一种Gaia系统中面向迭代计算的并行度动态调整方法
一种gaia系统中面向迭代计算的并行度动态调整方法
技术领域
1.本发明涉及分布式大数据计算系统及迭代计算技术领域,尤其涉及一种gaia系统中面向迭代计算的并行度动态调整方法。
背景技术:
2.gaia是一个面向多计算模型混合并存的高时效、可扩展的新一代大数据计算系统。该新型大数据计算系统针对批流混合任务具有全周期多尺度优化技术和统一计算引擎。现有大数据计算系统或依托自身计算引擎模拟另一类框架的行为,或定义一套通用接口屏蔽底层计算引擎的差异,对批流融合支持较弱。同时,其优化大多位于执行的特定时期或特定层级,且针对高复杂性任务的优化能力不足。针对以上问题,创新性地开发了基于统一计算引擎和全周期多尺度优化的高性能批流融合大数据计算引擎。该引擎为批流融合处理提供统一表达逻辑支持,通过统一表达建模融合批流处理的计算模型、数据模型、变换模型和动作模型,实现批、流处理的真正融合。针对作业的多样性、持久性、迭代性等特点,提供面向多作业、多任务、迭代计算、持久计算等优化策略,优化针对性更强。同时,提供执行前和执行中的全周期优化,并细分为作业级、任务级、变换级等多个尺度,以实现极速响应和海量吞吐。
3.迭代计算是数据处理中最常见的计算模型之一,其广泛应用于大数据机器学习、大图数据计算等领域。例如,网页排序算法pagerank通过迭代计算互联网中的海量超链接关系来确定网页权重;在社区发现领域,社区发现算法就是利用不断迭代来划分不同社区;在机器学习领域,各种聚类算法如k
‑
means算法和dbscan算法等都是典型的利用迭代计算不断接近最优解的算法。作为一种常见的计算模型,迭代计算包括首先给定的初值,然后用所给算法或公式计算初值得到的中间结果,并将中间结果作为输入参数进行反复计算的中间计算过程,以及在满足给定条件后得到的计算结果。
4.由于迭代计算中的迭代次数往往不是一个很小的数值,含有迭代计算的作业是一种耗时较长的作业。尤其当数据量较大的情况下,作业的计算耗时会更加明显,且含有迭代计算的部分会占据整个作业的大多数执行时间。因此,为了更快地得到计算结果,人们更多地将含有迭代计算的作业实现于大数据分布式计算系统(如hadoop、spark、gaia)中,利用物理节点的扩展来达到更快的作业执行效率,这也催生了研究者们更加致力于研究分布式计算系统中的迭代优化技术,来不断降低迭代计算的运行时间。
5.迭代计算的特点是每轮迭代步骤的计算逻辑相同,但是输入数据不同,这会造成每轮迭代步骤对分布式集群的负载不同。gaia中计算资源的基本单位是任务执行器(taskexecutor)中的任务槽(taskslot,简称slot)。slot的数量代表了gaia集群的并行处理能力,gaia中资源管理器主要就是对slot资源进行分配和管理。目前gaia系统中slot资源无法动态调整,所以在执行迭代任务过程中可能会出现两个方面的问题。一是并行度设置远不足以满足迭代任务的需求,这种情况下迭代任务的高负载会导致每个slot的压力过大,以及cpu压力过大,进而影响程序处理速度或造成内存溢出等情况的出现,导致作业效
率低下甚至执行失败。另一个问题是并行度设置过高导致系统资源利用率非常低,这种情况会造成资源的过度浪费和闲置,而在大规模数据处理中,可能会造成资源长时间闲置。
6.综上所述,需要一种面向迭代计算的动态可调整的slot资源分配机制,针对迭代算法重复计算的特性,结合系统资源统计信息进行相应的资源优化。
技术实现要素:
7.本发明要解决的技术问题是针对上述现有技术的不足,提供一种gaia系统中面向迭代计算的并行度动态调整方法,使运行在gaia系统中的各类迭代算法具有更高的执行效率。
8.为解决上述技术问题,本发明所采取的技术方案是:一种gaia系统中面向迭代计算的并行度动态调整方法,包括:
9.根据分布式集群的使用情况预设目标资源利用率;
10.收集用于并行度调整的统计信息数据;
11.在迭代作业运行时动态调整并行度资源,计算并行度;
12.保存迭代状态;
13.具体包括以下步骤:
14.步骤1、用户通过并行度调整接口根据分布式集群的使用情况预设目标资源利用率;
15.步骤2、基于心跳机制采集心跳信息;gaia系统的心跳监控器taskexecutor向作业管理器jobmaster进行心跳汇报的过程中,在周期性定时心跳过程中的payload负载信息中增加非连接状态统计信息的汇报;所述非连接状态统计信息包括:1)当前含有迭代计算的作业运行时的资源利用信息:包括对分布式集群的cpu使用核心数量及使用百分比、内存占用百分比、磁盘占用百分比及网络带宽这些资源已占用量和总量的统计;2)gaia系统执行作业时输入的数据集特征:包括数据集的大小、元素数量和数据键值的分布;
16.所述心跳机制收集用于调整并行度的统计信息数据;
17.所述taskexecutor向jobmaster进行心跳汇报的过程包括初始化阶段、注册阶段和心跳阶段;
18.所述初始化阶段为:jobmaster在启动时调用心跳服务类heartbeatservices类中的createheartbeatmanagersender()方法;此方法用来创建一个taskexecutorheartbeatmanager对象,该对象负责对与其连接的所有taskexecutor进行心跳管理,它会周期性地启动定时器,定期对其管理的对象进行扫描,然后对其发送心跳请求;taskexecutor创建jobmasterheartbeatmanager对象对jobmaster的心跳信息进行管理;
19.所述注册阶段为:在资源管理器resourcemanager将taskexecutor分配给相应的jobmaster之后,被分配的taskexecutor会主动向jobmaster进行信息注册,其通过远程过程调用rpc来调用jobmaster的registertaskexecutor()方法;jobmaster在收到远程rpc调用之后,首先执行本地方法接受taskexecutor的注册,然后通过taskexecutorheartbeatmanager的monitortarget()方法将此taskexecutor加入监控目标;最后将监控对象封装为heartbeatmonitor,并启动一个具有超时时间的心跳定时器;在
注册完taskexecutor之后,jobmaster会向其发送一个注册成功消息,在taskexecutor端会以同样的方式对jobmaster进行心跳监控;
20.所述心跳阶段为:jobmaster和taskexecutor之间的心跳检测过程是双向的;taskexecutor通过心跳机制向jobmaster进行负载信息的采集和上报;首先,jobmaster会定时通过rpc远程调用taskexecutor的heartbeatfromtaskexecutor()方法,taskexecutor接收到此rpc请求之后,调用对应heartbeatmonitor类中的reportheartbeat()方法,然后taskexecutor主动调用reportpayload()方法,将采集到的负载信息发送给jobmaster;
21.步骤3、以用户预设的目标资源利用率为目标,基于面向迭代计算的并行度机制动态调整并行度;
22.基于数据流作业的迭代特性,根据并行度机制在迭代作业运行时调整并行度资源;根据迭代过程中收集的系统统计信息,对计算系统资源以并行度的形式进行动态调整;根据公式1进行下次迭代并行度的计算:
[0023][0024]
其中,n为统计信息类别数;p
i
为迭代作业当前迭代的并行度,p
i+1
为迭代作业下次迭代的目标并行度;targetcpuavg和targetmenoryavg分别为由用户预设的cpu资源利用率和内存资源利用率;
[0025]
所述面向迭代计算的并行度机制包括并行度缩容机制和并行度扩容机制;所述并行度缩容机制为:在迭代计算的某些轮次中,gaia系统中每个slot的资源利用率都低于目标值,则在下次迭代中降低迭代并行度,使得slot平均资源利用率得到提升,并最终提高到用户预设的目标值;所述并行度扩容机制为:在迭代计算的某些轮次中,每个slot的利用率都高于目标值,则在下次迭代中提高迭代并行度,使得迭代作业的可用资源增加,slot平均资源利用率得以降低,最终达到用户预设的资源利用率目标值;
[0026]
步骤4、迭代状态保存:利用gaia迭代计算的特性,在迭代同步障碍处进行迭代状态的保存。
[0027]
采用上述技术方案所产生的有益效果在于:本发明提供的一种gaia系统中面向迭代计算的并行度动态调整方法,不需要事先预测作业所需资源,而是在作业执行过程中进行迭代资源的动态调整。如果作业执行过程中出现slot资源不足或占用过高的情况,则该机制会根据用户预先设定的资源利用率目标进行相应的slot资源扩容,使得作业所需的迭代资源得到满足,进而提升作业的执行效率,降低作业的执行时间,避免因为内存溢出等造成的作业失败。如果作业执行过程中出现slot资源浪费(每个slot资源使用过低)的情况,则该方法会根据用户预设的资源利用率目标进行相应的slot资源进行缩容,使得迭代作业所占用的slot资源数量进行相应的减少,进而使得gaia集群中剩余的slot资源得到增加,可供给其他程序使用。与根据频繁执行的作业进行负载预测或者通过作业短示例学习并预测作业所需资源相比,该动态调整并行度方法不需要在作业执行之前就执行相似的作业,也不需要执行专门的作业短示例,无需额外过多的预测时间。
[0028]
该方法利用迭代计算重复执行且输入数据不同的特点,降低了迭代计算的时间开销或者以极小的时间开销来释放较多的迭代资源。在迭代资源不足的情况下,迭代资源扩
容机制随着数据集规模的增大能够节省更多的作业运行时间,节省执行时间开销。在迭代资源利用率过低的情况下,迭代资源缩容机制能够以极小的时间开销节省迭代资源开销。
附图说明
[0029]
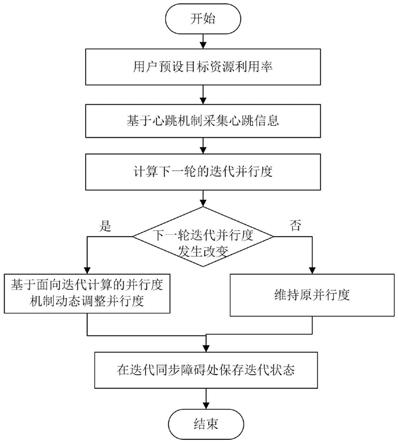
图1为本发明实施例提供的一种gaia系统中面向迭代计算的并行度动态调整方法的流程图;
[0030]
图2为本发明实施例提供的面向迭代计算的并行度缩容机制示意图;
[0031]
图3为本发明实施例提供的面向迭代计算的并行度扩容机制示意图;
[0032]
图4为本发明实施例提供的gaia系统中迭代步函数的实现过程图;
[0033]
图5为本发明实施例提供的心跳信息采集模块组件采集gaia系统资源信息的具体执行过程图。
具体实施方式
[0034]
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
[0035]
本实施例中,一种gaia系统中面向迭代计算的并行度动态调整方法,如图1所示,具体包括以下步骤:
[0036]
步骤1、用户通过并行度调整接口根据分布式集群的使用情况预设目标资源利用率;
[0037]
本实施例中,首先在gaia系统中新增心跳数据采集模块,该模块负责收集用于调整并行度的统计信息数据。同时为用户提供并行度调整接口,通过该接口,用户可以根据分布式集群的使用情况预设目标资源利用率,gaia系统会根据心跳数据采集模块的数据在下一轮迭代执行时进行并行度的自动调整。本实施例对迭代资源动态并行度机制的实现在设计和具体实现时符合设计模式的要求,特别注意了系统代码的可靠性和可扩展性。
[0038]
步骤2、基于心跳机制采集心跳信息;gaia系统的心跳监控器taskexecutor向作业管理器jobmaster进行心跳汇报的过程中,在周期性定时心跳过程中的payload负载信息中增加非连接状态统计信息的汇报;所述非连接状态统计信息包括:1)当前含有迭代计算的作业运行时的资源利用信息:包括对分布式集群的cpu使用核心(线程)数量及使用百分比、内存占用百分比、磁盘占用百分比及网络带宽这些资源已占用量和总量的统计;2)gaia系统执行作业时输入的数据集特征:包括数据集的大小、元素数量和数据键值的分布;
[0039]
新增的心跳机制是一种通过定期发送请求的方式来确定网络中的另一方是否存活的机制。在新增的心跳机制中,资源管理器(resourcemanager)、jobmaster以及taskexecutor这三个组件会互相进行心跳检测与心跳汇报。比如taskexecutor会向jobmaster心跳汇报自身状态,让jobmaster可以确定该taskexecutor是否存活,jobmaster也会向taskexecutor心跳汇报自身状态,让taskexecutor可以确定该jobmaster是否存活,进而决定在其上执行的任务是否进入失败状态。资源动态并行度机制是基于新增的gaia系统中的心跳机制进行实现的,在心跳阶段taskexecutor响应jobmaster自身存活信息时,又实现了slot负载信息的采集,使得在分布式作业迭代步骤的执行过程中能够感知slot资源的利用情况。新增的心跳机制中jobmaster与taskexecutor之间的心跳检测主要分为三个
阶段:初始化阶段,注册阶段以及心跳阶段。
[0040]
所述初始化阶段为:jobmaster在启动时调用心跳服务类heartbeatservices类中的createheartbeatmanagersender()方法;此方法用来创建一个taskexecutorheartbeatmanager对象,该对象负责对与其连接的所有taskexecutor进行心跳管理,它会周期性地启动定时器,定期对其管理的对象进行扫描,然后对其发送心跳请求;taskexecutor的心跳检测系统初始化过程和jobmaster初始化阶段的执行过程相类似,taskexecutor创建jobmasterheartbeatmanager对象对jobmaster的心跳信息进行管理;
[0041]
所述注册阶段为:在资源管理器resourcemanager将taskexecutor分配给相应的jobmaster之后,被分配的taskexecutor会主动向jobmaster进行信息注册,其通过远程过程调用rpc来调用jobmaster的registertaskexecutor()方法;jobmaster在收到远程rpc调用之后,首先执行本地方法接受taskexecutor的注册,然后通过taskexecutorheartbeatmanager的monitortarget()方法将此taskexecutor加入监控目标;最后将监控对象封装为heartbeatmonitor,并启动一个具有超时时间的心跳定时器;在注册完taskexecutor之后,jobmaster会向其发送一个注册成功消息,在taskexecutor端会以同样的方式对jobmaster进行心跳监控;
[0042]
所述心跳阶段为:jobmaster和taskexecutor之间的心跳检测过程是双向的;taskexecutor通过心跳机制向jobmaster进行负载信息的采集和上报;首先,jobmaster会定时通过rpc远程调用taskexecutor的heartbeatfromtaskexecutor()方法,taskexecutor接收到此rpc请求之后,调用对应heartbeatmonitor类中的reportheartbeat()方法,然后taskexecutor主动调用reportpayload()方法,将采集到的cpu,内存等负载信息发送给jobmaster;
[0043]
步骤3、以达到用户预设的目标资源利用率为目标,基于面向迭代计算的并行度机制动态调整并行度;
[0044]
基于数据流作业的迭代特性,根据并行度缩容机制和并行度扩容机制在迭代作业运行时调整并行度资源;根据迭代过程中收集的系统统计信息,对计算系统资源以并行度的形式进行动态调整,以实现经济高效的作业执行;根据公式1进行下次迭代并行度数量的计算:
[0045][0046]
其中,n为统计信息类别数,在上式中n的值为2,因为统计的指标类别包括cpu和内存平均利用率两种;p
i
为迭代作业当前迭代的并行度,p
i+1
为迭代作业下次迭代的目标并行度;targetcpuavg和targetmenoryavg分别为由用户预设的cpu资源利用率和内存资源利用率;根据上式,可以计算出为了达到用户预设的目标资源利用率目标,下次迭代计算的并行度需要设置为多大;
[0047]
所述面向迭代计算的并行度机制包括并行度缩容机制和并行度扩容机制;所述并行度缩容机制如图2所示,具体为:在迭代计算的某些轮次中,gaia系统中每个slot的资源利用率都低于目标值,则在下次迭代中降低迭代并行度,使得slot平均资源利用率得到提升,并最终提高到用户预设的目标值;通过并行度缩容可以避免资源浪费情况的继续,从而释放部分任务占用的槽资源,让其他处于等待状态的作业得以执行,进而提升系统的整体
效益。所述并行度扩容机制如图3所示,具体为:在迭代计算的某些轮次中,每个slot的利用率都高于目标值,过高的资源利用率会导致系统内存溢出或缓存不足而导致网络拥塞等情况的发生,则在下次迭代中提高迭代并行度,使得迭代作业的可用资源增加,slot平均资源利用率得以降低,最终达到用户预设的资源利用率目标值,从而避免迭代作业效率低下的问题;
[0048]
本实施例中,jobmaster的数据收集器(datacollection)组件负责收集和其关联的所有taskexecutor负载信息,然后对每个taskexecutor的负载信息进行合并,统计并计算各节点各指标的平均资源利用率。之后datacollection将心跳统计信息发送到gaia系统的client端,client端已经由用户预设相应的目标资源利用率。client端在收到jobmaster发送来的心跳统计信息之后,会根据公式(1)计算出下一轮的迭代并行度。如果下一轮迭代并行度相比于本轮迭代并行度发生了改变,那么gaia系统就会进行相应的并行度调整并继续迭代计算;如果下一轮迭代并行度并未发生改变,那么迭代作业会维持原并行度继续执行。
[0049]
步骤4、迭代状态保存:利用gaia迭代计算的特性,在迭代同步障碍处进行迭代状态的保存,因为在迭代同步障碍处不需要进行中间状态的处理。
[0050]
在迭代计算过程中进行并行度的动态调整,必须要进行迭代状态的保存,否则并行度调整之后无法正确的还原迭代任务。gaia系统中的迭代计算模型在迭代算子未收到迭代终止信号之前都会一直调用步函数(step function),并将其嵌入到迭代算子中从而实现迭代操作。gaia系统中的迭代步函数的实现过程如图4所示。首先,一个superstep(超级步)是一次迭代的完整执行。超级步被分解为3个步骤:本地计算阶段,消息传递阶段,同步障碍(barrier synchronization)阶段。同步障碍表明了迭代计算中的所有并行任务需要在下一个迭代超级步开始之前完成,每次同步障碍都代表在此分布式迭代计算中上一个超级步的结束以及下一个超级步的开始。gaia中一个作业迭代过程的结束条件通常被定义为两个方面,一个是迭代达到预设的最大迭代次数,另一个是迭代达到预设的收敛标准,只要满足了其中一个条件,那么整个迭代过程就会终止。
[0051]
在迭代状态保存中,主要利用gaia迭代计算的特性,在迭代同步障碍处进行迭代状态的保存。利用迭代障碍主要具有如下两个优势:1)统计信息更详细。在迭代障碍处,可以获得反映前一个迭代中处理的所有元素的详细统计信息。与在任务的每个阶段为任务的下一阶段收集统计数据相比,这种收集统计数据的方法不仅仅适用于批处理任务逐步执行的执行模型,也适用于流任务并行执行任务管道的执行模型。2)没有中间任务状态:在迭代障碍处,前一个迭代的所有任务已经完成,下一个迭代的任务还没有开始。因此,在迭代障碍处,数据流可以在不需要处理中间任务状态的情况下进行调整,这使得并行度动态扩缩容的实现更为简单。
[0052]
在gaia系统迭代计算过程中,迭代头任务iterationheadtask,迭代中间任务iterationintermediatetask和迭代尾任务iterationtailtask是gaia迭代过程的不同执行阶段。迭代头任务会读取初始输入并和迭代尾任务建立一个blockingbackchannel反馈通道;迭代中间任务负责更新workset和solution set的迭代状态;迭代尾任务会在迭代状态被更新之后,将本地任务的输出通过反馈通道传递给迭代头,这就意味着一次迭代逻辑的完成。iterationsynchronizationsinktask是对迭代障碍的实现,它只用来协调同步所
有的迭代头任务,不参与任何数据的处理。当iterationsynchronizationsinktask收到allworkersdoneevent事件之后,就意味着一次超步完成了,此时通过调用saveiterationstate()方法将处于反馈通道中的迭代状态信息进行保存,供迭代并行度调整之后进行作业重新恢复时使用。
[0053]
本实施例中,基于本发明的并行度调整方法,在gaia系统层面,作业管理器jobmaster通过心跳监控器taskexecutor中slot的资源利用信息,并通过心跳数据采集模块(datacollection)组件进行各类心跳信息统计。心跳信息采集模块组件采集系统资源信息的具体执行过如图5所示,心跳服务启动后,gaia系统会启动一个线程来处理心跳超时事件,在设定的心跳超时时间到达后执行线程;如果接收到调整并行度的统计信息数据,会先将该线程取消而后重新开启,重置心跳超时事件的触发;最终统计信息被传递到gaia系统的client端,client端通过并行度监管器parallelismregulato组件计算出下一轮迭代的并行度,然后调整并行度并继续下一轮迭代的执行。
[0054]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明权利要求所限定的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1