一种采用爬虫和OCR技术获取游戏版号和审批文号的方法与流程
一种采用爬虫和ocr技术获取游戏版号和审批文号的方法
技术领域
1.本发明涉及网络游戏监管相关的一种数据抓取技术,特别涉及一种采用爬虫和ocr技术获取游戏版号和审批文号的方法。
背景技术:
2.随着互联网行业在我国的蓬勃发展,网络游戏也变得越来越丰富多样。网络游戏的用户主要是以青少年为主。一些不法分子借机在游戏中植入一些不健康的内容,从而对青少年造成诸多不良影响。因此,国家专门设立了游戏监管部门对国内游戏的开发商和运行商进行监管。
3.目前,国内游戏的监管主要是通过游戏版号和审批文号来进行的。国内游戏的开发商和运营商需要申请游戏版号,并获得审批文号才能够将游戏上线给用户玩。然而在实际运营过程中,一些游戏开发商和运营商还未上传游戏版号和审批文号就先将游戏上线运营了,甚至经常还会出现版号和文号的套用、捏造、无版号和文号的情况。
4.针对上述国内游戏运营的乱象,国家游戏监管部门想主动出击监管整治。然而,国内游戏官网对于游戏版号和审批文号的记载方式却并不统一,有的将其存储在响应文档里面,有的将其显示在游戏界面上,且各家游戏网站有的采用http/https的通用协议,有的采用私有协议,常规技术方法无法同时适应这种复杂的状态。因此若采用常规的技术手段则很难获得较全面的数据,也难以达成监管要求的效果。
技术实现要素:
5.基于上述国内游戏运营的混乱状态,在实际的游戏运行环境下,游戏监管部门没有真正可靠和有效的手段,能够主动从游戏运营方获取游戏版号或审批文号,本发明的目的是:提出一种采用爬虫和ocr技术获取游戏版号和审批文号的方法,其不仅能够从通用协议中获取数据,还能够从私有化协议中获取数据,进而解决了游戏监管部门在监管方面的技术问题,扩大了监管范围,提高了监管效果。
6.本发明解决其技术问题所采用的技术方案是:
7.一种采用爬虫和ocr技术获取游戏版号和审批文号的方法,具体包括如下步骤:
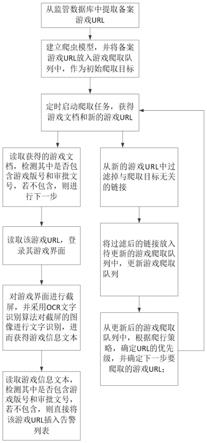
8.s1、从监管数据库中提取备案游戏url;
9.s2、建立游戏网站爬虫模型,并将备案游戏url放入游戏爬取队列中,作为初始爬取目标;
10.s3、定时启动爬取任务爬取页面,获得游戏文档和新的游戏url;
11.s4、根据过滤策略,从新的游戏url中过滤掉与爬取目标无关的链接;
12.s5、将过滤后的新的游戏url放入待更新的游戏爬取队列中,根据更新策略更新游戏爬取队列;
13.s6、从更新后的游戏队爬取列中,根据爬行策略,确定url的优先级,并确定下一步要爬取的游戏url;
14.s7、重复步骤s3~s6,获取更多的游戏文档;
15.s8、读取获得的游戏文档,检测其中是否包含游戏版号和审批文号,若不包含,则继续下一步处理;
16.s9、读取该游戏url,登录其游戏界面,并对其进行截屏处理,获得其游戏界面图像;
17.s10、采用ocr文字识别算法对获得的游戏界面图像进行文字识别处理,获得游戏信息文本;
18.s11、读取所述游戏信息文本,检测其中是否包含游戏版号和审批文号,若不包含,则直接将该游戏url插入告警列表。
19.进一步优选技术方案,所述游戏网站爬虫模型采用聚焦网络爬虫模型,所述聚焦网络爬虫模型的结构包括初始url集合、url队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块和链接评价模块。
20.进一步优选技术方案,在步骤s4中,所述过滤策略的目的是过滤掉不符合目标的链接,其具体过滤方法如下:
21.s41、去掉不符合协议的链接,即无效链接;
22.s42、按照游戏平台的规则,判断链接是否符合游戏平台要求,去掉不符合游戏平台规则的链接;
23.s43、链接去重。
24.进一步优先技术方案,在步骤s5中,所述更新策略具体包括如下步骤:
25.s51、针对未爬取过的内容,则直接添加至爬行队列中;
26.s52、针对爬取过的内容,首先判断链接历史是否可用,将链接历史不可用的直接加入队列,并根据历史更新周期建立更新模型预测其更新周期,若超过更新周期则加入队列。
27.进一步优选技术方案,在步骤s6中,所述爬行策略采用以下任意一种策略:
28.访问量爬行策略:访问人数越高的链接优先爬取;
29.更新周期爬行策略:更新周期长的优先爬取;
30.可用性爬行策略:有效链接优先爬取。
31.进一步优选技术方案,在步骤s8和s11中,所述游戏版号和审批文号的检测方法如下:
32.a、获取国家新闻总署发布的游戏名称、审批文号、游戏版号、出版单位、运营单位和采用时间建立备案对比数据库;
33.b、将获得的文本信息与备案对比数据库进行比对,判断备案对比数据库中是否存在与游戏名称、出版单位和运营单位完全匹配的游戏信息;
34.c、若存在,则根据审批文号、游戏版号的命名规则以及国家对其的采用时间,采用正则表达式获取审批文号和游戏版号。
35.本发明的有益效果是:采用本方案不仅能够从通用协议中获取游戏版号和审批文号,还能够从私有协议中获取。本方案获取游戏数据不仅快速准确,而且还弥补了目前爬虫技术无法抓取私有协议游戏数据的缺点。本方案数据采集面更广,获得的数据也更加全面,因此能最大限度地减少人工成本的基础上,扩大监管范围,保证监管的效果。
附图说明
36.图1是本发明中获取游戏版号和审批文号的处理流程图。
具体实施方式
37.国内游戏的开发商和运营商需要申请游戏版号,并获得审批文号才能够将游戏合规上线给用户玩。通常游戏在上线运营前,需要将其游戏版号和审批文号上传至监管数据库。因此,在监管数据库中存储有已备案的游戏url。
38.如图1所示,本发明的具体实施流程如下:
39.s1、从监管数据库中提取备案游戏url;
40.s2、建立游戏网站爬虫模型,并将备案游戏url放入游戏爬取队列中,作为初始爬取目标;
41.其中,游戏网站爬虫模型采用聚焦网络爬虫模型,所述聚焦网络爬虫模型的结构包括初始url集合、url队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块和链接评价模块。
42.s3、定时启动爬取任务爬取页面,获得游戏文档和新的游戏url;
43.s4、根据过滤策略,从新的游戏url中过滤掉与爬取目标无关的链接;
44.其中,过滤策略的目的是过滤掉不符合目标的链接,其具体过滤方法如下:
45.s41、去掉不符合协议的链接,即无效链接;
46.s42、按照游戏平台的规则,判断链接是否符合游戏平台要求,去掉不符合游戏平台规则的链接;
47.s43、链接去重;
48.s5、将过滤后的新的游戏url放入待更新的游戏爬取队列中,根据更新策略更新游戏爬取队列;
49.其中,更新策略为:
50.s51、针对未爬取过的内容,则直接添加至爬行队列中;
51.s52、针对爬取过的内容,首先判断链接历史是否可用,将链接历史不可用的直接加入队列,并根据历史更新周期建立更新模型预测其更新周期,若超过更新周期则加入队列;
52.s6、从更新后的游戏队爬取列中,根据爬行策略,确定url的优先级,并确定下一步要爬取的游戏url;
53.其中,爬行策略采用以下任意一种策略:
54.访问量爬行策略:访问人数越高的链接优先爬取;
55.更新周期爬行策略:更新周期长的优先爬取;
56.可用性爬行策略:有效链接优先爬取。
57.s7、重复步骤s3~s6,获取更多的游戏文档;
58.s8、读取获得的游戏文档,检测其中是否包含游戏版号和审批文号,若不包含,则继续下一步处理;
59.s9、读取该游戏url,登录其游戏界面,并对其进行截屏处理,获得其游戏界面图像;
60.s10、采用ocr文字识别算法对获得的游戏界面图像进行文字识别处理,获得游戏信息文本;
61.s11、读取所述游戏信息文本,检测其中是否包含游戏版号和审批文号,若不包含,则直接将该游戏url插入告警列表。
62.此外,在步骤s8和步骤s11中,所述游戏版号和审批文号的检测方法具体如下:
63.a、获取国家新闻总署发布的游戏名称、审批文号、游戏版号、出版单位、运营单位和采用时间建立备案对比数据库;
64.b、将获得的文本信息与备案对比数据库进行比对,判断备案对比数据库中是否存在与游戏名称、出版单位和运营单位完全匹配的游戏信息;
65.c、若存在,则根据审批文号、游戏版号的命名规则以及国家对其的采用时间,采用正则表达式获取审批文号和游戏版号。
66.本发明的技术方案融合了聚焦网络爬虫技术和ocr文字识别技术,既能最大限度发挥技术快速准确的优势,又能弥补目前爬虫技术无法获取到非http/https协议/通道数据的缺点,能最大限度地减少人工成本的基础上,扩大监管范围,保证监管的效果。
67.以上显示和描述了本方案的基本原理和主要特征和本方案的优点。本行业的技术人员应该了解,本方案不受上述实施例的限制,上述实施例和说明书中描述的只是说明本方案的原理,在不脱离本方案精神和范围的前提下,本方案还会有各种变化和改进,这些变化和改进都落入要求保护的本方案范围内。本方案要求保护范围由所附的权利要求书及其等效物界定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1