一种基于知识图谱和迁移学习的施工项目知识转移方法与流程
1.本发明属于计算技术领域,具体涉及一种基于知识图谱和迁移学习的施工项目知识转移方法。
背景技术:
2.随着知识经济时代的到来,知识逐渐发展成为企业的重要财富和资本施工企业作为典型的项目导向型企业,在进行项目的过程中积累了很多无形的知识财富。通过高效的项目知识管理,不仅能有效提高施工企业的技术、管理水平和竞争力,还能实现施工企业可持续发展的管理模式。然而,由于企业中项目团队的临时性和时间压力,通常在项目完成后团队就解散,知识难以被有效管理与共享,知识流失严重。造成这种局面的一大原因在于目前跨项目知识转移的方法和技术效率低下,项目人员无法高效、系统地把他们的项目知识传递给其他项目。
3.知识转移在施工项目管理中的研究还比较少,而且大多数是基于组织行为学进行研究,只有一小部分学者从技术实现角度进行知识转移的探讨。个别施工项目型企业构建了知识管理信息系统,但其只是充当了一个知识存储工具,没有起到促进知识转移的作用,知识转移无法真正落实到施工项目上。根本原因在于目前的施工项目知识管理忽略了项目之间、知识之间的关系,从而无法衡量项目之间的关联性,导致在进行跨项目知识转移时无法提供适合的转移对象,不能有效降低知识转移的成本与偏差。并且,以往的知识转移都需要专家讲解,或者通过“复制-粘贴”的方式直接转移,会花费非常多的人力成本而且转移效果不理想;
4.综上可知,现有的技术和方法都不能很好的进行施工项目之间的知识转移,所积累知识的利用率不高,转移过程中的知识损失大。
技术实现要素:
5.本发明公开了一种基于知识图谱和迁移学习的施工项目知识转移方法,拟解决背景技术中提到的目前施工项目积累的知识利用率不高,转移过程中知识损失大、难以高效以及高质量实现跨项目知识转移的问题。
6.为解决上述技术问题,本发明采用的技术方案如下:
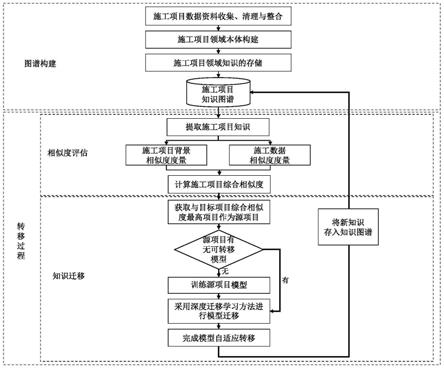
7.一种基于知识图谱和迁移学习的施工项目知识转移方法,包括以下步骤:
8.步骤1:整合所有能够获取到的施工项目资料;
9.步骤2:利用施工项目资料数据,构建施工项目本体库,并抽取施工项目的结构化信息,将抽取的结构化信息存入图数据库,构建施工项目知识图谱;
10.步骤3:从施工项目知识图谱中提取施工项目信息,计算目标项目与知识图谱中的源项目之间的背景相似度;根据目标项目的施工数据,计算目标项目的施工数据与源项目之间的数据相似度,基于背景相似度和数据相似度得到综合相似度,通过综合相似度查询,搜寻到相似度最高的源项目作为知识发送方;
11.步骤4:若源项目中存在已提炼的相关知识,则转移该知识;若源项目中不存在已提炼的相关知识,则利用源项目的数据提炼出相关知识,再进行迁移;
12.步骤5:以步骤4中提炼的相关知识中的施工参数预测模型作为知识转移目标,采用基于网络模型的深度迁移学习方法,进行从源项目到目标项目的模型迁移,将知识自适应地转移到目标项目。
13.本发明利用知识图谱表示施工项目知识和项目场景的方法,引入迁移学习思想进行待转移项目知识选取的方法,以及使该知识适配目标场景的迁移方法,数据驱动的跨项目知识转移系统原型,为自动、智能地对转移过程中的知识选取、调整以及转移环节设置提出了可行的方案,实现了施工企业的项目知识的共享以及运用,提高了项目知识的管理水平。
14.优选的,步骤2中所述施工项目知识图谱的构建包括以下步骤:
15.步骤2.1:结合项目施工领域的特征,构建施工项目领域本体;其中,知识本体o
kg
= {te,tf,tr}涵盖实体概念类属性类以及关系类
16.步骤2.2:施工项目领域本体的基础上,从数据资料中抽取出相关的所有实体e= {e1,e2,e3,...}、属性f={f1,f2,f3,...}以及实体之间的关系,将所有非结构和半结构数据进行结构化转变,规范成通用的三元组表示方式;
17.步骤2.3:将抽取出的知识存储到图数据库中。
18.优选的,步骤3中所述施工项目综合相似度包括以下计算步骤:
19.步骤3.1:在构建好的施工项目知识图谱中,依据各实体概念类提取各施工项目的信息;
20.步骤3.2:采用实体匹配技术进行各施工项目背景实体类相似度计算,再基于专家打分法加权计算得到背景相似度;
21.步骤3.3:利用现有的最大均值偏差计算公式,计算施工数据相似度,计算公式如下:
[0022][0023]
将目标项目与源项目的施工数据放入上述公式中计算得到分布距离,再将距离进行归一化处理,并转化为相似度;
[0024][0025]
式中,为目标项目p0与其他源项目pi的施工数据相似度,为目标项目p0与其他源项目pi的施工数据mmd距离;
[0026]
步骤3.4:计算施工项目综合相似度,计算公式如下:
[0027][0028]
式中:分别为目标项目p0与其他源项目pi的综合相似度、项目背景相似度、施工数据相似度的度量值;h0为目标项目的施工进度;h
t
为目标项目的总工程量。
[0029]
优选的,步骤3.2中所述的背景相似度计算包括以下步骤:
[0030]
步骤3.21:若一个项目与同一实体类中的单个实体关联时,则执行步骤3.22;若一个项目与同一实体类中的多个实体关联时则执行本步骤,采用基于jaccard相似度的邻居信息匹配方法;评价指标获取两个实体集合的交集和并集,并取交集和并集之间的比值,定义如下:
[0031][0032]
式中:为源项目pi与目标项目p0的第j个实体类的jaccard相似度,i∈ 1,...,m,m表示源项目个数,j∈1,...,n,n表示实体类个数;a为目标项目p0指向第j个实体类的所有实体集合;
[0033]
步骤3.22:当一个项目只与同一实体类中的单个实体关联时,采用属性匹配方法计算相似度;
[0034]
步骤3.23:根据求到的各实体类的相似度,基于专家打分法加权计算施工项目与目标项目的背景相似度,专家打分法采用标度法进行设计,打分表中的影响因子类全面涵盖各类实体类因子,每一位专家对两两因子的重要程度进行对比打分,最后累计求和得到每一类影响因子的总得分,并转换为权重系数,加权得到施工项目与目标项目的背景相似度。
[0035]
优选的,步骤3.22中所述的步骤属性匹配方法包括如下步骤:
[0036]
步骤3.221:判断实体属性类型,若是数值型属性,则采用数值属性相似度匹配,执行步骤3.222;若是类别属性,则采用类别属性相似度进行匹配,执行步骤3.223。
[0037]
步骤3.222:当实体属性类型为数值型属性时,通过考虑属性值距离来评价属性的相似度,并对相似度结果进行归一化处理;
[0038]
目标项目与其他源项目的数值属性距离表示如下:
[0039][0040]
式中:为源项目pi与目标项目p0的数值属性距离;α为某个数值属性;a0为目标项目p0的α属性值;ai为目标项目pi的α属性值;
[0041]
将距离转化为相似度并归一化后的结果如下:
[0042][0043]
式中:为源项目pi与目标项目p0的数值属性相似度;为源项目pi与目标项目p0的数值属性距离;dis
α
为α数值属性距离取值集合;
[0044]
执行完成后,执行步骤3.224;
[0045]
步骤3.223:当实体属性类型为类别属性时,通过类别匹配来衡量属性的相似度,目标项目与其他源项目的类别属性相似度表示为:
[0046][0047]
式中:为源项目pi与目标项目p0的类别属性相似度;β为某个类型属性;b0为目标项目p0的β属性值;bi为目标项目pi的β属性值;
[0048]
执行完成后,执行步骤3.224;
[0049]
步骤3.224:采用熵值法进行属性相似度权重系数计算;
[0050]
根据步骤3.222和3.223中求得的第j个实体类的k个属性相似度数据集根据步骤3.222和3.223中求得的第j个实体类的k个属性相似度数据集分别进行标准化处理,如下:
[0051][0052]
式中:为标准化后的属性相似度;
[0053]
得到标准化后的数据集之后,计算各相似度值所占比重,如下式所示:
[0054][0055]
式中:为第k个属性相似度集合中第i个源项目的相似度值所占比重,k∈1,...,k,k 表示实体类个数;
[0056]
定义属性信息熵,如下式子所示:
[0057][0058]
式中:h
1jk
为第j个实体类的第k个属性的信息熵;m为源项目个数;
[0059]
将信息熵转化为权重并进行归一化,得到:
[0060][0061]
式中:ω
1jk
为第j个实体类的第k个属性的权重系数;
[0062]
将求得的单个属性值进行加权求和得到总的实体类相似度,计算公式如下:
[0063]
[0064][0065]
式中:为源项目pi与目标项目p0的第j个实体类的属性相似度;ω
1jk
为第j个实体类的第k个属性的权重系数;为目标项目p0与源项目pi第j个实体类的第k个属性的相似度;
[0066]
得到各实体类相似度,如下所示:
[0067][0068]
式中:为第j个实体类相似度;第j个实体类的jaccard相似度;为第j个实体类的属性相似度。
[0069]
优选的,步骤3.23中所述的专家打分法加权计算,如下式所示:
[0070][0071][0072]
式中:为目标项目p0与其他源项目pi的背景相似度,i∈1,...,m,m表示源项目个数;ω
1j
为第j个实体类权重系数;为第j个实体类相似度;n为实体类个数。
[0073]
优选的,步骤4中所述的提炼相关知识,为提炼施工参数预测模型;
[0074]
所述施工参数预测模型的建立包括以下步骤:
[0075]
步骤4.1:将施工数据集进行重复、异常以及缺失清洗操作并进行标准化处理;将处理完成的数据集按时序划分为长度为s的子集,标签值按时序向前平移t个时刻,生成时序数据;将部分时序数据作为训练数据集,另外一部分时序数据划分为测试数据集;
[0076]
步骤4.2:以lstm模型为基础,构建施工参数预测模型;施工参数模型的整体结构包括输入层、lstm层、dropout层、3个全连接层以及输出层;
[0077]
步骤4.3:评估指标采用均方误差、均方根误差、平均绝对误差以及拟合优度r2;
[0078]
所述均方误差的计算公式如下:
[0079][0080]
式中:m为测试数据量,yi为第i个实际值,为第i个预测值;
[0081]
所述均方根误差的计算公式如下:
[0082][0083]
式中:m为测试数据量,yi为第i个实际值,为第i个预测值;
[0084]
所述平均绝对误差公式如下:
[0085][0086]
式中:m为测试数据量,yi为第i个实际值,为第i个预测值;
[0087]
所述拟合优度的计算公式为:
[0088][0089]
式中:m为测试数据量,yi为第i个实际值,为第i个预测值;为所有实际值得均值。
[0090]
优选的,将步骤4.1中所述的时序数据前85%的数据作为训练数据集,后15%的时序数据部分划分为测试数据集。
[0091]
优选的,步骤4.2中所述的lstm层神经元250个,dropout层参数为0.2,3个全连接层的神经元分别为128、64、32个,输出层神经元1个,优化算法采用rmsprop,学习率为0.001,损失函数采用mse,训练模型时采用100个epochs,每个batch设置为128;在其他参数不变的情况下,采用网格搜索对时间步长s和预测时刻t进行参数设置。
[0092]
优选的,所述步骤5包括以下步骤:
[0093]
步骤5.1:在源项目施工数据xs中预先训练得到深度神经网络模型fs(
·
);
[0094]
步骤5.2:将lstm模块的网络复制到目标模型f
t
(
·
)的前端,进行特征关系提取;
[0095]
步骤5.3:根据目标任务y
t
,在网络后端添加重新定义的全连接层以及输出层,定义dense 层、dense_1层、dense_2层神经元分别为128、64、32个,输出层神经元1个;
[0096]
步骤5.4:冻结f
t
(
·
)的lstm模型,使其参数不参加训练,只训练全连接模块;
[0097]
步骤5.5:编译f
t
(
·
)模型,采用学习率为1r=1e-5,训练模型时优化算法为rmsprop,损失函数为mse,通过网格搜索进行epochs和batch超参数调优,重新训练得到适用于目标项目的新模型f
t
(
·
)。
[0098]
综上所述,由于采用了上述技术方案,本发明的有益效果是:本发明通过施工项目知识图谱找到知识之间和项目之间的相关性;基于施工项目背景知识,实现了知识迁移源域的选择,有效解决了迁移源域没有选择依据的难题;并且本发明利用深度学习算法自动进行项目之间的知识匹配,构建了自动化、智能化的施工项目知识转移方法,提高了知识转移的质量与效率,有助于提升企业项目知识管理水平,具有显著的经济效益。
附图说明
[0099]
本发明将通过例子并参照附图的方式说明,其中:
[0100]
图1为本发明的方法流程图;
[0101]
图2为本发明的基于lstm的施工参数预测模型网格结构;
[0102]
图3为本发明的基于网络模型的深度迁移方法;
[0103]
图4为本发明的盾构施工项目知识图谱部分示意图;
[0104]
图5为本发明的lstm模型对project12测试集数据的预测结果。
具体实施方式
[0105]
为使本技术实施例的目的、技术方案和优点更加清楚,下面将结合本技术实施例中附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本技术一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本技术实施例的组件可以各种不同的配置来布置和设计。因此,以下对在附图中提供的本技术的实施例的详细描述并非旨在限制要求保护的本技术的范围,而是仅仅表示本技术的选定实施例。基于本技术的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本技术保护的范围。
[0106]
下面结合附图1和附图2对本发明的实施例作详细描述;
[0107]
一种基于知识图谱和迁移学习的施工项目知识转移方法,包括以下步骤:
[0108]
步骤1:整合所有能够获取到的施工项目资料;
[0109]
步骤2:利用施工项目资料数据,构建施工项目本体库,并抽取施工项目的结构化信息,将抽取的结构化信息存入图数据库,构建施工项目知识图谱;
[0110]
步骤2中所述施工项目知识图谱的构建包括以下步骤:
[0111]
步骤2.1:结合项目施工领域的特征,构建施工项目领域本体;其中,知识本体o
kg
= {te,tf,tr}涵盖实体概念类属性类以及关系类
[0112]
步骤2.2:施工项目领域本体的基础上,从数据资料中抽取出相关的所有实体e= {e1,e2,e3,...}、属性f={f1,f2,f3,...}以及实体之间的关系,将所有非结构和半结构数据进行结构化转变,规范成通用的三元组表示方式;
[0113]
步骤2.3:将抽取出的知识存储到图数据库中。
[0114]
步骤3:从施工项目知识图谱中提取施工项目信息,计算目标项目与知识图谱中的源项目之间的背景相似度;根据目标项目的施工数据,计算目标项目的施工数据与源项目之间的数据相似度,基于背景相似度和数据相似度得到综合相似度,通过综合相似度查询,搜寻到相似度最高的源项目作为知识发送方;
[0115]
步骤3中所述施工项目综合相似度包括以下计算步骤:
[0116]
步骤3.1:在构建好的施工项目知识图谱中,依据各实体概念类提取各施工项目的信息;
[0117]
步骤3.2:采用实体匹配技术进行各施工项目背景实体类相似度计算,再基于专家打分法加权计算得到背景相似度;
[0118]
步骤3.2中所述的背景相似度计算包括以下步骤:
[0119]
步骤3.21:若一个项目与同一实体类中的单个实体关联时,则执行步骤3.22;若一
个项目与同一实体类中的多个实体关联时则执行本步骤,采用基于jaccard相似度的邻居信息匹配方法;评价指标获取两个实体集合的交集和并集,并取交集和并集之间的比值,定义如下:
[0120][0121]
式中:为源项目pi与目标项目p0的第j个实体类的jaccard相似度,i∈1,...,m,m表示源项目个数,j∈1,...,n,n表示实体类个数;a为目标项目p0指向第j个实体类的所有实体集合;
[0122]
步骤3.22:当一个项目只与同一实体类中的单个实体关联时,采用属性匹配方法计算相似度;
[0123]
步骤3.22中所述的步骤属性匹配方法包括如下步骤:
[0124]
步骤3.221:判断实体属性类型,若是数值型属性,则采用数值属性相似度匹配,执行步骤3.222;若是类别属性,则采用类别属性相似度进行匹配,执行步骤3.223。
[0125]
步骤3.222:当实体属性类型为数值型属性时,通过考虑属性值距离来评价属性的相似度,并对相似度结果进行归一化处理;
[0126]
目标项目与其他源项目的数值属性距离表示如下:
[0127][0128]
式中:为源项目pi与目标项目p0的数值属性距离;α为某个数值属性;a0为目标项目p0的α属性值;ai为目标项目pi的α属性值;
[0129]
将距离转化为相似度并归一化后的结果如下:
[0130][0131]
式中:为源项目pi与目标项目p0的数值属性相似度;为源项目pi与目标项目p0的数值属性距离;dis
α
为α数值属性距离取值集合;
[0132]
执行完成后,执行步骤3.224;
[0133]
步骤3.223:当实体属性类型为类别属性时,通过类别匹配来衡量属性的相似度,目标项目与其他源项目的类别属性相似度表示为:
[0134][0135]
式中:为源项目pi与目标项目p0的类别属性相似度;β为某个类型属性;b0为目标项目p0的β属性值;bi为目标项目pi的β属性值;
[0136]
执行完成后,执行步骤3.224;
[0137]
步骤3.224:采用熵值法进行属性相似度权重系数计算;
[0138]
根据步骤3.222和3.223中求得的第j个实体类的k个属性相似度数据集根据步骤3.222和3.223中求得的第j个实体类的k个属性相似度数据集分别进行标准化处理,如下:
[0139][0140]
式中:为标准化后的属性相似度;
[0141]
得到标准化后的数据集之后,计算各相似度值所占比重,如下式所示:
[0142][0143]
式中:为第k个属性相似度集合中第i个源项目的相似度值所占比重,k∈1,...,k,k 表示实体类个数;
[0144]
定义属性信息熵,如下式子所示:
[0145][0146]
式中:h
1jk
为第j个实体类的第k个属性的信息熵;m为源项目个数;
[0147]
将信息熵转化为权重并进行归一化,得到:
[0148][0149]
式中:ω
1jk
为第j个实体类的第k个属性的权重系数;
[0150]
将求得的单个属性值进行加权求和得到总的实体类相似度,计算公式如下:
[0151][0152][0153]
式中:为源项目pi与目标项目p0的第j个实体类的属性相似度;ω
1jk
为第j个实体类的第k个属性的权重系数;为目标项目p0与源项目pi第j个实体类的第k个属性的相似度;
[0154]
得到各实体类相似度,如下所示:
[0155][0156]
式中:为第j个实体类相似度;第j个实体类的jaccard相似度;为第j个实体类的属性相似度。
[0157]
优选的,步骤3.23中所述的专家打分法加权计算,如下式所示:
[0158][0159][0160]
式中:为目标项目p0与其他源项目pi的背景相似度,i∈1,...,m,m表示源项目个数;ω
1j
为第j个实体类权重系数;为第j个实体类相似度;n为实体类个数。
[0161]
步骤3.23:根据求到的各实体类的相似度,基于专家打分法加权计算施工项目与目标项目的背景相似度,专家打分法采用标度法进行设计,打分表中的影响因子类全面涵盖各类实体类因子,每一位专家对两两因子的重要程度进行对比打分,最后累计求和得到每一类影响因子的总得分,并转换为权重系数,加权得到施工项目与目标项目的背景相似度。
[0162]
步骤3.3:利用最大均值偏差,计算施工数据相似度,计算公式如下:
[0163][0164]
将目标项目与源项目的施工数据放入上述公式中计算得到分布距离,再将距离进行归一化处理,并转化为相似度;
[0165][0166]
式中,为目标项目p0与其他源项目pi的施工数据相似度,为目标项目p0与其他源项目pi的施工数据mmd距离;
[0167]
步骤3.4:计算施工项目综合相似度,计算公式如下:
[0168][0169]
式中:分别为目标项目p0与其他源项目pi的综合相似度、项目背景相似度、施工数据相似度的度量值;h0为目标项目的施工进度;h
t
为目标项目的总工程量。
[0170]
步骤4:若源项目中存在已提炼的相关知识,则转移该知识;若源项目中不存在已提炼的相关知识,则利用源项目的数据提炼出相关知识,再进行迁移;
[0171]
步骤4中所述的提炼相关知识,为提炼施工参数预测模型;
[0172]
所述施工参数预测模型的建立包括以下步骤:
[0173]
步骤4.1:将施工数据集进行重复、异常以及缺失清洗操作并进行标准化处理;将处理完成的数据集按时序划分为长度为s的子集,标签值按时序向前平移t个时刻,生成时序数据;将部分时序数据作为训练数据集,另外一部分时序数据划分为测试数据集;
[0174]
步骤4.2:以lstm模型为基础,构建施工参数预测模型;施工参数模型的整体结构包括输入层、lstm层、dropout层、3个全连接层以及输出层;步骤4.2中所述的lstm层神经元250个,dropout层参数为0.2,3个全连接层的神经元分别为128、64、32个,输出层神经元1个,优化算法采用rmsprop,学习率为0.001,损失函数采用mse,训练模型时采用100个epochs,每个batch设置为128;在其他参数不变的情况下,采用网格搜索对时间步长s和预测时刻t进行参数设置。
[0175]
步骤4.3:评估指标采用均方误差、均方根误差、平均绝对误差以及拟合优度r2;
[0176]
所述均方误差的计算公式如下:
[0177][0178]
式中:m为测试数据量,yi为第i个实际值,为第i个预测值;
[0179]
所述均方根误差的计算公式如下:
[0180][0181]
式中:m为测试数据量,yi为第i个实际值,为第i个预测值;
[0182]
所述平均绝对误差公式如下:
[0183][0184]
式中:m为测试数据量,yi为第i个实际值,为第i个预测值;
[0185]
所述拟合优度的计算公式为:
[0186][0187]
式中:m为测试数据量,yi为第i个实际值,为第i个预测值;为所有实际值得均值。
[0188]
优选的,将步骤4.1中所述的时序数据前85%的数据作为训练数据集,后15%的时序数据划分为测试数据集。
[0189]
步骤5:以步骤4中提炼的相关知识中的施工参数预测模型作为知识转移目标,采用基于网络模型的深度迁移学习方法,进行从源项目到目标项目的模型迁移,将知识自适应地转移到目标项目。
[0190]
所述步骤5包括以下步骤:
[0191]
步骤5.1:在源项目施工数据xs中预先训练得到深度神经网络模型fs(
·
);
[0192]
步骤5.2:将lstm模块的网络复制到目标模型f
t
(
·
)的前端,进行特征关系提取;
[0193]
步骤5.3:根据目标任务y
t
,在网络后端添加重新定义的全连接层以及输出层,定义dense 层、dense_1层、dense_2层神经元分别为128、64、32个,输出层神经元1个;
[0194]
步骤5.4:冻结f
t
(
·
)的lstm模型,使其参数不参加训练,只训练全连接模块;
[0195]
步骤5.5:编译f
t
(
·
)模型,采用学习率为1r=1e-5,训练模型时优化算法为rmsprop,损失函数为mse,通过网格搜索进行epochs和batch超参数调优,重新训练得到适用于目标项目的新模型f
t
(
·
)。
[0196]
本发明利用知识图谱表示施工项目知识和项目场景的方法,引入迁移学习思想进行待转移项目知识选取的方法,以及使该知识适配目标场景的迁移方法,数据驱动的跨项目知识转移系统原型,为自动、智能地对转移过程中的知识选取、调整以及转移环节设置提出了可行的方案,实现了施工企业的项目知识的共享以及运用,提高了项目知识的管理水平。
[0197]
以下以某盾构施工项目为对象,对本发明的一种基于知识图谱和迁移学习的施工项目知识转移方法进行详细的说明;
[0198]
对应上述步骤1:收集所有可获得的施工项目数据资料,得到盾构施工项目数据资料及类型(如表1所示),进行清理和整合,得到盾构施工数据详情表(如表2所示);
[0199]
表1:盾构施工项目数据资料及类型
[0200][0201][0202]
表2:盾构施工项目数据详情表
[0203]
盾构施工项目盾构机原始数据文件格式测点数量数据量project 0shield 0.csv20055542project 1shield 1.csv19786956project 2shield 2.csv19759926project 3shield 3.csv1904805project 4shield 3.dat19041292project 5shield 4.dat195417792project 6shield 4.dat19536082
project 7shield 4.dat19033032project 8shield 5.dat19327704project 9shield 6.dat18594243project 10shield 7.dat383106160project 11shield 8.dat38341292project 12shield 9.csv200148691project 13shield 10.csv104437922project 14shield 11.csv104365632project 15shield 12.csv125113127project 16shield 13.csv125108170
[0204]
对应上述步骤2:利用施工数据资料,构建施工项目本体库,如表3所示;将抽取的结构化知识存入图数据库,存储结果如表4所示,盾构施工项目知识图谱部分可视化如图4所示;
[0205]
表3:盾构施工项目知识图谱的实体概念类与属性
[0206][0207][0208]
表4:知识图谱示例存储结果
[0209]
实体数量关系数量属性数量1692811258
[0210]
对应上述步骤3:从构建好的施工项目知识图谱中提取施工项目知识,选取project 0作为目标项目,其余15个项目作为待选源项目(由于从表2中可以看出,project 3的数据量太少,不适合作为迁移源域,故排除),计算施工项目综合相似度,得到结果如表5所示,通过相似度关系查询,快速匹配到相似度较高的项目知识,搜寻到最相似的源项目project 12 作为知识发送方;
[0211]
表5:施工项目综合相似度的度量结果
[0212][0213][0214]
对应上述步骤4:基于长短时记忆网络(lstm),在源项目project 12施工数据中构建盾构施工参数预测模型,在测试集中的预测结果如图5所示,蓝色为刀盘扭矩(单位:
×
1000kn
·
m) 预测值,橙色为刀盘扭矩实际观测值,可以发现两条曲线较为吻合,拟合结果较好,mse、 rmse、mae分别只有0.15、0.39、0.23,且r2达到0.91,说明本发明构建的lstm盾构施工预测模型具有很好的表现,能够较为准确的提前预测出施工参数取值。
[0215]
对应上述步骤5:以源项目project 12的lstm施工参数预测模型作为知识转移目标,采用基于网络模型的深度迁移学习方法deeptl_lstm,进行从源项目project 12到目标项目 project 0的模型迁移,将project 12的迁移结果与其他相似度相对较高的项目迁移结果进行比较,结果表明通过本发明提供的方法能够有效地将知识自适应地转移到目标项目,如表6所示;
[0216]
表6:将源项目模型迁移到目标项目后的模型预测结果
[0217][0218]
基于表6可以看出,本发明采用的deeptl_lstm自适应迁移方法在各项目下的迁移结果,都优于模型直接迁移;并且本发明选取出的最佳迁移源项目project 12的实际迁移效果最好,mse、rmse、mae都最低,而且r2表现最好。
[0219]
以上所述实施例仅表达了本技术的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本技术保护范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术技术方案构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1