一种基于深度学习的烟雾识别方法与流程
1.本发明涉及烟雾识别技术领域,特别涉及一种基于深度学习的烟雾识别方法。
背景技术:
2.烟雾的探测通常是以传感器监测烟雾的浓度来实现火灾防范的,但传感器探测的方式仅适合于室内或者近距离的达到报警浓度的烟雾探测。对于中远距离的探测,一种方式是采用多光谱手段探测烟雾特定光谱,另一种方式是采用中波红外探测烟雾所在波段。但上述两种中远距离所徐相机成本较高,不利于实际部署应用。
技术实现要素:
3.为解决上述技术问题,本发明提供了一种基于深度学习的烟雾识别方法,以达到降低处理成本,提高场景适应性和实际部署可行性的目的。
4.为达到上述目的,本发明的技术方案如下:
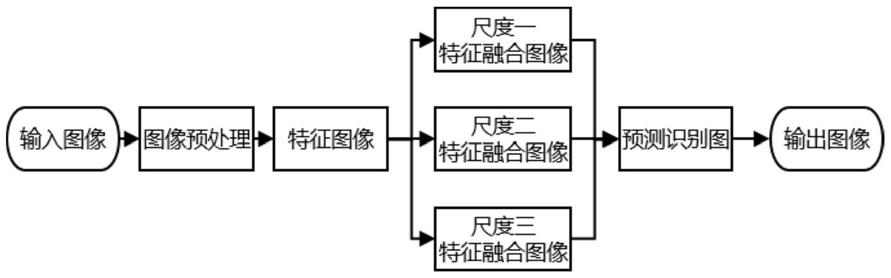
5.一种基于深度学习的烟雾识别方法,包括如下步骤:
6.步骤一,对拍摄的图像进行解码;
7.步骤二,利用基于空域和频域的方法对解码后的图像进行增强预处理,并进行自适应锚框计算及自适应图片尺寸变换;
8.步骤三,采用focus+csp结构对预处理之后的图像进行特征提取,得到特征图像;
9.步骤四,对特征图像利用spp、fpn+pan结构进行混合和组合图像特征,得到多尺度的特征融合图像;
10.步骤五,对多尺度的特征融合图像分别采用ciou_loss降低loss,采用diou_nms操作进行多识别框的筛选,从而完成对特征的分类和回归,并生成预测类型及边界框,从而得到最终的烟雾预测。
11.上述方案中,所述步骤一中的图像包括图片或视频。
12.上述方案中,所述步骤二中自适应图片尺寸变换后的图像规格为640*640*3。
13.上述方案中,所述步骤三的具体方法如下:将图像规格为640*640*3的图像输入focus结构,采用focus结构进行切片操作,先变成规格为320*320*12的特征图像,再经过一次32个卷积核的卷积操作,最终变成320*320*32的特征图像;并且采用由卷积层和x个resunint模块concate组成的csp1_x结构,先将基础层的特征映射划分为两部分,然后通过跨阶段层次结构将它们合并。
14.上述方案中,所述步骤四的具体方法如下:先采用spp结构的1
×
1,5
×
5,9
×
9,13
×
13的最大池化的方式,再将不同尺度的特征图像进行concat操作进行多尺度融合;再利用fpn将高层的特征信息通过上采样的方式进行传递融合,强调语义特征,并结合pan下采样操作,强调定位特征,利用fpn+pan结构得到多尺度的特征融合图像。
15.上述方案中,所述步骤五中,预测时采用ciou_loss作为目标bounding box的损失函数,ciou_loss的计算公式如公式(1)所示:
[0016][0017]
其中,iou是指两预测框与真实目标的相交的面积/两个方框合并的面积,0≤iou≤1,b代表预测中心坐标的参数,代表真实目标边界框中心的参数,ρ代表b和之间的欧氏距离,c代表两个矩形的最小外接矩形对角线长度,α和v是把预测框长宽比拟合成目标框的长宽比的影响因子,α和v的计算公式分别为公式(2)和公式(3):
[0018][0019][0020]
其中,w、h分别代表预测框的高和宽,w
gt
、h
gt
分别代表真实框的高和宽。
[0021]
通过上述技术方案,本发明提供的一种基于深度学习的烟雾识别方法具有如下有益效果:
[0022]
1、本发明通过深度学习的方法识别烟雾,在极大程度上解决了通过颜色等常规图像处理的方法识别烟雾的场景适应性的问题。
[0023]
2、通过本发明的算法处理rgb图像,与烟雾传感器、多光谱相机、中波红外相机等工艺相比,处理rgb彩色相机的图像的方式识别烟雾的成本低,解决了实际应用成本实际部署可行性的问题。
附图说明
[0024]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。
[0025]
图1为本发明实施例所公开的一种基于深度学习的烟雾识别方法整体流程示意图;
[0026]
图2为本发明所公开的一种基于深度学习的烟雾识别方法的具体算法流程示意图;
[0027]
图3为本发明所公开的focus流程图;
[0028]
图4为本发明所公开的focus结构图;
[0029]
图5为本发明所公开的csp1_x结构组成图;
[0030]
图6为本发明所公开的spp结构图;
[0031]
图7为本发明所公开的csp2_x结构组成图;
[0032]
图8为本发明所公开的fpn+pan结构图;
[0033]
图9
‑
图12为在不同的地方拍摄的图像经本发明的方法处理后得到的烟雾识别框的情况。
具体实施方式
[0034]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
[0035]
本发明提供了一种基于深度学习的烟雾识别方法,如图1所示,包括如下步骤:
[0036]
步骤一,对拍摄的图像进行解码,图像包括图片或视频;
[0037]
具体为:利用rgb相机获取烟雾的图像,或采用中波红外等其他波段光谱的相机探测后进行可视化处理,需保证烟雾在图像中能够体现出烟雾的形态特征。
[0038]
步骤二,利用基于空域和频域的方法对解码后的图像进行增强预处理,改善图像的清晰度,并进行自适应锚框计算及自适应图片尺寸变换,变换后的图像规格为640*640*3;
[0039]
步骤三,采用focus+csp结构对预处理之后的图像进行特征提取,得到特征图像;
[0040]
具体为:将图像规格为640*640*3的图像输入图3和图4所示的focus结构,采用focus结构进行切片操作,先变成规格为320*320*12的特征图像,再经过一次32个卷积核的卷积操作,最终变成320*320*32的特征图像;并且采用图5所示的由卷积层和x个res unint模块concate组成的csp1_x结构,先将基础层的特征映射划分为两部分,然后通过跨阶段层次结构将它们合并,在减少了计算量的同时保证准确率。
[0041]
步骤四,对特征图像利用spp、fpn+pan结构进行混合和组合图像特征,得到多尺度的特征融合图像;
[0042]
具体为:如图6所示,先采用spp结构的1
×
1,5
×
5,9
×
9,13
×
13的最大池化的方式,再将不同尺度的特征图像进行concat操作进行多尺度融合;并借鉴如图7所示的cspnet设计的csp2_x结构,加强网络特征融合的能力。如图8所示fpn+pan结构,fpn是自顶向下的,将高层的特征信息通过上采样的方式进行传递融合,强调语义特征,结合pan下采样操作,强调定位特征,利用fpn+pan结构得到多尺度的预测特征图。
[0043]
步骤五,对多尺度的特征融合图像分别采用ciou_loss降低loss,采用diou_nms操作进行多识别框的筛选,从而完成对特征的分类和回归,并生成预测类型及边界框,从而得到最终的烟雾预测,即得到该图像中的烟雾识别框;
[0044]
具体为:经过上述步骤四的fpn处理后,得到76*76、38*38、19*19多尺寸特征图,结合最终每个预测的18维(注:4(坐标值)、1(置信度分数)、1(1类烟雾预测类别)、3(rgb图像三个维度),(4+1+1)*3=18)信息,从而得到最后的预测中用于预测的三个特征图
①
19*19*18、
②
38*38*18、
③
76*76*18。
[0045]
最终得到多尺度的训练时采用ciou_loss作为目标bounding box的损失函数,ciou_loss的计算公式如公式(1)所示:
[0046][0047]
其中,iou是指两预测框与真实目标的相交的面积/两个方框合并的面积,0≤iou≤1,b代表预测中心坐标的参数,代表真实目标边界框中心的参数,ρ代表b和之间的欧氏距离,c代表两个矩形的最小外接矩形对角线长度,α和v是把预测框长宽比拟合成目标框的长宽比的影响因子,α和v的计算公式分别为公式(2)和公式(3):
[0048]
[0049][0050]
其中,w、h分别代表预测框的高和宽,w
gt
、h
gt
分别代表真实框的高和宽。
[0051]
经过上述的步骤一至步骤五后,得到的最终烟雾预测如图9至图12所示,在每张识别预测图中都包含了预测的类别信息(烟雾)、烟雾的位置信息、预测置信度分数等关于烟雾的预测信息。
[0052]
本发明主体在于烟雾识别,目前尚没有利用深度学习应用到识别烟雾方向的技术,本发明在于增加烟雾探测的手段、识别烟雾精度提高,场景适用性增强,增加实际场景部署可行性。
[0053]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1