垃圾分类信息获取方法、装置、设备及存储介质
1.本发明涉及互联网技术领域,尤其涉及一种垃圾分类信息获取方法、装置、设备及存储介质。
背景技术:
2.目前,我国垃圾每天产量数以万吨,家庭垃圾占主要,种类复杂,分类困难,给生存环境带来巨大压力和考验。现有技术中需要人工学习垃圾分类知识以进行垃圾分类,由于垃圾种类广,导致垃圾分类的准确率低下。
3.上述内容仅用于辅助理解本发明的技术方案,并不代表承认上述内容是现有技术。
技术实现要素:
4.本发明的主要目的在于提供了一种垃圾分类信息获取方法、装置、设备及存储介质,旨在如何提高垃圾分类的准确率的技术问题。
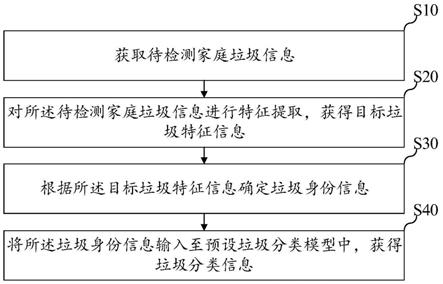
5.为实现上述目的,本发明提供了一种垃圾分类信息获取方法,所述垃圾分类信息获取方法包括:
6.获取待检测家庭垃圾信息;
7.对所述待检测家庭垃圾信息进行特征提取,获得目标垃圾特征信息;
8.根据所述目标垃圾特征信息确定垃圾身份信息;
9.将所述垃圾身份信息输入至预设垃圾分类模型中,获得垃圾分类信息。
10.可选地,所述获取待检测家庭垃圾图片的步骤之前,还包括:
11.获取家庭垃圾数据样本集,所述家庭垃圾数据样本集中存在多个家庭垃圾数据样本;
12.对多个所述家庭垃圾数据样本进行分类处理,获得多个家庭垃圾数据样本子集及对应的垃圾样本特征信息;
13.确定所述家庭垃圾数据样本集对应的信息熵;
14.根据所述垃圾样本特征信息分别确定多个所述家庭垃圾数据样本子集对应的条件熵;
15.根据所述信息熵和所述条件熵确定所述垃圾样本特征信息对应的信息增益;
16.根据所述信息增益和所述垃圾样本特征信息构建预设决策树;
17.根据多个家庭垃圾数据样本子集和所述预设决策树对预设初始网络模型进行训练,获得预设垃圾分类模型。
18.可选地,所述获取家庭垃圾数据样本集的步骤,包括:
19.按照预设划分策略对多个垃圾数据进行划分处理,获得多个垃圾数据集;
20.从多个所述垃圾数据集中选取多个垃圾数据训练集;
21.根据多个所述垃圾数据训练集确定家庭垃圾数据样本集。
22.可选地,所述根据多个家庭垃圾数据样本子集和所述预设决策树对预设初始网络模型进行训练,获得预设垃圾分类模型的步骤,包括:
23.根据多个所述家庭垃圾数据样本集确定预设交叉策略;
24.根据所述预设交叉策略、多个家庭垃圾数据样本子集和所述预设决策树对预设初始网络模型进行训练,获得预设垃圾分类模型。
25.可选地,所述根据所述预设交叉策略、多个家庭垃圾数据样本子集和所述预设决策树对预设初始网络模型进行训练,获得预设垃圾分类模型的步骤,包括:
26.根据所述预设交叉策略、多个家庭垃圾数据样本子集和所述预设决策树对预设初始网络模型进行训练,获得初始垃圾分类模型;
27.获取家庭垃圾数据样本测试子集;
28.通过所述家庭垃圾数据样本测试子集对所述初始垃圾分类模型进行测试,获得模型测评分值;
29.在所述模型测评分值大于预设阈值时,将所述初始垃圾分类模型作为预设垃圾分类模型。
30.可选地,所述确定所述家庭垃圾数据样本集对应的信息熵的步骤,包括:
31.获取所述家庭垃圾数据样本集对应的垃圾类别标签数量和家庭垃圾数据总数量;
32.根据所述垃圾类别标签数量和所述家庭垃圾数据总数量通过第一预设公式计算所述家庭垃圾数据样本集对应的信息熵;
33.所述第一预设公式为:
[0034][0035]
式中,h(d)为家庭垃圾数据样本集对应的信息熵,cm为垃圾类别标签数量,n为家庭垃圾数据总数量。
[0036]
可选地,所述根据所述信息熵和所述条件熵确定所述垃圾样本特征信息对应的信息增益的步骤,包括:
[0037]
根据所述信息熵和所述条件熵通过预设增益公式计算所述垃圾样本特征信息对应的信息增益;
[0038]
所述预设增益公式为:
[0039]
g(d,a)=h(d)-h(d|a)
[0040]
式中,g(d,a)为样本垃圾特征信息对应的信息增益,h(d)为信息熵,h(da)为条件熵。
[0041]
此外,为实现上述目的,本发明还提出一种垃圾分类信息获取装置,所述垃圾分类信息获取装置包括:
[0042]
获取模块,用于获取待检测家庭垃圾信息;
[0043]
提取模块,用于对所述待检测家庭垃圾信息进行特征提取,获得目标垃圾特征信息;
[0044]
确定模块,用于根据所述目标垃圾特征信息确定垃圾身份信息;
[0045]
识别模块,用于将所述垃圾身份信息输入至预设垃圾分类模型中,获得垃圾分类信息。
[0046]
此外,为实现上述目的,本发明还提出一种垃圾分类信息获取设备,所述设备包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的垃圾分类信息获取程序,所述垃圾分类信息获取程序配置为实现如上文所述的垃圾分类信息获取方法的步骤。
[0047]
此外,为实现上述目的,本发明还提出一种存储介质,所述存储介质上存储有垃圾分类信息获取程序,所述垃圾分类信息获取程序被处理器执行时实现如上文所述的垃圾分类信息获取方法的步骤。
[0048]
本发明首先获取待检测家庭垃圾信息,然后对待检测家庭垃圾信息进行特征提取,获得目标垃圾特征信息,之后根据目标垃圾特征信息确定垃圾身份信息,并将垃圾身份信息输入至预设垃圾分类模型中,获得垃圾分类信息。相较于现有技术中需要人工提前进行垃圾分类,并根据人工设置的垃圾分类标签确定垃圾分类信息,而本发明中可以可以将垃圾身份信息输入至预设垃圾分类模型中,以获得垃圾分类信息,从而提高了垃圾分类的准确率,进而提高了垃圾的分类效率。
附图说明
[0049]
图1是本发明实施例方案涉及的硬件运行环境的垃圾分类信息获取设备的结构示意图;
[0050]
图2为本发明垃圾分类信息获取方法第一实施例的流程示意图;
[0051]
图3为本发明垃圾分类信息获取方法第二实施例的流程示意图;
[0052]
图4为本发明垃圾分类信息获取方法第二实施例的决策树逻辑图;
[0053]
图5为本发明垃圾分类信息获取方法第二实施例的模型验证曲线图;
[0054]
图6为本发明垃圾分类信息获取装置第一实施例的结构框图。
[0055]
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
[0056]
应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
[0057]
参照图1,图1为本发明实施例方案涉及的硬件运行环境的垃圾分类信息获取设备结构示意图。
[0058]
如图1所示,该垃圾分类信息获取设备可以包括:处理器1001,例如中央处理器(central processing unit,cpu),通信总线1002,用户接口1003,网络接口1004,存储器1005。其中,通信总线1002用于实现这些组件之间的连接通信。用户接口1003可以包括显示屏(display)、输入单元比如键盘(keyboard),可选用户接口1003还可以包括标准的有线接口、无线接口。网络接口1004可选的可以包括标准的有线接口、无线接口(如无线保真(wireless-fidelity,wi-fi)接口)。存储器1005可以是高速的随机存取存储器(random access memory,ram),也可以是稳定的非易失性存储器(non-volatile memory,nvm),例如磁盘存储器。存储器1005可选的还可以是独立于前述处理器1001的存储装置。
[0059]
本领域技术人员可以理解,图1中示出的结构并不构成对垃圾分类信息获取设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
[0060]
如图1所示,作为一种存储介质的存储器1005中可以包括操作系统、网络通信模
块、用户接口模块以及垃圾分类信息获取程序。
[0061]
在图1所示的垃圾分类信息获取设备中,网络接口1004主要用于与网络服务器进行数据通信;用户接口1003主要用于与用户进行数据交互;本发明垃圾分类信息获取设备中的处理器1001、存储器1005可以设置在垃圾分类信息获取设备中,所述垃圾分类信息获取设备通过处理器1001调用存储器1005中存储的垃圾分类信息获取程序,并执行本发明实施例提供的垃圾分类信息获取方法。
[0062]
本发明实施例提供了一种垃圾分类信息获取方法,参照图2,图2为本发明垃圾分类信息获取方法第一实施例的流程示意图。
[0063]
本实施例中,所述垃圾分类信息获取方法包括以下步骤:
[0064]
步骤s10:获取待检测家庭垃圾信息。
[0065]
易于理解的是,本实施例的执行主体可以是具有图片处理、数据处理、网络通讯和程序运行等功能的垃圾分类信息获取设备,该垃圾分类信息获取设备还能够将垃圾身份信息输入至预设垃圾分类模型中,获得垃圾分类信息等,也可以为其他具有相似功能的计算机设备等,本实施例并不加以限制。
[0066]
待检测家庭垃圾信息可以理解为家庭垃圾中需要分类的垃圾图像或垃圾语音等。
[0067]
步骤s20:对所述待检测家庭垃圾信息进行特征提取,获得目标垃圾特征信息。
[0068]
需要说明的是,若待检测家庭垃圾信息为垃圾图像,则对垃圾图像进行图像特征提取,以获取垃圾图像对应的目标垃圾特征信息;若待检测家庭垃圾信息为垃圾语音,则对垃圾语音进行语音文字提取,获得语音关键词,并将语音关键词作为目标垃圾特征信息等。
[0069]
对垃圾图像进行图像特征提取,以获取垃圾图像对应的目标垃圾特征信息的处理方式可以为对垃圾图像进行灰度处理,获得垃圾灰度图像,然后获取垃圾灰度图像的像素点信息,根据像素点信息从垃圾灰度图像中提取垃圾轮廓线,根据垃圾轮廓线确定目标垃圾特征信息等。
[0070]
在具体实现中,用户可以将拍摄的垃圾图像传输至预设垃圾分类模型中,预设垃圾分类模型可以提取垃圾图像对应的垃圾轮廓线,之后将垃圾轮廓线与预存的多个垃圾轮廓线样本进行匹配,并获取垃圾轮廓线与多个垃圾轮廓线样本之间的匹配值,在匹配值大于预设匹配阈值时,获取匹配值大于预设匹配阈值的若干个垃圾轮廓线样本对应的数量,在若干个垃圾轮廓线样本数量大于预设数量阈值时,可以根据匹配值将若干个垃圾轮廓线样本进行排序,获得垃圾匹配排序结果,根据垃圾匹配排序结果从若干个垃圾轮廓线样本中选取目标垃圾轮廓线样本,并将目标垃圾轮廓线样本作为目标垃圾特征信息等。预设匹配阈值和预设数量阈值均为用户自定义设置,预设匹配阈值可以为百分之九十等,预设数量阈值可以为2等。
[0071]
在本实施例中,若垃圾图像的垃圾轮廓线为a,预存的多个垃圾轮廓线样本分别为a1、a2、a3、a4及a5,a与a1之间的匹配值为百分之八十,a与a2之间的匹配值为百分之九十,a与a3之间的匹配值为百分之九十五,a与a4之间的匹配值为百分之九十六,a与a5之间的匹配值为百分之九十三,预设匹配阈值为百分之九十,则将a2、a3、a4及a5进行排序,垃圾匹配排序结果为a4-a3-a5-a2,目标垃圾轮廓线样本为a4等。
[0072]
对垃圾语音进行语音文字提取,获得语音关键词的处理方式可以为将垃圾语音转换成语音文字,从语音文字中提取多个语音词汇,根据多个语音词汇确定语音关键词等。
[0073]
在具体实现中,用户需要查询待检测垃圾的垃圾分类信息时,需要获取用户对于该待检测垃圾的语音描述信息,之后将语音描述信息转换为语音文字等。
[0074]
在本实施例中,若语音描述信息为“黑色的电脑”,则语音词汇分别为“黑色”、“电脑”,由于“黑色”为形容词,“电脑”为名词,可以将“电脑”作为语音关键词等。
[0075]
步骤s30:根据所述目标垃圾特征信息确定垃圾身份信息。
[0076]
垃圾身份信息可以理解为垃圾名称,例如玻璃或木柜等。
[0077]
应理解的是,若目标垃圾特征信息为目标垃圾轮廓线样本,则需要从预设垃圾身份映射关系表中查找目标垃圾轮廓线样本对应的垃圾身份信息等,预设垃圾身份映射关系表中存在多个垃圾轮廓线样本和多个垃圾身份信息,其中垃圾轮廓线样本和多个垃圾身份信息存在一一对应的关系。
[0078]
还应理解的是,若目标垃圾特征信息为语音关键词,则直接将语音关键词作为垃圾身份信息等。
[0079]
步骤s40:将所述垃圾身份信息输入至预设垃圾分类模型中,获得垃圾分类信息。
[0080]
为了能够精准查询垃圾分类信息,可以获取家庭垃圾数据样本集,家庭垃圾数据样本集中存在多个家庭垃圾数据样本,对多个家庭垃圾数据样本进行分类处理,获得多个家庭垃圾数据样本子集及对应的垃圾样本特征信息,确定家庭垃圾数据样本集对应的信息熵,根据垃圾样本特征信息分别确定多个家庭垃圾数据样本子集对应的条件熵,根据信息熵和条件熵确定垃圾样本特征信息对应的信息增益,根据信息增益和垃圾样本特征信息构建预设决策树,根据多个家庭垃圾数据样本子集和预设决策树对预设初始网络模型进行训练,获得预设垃圾分类模型。
[0081]
垃圾分类信息可以为有害垃圾、湿垃圾、可回收垃圾和其他垃圾等。
[0082]
在本实施中,用户可以利用垃圾图像或垃圾语音确定垃圾身份信息,之后将垃圾身份信息展示在预设垃圾分类模型的搜索框内,若垃圾身份信息与实际物体不相符,用户还可以在搜索框内手动输入垃圾身份信息等。
[0083]
预设垃圾分类模型还可以展现与垃圾身份信息相关的多个垃圾身份信息及对应的垃圾分类信息等。
[0084]
例如搜索框内的垃圾身份信息为瓶子,则相关的多个垃圾身份信息可以为塑料瓶子或玻璃瓶子等,其中塑料瓶子对应的垃圾分类信息为可回收垃圾,玻璃瓶子对应的垃圾分类信息为可回收垃圾等。
[0085]
在具体实现中,为了能够精准查询垃圾分类信息,在用户输入垃圾身份信息后,还可以点击设置该垃圾身份信息的特征信息,例如是否有毒、是否易腐烂、是否包含再生材料、材质及形态等。
[0086]
特征选取决定模型性能,特征的选取至关重要,本文主要根据环保专家和学者经验以及相关书籍资料,同时考虑常见家庭垃圾处理方法和结合家庭垃圾特点,选取材质、形态、毒性、是否易腐烂和是否包含再利用材料作为有效特征。
[0087]
在家庭垃圾中,有部分垃圾具有毒性,例如废电池、废灯管、废温度计、废药品、废油漆、废杀虫剂、废相纸等,这些毒性家庭生活垃圾可以明显区分垃圾类别,一般作为不可回收类别。因此,选取毒性做为本文有效特征。【“1”表示有毒,“0”表示无毒】。
[0088]
家庭生活中产生的易腐性垃圾(即湿垃圾),腐烂垃圾主要包括:剩菜剩饭、菜梗菜
叶、肉食内脏、果壳瓜皮、室内绿植等等,但是这些腐烂的家庭垃圾却是生物或者有机物中的一类,可以形成沼气和有机肥,正是植物所需养分的主要来源,也能够改善土壤肥力特性,所以可以将物体是否易腐作为一个维度特征划分。因此,选取腐烂性做为本文有效特征。【“1”表示腐烂,“0”表示不腐烂】。
[0089]
在家庭垃圾中,有部分垃圾废弃物可以回收利用,例如纸类、塑料、玻璃、金属、织物及瓶罐等,这些垃圾都能通过重新加工处理被再次利用。因此,再利用作为一个重要特征维度。【“1”表示可再利用,“0”表示不可再利用】。
[0090]
在家庭生活中,不同垃圾有着不同的材质构成,在一定程度上,材质决定所属类别,例如纸张、玻璃、塑料、金属、橡胶、木材、棉织物、电子产品、化学品、肉类等。因此,选取9种主要的材质做为本文有效特征。【“0”表示纸张,“1”表示玻璃,“2”表示塑料,“3”表示橡胶,“4”表示木材,“5”表示金属,“6”表示棉织物,“7”表示电子产品,“8”表示化学品,“9”表示肉类】。
[0091]
家庭生活垃圾的形态,一般分为固体(板凳)、液体(酱油)、气体(瓶罐中的氧气),它能够比较明显区分是否是湿垃圾或再利用垃圾。因此,选取形态做为本文有效特征。其中,【“0”表示固态,“1”表示液态,“2”表示气态】。
[0092]
在本实施例中,首先获取待检测家庭垃圾信息,然后对待检测家庭垃圾信息进行特征提取,获得目标垃圾特征信息,之后根据目标垃圾特征信息确定垃圾身份信息,并将垃圾身份信息输入至预设垃圾分类模型中,获得垃圾分类信息。相较于现有技术中需要人工提前进行垃圾分类,并根据人工设置的垃圾分类标签确定垃圾分类信息,而本实施例中可以可以将垃圾身份信息输入至预设垃圾分类模型中,以获得垃圾分类信息,从而提高了垃圾分类的准确率,进而提高了垃圾的分类效率。
[0093]
参考图3,图3为本发明垃圾分类信息获取方法第二实施例的流程示意图。
[0094]
基于上述第一实施例,在本实施例中,所述步骤s10之前,还包括:
[0095]
步骤s01:获取家庭垃圾数据样本集,所述家庭垃圾数据样本集中存在多个家庭垃圾数据样本。
[0096]
按照预设划分策略对多个垃圾数据进行划分处理,获得多个垃圾数据集,从多个垃圾数据集中选取多个垃圾数据训练集,根据多个垃圾数据训练集确定家庭垃圾数据样本集。
[0097]
需要说明的是,多个垃圾数据可以通过手工收集和网络爬虫等技术,收集环保领域网站以及第三方网站等家庭垃圾实体数据,并邀请环保专家学者进行数据去噪和数据清洗,并按照垃圾分类标准进行分类,将训练数据和测试数据保存在格式为utf-8的文本中。
[0098]
预设划分策略可以为等份划分,例如家庭垃圾语料库中多个垃圾数据为4000条数据,之后将4000条数据平均划分为5等份,并将划分后的5等份数据集作为多个垃圾数据集,在具体实现中可以从多个垃圾数据集任一选取4份作为家庭垃圾数据样本集等。
[0099]
步骤s02:对多个所述家庭垃圾数据样本进行分类处理,获得多个家庭垃圾数据样本子集及对应的垃圾样本特征信息。
[0100]
由于每个家庭垃圾数据样本中均存在对应的垃圾样本特征信息,可以根据垃圾样本特征信息对多个家庭垃圾数据样本进行分类处理,获得多个家庭垃圾数据样本子集等。
[0101]
垃圾样本特征信息包括毒性特征、腐烂性特征及再利用特征。
[0102]
步骤s03:确定所述家庭垃圾数据样本集对应的信息熵。
[0103]
获取家庭垃圾数据样本集对应的垃圾类别标签数量和家庭垃圾数据总数量;根据垃圾类别标签数量和家庭垃圾数据总数量通过第一预设公式计算家庭垃圾数据样本集对应的信息熵;
[0104]
第一预设公式为:
[0105][0106]
式中,h(d)为家庭垃圾数据样本集对应的信息熵,cm为垃圾类别标签数量,n为家庭垃圾数据总数量。
[0107]
垃圾类别标签可以为有害垃圾标签、湿垃圾标签、可回收垃圾及其他垃圾等。
[0108]
在本实施例中,家庭垃圾数据样本集中家庭垃圾数据总数量为101条,数据特征列c={毒性,腐烂性,再利用},类别标签s={有害垃圾,湿垃圾,可回收垃圾,其他垃圾}。其中,s1(有害垃圾)=23,s2(湿垃圾)=34,s3(可回收垃圾)=24,s4(其他垃圾)=20,计算对给定家庭垃圾数据集分类所需的信息熵,根据第一预设公式,计算如下:可知1.970为家庭垃圾数据样本集对应的信息熵。
[0109]
步骤s04:根据所述垃圾样本特征信息分别确定多个所述家庭垃圾数据样本子集对应的条件熵。
[0110]
在具体实现中,若训练集为d,d的样本个数为n,d的数据有m个分类,分别为c1,c2,c3,...,cm,分类cm的数据个数为|cm|,任一个特征的n个不同取值,记为a1,a2,a3,
…
,an。根据特征的n个取值将d划分的n个子集为d1,d2,d3,...,dn。对于任意的子集di∈{a1,a2,a3,...,an},设di的样本个数为ni,di中属于类ci∈{c1,c2,c3,...,cm}的样本个数为|ci|,那么特征a对数据集的条件熵
[0111]
计算“毒性”特征的条件熵。毒性共分两组:有毒垃圾(d
00
)、无毒垃圾(d
01
)。其中,d
00
有28条数据有害垃圾有23条,其他垃圾5条。d
01
有73条数据,其中湿垃圾34条,可回收垃圾24条,其他垃圾15条。所以,根据条件熵公式,毒性特征的条件熵计算如下:
[0112][0113]
可知,“毒性”特征的条件熵为1.278。
[0114]
计算“腐烂”特征的条件熵。腐烂共分为两组:易腐烂垃圾(d
10
)、不易腐烂垃圾(d
11
)。d
10
有64条数据,其中有害垃圾有23条,湿垃圾2条,可回收垃圾19条,其他垃圾20条。d11有37条数据,其中湿垃圾32条,可回收垃圾5条。所以,根据条件熵公式(2),是否易腐烂特征的条件熵,计算如下:
[0115][0116]
可知,“腐烂”特征的条件熵为1.298。
[0117]
计算“再利用”特征的条件熵。再利用共分为两组:再利用垃圾(d
20
)、非再利用垃圾
(d
21
)。其中,d
20
有70条数据,其中有害垃圾23条,湿垃圾34条,其他垃圾13条。d
21
有31条数据,其中,可回收垃圾24条,其他垃圾7条。所以,是否包含再利用性特征的条件熵,计算如下:
[0118][0119]
可知,“再利用”特征的条件熵为1.256。
[0120]
步骤s05:根据所述信息熵和所述条件熵确定所述垃圾样本特征信息对应的信息增益。
[0121]
根据信息熵和条件熵通过预设增益公式计算垃圾样本特征信息对应的信息增益;
[0122]
预设增益公式为:
[0123]
g(d,a)=h(d)-h(d|a)
[0124]
式中,g(d,a)为样本垃圾特征信息对应的信息增益,h(d)为信息熵,h(d|a)为条件熵。
[0125]
在本实施例中,可以用家庭垃圾数据集的信息熵信息熵减去每个特征的条件熵,求出三个特征的信息增益,毒性特征的信息增益为0.692,腐烂特征的信息增益为0.672,再利用特征的信息增益为0.714。
[0126]
步骤s06:根据所述信息增益和所述垃圾样本特征信息构建预设决策树。
[0127]
在具体实现中,可以从所有的特征列中选出信息增益最大的那个作为根节点或内部节点——划分节点,划分整列,并生成预设决策树。
[0128]
根据划分节点的不同取值,来拆分数据集为若干个子集,然后删去当前的特征列,再计算剩余特征列的信息熵。如果有信息增益,就重复直至划分结束。首次划分后,再利用性与非再利用内含有多个标签,所以可以继续划分。划分结束的标志为:子集中只有一个类别标签,停止划分。参考图4,图4为本发明垃圾分类信息获取方法第二实施例的决策树逻辑图。
[0129]
步骤s07:根据多个家庭垃圾数据样本子集和所述预设决策树对预设初始网络模型进行训练,获得预设垃圾分类模型。
[0130]
根据多个家庭垃圾数据样本集确定预设交叉策略,根据预设交叉策略、多个家庭垃圾数据样本子集和预设决策树对预设初始网络模型进行训练,获得预设垃圾分类模型。预设交叉策略为可以5倍交叉交叉策略。
[0131]
根据预设交叉策略、多个家庭垃圾数据样本子集和预设决策树对预设初始网络模型进行训练,获得初始垃圾分类模型,获取家庭垃圾数据样本测试子集,通过家庭垃圾数据样本测试子集对初始垃圾分类模型进行测试,获得模型测评分值,在模型测评分值大于预设阈值时,将初始垃圾分类模型作为预设垃圾分类模型。
[0132]
在本实施例中可以,采用模型评测分值即正确率作为家庭垃圾分类模型的测评标准。正确率计算公式为:
[0133][0134]
其中,p为正确率,nr为家庭垃圾数据样本测试子集中预测分类正确的个数,nc为家庭垃圾数据样本集中垃圾的总数。
[0135]
为了能够进一步准确评估构建的预设垃圾分类模型,本次实验将家庭垃圾数据集按照每500条均匀划分为500条、1000条、1500条、2000条、2500条、2500条、3500条和4000条8组不同训练数据规模集合,进行正确率测试。参考图5,图5为本发明垃圾分类信息获取方法第二实施例的模型验证曲线图。图5可知,基于8次实验数据规模,对决策树模型的性能评估,随着实验数据规模不断增加,正确率也随着增加,当趋于4000条数据时,正确率趋向稳定于83.52%。
[0136]
为了能够更加准确评估构建的决策树家庭垃圾分类模型,本次实验采用5倍交叉实验,将家庭垃圾语料库4000条数据集平均划分为5等份,其中4份
[0137]
作为训练数据,另外1份作为测试数据,5倍交叉策略实验结果如表1所示。
[0138]
表1
[0139]
序号训练数据测试数据正确率1第1、2、3、4等份第5等份83.53%2第1、2、3、5等份第4等份83.41%3第1、2、4、5等份第3等份84.16%4第1、3、4、5等份第2等份83.21%5第2、3、4、5等份第1等份83.27%
[0140]
从上表可见,5倍交叉策略实验对基于决策树模型的性能评估,局部正确率最高为84.16%,局部正确率最低为83.21%,为准确客观评价模型性能,实验正确率采用5组平均值,即83.52%。
[0141]
在本实施例中,首先获取家庭垃圾数据样本集,家庭垃圾数据样本集中存在多个家庭垃圾数据样本,然后对多个家庭垃圾数据样本进行分类处理,获得多个家庭垃圾数据样本子集及对应的垃圾样本特征信息,确定家庭垃圾数据样本集对应的信息熵,之后根据垃圾样本特征信息分别确定多个家庭垃圾数据样本子集对应的条件熵,根据信息熵和条件熵确定垃圾样本特征信息对应的信息增益,并根据信息增益和垃圾样本特征信息构建预设决策树,最后根据多个家庭垃圾数据样本子集和预设决策树对预设初始网络模型进行训练,获得预设垃圾分类模型,相较于现有技术中人工分类导致垃圾分类效率和正确率低,而本实施例中通过构建预设垃圾分类模型可以提取更多有效特征,从而能够更加精准、全面、快速地识别家庭垃圾的类别。
[0142]
参照图6,图6为本发明垃圾分类信息获取装置第一实施例的结构框图。
[0143]
如图6所示,本发明实施例提出的垃圾分类信息获取装置包括:
[0144]
获取模块6001,用于获取待检测家庭垃圾信息。
[0145]
提取模块6002,用于对所述待检测家庭垃圾信息进行特征提取,获得目标垃圾特征信息。
[0146]
确定模块6003,用于根据所述目标垃圾特征信息确定垃圾身份信息。
[0147]
识别模块6004,用于将所述垃圾身份信息输入至预设垃圾分类模型中,获得垃圾分类信息。
[0148]
在本实施例中,首先获取待检测家庭垃圾信息,然后对待检测家庭垃圾信息进行特征提取,获得目标垃圾特征信息,之后根据目标垃圾特征信息确定垃圾身份信息,并将垃圾身份信息输入至预设垃圾分类模型中,获得垃圾分类信息。相较于现有技术中需要人工
提前进行垃圾分类,并根据人工设置的垃圾分类标签确定垃圾分类信息,而本实施例中可以可以将垃圾身份信息输入至预设垃圾分类模型中,以获得垃圾分类信息,从而提高了垃圾分类的准确率,进而提高了垃圾的分类效率。
[0149]
本发明垃圾分类信息获取装置的其他实施例或具体实现方式可参照上述各方法实施例,此处不再赘述。
[0150]
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
[0151]
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
[0152]
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如只读存储器/随机存取存储器、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,空调器,或者网络设备等)执行本发明各个实施例所述的方法。
[0153]
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1