基于深度学习的弥散微循环模型驱动参数估计方法、装置及介质
1.本技术涉及磁共振成像优化与数据模型拟合领域,尤其涉及弥散微循环模型的参数估计方法优化、装置及存储介质。
背景技术:
2.弥散磁共振成像(dmri)是一种基于水分子在生物组织中受限弥散的无创探测组织微结构的重要医学成像工具。常用的表观弥散系数(adc)是用一个指数来计算的,该模型对脑卒中、肿瘤等病理变化敏感,但对微观结构特性不敏感。现在发展出了先进的生物物理模型来表征特定的微结构特性,如弥散张量成像(dti)、弥散峰度成像(dki)、体素内不相干运动模型(ivim)和其他房室模型。
3.准确的估计微结构特性的模型参数对诊断具有重要意义。然而,大多数dmri模型由多个数学上复杂且高度非线性的部分组成。用最小二乘法等传统的优化技术对这些模型进行拟合,容易产生估计误差。此外,从数据获取的角度来看,先进的dmri模型需要在q空间中获取多个b值和弥散方向,这既耗时又容易受到运动伪影的影响。
4.深度学习技术为dmri模型拟合开辟了新的途径。q空间学习的方法是一种基于多层感知器(mlp)的方法,它利用q空间数据的一个子集来估计dti参数。然而,它与生物物理模型无关,因此很难被解释。在深层神经网络中引入领域知识作为先验信息被认为是提高网络性能和可解释性的有效途径。此外,mlp框架在捕获图像中丰富信息方面的能力有限。卷积网络被设计用于图像特征提取,但由于感知野固定,卷积网络的应用受到限制。在q空间深度学习方法中加入适应动态感知野的自注意机制,提高学习性能,形成transformer结构。
技术实现要素:
5.为了克服现有采集技术时间长、受运动影响大的缺点和深度学习方法可解释性差的缺点,本发明提出了一种基于深度学习的弥散微循环模型驱动参数估计方法,该方法借助深度学习方法,结合弥散微循环模型的物理原理,利用transformer结构的长距离建模能力和深度神经网络的万能逼近性原理,可以通过少数b值的q空间信息拟合,有效的缩短采集数据所消耗的时间,并且能够比现有的参数估计方法有更小的误差。
6.为了达到上述目的,本发明采用以下技术方案予以实现:
7.第一方面,本发明提供了一种基于深度学习的弥散微循环模型驱动参数估计方法,用于估计弥散微循环模型的模型参数,其包括以下步骤:
8.s1、对多b值下采集的磁共振弥散加权图像进行多b值间的循环配准,对配准后的图像进行感兴趣区域的划分;
9.s2、以s1中得到的多b值下图像感兴趣区域中体素的信号值为拟合数据,采用贝叶斯估计方法对弥散微循环模型进行参数拟合,得到视为金标准的弥散微循环模型的模型参
数;
10.s3、在s1采集的磁共振弥散加权图像基础上,取其中部分b值作为b值组合,将b值组合中各个b值对应的弥散磁共振信号作为输入,将对应体素中s2中拟合得到的模型参数作为真值标签,构建为缺省b值的训练数据;利用缺省b值的训练数据训练一个弥散微循环模型驱动的深度学习网络,训练完毕后得到参数估计模型;
11.所述深度学习网络由编码器部分和一个基于弥散微循环模型的稀疏编码深度神经网络(scdnn)解码器组成;在编码器部分中,输入训练数据中不同b值下以每个待估计体素为中心的图像块,先经过图像块编码后依次经过多个transformer编码器,将最后一个transformer编码器的输出作为解码器的输入;在解码器中,将通过稀疏编码深度神经网络迭代单元的信号与未经过迭代的输出信号相叠加,反复迭代后输出待估计体素对应的模型参数估计值;
12.s4、获取待估计对象在所述b值组合中各个b值下采集的磁共振弥散加权图像,通过配准、感兴趣区域划分后,输入参数估计模型中,估计得到弥散微循环模型的模型参数。
13.基于该方案,各步骤还可以进一步提供以下优选的实现方式。需要注意的是,各优选方式中的技术特征在没有冲突的情况下均可进行相互组合。当然这些优选方式也可以通过其他能够实现相同技术效果的方式实现,不构成限制。
14.作为优选,所述s1的实现方法如下:
15.针对每个被试个体,分别获得多个b值各自对应的磁共振弥散加权图像(dwi),并通过循环配准对各b值图像之间进行运动伪影校正;循环配准时,首先对各b值的图像进行平均,得到平均模板,再通过刚体变换和仿射变换将所有b值的图像与平均模板进行比对配准,然后将配准之后得到的图像再次进行平均,得到新的平均模板,得到新的平均模板后再次进行比对配准,如此循环6~10次,得到每个b值下扩散加权图像的配准结果;最终在配准结果基础上对感兴趣区域进行划分。
16.作为优选,所述s2中,所述的弥散微循环模型如下所示:
[0017][0018]
其中:s
b
为b值下的信号值,s0为没有扩散加权时的信号值,f是微循环的体积分数,d是组织水分子的弥散系数,d
*
是微循环血液中水分子的伪弥散系数,f,d,d
*
均为待拟合的模型参数。
[0019]
作为优选,所述s3中,缺省b值的训练数据中的每一个样本均包含一个体素x的序列数据组合以及该体素x对应的模型参数真值标签,体素x的序列数据组合包括所述b值组合中不同b值对应的序列数据,且每一个b值对应的序列数据由该b值对应的磁共振弥散加权图像中以该体素x为中心的图形块中每一个体素的归一化弥散加权信号s
b
/s0按序组成;所述b值组合中的b值数量优选为不小于3,进一步优选为3~5。
[0020]
作为优选,所述s3中,所述编码器部分由全连接层以及多个transformer编码器连接而成,输入样本中的序列数据组合通过全连接层进行编码后,再依次经过多个transformer编码器,且前一个transformer编码器的输出作为下一个transformer编码器的输入,最后一个transformer编码器的输出作为编码器部分的输出,用于输入解码器;在每一个transformer编码器中,transformer编码器的原始输入先通过层归一化后输入多头注意力机制层,再通过残差连接将多头注意力机制层的输出和未经过层归一化的原始输入
进行叠加,得到新的输入,随后将这个新的输入依次通过层归一化层和两层全连接层后,再将得到的输出与所述新的输入相加得到该transformer编码器的最终输出。
[0021]
作为优选,基于弥散微循环模型的scdnn解码器构建方法如下:
[0022]
scdnn解码器是一种基于弥散微循环模型驱动的解码器,通过使用迭代算法将弥散微循环模型进行展开,得到所构建的解码器。其中弥散微循环模型如下所示:
[0023][0024]
其中f是灌注分数,d是水分子弥散系数,d
*
是水分子伪弥散系数。
[0025]
通过将弥散微循环模型得到的信号进行字典化的方法,将原有的模型进行了线性化的处理。如下所示:
[0026][0027]
其中,y为观测到的信号,为由离散化的组织水分子的弥散系数d和微循环血液中水分子的伪弥散系数d
*
所构成的字典向量,x为由离散化的f所构成字典的系数向量。通过对该线性化的模型,构建如下所示的目标函数来进行求解:
[0028][0029]
其中,β为其正则化系数。通过使用硬阈值迭代算法将该目标函数的求解过程进行展开,展开过程如下所示:
[0030]
x
n+1
=h
m
(wy+sx
n
)
[0031]
其中h
m
为非线性的算子。当输入值的绝对值小于其设定的阈值时为0,大于等于阈值时,保持不变。依据上述过程,即可通过组合卷积层、批归一化层、阈值层和卷积层构建形成解码器。
[0032]
因此,所述s3中解码器的具体模型结构如下:解码器接收编码器部分的输出作为输入,首先将该输入依次通过卷积层、批归一化层、阈值层和卷积层后得到输出信号,随后将这一输出信号输入连续的迭代单元,迭代单元依照字典构建的方法进行设计,从而通过迭代过程实现字典的构建;每个迭代单元中输入信号依次经过阈值层和卷积层阈值层为一非线性算子,卷积层则对通道内的数据进行组合,之后将卷积层输出的信号与该迭代单元的原始输入信号通过残差连接相叠加,作为通过该迭代单元后的输出信号并作为下一个迭代单元的输入信号;第n个迭代单元中通过对信号的处理实现硬阈值迭代算法在弥散微循环模型中的通项表达式:x
n+1
=h
m
(wy+sx
n
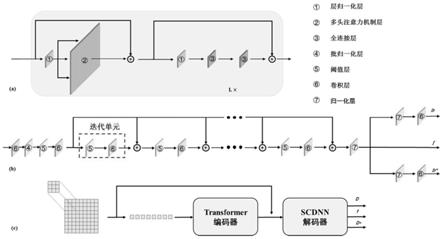
),其中权重为由离散化的组织水分子的弥散系数d和微循环血液中水分子的伪弥散系数d
*
所构成的字典向量,i是单位矩阵,h
m
为非线性的算子,y为观测到的信号,x
n
和x
n+1
分别代表第n个迭代单元的输入信号和输出信号;如此进行反复迭代,得到通过所有迭代单元后的最终输出信号,将最终输出信号输入归一化层后,得到体积分数f,通过归一化后,使信号限制在0~1,满足实际生理状况;再将通过归一化层的输出分为等长的两部分,分别进行再次归一化后输入两个不同卷积层进行信号组合,一个卷积层输出由离散化的组织水分子的弥散系数d重新组合的结果,另一个卷积层输出由离散化的微循环血液中水分子的伪弥散系数d
*
重新组合的结果。
[0033]
作为优选,所述s3中,所述深度学习网络在训练时,每一个训练批次均通过最小化总损失函数进行网络参数优化,所述总损失函数为每一个训练批次中所有输入样本的损失
函数值之和,每一个输入样本的损失函数由输出的模型参数估计结果与真值标签的绝对误差如下所示:
[0034][0035]
其中,[f,d,d
*
]为模型参数中三个参数的金标准值,为深度学习网络输出的模型参数中三个参数估计值。
[0036]
作为优选,所述s4中,待估计对象的磁共振弥散加权图像,按照与训练数据中样本相同做法进行配准和感兴趣区域划分。
[0037]
第二方面,本发明提供了一种弥散微循环模型驱动深度学习网络的参数估计装置,其包括存储器和处理器;
[0038]
所述存储器,用于存储计算机程序;
[0039]
所述处理器,用于当执行所述计算机程序时,实现如第一方面中任一项所述的基于深度学习的弥散微循环模型驱动参数估计方法。
[0040]
第三方面,本发明提供了一种计算机可读存储介质,其特征在于,所述存储介质上存储有计算机程序,当所述计算机程序被处理器执行时,实现如第一方面中任一项所述的基于深度学习的弥散微循环模型驱动参数估计方法。
[0041]
相对于现有技术,本发明具有以下有益效果:
[0042]
本发明提供了一种基于深度学习的弥散微循环模型驱动参数估计方法,可以仅通过少数b值数据即能达到多b值的参数拟合效果,在实际的操作中具有缩短采集时间的作用。并且由于体素不相干运动成像在数学上是一种复杂且高度非线性的模型,用最小二乘法等传统的优化技术对其进行拟合时容易产生估计误差,造成错误的判断。同时由于传统的优化算法是基于迭代的优化方法,需要较长的时间来进行迭代。而传统的q空间的学习方法为一个黑箱模型,不具有解释性。本发明在结合传统的弥散磁共振模型拟合方法和深度学习方法,将弥散微循环模型的迭代求解过程转化为深度学习网络。该方法能够在有效减少采集b值数据的同时,减少在求解特征参数时所需要的时间。相较于q空间的深度学习方法,本方法不仅在拟合的准确率上有较大提升,同时更具备模型的解释性。
附图说明
[0043]
图1为基于模型驱动深度学习网络示意图。
[0044]
图2为本发明与其他网络的结果对比,其中(a)为本发明的编码器与卷积编码器的结果对比,(b)为本发明的解码器与q空间解码器的结果对比。
[0045]
图3为信噪比为10~70时弥散微循环模型参数估计的相对误差。
[0046]
图4为本发明深度学习网络的多中心比较结果。
具体实施方式
[0047]
下面基于本发明提出的方法结合实施例展示其具体的技术效果,以便本领域技术人员更好地理解本发明的实质。
[0048]
本发明通过将一种基于dmri微循环模型(即ivim模型)的物理机制和深度学习方法相结合,取得了较好的效果。
[0049]
在本发明的一个较佳实施例中,以胎盘为例,提供了一种基于深度学习的弥散微
循环模型驱动参数估计方法,该方法用于估计弥散微循环模型的模型参数,具体包括以下步骤:
[0050]
步骤一:在人体磁共振系统上,通过单次激发的弥散加权的epi序列采集胎盘的多b值磁共振弥散加权图像(dwi)。初始采集的多b值dwi中所需覆盖的b值及数量可根据实际进行调整。在本实施例中,以人体胎盘数据为例,在1.5t ge磁共振系统上,通过单次激发的弥散加权的epi序列采集包含b值为0,10,20,50,80,100,150,200,300,和500s/mm2的10个b值的dwi,扫描对象为29例怀孕孕周在13~37周的正常孕妇。
[0051]
由于成像需要采集的b值较多,所以影像采集的时间较长,且宫内成像易受孕妇腹部的呼吸运动和胎儿的不规律运动影像。为了确保所有不同b值影像空间的一致性,使之后每个体素参数的计算更精确,需要先针对每一位被试个体在多b值下采集的dwi进行配准,去除母体呼吸、胎儿运动导致的各个b值扩散加权图像间的位移,使得不同b值的图像中组织结构在空间上达到一致,消除运动伪影的影响。在本发明中,采用循环配准来实现运动伪影的校正,具体做法如下:首先对各b值的dwi进行平均,得到平均模板,再通过刚体变换和仿射变换将所有b值的dwi分别与平均模板进行比对配准,然后将配准之后得到的所有b值的dwi再次进行平均,得到新的平均模板,得到新的平均模板后再次进行比对配准,如此循环6~10次,即可得到每个b值下扩散加权图像的配准结果。由于人体胎盘的dwi中还含有除了胎盘之外的其他组织图像,因此在完成图像的配准后,最终还需要在配准结果基础上对感兴趣区域进行划分,此处感兴趣区域即图像中的胎盘区域。
[0052]
当然在其他的实施例中,具体的感兴趣区域需要根据实际的研究需要进行选择,对此不做限定。
[0053]
步骤二:由于前述的人体胎盘的dwi用于深度学习网络训练时,需要预先带有真值标签,因此需要先利用目前公认的准确的计算方法金标准作为其标签值。在本实施例中,以s1中得到的多b值下图像感兴趣区域中体素的信号值为拟合数据,采用贝叶斯估计方法对弥散微循环模型进行参数拟合,得到视为金标准的弥散微循环模型的模型参数。
[0054]
其中,弥散微循环模型如下所示:
[0055][0056]
其中:s
b
为b值下的信号值,s0为没有扩散加权时的信号值,f是微循环的体积分数,d是组织水分子的弥散系数,d
*
是微循环血液中水分子的伪弥散系数,f,d,d
*
均为待拟合的三个模型参数。
[0057]
在进行本步骤的拟合时,其拟合数据为10个b值下的dwi的感兴趣区域中体素的信号值,由于拟合时是对单个体素进行的,因此拟合的自变量和因变量也分别是对应的单个体素中的数据。
[0058]
当获得dwi的感兴趣区域中每个体素对应的真值标签后,后续即可采用深度学习的方法,通过拟合得的数据进行训练,得到特征参数,下面描述其具体做法。
[0059]
步骤三:在s1采集的磁共振弥散加权图像基础上,取其中部分b值作为b值组合,将b值组合中每一个b值对应的图像感兴趣区域结合s2中拟合得到的模型参数作为真值标签,构建为缺省b值的训练数据;利用缺省b值的训练数据训练一个弥散微循环模型驱动的深度学习网络,训练完毕后得到参数估计模型。
[0060]
在本发明中,虽然前述的贝叶斯估计方法拟合模型参数金标准时需要用到所有的
b值,但是采集的b值过多将导致采集耗时过长,因此我们希望深度学习网络所需的b值相对于贝叶斯估计方法所需的b值更少,也就是少于本实施例中的10个b值。因此,本实施例中,从10个b值中仅取出m个b值记为b值组合,深度学习网络仅需b值组合中各b值所对应的dwi数据,即可实现感兴趣区域中每一个体素的弥散微循环模型参数估计。但b值组合中的b值数量m也不能过少,否则估计精度将会很差,综合考虑精度和采集耗时,m优选为3~5。
[0061]
因此,上述缺省b值的训练数据中的每一个样本都是针对感兴趣区域中的一个体素构建的,因此深度学习网络是逐体素进行输入与输出从而实现训练的。对于任意一个体素x对应的样板,其包含体素x的序列数据组合以及该体素x对应的模型参数真值标签,体素x的序列数据组合包括前述b值组合中不同b值对应的序列数据,且每一个b值对应的序列数据由该b值对应的磁共振弥散加权图像中以该体素x为中心的图形块中每一个体素的归一化弥散加权信号s
b
/s0按序组成。在实际的处理过程中,可将每一个b值对应的dwi用一个n*n的提取框进行逐体素滑动扫描,每一个提取框的中心体素即为样本所对应的体素x,而n*n个体素的归一化弥散加权信号s
b
/s0按序组合成n*n长度的一维序列数据。同一个体素x在不同b值的dwi中得到的一维序列数据即组成了样本中的序列数据组合,结合在第二步中得到的该体素x对应的模型参数真值标签,即可形成一个完整的带标签的样本。本实施例中,n优选为3。
[0062]
本发明设计的基于模型驱动深度学习网络由编码器部分和一个基于弥散微循环模型的稀疏编码深度神经网络(scdnn)解码器组成。编码器部分由层归一化层,多头注意力机制层,全连接层和残差连接等构成,其中包含了多个transformer编码器。在编码器部分中,输入训练数据中不同b值下以每个待估计体素为中心的图像块,先经过图像块编码后依次经过多个transformer编码器,将最后一个transformer编码器的输出作为解码器的输入。解码器是一种基于模型驱动的解码器,通过使用迭代算法将步骤二中弥散微循环模型通过多层神经网络进行展开,得到所构建的解码器。在解码器中,将通过稀疏编码深度神经网络迭代单元的信号与未经过迭代的输出信号相叠加,反复迭代后输出待估计体素对应的模型参数估计值。
[0063]
上述解码器是基于弥散微循环模型驱动的,通过将弥散微循环模型得到的信号进行字典化的方法,将原有的模型进行了线性化的处理,如下所示:
[0064][0065]
其中,y为观测到的信号,为由离散化的d和d
*
所构成的字典向量,x为由离散化的f所构成字典的系数向量。通过对该线性化的模型,构建如下所示的目标函数来进行求解:
[0066][0067]
其中,β为其正则化系数。通过使用硬阈值迭代算法将该目标函数的求解过程进行展开,展开过程如下所示:
[0068]
x
n+1
=h
m
(wy+sx
n
)
[0069]
其中h
m
为非线性的算子。当输入值的绝对值小于其设定的阈值时为0,大于等于阈值时,保持不变。依据上述过程,即可通过组合卷积层、批归一化层、阈值层和卷积层构建形成解码器。
[0070]
下面结合图1,对深度学习网络中编码器部分和解码器的具体结构进行详细描述
[0071]
如图1中的(c)所示,编码器部分由用于编码的全连接层以及多个transformer编码器连接而成(transformer编码器的数量表示为l个),而解码器部分则连接与编码器部分之后。
[0072]
在编码器部分中,输入样本中的序列数据组合先通过全连接层进行编码,再依次经过多个transformer编码器,全连接层的编码结果输入第一个transformer编码器中,而除了第一个transformer编码器之外的其他transformer编码器,则以前一个transformer编码器的输出作为下一个transformer编码器的输入,最后一个transformer编码器的输出作为编码器部分的输出,用于输入解码器。如图1中的(a)所示,展示了单个transformer编码器的结构,每一个transformer编码器的结构相同,包含了层归一化层、多头注意力机制层、残差连接和全连接层,该transformer编码器的原始输入先经过层归一化后输入多头注意力机制层,再通过残差连接将多头注意力机制层的输出和未经过层归一化的原始输入进行叠加,得到新的输入;随后将这个新的输入依次通过层归一化层和两层全连接层后,再将得到的输出与该新的输入相加得到该transformer编码器的最终输出。
[0073]
而如图1中的(b)所示,展示了解码器的结构,解码器接收编码器部分的输出作为输入。在解码器中,首先将编码器部分输出作为输入,依次通过卷积层、批归一化层、阈值层和卷积层后得到输出信号,随后将这一输出信号输入连续的迭代单元,迭代单元依照字典构建的方法进行设计,从而通过迭代过程实现字典的构建。第一个迭代单元的输入是前述卷积层的输出信号,而后续迭代单元的输入均为前一个迭代单元的输出。每个迭代单元是由阈值层、卷积层和残差连接组成的,每个迭代单元中输入信号依次经过阈值层和卷积层后,阈值层为一非线性算子,卷积层则对通道内的数据进行组合,之后将卷积层输出的信号与该迭代单元的原始输入信号通过残差连接相叠加,作为通过该迭代单元后的输出信号并作为下一个迭代单元的输入信号。每个迭代单元的上述层结构都是为了通过对信号的处理实现硬阈值迭代算法在弥散微循环模型中的通项表达式,对于任意第n个迭代单元而言其实现的通项表达式为:x
n+1
=h
m
(wy+sx
n
),其中权重为由离散化的组织水分子的弥散系数d和微循环血液中水分子的伪弥散系数d*所构成的字典向量,i是单位矩阵,h
m
为非线性的算子,y为观测到的信号,x
n
和x
n+1
分别代表第n个迭代单元的输入信号和输出信号。如此进行反复迭代,得到通过所有迭代单元后的最终输出信号。基于该最终输出信号,可以计算模型参数中的三个不同参数,但计算三个不同参数的方法略有不同:对于体积分数f而言,将最终输出信号输入一层归一化层后,即可得到体积分数f,通过归一化后可使信号限制在0~1,满足实际生理状况;但对于另外两个参数而言,需要将通过前述归一化层的输出再按照长度分为等长的两部分,分别进行再次归一化后输入两个不同卷积层,两个卷积层分别输出组织水分子的弥散系数d和微循环血液中水分子的伪弥散系数d
*
离散化信号重新组合的结果,也就是说等长的两部分分别进入两条网络分支,第一条网络分支中将一部分输出信号线经过一层归一化层后再经过卷积层,得到由离散化的组织水分子的弥散系数d重新组合的结果,第二条网络分支中将另一部分输出信号线经过一层归一化层后再经过卷积层,得到由离散化的微循环血液中水分子的伪弥散系数d
*
重新组合的结果。
[0074]
需说明的是,本发明中所谓的阈值层,起到了类似激活函数的作用,当阈值层的输入值大于预设阈值时将其置0输出,若阈值层的输入值大于等于预设阈值时,将输入值保持
不变进行输出。
[0075]
上述深度学习网络可利用前述带标签的训练数据进行分批次训练,当网络精度达到要求后即可作为参数估计模型。在训练时,每一个训练批次(batch)均通过最小化总损失函数进行网络参数优化,而总损失函数为每一个训练批次中所有输入样本的损失函数值之和,每一个输入样本的损失函数由输出的模型参数估计结果与真值标签的绝对误差如下所示:
[0076][0077]
其中,[f,d,d
*
]为模型参数中三个参数的金标准值,为深度学习网络输出的模型参数中三个参数估计值,[f,d,d
*
]和一一对应计算绝对误差后加和即可得到该样本的损失函数值。
[0078]
步骤四:在实际应用时,可按照与步骤一相同的做法,获取待估计对象在前述b值组合中每个b值下采集的dwi,通过与训练数据中样本相同的配准、感兴趣区域划分后,输入参数估计模型中,估计得到弥散微循环模型的模型参数。而且,在参数估计模型中也是按照逐像素对其进行模型参数估计的,每一个像素以自身为中心点形成n*n的图像块,进而形成网络的输入。
[0079]
由此,本发明仅采用3
‑
5个b值的dwi,即可通过该参数估计模型得到胎盘图像中每个体素的f、d和d*三个特征参数,这可以大大减少获得孕妇的多b值dwi所需的采样次数,缩短采集所需的时间而不影响特征参数重建效果。
[0080]
下面基于上述方法的步骤一到四,结合实施例对其技术效果进行展示,以便本领域技术人员更好地理解本发明的实质。
[0081]
实施例
[0082]
将上述基于深度学习的弥散微循环模型驱动参数估计方法在29名孕期在13~37周的被试数据中进行了测试,具体步骤的基本流程如前所述。磁共振扫描在通用电气signa hdxt 1.5t磁共振扫描仪上进行,采用扩散加权的平面回波成像序列从母体矢状位采集胎盘图像:回波时间(te)/重复时间(tr)=76/3000ms,视野(fov)=320
×
320mm,平面内分辨率为1.25
×
1.25mm,层厚4mm,共15层,共采集10个b值的数据,分别为0,10,20,50,80,100,150,200,300和500s/mm2。29例怀孕孕周在13~37周的正常孕妇样本将按照6∶2∶2的比例,将其划分为训练集,验证集和测试集。其中训练集中有15例样本(324016个体素),验证集中有4例样本(11628个体素),测试集中有5例样本(131867个体素)。
[0083]
同时为了对比展示本发明的技术效果,本实施将神经网络在测试集中得到的结果与拟合得到的金标准和其他方法得到的结果进行对比,同时进行了不同噪声条件下的抗噪声能力检验和多中心的泛化能力检验。实验结果如图2~4所示:
[0084]
图2(a)为q
‑
空间学习解码器(q
‑
space解码器)与本发明提出的稀疏编码深度神经网络(scdnn解码器),在5个b值输入(20,50,150,300,500s/mm2)时的比较结果。q空间学习解码器是按照golkov的方法设计的,它由三个完全连通的全连接层和非线性激活relu组成。图2(a)中的结果显示,与q空间学习解码器相比,从scdnn解码器估计的模型参数与真实值实有更高的相关性。scdnn解码器比q空间学习解码器的估计误差更低,特别是对于δf和δd*图。
[0085]
图2(b)为基于深度学习的弥散微循环模型驱动参数估计方法编码器(transformer编码器)与卷积编码器(conv2d编码器),在5个b值输入(20,50,150,300,500s/mm2)时的比较结果。卷积编码器由卷积层、批处理归一化层和修正线性单元激活函数组成。图2(b)中相关性图和δf、δd、以及δd*图的结果表明,transformer编码器提供了更准确的弥散微循环模型参数估计。
[0086]
图3为图像信噪比影响参数估计结果的实验。在信噪比级别从10到70的图像中我们评估了不同信噪比级别下的相对误差(误差占真实值的百分比)。图3(a)显示,f的相对误差随着信噪比的增加而逐渐减小,并在信噪比大于40时趋于稳定。相反,d的估计对信噪比相对不敏感(图3(b))。d*的相对误差随信噪比的变化不大,稳定在信噪比大于40时,结果表明基于深度学习的弥散微循环模型驱动参数估计方法对噪声具有较强的鲁棒性,信噪比大于40时可以保证最佳的估计精度。
[0087]
图4为多中心的验证实验。之前的训练、验证和测试是使用在1.5t通用电气signa hdxt扫描仪上采集的数据上进行的,在这里,我们使用相同采集协议在另一家医院的3.0t通用电气750w上采集的数据测试了网络性能。新的测试数据包括2例正常被试(37194个体素)。结果表明,多中心数据的估计误差略有增加,但仍足以进行参数估计。
[0088]
同时,本发明还比较了在不同数量b值,和不同组合b值的情况下基于深度学习的弥散微循环模型驱动参数估计方法的误差表现,如表1所示。我们选择了5个b值的子集,分别为20、50、150、300、500s/mm2。在这里,我们测试了表1中列出的其他四种组合,对于每个模型参数,具有最佳性能的组合以粗体突出显示。总体而言,20、50、150、300、500s/mm2的b值组合实现了所有三个弥散微循环模型参数估计精度的最佳平衡。同时我们测试了不同数量b值的影响。表1显示,当b值从3增加到5时,均方误差显著降低,但b值从5增加到7时,扫描时间为5个b值时的1.4倍,可是对于误差降低的提升有限。
[0089]
表1:采用不同的b值组合的dwi数据估计的弥散微循环模型参数与金标准相比的均方误差(mse)。
[0090][0091]
此外本发明还进行了与传统算法和其他深度学习算法的对比。表2比较了四种不
同的算法,包括两种传统优化方法:最小二乘法(lsq)和贝叶斯方法(bayesian),以及两种基于学习的方法:q
‑
space深度学习和scdnn(不带transformer)。与最小二乘法和贝叶斯方法相比,基于学习的方法具有更高的估计精度。在基于学习的方法中,模型驱动的方法的性能优于无先验信息的q空间学习,基于深度学习的弥散微循环模型驱动参数估计方法(metsc)的性能最好。
[0092]
表2:比较五种方法在使用减少的b值(20、50、150、300、500s/mm2)估计弥散微循环模型参数的均方误差(mse),每种算法与metsc的配对t检验,*p<0.05,**p<0.01,***p<0.001。
[0093][0094]
同时,本发明还比较了在所有的测试数据上,不同的结构(q
‑
space解码器/scdnn解码器、transformer编码器/卷积编码器、块图像(将原始图像按照重叠的分割成若干块)/非块图像(不对原始图像进行操作)输入、位置编码(通过学习得到的1
‑
d位置编码信息)/非位置编码(无位置信息))对于微循环参数估计的影响,如表3所示。将这表明,现有的结构在具有最好的性能。
[0095]
表3:在五个测试数据(约131867个体素)上,使用不同的编码器、解码器、输入形式和位置编码的metsc的均方误差(mse)。对四组比较分别进行配对t检验,*p<0.05,**p<0.01,***p<0.001。
[0096][0097]
另外,在其他实施例中,还可以提供一种基于深度学习的弥散微循环模型驱动参数估计装置,其包括存储器和处理器;
[0098]
所述存储器,用于存储计算机程序;
[0099]
所述处理器,用于当执行所述计算机程序时,实现前述的基于深度学习的弥散微循环模型驱动参数估计方法。
[0100]
另外,在其他实施例中,还可以提供一种计算机可读存储介质,所述存储介质上存储有计算机程序,当所述计算机程序被处理器执行时,实现前述的基于深度学习的弥散微循环模型驱动参数估计方法。
[0101]
需要注意的是,存储器可以包括随机存取存储器(random access memory,ram),也可以包括非易失性存储器(non
‑
volatile memory,nvm),例如至少一个磁盘存储器。上述的处理器可以是通用处理器,包括中央处理器(central processing unit,cpu)、网络处理器(network processor,np)等;还可以是数字信号处理器(digital signal processing,dsp)、专用集成电路(application specific integrated circuit,asic)、现场可编程门阵列(field
‑
programmable gate array,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。当然,还装置中还应当具有实现程序运行的必要组件,例如电源、通信总线等等。
[0102]
需要指出的是,以上所述的实施例只是本发明的一种较佳的方案,然其并非用以限制本发明。有关技术领域的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型。因此凡采取等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1