一种查询数据修复方法、系统、计算机设备及存储介质与流程
1.本发明属于数据处理技术领域,具体涉及一种查询数据修复方法、系统、计算机设备和存储介质。
背景技术:
2.随着互联网科技的飞速发展,人才招聘的方式也逐渐实现在线化。其中,在线招聘时,需要对接数据库来实现准确理解用户需求,并刻画用户肖像,以及自动修复缺失数据。例如,在招聘数据库中。在线招聘业务中的搜索/推荐场景,经常由于简历或职位的数据缺失,导致搜索/推荐召回量和匹配度受到限制,很难实现大幅度提升。归其原因,是因为在通常情况下用户都习惯使用简写内容,而非标准内容。比如:用户搜索智联公司职位时,很少会输入公司全名“北京网聘咨询有限公司”进行搜索,更多是“智联”或“智联招聘”等。在简历填写环节,用户填写教育经历,通常会填写“北大”、“理工”等内容。这种数据缺失问题,在简历、职位和公司基本信息填写等场景中都普遍存在。正是用户这种输入习惯,给在线招聘业务的搜索/推荐召回和匹配带来巨大挑战。针对这一问题,需要提供一种查询数据修复方法、系统、计算机设备和存储介质,用于实时修复、补全数据,实现用户与匹配内容的相关性对齐,召回最相关数据,从根本上实现查询的召回量和匹配度的双向提升。
技术实现要素:
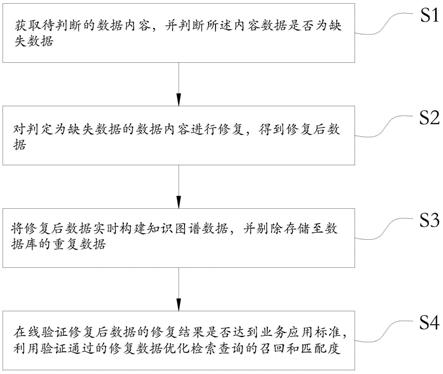
3.为解决现有技术中由于简历或职位的数据缺失,导致搜索/推荐召回量和匹配度受到限制,很难实现大幅度提升的问题,本发明提供了一种查询数据修复方法、系统、装置和存储介质,基于实时计算链路对在线招聘业务主数据修复,实现了主数据缺失性判断、数据修复、数据的验证、构建以及相关性判断,形成完成的查询数据修复闭环,实时修复、补全数据,实现用户与匹配内容的相关性对齐,召回最相关数据,从根本上实现查询的召回量和匹配度的双向提升。本发明采用以下技术方案实现:一种查询数据修复方法,包括:获取待判断的数据内容,并判断所述内容数据是否为缺失数据;对判定为缺失数据的数据内容进行修复,得到修复后数据;将修复后数据实时构建知识图谱数据,并剔除存储至数据库的重复数据;在线验证修复后数据的修复结果是否达到业务应用标准,利用验证通过的修复数据优化检索查询的召回和匹配度。可选的,判断所述内容数据是否为缺失数据的方法,包括:读取用户端输入的数据内容,其中,所述数据内容包括用户端填写至搜索框中的查询数据以及简历数据;基于用户行为数据和领域知识图谱数据,遍历获取的数据内容,判断所述数据内
容是否为缺失内容;针对缺失内容基于构建的领域知识图谱数据,判断所述缺失内容是否已补全;标记缺失未补全的数据内容,得到缺失数据。可选的,所述对判定为缺失数据的数据内容进行修复的方法,包括:获取待修复的缺失数据;根据用户行为数据和领域知识图谱数据,实时对所述缺失数据进行修复;通过搜索与用户行为偏好相关性的所述用户行为数据,完成所述缺失数据的修复;通过爬虫实时采集互联网开放域知识,获取与所述缺失数据相对应的标签数据,并进行标注确认后,生成特征标签数据,建立用户输入数据与修复后数据的领域知识图谱数据,完成所述缺失数据的修复。可选的,将修复后数据实时构建知识图谱数据,并剔除存储至数据库的重复数据的方法,包括:获取修复后的数据,定位为宽表数据,以三元组(spo)数据形式将宽表数据转换为元数据表中的三元组数据,设立知识图谱数据存储的分层架构的基础spo层;根据所述元数据表中三元组数据的属性生成链路,对构建三元组的基础层的实体数据进行去重归一处理,清除无效数据,设立知识图谱数据存储的分层架构的实体数据归一层;将实体数据归一层的三元组数据转换为宽表数据,实现三元组数据的属性名称及数据类型映射到宽表数据,设立知识图谱数据存储的宽表服务应用层。进一步的,所述元数据表包括生成的实体类别表、实体属性表、构建的自动化入库任务元数据表、记录溯源表以及辅助表;其中,所述实体类别表包括实体类别编号、类别名称、级别、父类编号,所述实体属性表用于约束实体数据的属性,所述属性包括实体数据的基本属性和关系属性,实体属性表包括属性名称、属性所属类别、是否多值;所述自动化入库任务元数据表用于描述对实体数据所对应的属性,进行自动化构建,所述自动化入库任务元数据表包括任务编号、属性名称、数据来源、字段映射、关系属性约束、是否构建逆向关系;所述记录溯源表用于记录数据构建过程中的过程信息和详细配置信息,便于数据的溯源,所述记录溯源表包括溯源id、实体类别、构建时间、类型、数据来源、版本号;所述辅助表包括属性约束表、数据来源表、定制化宽表转换配置表等。可选的,所述在线验证修复后数据的修复结果是否达到业务应用标准的方法为:将修复后数据推送至线上,经小流量实验分析,以验证数据修复结果是否达到业务应用标准。本发明还包括一种查询数据修复系统,所述查询数据修复系统采用前述查询数据修复方法实现缺失数据修复;所述查询数据修复系统包括数据缺失性判断模块、数据修复模块、数据构建模块以及数据验证模块。所述数据缺失性判断模块用于获取待判断的数据内容,并根据用户行为数据和领域知识图谱数据判断所述内容数据是否为缺失数据,以及缺失数据是否补全;所述数据修复模块用于对判定为缺失数据的数据内容依据用户行为数据和/或爬虫实时采集互联网开放域知识进行修复,得到修复后数据;所述数据构建模块用于将修复后数据以三元组结构
的形式,进行递进式分层的方式实时构建知识图谱数据存储,并根据知识图谱数据自动构建链路,以剔除存储至数据库的重复数据;所述数据验证模块用于在线验证修复后数据的修复结果是否达到业务应用标准,利用验证通过的修复数据双向提升查询的召回量和匹配度。本发明还包括一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现查询数据修复方法的步骤。本发明还包括一种存储介质,存储有计算机程序,所述计算机程序被处理器执行时实现查询数据修复方法的步骤。本发明提供的技术方案,具有如下有益效果:本发明通过对在线招聘业务中的搜索/推荐场景涉及到的数据缺失问题,进行实时修复、补全数据,实现用户与匹配内容的相关性对齐,召回最相关数据,从根本上实现查询的召回量和匹配度的双向提升。通过对主数据的缺失性判断、修复、构建以及验证,形成完整闭环,在进行查询时,可以查看与实体数据油管的所有实体数据,探索实体数据的关系网数据以及所有实体数据的属性和关系。
附图说明
4.附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:图1为本发明实施例1的一种查询数据修复方法的流程图。图2为本发明实施例1的查询数据修复方法中简历数据修复前后的示意图。图3为本发明实施例1的查询数据修复方法中数据缺失性判断的流程图。图4为本发明实施例1的查询数据修复方法中缺失数据修复的流程图。图5为本发明实施例1的查询数据修复方法中构建知识图谱数据的流程图。图6为本发明实施例1的查询数据修复方法中构建任务三个分支的示意图。图7为本发明实施例1的查询数据修复方法中三元组结构数据进行spo转宽表的示意图。图8为本发明实施例2的一种查询数据修复系统的系统框图。
具体实施方式
5.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。知识图谱,其本质上是语义网络,是一种基于图的数据结构,可以由节点(point)和边(edge)组成。在知识图谱里,每个节点表示现实世界中存在的“实体”,每条边为实体与实体之间的“关系”。知识图谱是关系的有效的表示方式。通俗理解,知识图谱可以是把所有不同种类的信息连接在一起而得到的一个关系网络。知识图谱提供了从“关系”的角度去分析问题的能力。假设用知识图谱来描述一个事实:张三是李四的父亲。这里实体是张三和李四,关系是父亲。当然,张三和李四有可能会跟其他人存在着某种类型的关系,在此暂不考虑。当把电话号码也作为节点加入到知识图谱以后,电话号码也是实体,人和电话之间也可
以定义一种关系叫has_phone,即某个电话号码属于某个人。可以把时间作为属性添加到has_phone关系里来表示开通电话号码的时间,这种属性不仅可以加到关系里,还可以加到实体当中等。简历知识图谱是利用简历相关的信息构建的知识图谱。简历知识图谱可以是一整套实现知识表示和推理的框架,包括知识图谱实体、关系、词林(同义词、上下位词)、垂直知识图谱(领域专业图谱)、知识维护模块、机器学习推理引擎(上下位和等位推理、不一致推理、知识发现推理、本体概念推理)等。知识图谱的推理机制一方面在简历解析时起到辅助识别作用;另一方面在信息评估中,实现实体定位、匹配程度识别等功能,为最终的简历评估提供支持。在一个实施例中,可以利用已评估过的历史简历生成简历知识图谱。已评估过的历史简历,可以包括已经应聘成功的求职者的简历,还可以包括没有应聘成功的求职者的简历。已评估过的历史简历,可以是对历史简历进行整体评分后的简历,也可以是针对简历中一个或多个简历信息进行评分后的简历。简历知识图谱中至少包括历史简历的简历信息相对于岗位的岗位需求的相关性信息。岗位需求可以由招聘需求和领域定位确定。例如,可以包括技能需求、学历需求、工作年限需求、行业特征需求等等。简历信息可以是简历中记录的信息,例如,包括个人描述、学习经历描述、工作经历描述等。简历知识图谱中的节点以及节点间的关系,可以根据需求配置。例如,简历知识图谱中的节点可以包括岗位节点和简历节点等。岗位节点可以用于表示岗位需求,简历节点可以用于表示与简历相关的信息。简历知识图谱中的节点连边用于表示相连节点之间具有关联关系。相关性信息可以是关联度、评分或匹配度等用于评价关联性的信息。示例的,简历节点与岗位节点的节点连边的属性,可以包括简历节点相对于岗位节点的价值属性。价值属性可以由评分值/关联度等方式来体现。在某些示例中,某些简历节点还具有价值属性。例如,某个节点表示获得了诺贝尔奖,该节点具有价值属性,用来描述该节点的价值。在确定节点间的相关性时,可以由节点间连边的价值属性来确定,也可以由节点的价值属性来确定。构建简历知识图谱的方式有很多种,在此不一一赘述。本技术旨在解决,当查询数据被判定为缺失数据时,并需要进行修复时,如何实时进行数据修复。本发明提供的一种查询数据修复方法、系统、计算机设备及存储介质,对解决在线招聘业务中的搜索/推荐场景涉及到的数据缺失问题时,通过对招聘业务中主数据进行缺失性判断、修复、构建以及验证,形成完整闭环,实时修复和补全数据。实现用户与匹配内容的相关性对齐,召回最相关数据,从根本上实现查询的召回量和匹配度的双向提升。以下将结合具体实施例加以说明。实施例1如图1所示,本发明的一个实施例提供一种查询数据修复方法,该方法用于对用户端用户输入的数据内容进行缺失判断并修复,该方法包括如下步骤:s1、获取待判断的数据内容,并判断所述内容数据是否为缺失数据。在本实施例中,缺失数据主要分为两种类型,一种为用户实际填写了内容,人可以认知,但机器很难识别。参见图2所示,简历数据修复前后的示意图。例如原始简历的学校名称填写的”北大”。因为人有背景知识,可以知道”北大”实际指”北京大学”,但机器却不能将两者的关系建立起来;另外一种为用户没有填写,但知识隐藏在了已填内容中,需要辅助背景知识读取,还是以”北大”为例,人知道该用户是985和211学校毕业的,虽然用户并没有具
体填写,而机器却无法知道这些。显然,这两类缺失数据补充修复对于人岗匹配在召回和匹配度上的影响是至关重要的。为了解决以上两种类型缺失数据问题。参见图3所示,判断所述内容数据是否为缺失数据的方法,包括:s101、读取用户端输入的数据内容,其中,所述数据内容包括用户端填写至搜索框中的查询数据以及简历数据。s102、基于用户行为数据和领域知识图谱数据,遍历获取的数据内容,判断所述数据内容是否为缺失内容。s103、针对缺失内容基于构建的领域知识图谱数据,判断所述缺失内容是否已补全。s104、标记缺失未补全的数据内容,得到缺失数据。在本实施例中,是基于用户行为数据和领域知识图谱数据,实时计算用户输入内容是否为缺失数据,以及该数据内容是否已补全。具体的行为数据包括:用户端主要为使用用户在搜索框中输入的查询内容、职位点击、职位查看、职位投递数据;负责招聘的hr输入的查询内容、简历工作经历、简历教育经历等数据。例如:通过用户端用户输入查询内容“智联”、以及后续职位点击、职位查看和职位投递的公司为“北京网聘咨询有限公司”等偏好数据,能够判断,用户输入的“智联”为缺失内容。基于构建的领域知识图谱数据,能够判断该缺失数据是否已补全。s2、对判定为缺失数据的数据内容进行修复,得到修复后数据。在本实施例中,参见图4所示,对判定为缺失数据的数据内容进行修复的方法,包括:s201、获取待修复的缺失数据;s202、根据用户行为数据和领域知识图谱数据,实时对所述缺失数据进行修复;s203、通过搜索与用户行为偏好相关性的所述用户行为数据,完成所述缺失数据的修复;s204、通过爬虫实时采集互联网开放域知识,获取与所述缺失数据相对应的标签数据,并进行标注确认后,生成特征标签数据,建立用户输入数据与修复后数据的领域知识图谱数据,完成所述缺失数据的修复。在实施例中,被判定为缺失数据并需要进行修复的数据内容,会实时进行数据修复。数据修复主要提供两种途径:一种为基于用户行为数据进行修复。行为数据包括:搜索查询、职位点击、职位查看、职位投递数据、简历工作经历、简历教育经历等数据。通过搜索与行为偏好间的相关性计算,从而完成缺失数据的修复。例如:搜索“智联招聘”的用户,都会直接查看“北京网聘咨询有限公司”的职位。从而建立,“智联招聘”与“北京网聘咨询有限公司”实体间的关系。另外一种,就是采用爬虫实时采集互联网开放域知识,获取“北大”与“北京大学”关系数据,“北京大学”与
→“
985、211”标签数据。然后人工标注确认后,进行特征标签生产加工,生成标签数据,建立用户输入数据与修复后数据的关系。s3、将修复后数据实时构建知识图谱数据,并剔除存储至数据库的重复数据。在本实施例中,修复后的数据,会通过数据构建模块,实时构建入库。为了提高缺
失数据修复和服务能力,本发明将修复后的数据,以三元组(spo)结构形式构建入库。这样结构数据,不仅保留了数据间丰富的语义含义,对图数据库也更加友好,特别是在数据修复、加工这类业务上更加灵活,比较符合多源、多样的缺失数据修复加工和服务应用场景。为了保证数据入库质量,以及上层业务调用数据的一致性,本发明通过元数据统一管理属性的入库过程。采用的方案包括:1)元数据配置;2)知识图谱元数据管理平台;3)递进式的分层进行构建知识图谱的数据存储;4)知识图谱数据的自动化构建链路;标准化去重等。参见图5所示,将修复后数据实时构建知识图谱数据的方法,包括:s301、获取修复后的数据,定位为宽表数据,以三元组(spo)数据形式将宽表数据转换为元数据表中的三元组数据,设立知识图谱数据存储的分层架构的基础spo层;s302、根据所述元数据表中三元组数据的属性生成链路,对构建三元组的基础层的实体数据进行去重归一处理,清除无效数据,设立知识图谱数据存储的分层架构的实体数据归一层;s303、将实体数据归一层的三元组数据转换为宽表数据,实现三元组数据的属性名称及数据类型映射到宽表数据,设立知识图谱数据存储的宽表服务应用层。在本实施例中,所述元数据表包括生成的实体类别表、实体属性表、构建的自动化入库任务元数据表、记录溯源表以及辅助表。所述实体类别表包括实体类别编号、类别名称、级别、父类编号,所述实体属性表用于约束实体数据的属性,所述属性包括实体数据的基本属性和关系属性,实体属性表包括属性名称、属性所属类别、是否多值;所述自动化入库任务元数据表用于描述对实体数据所对应的属性,进行自动化构建,所述自动化入库任务元数据表包括任务编号、属性名称、数据来源、字段映射、关系属性约束、是否构建逆向关系;所述记录溯源表用于记录数据构建过程中的过程信息和详细配置信息,便于数据的溯源,所述记录溯源表包括溯源id、实体类别、构建时间、类型、数据来源、版本号;所述辅助表包括属性约束表、数据来源表、定制化宽表转换配置表等。本发明搭建了统一的知识图谱元数据管理平台,由数据模型师提前预设各类实体和属性元数据,可管控内容包括:属性名称、中文含义、属性描述、边类型、单/多值、所属类、数据类型、来源标识、规则约束等。在数据入库前,首先需要在元数据管理平台统一配置元数据,在数据入库中,程序会读取元数据进行校验,以保证入库数据符合数据标准。例如:“北京大学”的985、211标签字段,就是多值类型,配置好多值类型后,系统才能准确识别并自动构建多值数组格式,这样才能在召回和匹配中应用起来。在知识图谱数据构建中,因为其实体、关系和属性等数据大多来自多源渠道,所以,无法避免会出现数据重复入库问题,例如:“北京大学”实体的“北大”属性入多次。像这种重复数据,不仅占用存储空间,也影响业务的实际应用效果。为避免这一问题,既要保证数据入库效率,又要保证数据高可用性,本发明充分利用了入库链路分层特点,在上层对重复数据进行可信度判断和重复数据去重。基于数据库本身提供的重复值去重能力,剔除重复数据。在本发明的一个实施例中,将实体数据抽象为元数据表,对数据进行统一的规范、约束个管理;具体包括:1.1)生成实体类别表,主要有实体类别编号、类别名称、级别、父类编号。
1.2)生成实体属性表,约束实体有哪些属性(基本属性和关系属性)、主要有属性名称、属性所属类别、是否多值等。1.3)构建自动化入库任务元数据表,描述对哪个实体哪些属性进行自动化构建,主要有任务编号、属性名称、数据来源、字段映射、关系属性约束、是否构建逆向关系。1.4)数据构建记录溯源表,记录数据构建过程中的过程信息和详细配置信息,便于数据的溯源,主要有trackid(溯源id)、实体类别、构建时间、类型、数据来源、版本号等。1.5)另外一些提高数据质量的辅助表,比如:属性约束表、kg_source数据来源表、定制化宽表转换配置表等。在本实施例中,根据元数据属性生成链路,具体包括:实体类别管理、实体属性管理、数据来源的管理。将修复后数据实时构建知识图谱数据中,参见图6所示,整个构建任务分为三个分支:三元组(spo)结构存储、数据归一和去重和spo转宽表。其中:(1)三元组结构存储的目的就是支持动态多样的属性类型变化和图计算查询支持。支持任意属性的动态增加。比如:“北京网聘咨询有限公司”实体增加属性别名“智联招聘”,增加属性曾用名“北京智联三珂人才服务有限公司”等,都不用修改表结构,动态增加即可。(2)数据归一和去重任务的目的是为了保证在为前端业务提供数据服务时,保证数据的一致性和可靠性,不能出现歧义。比如:“北京网聘咨询有限公司”和“北京智联三珂人才服务有限公司”其实是同一家公司的不同抬头,对外提供服务时,要基于统一标准化后的数据进行服务,统一采用“北京网聘咨询有限公司”对外服务。实现数据归一和去重,就是通过数据归一模型,判断两个实体的相似性,如果相似性达到一定阈值,及证明数据是统一实体,进行实体归一。在公司实体相似性模型中,本发明选择的特征包括:公司名称、公司注册地址、公司法人、公司股权关系等。(3)spo转宽表的任务目的是为了解决三元组结构数据的分析和挖掘场景,提供的数据格式自动化转化。参见图7所示,三元组结构的优点是构建方便、灵活,缺点是不适合在hive、mysql等非图数据库中进行数据分析和挖掘,因为,要通过大量join表操作。不仅开发成本高,执行过滤低。所以,本发明实现了spo转宽表的服务,基于元数据,将spo结构的数据表,自动转化为宽表结构,为数据分析和挖掘提供服务。在本发明的一个实施例中,知识图谱数据存储的分层架构设立包括三层,其中,第一层为基础spo层,第二层实体数据归一层,第三层宽表服务应用层。所述基础spo层:kg数据的基础数据,包含各个数据来源,尚未对实体进行归一的数据,主要实现将宽表数据转换为三元组数据,实体属性关系配置化,数据可追溯trackid生成,互逆关系的自动构建,可靠数据源属性把控,数据存储于dm_garph层。所述实体数据归一层:对基础层实体数据进行去重归一,主要实现数据归一,数据的排序,根据单值/多值去重,无效数据的清洗,数据来源的把控,数据存储于dmr_garph层。所述宽表服务应用层:对数据使用方提供一站式服务,方便不懂spo的用户室友,主要实现属性名称及数据类型到宽表的映射,配置化构建,数据存储于dma_garph层。s4、在线验证修复后数据的修复结果是否达到业务应用标准,利用验证通过的修复数据优化检索查询的召回和匹配度。在本实施例中,所述在线验证修复后数据的修复结果是否达到业务应用标准的方
法为:将修复后数据推送至线上,经小流量实验分析,以验证数据修复结果是否达到业务应用标准。最后,在进行检索时,在该方法构建的平台上进行检索,可以优化检索,查询实现召回量和匹配度双向提升。通过该方法构建的平台进行检索时,可以点击查看公司的详情信息;点击查看和该公司有关系的实体,进入该实体的详情页,后续可以进一步查看和这个实体有关系的所有实体,进而可以探索某个实体的关系网数据;点击进入实体详情页,可以看到该实体的属性和关系。实施例2如图8所示,本发明的一个实施例中提供了一种查询数据修复系统包括数据缺失性判断模块11、数据修复模块12、数据构建模块13以及数据验证模块14。所述数据缺失性判断模块11用于获取待判断的数据内容,并根据用户行为数据和领域知识图谱数据判断所述内容数据是否为缺失数据,以及缺失数据是否补全。在本实施例中,数据缺失性判断模块11针对两种类型缺失数据问题进行判断,缺失数据的两种类型分别为:用户实际填写了内容,人可以认知,但机器很难识别;用户没有填写,但知识隐藏在了已填内容中,需要辅助背景知识读取。所述数据缺失性判断模块11可以读取用户端输入的包括上述两种类型缺失数据的数据内容,基于用户行为数据和领域知识图谱数据,遍历获取的数据内容,判断所述数据内容是否为缺失内容。针对缺失内容基于构建的领域知识图谱数据,判断所述缺失内容是否已补全,标记缺失未补全的数据内容,得到缺失数据。所述数据缺失性判断模块11可以基于构建的领域知识图谱数据,能够判断该缺失数据是否已补全。所述数据修复模块12用于对判定为缺失数据的数据内容依据用户行为数据和/或爬虫实时采集互联网开放域知识进行修复,得到修复后数据。在本实施例中,所述数据修复模块12进行修复时,通过获取待修复的缺失数据,根据用户行为数据和领域知识图谱数据,实时对所述缺失数据进行修复。修复的方法分为两种,一种是基于用户行为数据,通过搜索与用户行为偏好相关性的所述用户行为数据,完成所述缺失数据的修复。另一种是基于领域知识图谱数据,通过爬虫实时采集互联网开放域知识,获取与所述缺失数据相对应的标签数据,并进行标注确认后,生成特征标签数据,建立用户输入数据与修复后数据的领域知识图谱数据,完成所述缺失数据的修复。例如,行为数据包括:搜索查询、职位点击、职位查看、职位投递数据、简历工作经历、简历教育经历等数据。通过搜索与行为偏好间的相关性计算,从而完成缺失数据的修复。例如:搜索“智联招聘”的用户,都会直接查看“北京网聘咨询有限公司”的职位。从而建立,“智联招聘”与“北京网聘咨询有限公司”实体间的关系。基于领域知识图谱数据修复时,例如,获取“北大”与“北京大学”关系数据,“北京大学”与
→“
985、211”标签数据。然后人工标注确认后,进行特征标签生产加工,生成标签数据,建立用户输入数据与修复后数据的关系。所述数据构建模块13用于将修复后数据以三元组结构的形式,进行递进式分层的方式实时构建知识图谱数据存储,并根据知识图谱数据自动构建链路,以剔除存储至数据库的重复数据。其中,数据构建模块13在知识图谱数据构建中,针对重复数据的剔除前,由于实体、关系和属性等数据大多来自多源渠道出现的数据重复入库问题,利用了入库链路
分层特点,在上层对重复数据进行可信度判断和重复数据去重。基于数据库本身提供的重复值去重能力,剔除重复数据。所述数据构建模块13还用于将实体数据抽象为元数据表,对数据进行统一的规范、约束个管理。元数据表包括生成的实体类别表、实体属性表、构建的自动化入库任务元数据表、记录溯源表以及辅助表。根据元数据属性生成链路,实现实体类别管理、实体属性管理、数据来源的管理。通过三元组(spo)结构存储、数据归一和去重和spo转宽表构建整个构建任务。所述数据验证模块14用于在线验证修复后数据的修复结果是否达到业务应用标准,利用验证通过的修复数据双向提升查询的召回量和匹配度。在本实施例中,通过数据验证模块14将修复后数据内容推送到线上,联网进行小流量a/b实验显著性分析以验证数据修复结果。最后通过在该系统构建的平台进行检索,可以优化检索,查询实现召回量和匹配度双向提升。实施例3在本发明的一个实施例中提供了一种计算机设备,该计算机设备可以用于实施上述实施例中提供的查询数据修复方法,该计算机设备可以是智能手机、电脑、平板电脑等设备。所述计算机设备包括存储器和处理器,存储器中存储有计算机程序,该处理器执行计算机程序时实现上述方法实施例中的步骤:获取待判断的数据内容,并判断所述内容数据是否为缺失数据;对判定为缺失数据的数据内容进行修复,得到修复后数据;将修复后数据实时构建知识图谱数据,并剔除存储至数据库的重复数据;在线验证修复后数据的修复结果是否达到业务应用标准,利用验证通过的修复数据优化检索查询的召回和匹配度。实施例4本发明的一个实施例中还提供了一种存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述各方法实施例中的步骤:获取待判断的数据内容,并判断所述内容数据是否为缺失数据;对判定为缺失数据的数据内容进行修复,得到修复后数据;将修复后数据实时构建知识图谱数据,并剔除存储至数据库的重复数据;在线验证修复后数据的修复结果是否达到业务应用标准,利用验证通过的修复数据优化检索查询的召回和匹配度。本实施例提供的基于知识图谱进行的查询数据修复方法可以通过软件执行,也可以通过软件和硬件相结合或者硬件执行的方式实现,所涉及的硬件可以由两个或多个物理实体构成,也可以由一个物理实体构成。本实施例方法可以应用于具有处理能力的电子设备。其中,电子设备可以是pc、平板电脑、笔记本电脑、台式电脑等设备。需要说明的是,对本技术所述查询数据修复方法而言,本领域普通测试人员可以理解实现本技术实施例所述查询数据修复方法的全部或部分流程,是可以通过计算机程序来控制相关的硬件来完成,所述计算机程序可存储于一计算机可读存储介质中,如存储在计算机设备的存储器中,并被该计算机设备内的至少一个处理器执行,在执行过程中可包
括如所述查询数据修复方法的实施例的流程。相应的,本说明书实施例还提供一种计算机存储介质,所述存储介质中存储有程序指令,所述程序指令被处理器执行时实现上述任一项所述基于知识图谱的查询数据修复方法。本说明书实施例可采用在一个或多个其中包含有程序代码的存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。计算机可用存储介质包括永久性和非永久性、可移动和非可移动媒体,可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括但不限于:相变内存(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、只读光盘只读存储器(cd-rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。对本技术实施例的所述查询数据修复装置而言,其各功能模块可以集成在一个处理芯片中,也可以是各个模块单独物理存在,也可以两个或两个以上模块集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读存储介质中,所述存储介质譬如为只读存储器,磁盘或光盘等。综上所述,本发明通过对在线招聘业务中的搜索/推荐场景涉及到的数据缺失问题,进行实时修复、补全数据,实现用户与匹配内容的相关性对齐,召回最相关数据,从根本上实现查询的召回量和匹配度的双向提升。通过对主数据的缺失性判断、修复、构建以及验证,形成完整闭环,在进行查询时,可以查看与实体数据油管的所有实体数据,探索实体数据的关系网数据以及所有实体数据的属性和关系。以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1