一种半监督医疗图像的分割方法及装置
本发明涉及机器学习,尤其涉及一种半监督医疗图像的分割方法及装置。
背景技术:
1、近年来,随着医疗技术的快速发展,医院中患者数据的急剧增加,大量医疗影像数据急需处理。传统人工识别分析的方式,例如器官分割、肿瘤分割、靶区标定以及病理分析等,对医生的要求过高,过于依赖医生的状态及经验,具有成本高且效率低的特点。无法满足高效率的数据分析需求,给医生带来了很大的工作压力。面对海量的医疗图像,如何快速、高效并准确的将医疗影像中的目标成为了研究的热点。然而一个现实的问题是,医疗影像的获取并不难,但对其进行人工标注的过程却是代价昂贵的。例如,一份三维的核磁数据,往往就需要花费一名医生一整天的时间来完成标注,而现有的基于深度学习的识别方法均需要大量有标签数据作为训练基础,在数据量不足的情况下模型难以得到有效的训练。因此,如何能够将深度学习技术应用到医疗领域成为亟待解决的技术难题。
技术实现思路
1、本技术提供一种半监督医疗图像的分割方法及装置,可以充分利用带有标注的医疗影像样本数据,通过半监督学习,将医疗图像进行快速和准确的分割,完成医疗图像的识别任务。
2、第一方面,本技术提供了一种半监督医疗图像的分割方法,所述方法包括:
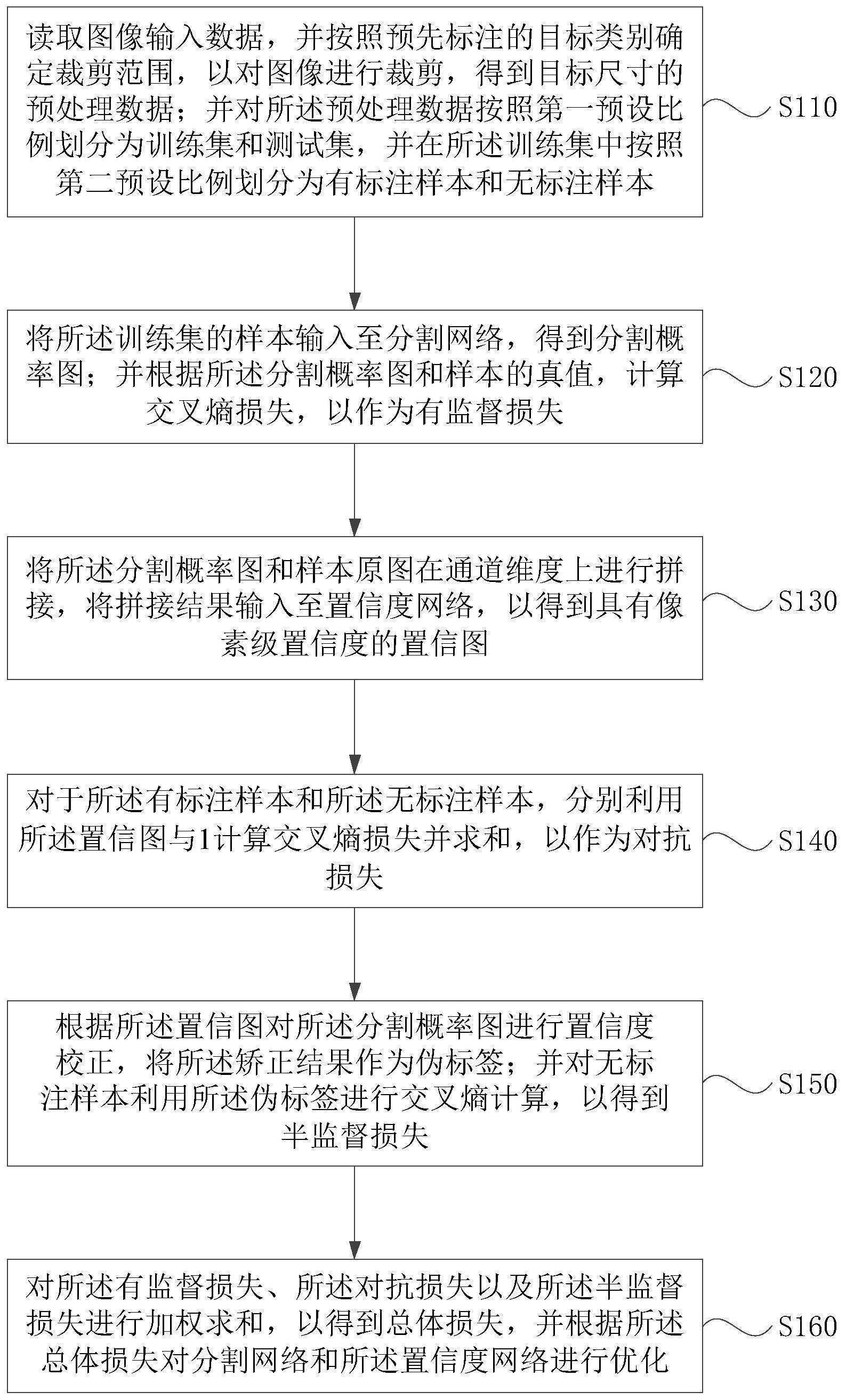
3、读取图像输入数据,并按照预先标注的目标类别确定裁剪范围,以对图像进行裁剪,得到目标尺寸的预处理数据;并对所述预处理数据按照第一预设比例划分为训练集和测试集,并在所述训练集中按照第二预设比例划分为有标注样本和无标注样本;
4、将所述训练集的样本输入至分割网络,得到分割概率图;并根据所述分割概率图和样本的真值,计算交叉熵损失,以作为有监督损失;
5、将所述分割概率图和样本原图在通道维度上进行拼接,将拼接结果输入至置信度网络,以得到具有像素级置信度的置信图;
6、对于所述有标注样本和所述无标注样本,分别利用所述置信图与1计算交叉熵损失并求和,以作为对抗损失;
7、根据所述置信图对所述分割概率图进行置信度校正,将所述矫正结果作为伪标签;并对无标注样本利用所述伪标签进行交叉熵计算,以得到半监督损失;
8、对所述有监督损失、所述对抗损失以及所述半监督损失进行加权求和,以得到总体损失,并根据所述总体损失对所述分割网络和所述置信度网络进行优化。
9、进一步的,在得到具有像素级置信度的置信图之后,所述方法还包括:
10、对于所述有标注样本,根据所述置信图与样本的真值计算交叉熵损失,以进行反向传播优化所述置信度网络。
11、进一步的,在得到目标尺寸的预处理数据之后,所述方法还包括:
12、对所述预处理数据进行数据增强处理,得到增强数据集;其中,所述增强处理包括沿任一空间坐标轴进行翻转处理和/或旋转处理,其中,所述旋转处理的旋转角度为预设角度值。
13、进一步的,所述分割网络为三维形式的u-net网络,具体包括:三个下采样模块、一个桥接模块、三个上采样模块以及聚合卷积模块;
14、其中,所述下采样模块包括两个卷积层及一个池化层,卷积核为3×3×3,步长为1,padding为1;池化层步长为2,池化大小为2×2×2;
15、所述桥接模块包括两个卷积层,卷积核为3×3×3,步长为1,padding为1;
16、所述上采样模块包括一次反卷积操作,及两次卷积操作,反卷积操作的卷积核大小为3×3×3,步长为2,padding为1,卷积操作的卷积核大小为3×3 ×3,步长为1,padding为1;
17、所述聚合卷积模块设置为单层卷积,卷积核大小为1×1×1,步长为1, padding为0。
18、进一步的,根据所述分割概率图和样本的真值,计算交叉熵损失,以作为有监督损失,包括:
19、采用如下公式计算有监督损失:
20、lsup=ldice+lce;
21、
22、
23、
24、
25、其中,lsup为有监督损失,ldice为dice损失,lce为交叉熵损失,为有标注样本的真实标签y的one-hot向量形式,θ代表网络的参数,s为分割网络,c为真实标签的类别,∈为平滑因子,πc为各类别的均衡权重,i为真实标签的分类函数。
26、进一步的,对于所述有标注样本,根据所述置信图与样本的真值计算交叉熵损失,以进行反向传播优化所述置信度网络,包括:
27、对于有标注样本xl,从确定有标注样本的分割概率图根据所述置信图与样本的真值计算交叉熵损失的计算公式如下:
28、
29、其中,d为置信度网络,s为分割网络,θ代表网络的参数,lbce为交叉熵损失函数,g为置信度与样本的真值的配对结果,其中交叉熵损失与配对函数的计算方式如下:
30、
31、
32、其中,q为任意样本的样本的真值,为该样本的预测结果;
33、相应的,对于所述有标注样本和所述无标注样本,分别利用所述置信图与 1计算交叉熵损失并求和,以作为对抗损失,包括:
34、所述对抗损失的计算公式如下:
35、ladv(xl,θs)=lbce(d(s(xl;θs)),1)+lbce(d(s(xu;θs)),1);
36、其中θs为分割网络参数,xl,xu分别为有标注样本和无标注样本,d为置信度网络,s为分割网络。
37、进一步的,根据所述置信图对所述分割概率图进行置信度校正,将所述矫正结果作为伪标签,包括:
38、将无标注样本的置信图中置信度高于设定阈值的区域采用预测结果作为伪标签,置信图中置信度低于设定阈值的区域采用作为伪标签,并以yi作为第i类伪标签表示,则所述伪标签的表达式如下:
39、
40、相应的,对无标注样本利用所述伪标签进行交叉熵计算,以得到半监督损失,包括:
41、对于无标注样本,利用所生成的伪标签计算半监督损失,计算公式如下:
42、
43、其中,为无标注样本的概率特征,xu为无标注样本,为伪标签。
44、第二方面,本技术提供了一种半监督医疗图像的分割装置,该装置包括:
45、预处理单元,用于读取图像输入数据,并按照预先标注的目标类别确定裁剪范围,以对图像进行裁剪,得到目标尺寸的预处理数据;并对所述预处理数据按照第一预设比例划分为训练集和测试集,并在所述训练集中按照第二预设比例划分为有标注样本和无标注样本;
46、有监督损失计算单元,用于将所述训练集的样本输入至分割网络,得到分割概率图;并根据所述分割概率图和样本的真值,计算交叉熵损失,以作为有监督损失;
47、置信图确定单元,用于将所述分割概率图和样本原图在通道维度上进行拼接,将拼接结果输入至置信度网络,以得到具有像素级置信度的置信图;
48、对抗损失计算单元,用于对于所述有标注样本和所述无标注样本,分别利用所述置信图与1计算交叉熵损失并求和,以作为对抗损失;
49、半监督损失计算单元,用于根据所述置信图对所述分割概率图进行置信度校正,将所述矫正结果作为伪标签;并对无标注样本利用所述伪标签进行交叉熵计算,以得到半监督损失;
50、模型优化单元,用于对所述有监督损失、所述对抗损失以及所述半监督损失进行加权求和,以得到总体损失,并根据所述总体损失对所述分割网络和所述置信度网络进行优化。
51、本技术所提供的技术方案,通过对样本的预处理,以及采用分割网络和置信度网络完成半监督的模型训练,以得到一个系统的医疗图像分割方法,实现快速并准确的完成医疗图像分割的目的。
- 还没有人留言评论。精彩留言会获得点赞!