一种下游任务解耦的神经网络指纹检测方法
1.本发明属于人工智能模型技术领域,具体涉及一种下游任务解耦的神经网络指纹检测方法。
背景技术:
2.随着深度学习技术的不断发展,神经网络的知识产权保护成为了一个重要问题。模型的训练通常需要大量的计算资源与数据样本,而攻击者可通过系统攻击、算法攻击等方式窃取模型,并施以模型所有权混淆技术,低成本地完成盗版模型的构建。
3.对于模型窃取,现有的知识产权保护方法主要包括水印检测与指纹检测。其中,水印检测方法需要修改模型的参数,这在一定程度上会影响到模型本身的性能;而指纹检测方法虽不会修改模型,但此前方法均依赖于对抗样本作为模型指纹,导致现有指纹检测方法均局限于分类任务,无法适用于其他重要的人工智能应用任务场景。
技术实现要素:
4.本发明针对模型窃取攻击,提出一种下游任务解耦的神经网络指纹检测方法。
5.模型所有者训练得到一个神经网络模型,简称目标模型;攻击者通过系统攻击等方式窃取该模型,并施以模型剪枝、参数微调和部分重训练等模型所有权混淆技术,得到一个盗版模型,称作正例嫌疑模型。若另有一神经网络的训练过程与目标模型无关,则称之为负例嫌疑模型。所述神经网络指纹检测方法,指提取目标模型的特定指纹信息,判断待检测的嫌疑模型为正例嫌疑模型或负例嫌疑模型。
6.本发明利用神经网络中修正线性单元(relu)的固有特性,通过比较目标模型与嫌疑模型第一个relu层形成的线性区域划分的相似性,进行模型指纹的检测:先为目标模型构建属于相同线性区域的多个指纹样本对,再检测嫌疑模型中这些指纹样本对是否仍属于相同线性区域。该验证机制基于线性区域划分而非对抗样本,故与具体的应用任务类型解耦。本发明中使用的指纹样本对在负例嫌疑模型中几乎不可能属于相同线性区域,故本发明具有较好的指纹独特性;同时,对于线性区域边界超平面的轻微扰动,线性区域划分通常相对稳定,故本发明具有较好的指纹鲁棒性。
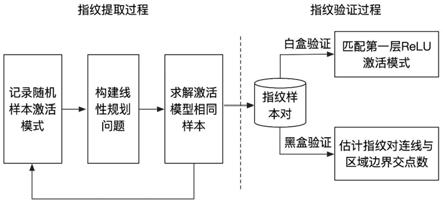
7.本发明提出的保护神经网络知识产权的指纹检测方法,是基于下游任务解耦的神经网络指纹检测方法,包括指纹提取阶段和指纹验证阶段;在指纹提取阶段,基于目标模型构建多组指纹样本对,其中每对样本在第一个relu层拥有相同的激活模式;在指纹验证阶段,检测提取的多个指纹样本对在嫌疑模型中是否仍属于相同线性区域,该阶段根据防御者对嫌疑模型访问权限的不同分为白盒和黑盒两个场景,白盒场景中防御者可获知嫌疑模型第一个relu层的激活模式,黑盒场景中防御者仅可获知嫌疑模型的预测结果,参见图1所示,具体步骤如下:
8.步骤一、指纹提取:为目标模型构建属于相同线性区域的n组指纹样本对。
9.(1.1)首先,从数据样本分布x中随机采样一个样本点x0,其在目标模型f中第一个
relu层的激活模式记为其中θ为目标模型f的参数,表示输入样本x在第一个relu层的激活模式,d1为该层的输出维度。
10.(1.2)通过求解下述优化问题构造与x0激活模式相同的另一个样本点:
[0011][0012]
其中,δ为添加在x0上的扰动,||δ||1表示扰动向量δ的l1范数。等式约束条件可以写成以下的等价形式:
[0013][0014]
这里,
⊙
表示向量逐位相乘,f1(x0+δ;θ)表示目标模型f的第一个线性层的输出结果,∈为边界距离参数,控制样本点到区域边界的距离,其值越大则产生的指纹样本离边界越远、鲁棒性越好。
[0015]
本发明中,边界距离参数∈优选为0.01。
[0016]
(1.3)用线性规划求解器求解上述优化问题,获得最优扰动,记为δ
*
,生成该指纹样本对中的另一个样本为:x1∶=x0+δ
*
。
[0017]
本发明中,线性规划求解器优选为glpk开源求解器。
[0018]
(1.4)将上述步骤重复n次,得到n组指纹样本对
[0019]
本发明中,指纹样本对个数n优选不小于50。
[0020]
步骤二、指纹验证:检测嫌疑模型中n组指纹样本对是否仍属于相同线性区域。作为防御者,给定已构建的多组指纹样本对和对嫌疑模型的白盒或黑盒访问权,输出嫌疑模型是否剽窃目标模型的置信度值,即嫌疑模型与目标模型的指纹匹配率。若该置信度值高于某个决策阈值ρ∈(0,1),则预测该嫌疑模型为正例,反之为负例。
[0021]
(2.1)白盒验证算法:该场景中,可获知嫌疑模型对于给定输入样本在第一个relu层的激活模式。对于某一嫌疑模型,直接查询a1(
·
)得到指纹样本对的第一层激活模式,即(a1(x
i0
),a1(x
i1
)),再通过归一化汉明距离(hammingdistance)计算嫌疑模型与目标模型的指纹匹配率为:
[0022][0023]
(2.2)黑盒验证算法:该场景中,仅可获知嫌疑模型f对于给定输入样本的预测结果。在容忍度η内,对于指纹样本对x0和x1,计算为两点x0与x1间的线段u(t)=x0+t(x
1-x0)与模型第一个relu层对应的边界超平面的交点数目是否为零:
[0024]
pointsonline(x0,x1,f):=1{|‖f(u(δ))-f(u(0))‖-‖f(u(1))-f(u(1-δ))‖|≥ηδ};
ꢀꢀ
(4)。
[0025]
其中,u(δ)表示在线段u(t)=x0+t(x
1-x0)的t=δ处对应的样本,δ为数值估计梯度时所使用的扰动半径参数。所述容忍度是指为比较两数值计算结果是否相等所设定的可容忍数值误差上界。
[0026]
本发明中,容忍度η优选为0.001;扰动半径参数δ优选为0.01。
[0027]
相应地,嫌疑模型与目标模型的指纹匹配率为:
[0028][0029]
本发明中,所述的模型所有权混淆技术,是指攻击者通过对模型参数施以各种后
置处理的技巧,以达到尽量与目标模型准确度类似的情况下,降低嫌疑模型与目标模型的相似性。涉及的后置处理技巧包括模型剪枝、参数微调、部分重训练。
[0030]
本发明中,所述的指纹检测方法的指纹独特性,是指负例嫌疑模型中被指纹检测方法正确验证为负例的比例;所述的指纹检测方法的指纹鲁棒性,是指正例嫌疑模型中被指纹检测方法正确验证为正例的比例。
[0031]
本发明中,所述的下游任务解耦是指,指纹检测算法不依赖于下游任务的特定属性,能应用于神经网络模型适用的多种下游任务场景,包括但不限于:分类、回归、生成任务。
[0032]
技术效果
[0033]
本发明基于目标神经网络构建属于相同线性区域的多组指纹样本对,并检测嫌疑模型中这些指纹样本对是否仍属于相同线性区域。该指纹检测机制基于线性区域的划分而非对抗样本,故本指纹检测方法与具体任务类型解耦,指纹样本的产生不依赖于训练数据,且具有较好的指纹独特性与鲁棒性。
[0034]
本发明的指纹检测方法与目标神经网络的具体应用任务解耦,适用于分类、回归、生成等任务类型。在分类任务中,本发明的鲁棒性与独特性均高于此前的ipguard指纹检测方法;在回归和生成任务中,本发明的白盒与黑盒验证方法对于攻击者的各种后置处理技巧有着不同的适用情况,均能较好地检测出盗版的模型。
附图说明
[0035]
图1为本发明方法流程示意图。
[0036]
图2为实施例指纹检测效果提升对比示意图。
[0037]
图3为本发明在回归和生成任务上指纹检测效果示意图。
具体实施方式
[0038]
本实施例选择分类任务类型,采用dermamnist数据集,通过本实施例方法对用于皮肤病诊断的深层卷积神经网络resnet-18进行知识产权保护,对各种嫌疑模型进行指纹检测。如图1所示,本实施例具体包括:
[0039]
步骤一、指纹提取:为目标模型构建属于相同线性区域的n组指纹样本对。
[0040]
(1.1)在生成一组指纹样本时,先从dermamnist数据集的数据样本分布x中随机采样一个样本点x0,在目标模型f,即模型所有者的原模型resnet-18中,它的第一个relu层的激活模式为其中θ为目标模型f的参数,表示某输入样本在第一个relu层的激活模式,d1为该层的输出维度。在本实施例中,d1为resnet-18中第一个relu层的输出维度:1*64*112*112。
[0041]
(1.2)通过求解下述优化问题构造与x0激活模式相同的另一个样本点:其中,δ为添加在x0上的扰动,等式约束条件可写成以下的不等式约束组:这里∈控制着样本点到区域边界的距离,其值越大则产生的指纹样本离边界越远、鲁棒性越好。在本实施例中,∈优选为0.01。
[0042]
(1.3)通过线性规划求解器gplk求解上述问题获得最优δ
*
,生成该指纹样本对中的另一个样本x1∶=x0+δ
*
。
[0043]
(1.4)将上述步骤重复n次,得到n组指纹样本对根据推荐设置,n应该不小于50,在本实施例中,n优选为100。
[0044]
步骤二、指纹验证:检测嫌疑模型中n组指纹样本对是否仍属于相同线性区域。作为防御者,给定已构建的多组指纹样本对和对嫌疑模型的白盒或黑盒访问权,输出嫌疑模型是否剽窃目标模型的置信度值,即嫌疑模型与目标模型的指纹匹配率。若该置信度值高于某个决策阈值ρ∈(0,1),则预测该嫌疑模型为正例,反之为负例。
[0045]
(2.1)白盒验证过程中,对于某一嫌疑模型,直接查询a1(
·
)得到指纹样本对的第一层激活模式,即(a1(x
i0
),a1(x
i1
)),则嫌疑模型与目标模型间的匹配率可通过归一化汉明距离计算得出:
[0046]
(2.2)黑盒验证过程中,将计算两点x0与x1间的线段与模型第一个relu层对应的边界超平面的交点数目是否为零:pointsonline(x0,x1,m)∶=1{|‖f(u(δ))-f(u(0))‖-‖f(u(1))-f(u(1-δ))‖|≥ηδ}。最终,嫌疑模型与目标模型间的匹配率为:在本实施例中,η优选为0.001。
[0047]
攻击者窃取目标模型并进行后置处理,得到25个正例嫌疑模型,其中涉及具体的模型所有权混淆技术包括模型剪枝(不同比例的权重剪枝、不同比例的卷积核剪枝)、参数微调(微调最后一层、微调所有层)以及部分重训练(重训最后一层、重训所有层);另有架构与训练集跟目标模型相同的、从零开始训练的25个负例嫌疑模型。如图2所示,使用本发明方法对嫌疑模型进行指纹检测,与现有的ipguard指纹检测方法对比,本发明在各决策阈值下,鲁棒性与独特性均高于ipguard方法。
[0048]
如图3所示,在iwpc(华法林剂量预测,属于回归任务)和fashionmnist(时装生成,属于生成任务)数据集上进行相同的实验,实验效果为:本发明的白盒与黑盒验证方法在各决策阈值下均表现较好的指纹鲁棒性与独特性。
[0049]
综上所述,本发明与下游任务解耦,能够广泛应用于各种任务类型的神经网络指纹检测,如分类、回归、生成任务等,以保护神经网络的知识产权,且对于各类正、负例嫌疑模型具有较好的指纹鲁棒性与独特性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1