一种融合预置QA对和知识图谱推理的智能问答系统的制作方法
一种融合预置qa对和知识图谱推理的智能问答系统
技术领域
1.本发明属于人工智能的问答系统技术领域,尤其涉及融合预置qa对和知识图谱推理的智能问答系统,本发明面向阳光高考智能问答场景,也可稍作修改后用于其它垂直化场景中。
背景技术:
2.在传统高考领域,考生在获取心仪院校信息时主要通过纸质书籍查找或主动在网上搜寻院校相关信息。但随着数据爆炸式的增长,上述此方式的获取效率极为低效。
3.由于人工智能的快速发展,智能问答机器人、系统等随之应运而生,大量基于人工智能的问答系统产品频出。
4.目前的智能问答系统中,主流的方式主要有:基于人工模板、基于知识库检索和基于深度学习的序列到序列生成模型。基于人工模板的方式,因基于深度学习的序列到序列生成模型所生成的答案可控性较差,不太适合本文所述的阳光高考场景。因此,本文针对阳光高考场景,提出一种融合预置qa对和知识图谱推理的智能问答系统,既能减少人工运营成本,又能避免不可控的风险,本发明的提出具有重要实际意义。
技术实现要素:
5.本发明针对上述的问题,提供了一种融合预置qa对和知识图谱推理的智能问答系统。
6.为了达到上述目的,本发明采用的技术方案为,
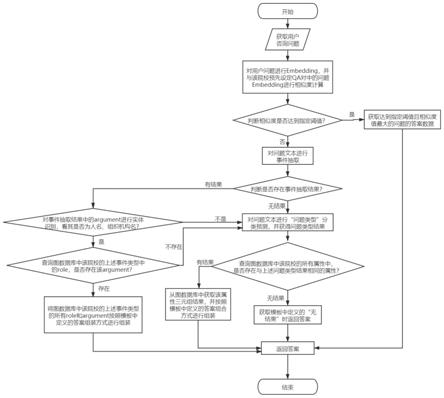
7.一种融合预置qa对和知识图谱推理的智能问答系统,具体包括:
8.预置qa对相似度对比模块、用户问题的事件抽取模块、用户问题分类模块、知识图谱三元组答案推理模块;
9.所述用户问题分类模块由文本qa对自动生成模块和问题分类训练模块组成。
10.作为优选,
11.所述预置qa对相似度对比模块:
12.主要通过bert模型对用户所提问题进行embedding后,与数据库中所存储的预置qa对中的问题embedding向量进行相似度计算,并返回相似度符合自定义阈值且相似度值最高的问题所对应的答案返回给用户。
13.作为优选,
14.所述预置qa对相似度对比模块的具体步骤如下:
15.(1)对运营人员预置的qa对进行数据处理,为达到相似度计算中,能更接近于真实的语义相似度,而不是词汇相似度,采用bert-flow的方式对预置的问题进行embedding,将服从高斯分布的随机变量映射到bert编码的,则反函数就能把映射到高斯分布上;在训练过程中保持bert的参数不变,只优化标准化流的参数,优化目标为最大化从高斯分布中产生bert表示的概率,公式如下:
[0016][0017]
(2)将由bert-flow对预置的qa对中的q进行embedding后的向量结果及其对应的原始a,将院校及其所有qa对存储于数据库中;
[0018]
(3)对用户针对某一院校实时反馈的问题,利用bert-flow对问题进行 embedding,并从数据库中读取经过embedding后的预置qa对结果并缓存至内存中;对用户的问题embedding及预置qa对中的所有问题的embedding进行余弦相似度计算,如相似度值达到指定阈值,则返回满足指定阈值且相似度值最高的问题embedding所对应的答案返回给用户,否则进行下一步流程。
[0019]
作为优选,
[0020]
所述用户问题的事件抽取模块:
[0021]
主要通过roberta+crf模型对用户问题进行事件抽取。
[0022]
作为优选,
[0023]
所述用户问题的事件抽取模块的具体步骤如下:
[0024]
(1)定义事件schema,即对训练语料和阳光高考场景下用户可能问到的事件进行定义;
[0025]
(2)对训练语料进行数据预处理;训练预料labels由schema中的所有事件及角色组成,将训练语料中的event_list进行逐条拆分后,通过tockenizer分别对 text、role、label进行encode;
[0026]
(3)建立roberta+crf模型,即在预训练语言模型roberta后依次添加全连接层、crf层,crf层的输出通过decode后即为预测结果,其中采用 adam优化器进行优化,且max_len为128;
[0027]
(4)离线训练出最优模型后,在实时中接收到预置qa对相似度对比模块中所传输的用户问题,对用户问题首先利用tockenizer进行embedding,利用训练好的事件抽取模型对embedding进行预测,并利用viterbi算法对预测结果进行最优路径求解来获取事件抽取结果;
[0028]
(5)如上述(4)中存在事件抽取结果,则对抽取结果中的arguments分别进行实体识别,筛选出argument为人名或组织机构名的抽取结果作为 new_arguments。如new_arguments长度不为空(new_arguments数据结构为:
[0029]
[{“role”:”**”,“argument”:”**”}]),则进行(6)中操作;如 new_arguments结果为空或原始抽取结果arguments为空,则进行如下4中的用户问题分类模块;
[0030]
(6)获取上述(5)中new_arguments的role,查询用户访问院校在图数据中该role下是否存在new_arguments中role与之对应的argument,如有则将图数据中role下所有三元组结果传至下述5中知识图谱三元组答案推理模块。如无则进行如下4中的用户问题分类模块。
[0031]
作为优选,
[0032]
所述用户问题分类模块:
[0033]
主要通过bert分类模型对用户的问题进行分类,分类结果为知识图谱中的三元组
属性,即预测用户问题属于哪一类属性的问题;在训练bert分类模型中,利用seq2seq模型进行原始语料的qa对自动生成,用于补充分类模型的训练数据。
[0034]
作为优选,
[0035]
所述用户问题分类模块的具体步骤如下:
[0036]
(1)训练seq2seq模型,利用交叉熵作为loss并mask掉输入部分,在得到最优模型后,对各院校的文本语料进行自动qa对提取。在结果提取阶段,通过随机采样答案并通过beam search来生成问题;
[0037]
(2)融合各高校语料数据经过上述(1)中自动生成的qa对及运营人员预置的qa对数据,并以此数据中的q集合作为训练集,其中q集合中单条样本数据所对应的label为高校图数据中所有三元组中的role;以此数据来训练bert 问题分类模型;
[0038]
(3)利用上述(2)中训练好的最优bert模型,对预置qa对相似度对比模块或用户问题的事件抽取模块中所传入的用户问题进行问题分类预测,预测结果为role。查询该高校图数据中的role所对应的三元组结果并进行5中三元组答案推理模块操作;如该高校图数据中不存在该role,则返回自定义规则中“无答案”时的结果返回给用户
[0039]
作为优选,
[0040]
所述知识图谱三元组答案推理模块:
[0041]
主要将寻找到的最优知识图谱三元组结果按照自定义规则库进行答案组装,并将答案反馈给用户。
[0042]
作为优选,
[0043]
所述知识图谱三元组答案推理模块的具体步骤如下:
[0044]
(1)如传入结果为上述权利要求3中事件抽取的三元组结果,则按照自定义事件抽取结果组装规则,对[(事件,论元角色,论元),(事件,论元角色,论元),...]三元组结果按照事件所对应的组装规则,依据论元角色属性对多个论元结果及事件结果进行答案组装;
[0045]
(2)如传入结果为上述权利要求4中用户问题分类模块传入的三元组结果,则按照自定义实体三元组结果组装规则,对(主体,关系,客体)三元组结果按照“关系”所对应的组装规则进行答案组装。
[0046]
与现有技术相比,本发明的优点和积极效果在于,
[0047]
1、本发明通过融合预置qa对和知识图谱推理,解决了传统的智能问答系统预定义规则进行匹配而无法回答各类问句的问题,同时通过自定义三元组答案组装规则库,有效规避答案中所存在的未知风险问题。
附图说明
[0048]
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
[0049]
图1为融合预置qa对和知识图谱推理的智能问答系统流程示意图;
[0050]
图2为融合预置qa对和知识图谱推理的智能问答系统的应用场景效果图。
具体实施方式
[0051]
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和实施例对本发明做进一步说明。需要说明的是,在不冲突的情况下,本技术的实施例及实施例中的特征可以相互组合。
[0052]
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用不同于在此描述的其他方式来实施,因此,本发明并不限于下面公开说明书的具体实施例的限制。
[0053]
实施例1,如图1、图2所示,本发明提供了一种融合预置qa对和知识图谱推理的智能问答系统,其主要由四个大模块组装,分别为:预置qa对相似度对比模块、用户问题的事件抽取模块、用户问题分类模块、知识图谱三元组答案推理模块。其中用户问题分类模块由文本qa对自动生成和问题分类训练模块。其上述模块具体作用如下:
[0054]
s1:预置qa对相似度对比模块,主要通过bert模型对用户所提问题进行embedding后,与数据库中所存储的预置qa对中的问题embedding向量进行相似度计算,并返回相似度符合自定义阈值且相似度值最高的问题所对应的答案返回给用户。
[0055]
s2:用户问题的事件抽取模块,主要通过roberta+crf模型对用户问题进行事件抽取。
[0056]
s3:用户问题分类模块,主要通过bert分类模型对用户的问题进行分类,分类结果为知识图谱中的三元组属性,即预测用户问题属于哪一类属性的问题。在训练bert分类模型中,利用seq2seq模型进行原始语料的qa对自动生成,用于补充分类模型的训练数据。
[0057]
s4:知识图谱三元组答案推理模块,主要将寻找到的最优知识图谱三元组结果按照自定义规则库进行答案组装,并将答案反馈给用户。
[0058]
下面详细的说明一下上述模块的具体步骤:
[0059]
所述预置qa对相似度对比模块,其主要步骤如下:
[0060]
(1)对运营人员预置的qa对进行数据处理,为达到相似度计算中,能更接近于真实的语义相似度,而不是词汇相似度,采用bert-flow的方式对预置的问题进行embedding,将服从高斯分布的随机变量z映射到bert编码的 u,则反函数f-1
就能把u映射到高斯分布上。在训练过程中保持bert的参数不变,只优化标准化流的参数,优化目标为最大化从高斯分布中产生
[0061]
bert表示的概率,公式如下:
[0062][0063]
(2)将由bert-flow对预置的qa对中的q进行embedding后的向量结果及其对应的原始a,将院校及其所有qa对存储于数据库中。
[0064]
(3)对用户针对某一院校实时反馈的问题,利用bert-flow对问题进行
[0065]
embedding,并从数据库中读取经过embedding后的预置qa对结果并缓存至内存中。对用户的问题embedding及预置qa对中的所有问题的 embedding进行余弦相似度计算,如相似度值达到指定阈值,则返回满足指定阈值且相似度值最高的问题embedding所对应的答案返回给用户,否则进行下一步流程。
[0066]
所述用户问题的事件抽取模块,其主要步骤如下:
[0067]
(1)定义事件schema,即对训练语料和阳光高考场景下用户可能问到的事件进行定义。示例如下:
[0068][0069]
(2)对训练语料进行数据预处理,训练语料数据格式如下:
[0070][0071]
训练预料labels由schema中的所有事件及角色组成,将训练语料中的 event_list进行逐条拆分后,通过tockenizer分别对text、role、label进行 encode。
[0072]
(3)建立roberta+crf模型,即在预训练语言模型roberta后依次添加全连接层、crf层,crf层的输出通过decode后即为预测结果,其中采用adam 优化器进行优化,且max_len为128。
[0073]
(4)离线训练出最优模型后,在实时中接收到预置qa对相似度对比模块中所传输的用户问题,对用户问题首先利用tockenizer进行embedding,利用训练好的事件抽取模型对embedding进行预测,并利用viterbi算法对预测结果进行最优路径求解来获取事件抽取
结果。
[0074]
(5)如上述(4)中存在事件抽取结果,则对抽取结果中的arguments分别进行实体识别,筛选出argument为人名或组织机构名的抽取结果作为 new_arguments。如new_arguments长度不为空(new_arguments数据结构为:
[0075]
[{“role”:”**”,“argument”:”**”}]),则进行(6)中操作;如new_arguments结果为空或原始抽取结果arguments为空,则进行如下4中的用户问题分类模块。
[0076]
(6)获取上述(5)中new_arguments的role,查询用户访问院校在图数据中该role下是否存在new_arguments中role与之对应的argument,如有则将图数据中role下所有三元组结果传至下述5中知识图谱三元组答案推理模块。如无则进行如下4中的用户问题分类模块。
[0077]
所述用户问题分类模块,其主要步骤如下:
[0078]
(1)训练seq2seq模型,利用交叉熵作为loss并mask掉输入部分,在得到最优模型后,对各院校的文本语料进行自动qa对提取。在结果提取阶段,通过随机采样答案并通过beam search来生成问题。生成效果示例如下:
[0079][0080]
(2)融合各高校语料数据经过上述(1)中自动生成的qa对及运营人员预置的qa对数据,并以此数据中的q集合作为训练集,其中q集合中单条样本数据所对应的label为高校图数据中所有三元组中的role。以此数据来训练bert 问题分类模型。
[0081]
(3)利用上述(2)中训练好的最优bert模型,对预置qa对相似度对比模块或用户问题的事件抽取模块中所传入的用户问题进行问题分类预测,预测结果为role。查询该高校图数据中的role所对应的三元组结果并进行5中三元组答案推理模块操作。如该高校图数据中不存在该role,则返回自定义规则中“无答案”时的结果返回给用户。
[0082]
所述知识图谱三元组答案推理模块,其主要步骤如下:
[0083]
(1)如传入结果为上述3中事件抽取的三元组结果,则按照自定义事件抽取结果组装规则,对[(事件,论元角色,论元),(事件,论元角色,论元),...]三元组结果按照事件所对应的组装规则,依据论元角色属性对多个论元结果及事件结果进行答案组装。例:[(“院校重组-更名”,“现名”,“某某大学”),(“院校重组-更名”,“原名”,“某某学院”)]三元组则组装为“某某大学的原名为某某学院”。并将组装好后的答案返回给用户。
[0084]
(2)如传入结果为上述4中用户问题分类模块传入的三元组结果,则按照自定义实体三元组结果组装规则,对(主体,关系,客体)三元组结果按照“关系”所对应的组装规则进行答案组装。例:(“某某大学”,“曾用名”,“某某学院”)三元组则组装为“某某大学的曾用名是某某学院”。并将组装好后的答案返回给用户。
[0085]
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作其它形式的限制,任何熟悉本专业的技术人员可能利用上述揭示的技术内容加以变更或改型为等同变化的等效实施例应用于其它领域,但是凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与改型,仍属于本发明技术方案的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1