基于机器学习的SQL注入攻击检测方法与流程
基于机器学习的sql注入攻击检测方法
技术领域
1.本发明涉及一种网络安全的大数据分析技术。更具体地说,本发明涉及一种基于机器学习的sql注入攻击检测方法。
背景技术:
2.在当下的“5g”时代,网络早已融入人们的日常生活,云数据量呈现爆炸式增长,与此同时,每个人都被数字所包围,网络安全理所当然成为目前炙手可热的话题。用户使用的每个浏览器、app甚至用户本身,都会被各大公司以数据的形式存放于数据库中,不论对于个人用户还是企业来说,有数据的地方,就有被入侵的危险。不法分子往往会利用程序中的漏洞进行网络攻击,而网络攻击造成的后果通常是非常严重的,比如盗取或滥用数据信息、致使服务器瘫痪甚至盗取钱财等。近年来,针对sql注入检测的研究也偶有出现,比如基于tf
‑
idf的机器学习检测技术,但是tf
‑
idf提取出来的特征向量往往数据维度非常大,甚至达到上千维,不仅消耗资源,且速度较慢;而基于深度学习的检测方法,由于网络结构的复杂性,计算量会异常庞大,同样会使得运行速度十分缓慢。
技术实现要素:
3.本发明的一个目的是解决至少上述问题,并提供至少后面将说明的优点。
4.本发明还有一个目的是提供一种基于机器学习的sql注入攻击检测方法,其以训练好的模型为主,白名单为辅,对流入的新数据进行预测,能够有效且快速检测出sql注入攻击,防御恶意攻击,保护系统安全。
5.为了实现根据本发明的这些目的和其它优点,提供了一种基于机器学习的sql注入攻击检测方法,其包括以下步骤:
6.步骤一,获取足量标注数据和对原始请求数据的清洗及预处理;
7.步骤二,特征提取,分别针对请求数据的不同部分进行特征提取,根据经验构造特征向量;其中,提取的特征包括:频繁项集的权重;所述频繁项通过fp
‑
growth算法挖掘sql注入数据中的频繁项集所得,获取关联最紧密的前m个组合,每个组合的长度为2,根据支持度分配不同的权重,sql注入常出现的频繁项集权重较高,出现次数较少的权重较低,在每条样本数据中进行匹配,再进行加权求和;
8.步骤三,将步骤二获得的特征向量进行拼接,得到整条数据的特征向量;公式如下:
[0009][0010]
式中,t表示最终的特征向量,n表示构造的特征个数,wi表示第i个组合的权重,m表示挖掘的组合个数。
[0011]
步骤四,采用5折交叉验证和网格搜索方法,输出svm模型的惩罚因子c和核函数类型的最佳组合,并以得到的c和核函数类型来训练svm模型,建立svm检测模型;将步骤三获
得的整条数据的特征向量输入svm检测模型到中进行训练;
[0012]
步骤五,将待测请求数据的特征向量输入到训练好的svm检测模型进行预测,判断待测请求数据是否为sql注入攻击数据。
[0013]
优选的是,所述步骤五还包括:制作白名单:基于业务类型,将含有sql注入数据特征的该业务的正常请求数据制成白名单数据库。
[0014]
优选的是,所述步骤五还包括:在svm检测模型进行预测后,还需与所述白名单数据库进行匹配,过滤正常的请求数据。
[0015]
优选的是,所述步骤二中,所述步骤二中的请求数据的不同部分包括:url、request_body、request_method以及user
‑
agent。
[0016]
优选的是,所述步骤二中的针对请求数据的不同部分进行特征提取具体为:
[0017]
步骤2.1user
‑
agent提取特征:特殊字符个数、是否含有“.exe”、总长度、熵值、频繁项集、sql注入高危词个数和普危词个数,其中sql注入危险词通过经验总结和聚类方法获得;
[0018]
步骤2.2对url提取特征:特殊字符个数、是否含有“.exe”、总长度、熵值、频繁项集、sql注入高危词个数、普危词个数、路径深度、“.”的个数、参数个数、最长参数长度、数字占比、字母占比、连续数字的最大长度、是否存在ip和最长参数占比;
[0019]
步骤2.3对request_body提取特征:特殊字符个数、是否含有“.exe”、总长度、熵值、频繁项集、sql注入高危词个数和普危词个数;
[0020]
步骤2.4对request_method通过字典映射进行数值转换;
[0021]
优选的是,所述步骤一中,获取足量标注数据具体为:高质量的标注样本数据是机器学习的基石,但是人工标注所有的数据集需要相当大的时间和人力成本,我们可以获得业务的大量请求数据,但是这些数据并未进行正常和sql注入的分类,本发明提出人工标注小部分特征明显的数据集,再通过余弦相似度计算,取得所有相似度超过90%的数据,将其统一标注,以此来降低标注数据的成本。
[0022]
优选的是,所述步骤一中,原始请求数据清洗及预处理具体为:将收集的原始请求数据进行常规去重操作,再进行解码、缺失值填充和分词的预处理操作。
[0023]
优选的是,所述步骤四中,svm模型的惩罚因子c=10,核函数类型为线性核函数。
[0024]
优选的是,所述步骤三中还包括:为缩小特征值域范围,使用standardscaler将特征向量的各个值进行缩放。
[0025]
本发明至少包括以下有益效果:本发明所述基于机器学习的sql注入攻击检测方法不仅针对请求数据url部分,还针对其request_body、method和user
‑
agent进行特征提取,大大提高的数据的准确性。在特征提取时,引入频繁项集作为特征向量,有效提高sql注入攻击检测的识别度。本发明还针对特殊业务数据的识别可能会出现偏差,所以引入白名单作为辅助,对模型预测为sql注入的数据再做一次过滤;本发明可以有效且快速检测出sql注入攻击,防御恶意攻击,保护系统安全。
[0026]
本发明的其它优点、目标和特征将部分通过下面的说明体现,部分还将通过对本发明的研究和实践而为本领域的技术人员所理解。
附图说明
[0027]
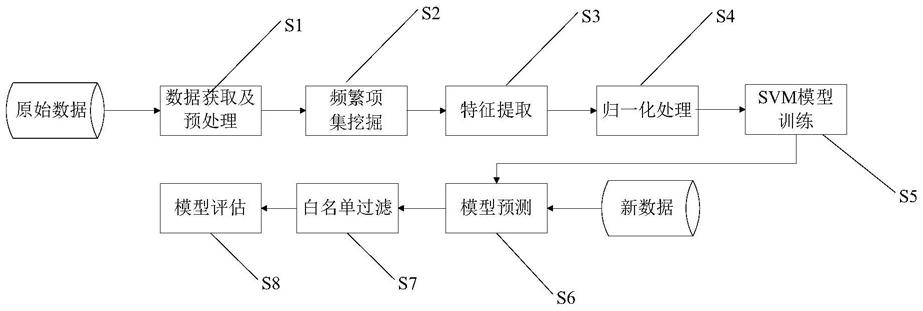
图1为本发明其中一个实施例所述基于机器学习的sql注入攻击检测方法的流程示意图。
具体实施方式
[0028]
下面结合附图对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。
[0029]
应当理解,本文所使用的诸如“具有”、“包含”以及“包括”术语并不排除一个或多个其它元件或其组合的存在或添加。
[0030]
本发明提供一种基于机器学习的sql注入攻击检测方法,其包括以下步骤:
[0031]
步骤一,获取足量标注数据和对原始请求数据的清洗及预处理;
[0032]
步骤二,特征提取,分别针对请求数据的不同部分进行特征提取,根据经验构造特征向量;其中,提取的特征包括:提取频繁项集;所述频繁项集通过fp
‑
growth算法挖掘sql注入数据中的频繁项集所得,获取关联最紧密的前m个组合,每个组合的长度为2,根据支持度分配不同的权重,sql注入常出现的频繁项集权重较高,出现次数较少的权重较低,在每条样本数据中进行匹配,再进行加权求和;计算公式如下:
[0033][0034]
式中,t表示最终的特征向量,n表示构造的特征个数,w
i
表示第i个组合的权重,m表示挖掘的组合个数。
[0035]
步骤三,将步骤二获得的特征向量进行拼接,得到整条数据的特征向量;
[0036]
步骤四,采用5折交叉验证和网格搜索方法,输出svm模型的惩罚因子c和核函数类型的最佳组合,并以得到的c和核函数类型来训练svm模型,建立svm检测模型;将步骤三获得的整条数据的特征向量输入svm检测模型到中进行训练;
[0037]
步骤五,将待测请求数据的特征向量输入到训练好的svm检测模型进行预测,判断待测请求数据是否为sql注入攻击数据。
[0038]
实施例
[0039]
如图1所示,本发明提供一种基于机器学习的sql注入攻击检测方法,其包括以下步骤:
[0040]
步骤s1,获取足量标注数据具体为:高质量的标注样本数据是机器学习的基石,但是人工标注所有的数据集需要相当大的时间和人力成本,我们可以获得业务的大量请求数据,但是这些数据并未进行正常和sql注入的分类,本发明提出人工标注小部分特征明显的数据集,再通过余弦相似度计算,取得所有相似度超过90%的数据,将其统一标注,以此来降低标注数据的成本。将原始请求数据进行清洗及预处理;为减小数据集的噪音,需对原始数据进行清洗,将收集的原始数据进行常规去重操作,再进行解码、缺失值填充和分词的预处理操作,其中,分词时引入自定义词典,用于切分非常见词;数据源的好坏会直接影响模型的效果,所以数据处理的每一步都极其重要。
[0041]
步骤s2,挖掘频繁项集;本发明将fp
‑
growth算法挖掘出的sql注入数据中的频繁项集,即常一起出现的词组或字符串组,作为一个特征加入到特征向量中,具体做法为:获
取关联最紧密的前m个组合,每个组合的长度为2,根据支持度分配不同的权重,sql注入常出现的频繁项集权重较高,出现次数较少的权重较低,在每条样本数据中进行匹配,再进行加权求和,将计算结果拼接到特征向量;计算公式如下:
[0042][0043]
式中,t表示最终的特征向量,n表示构造的特征个数,w
i
表示第i个组合的权重,m表示挖掘的组合个数。
[0044]
特征工程是传统机器学习中至关重要的部分,因为是依靠经验总结特征来构造特征向量,若特征选取的不好,会很难训练出适用的模型。本发明引入频繁项集的权重作为特征,加入特征向量中,用于模型的训练和预测,大大提高了svm模型的准确率。
[0045]
步骤s3,分别针对请求数据的不同部分提取特征;本发明针对请求数据的不同部分分别进行特征提取,根据经验构造特征向量,具体特征如下:
[0046]
1.对user
‑
agent提取特征:特殊字符个数、是否含有“.exe”、总长度、熵值、频繁项集、sql注入高危词个数和普危词个数,其中sql注入危险词通过经验总结和聚类方法获得。
[0047]
2.对url提取特征:特殊字符个数、是否含有“.exe”、总长度、熵值、频繁项集、sql注入高危词个数、普危词个数、路径深度、“.”的个数、参数个数、最长参数长度、数字占比、字母占比、连续数字的最大长度、是否存在ip和最长参数占比。
[0048]
3.对request_body提取特征:特殊字符个数、是否含有“.exe”、总长度、熵值、频繁项集、sql注入高危词个数和普危词个数。
[0049]
4.对request_method通过字典映射进行数值转换。目前,已有的针对sql注入的机器学习检测方法,往往只针对url进行检测,这对于整个请求来说只是一小部分,而请求中可能存在sql注入的地方非常多,所以,只针对url进行检测,是不准确的,而本发明除了url部分,还针对request_body、method和user
‑
agent进行检测。
[0050]
步骤s4,对特征向量进行归一化处理;将请求数据的各个部分提取获得的向量进行拼接,得到整条数据的特征向量,为缩小特征值域范围,例如使用standardscaler将向量的各个值进行缩放。
[0051]
步骤s5,将经过步骤s4处理后的特征向量输入到svm模型中进行训练,调整模型超参数,达到最优结果;构建获得svm检测模型。本发明的目的是判断数据是否存在sql注入数据,所以本发明训练过程中,采用5折交叉验证和网格搜索方法,确定最优参数。最终确定的参数为c=10,kernel='linear',构建获得svm检测模型。其中,c为惩罚参数,c值越大,对误差的容忍度越小,易出现过拟合,c越小,对误差的容忍度越高,易出现欠拟合;kernel为核函数类型,选取的'linear'为线性核函数。
[0052]
步骤s6,模型测试;将本发明构建的svm检测模型应用于具体的业务环境中,对流入的数据进行检测,每天随机选取部分检测结果以表格或其他格式进行汇总展示。
[0053]
步骤s7,制作白名单;基于业务类型,将含有sql注入数据特征的该业务的正常请求数据制成白名单数据库。由于个别业务的特殊性,有可能某种业务下的正常请求数据含有sql注入数据具有的特征,而被svm检测模型误认为sql注入数据,因此,加入白名单做辅助。白名单中包含某个业务数据的域名,url和request_body的正则表达式,将模型预测为sql注入的数据在白名单中进行匹配,若以上三个字段都符合,即认为该类数据存在于白名
单中,将预测结果修正为正常。
[0054]
步骤s8,根据模型评价指标对模型进行整体评估。将检测结果进行统计,以模型的标准评价指标对模型做出评估。经过多次试验,本发明所述svm检测模型的交叉验证准确率可达到97%左右,损失值在0.02左右,召回率可达到95%左右,精确率可达到在实际环境测试过程中,模型的准确率可达到90%左右,召回率可达91%左右。
[0055]
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1