上的优势。
[0045]
表2 事件触发词抽取模型超参数
[0046]
参数名称参数值bert字向量维度768bi
‑
gru状态层维度512自注意力机制输出维度512dropout概率0.5学习率1e
‑7[0047]
表3 事件触发词抽取实验的结果
[0048][0049]
从实验结果中可以看出,本发明所述方法相比于其他现有方法具有更高的精确率、召回率和f
‑
值;即本发明相比于现有技术对面向百科数据的军事事件抽取更加准确,更具有鲁棒性。
[0050]
以上所述仅为本发明较佳的实施方式,但本发明的保护范围并不局限于此。任何
熟悉本技术领域的技术人员在本发明披露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1