基于知识库的政务数据质量评价方法与流程
1.本发明涉及一种基于知识库的政务数据质量评价方法。
背景技术:
2.数据质量是政务大数据的重中之重,事关提升城市治理能力的最终成效。科学的数据质量评价体系不但能够提升政务大数据的可用性,而且还能为有效分析数据、反哺数据提供便利。为了能够让政务大数据解决更多业务问题,在理想情况下数据维度越多越好,数据准确性越高越好。
3.但是,现有的数据质量评价方法没有考虑数据成熟度因素,导致数据质量评价效果差,准确性低。
技术实现要素:
4.本发明的目的是提供一种基于知识库的政务数据质量评价方法,该方法能够给出全局性数据维度扩充及数据值改进建议,驱动政府部门完善并修正相关数据目录、数据项和数据值;同时,还可以满足单一政府部门业务的需要以及数据共享、互操作与业务发展的进一步要求。
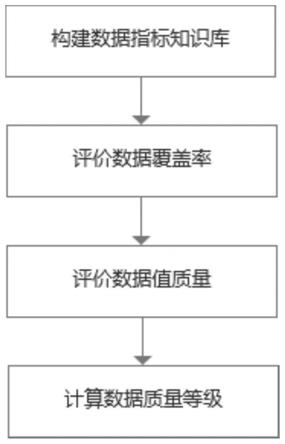
5.为了实现上述目的,本发明提供了一种基于知识库的政务数据质量评价方法,该基于知识库的政务数据质量评价方法包括:
6.步骤1、选取一体化政务服务能力较高的城市的政务服务网站作为数据指标知识库形成的来源,构建数据指标知识库;
7.步骤2、评价数据覆盖率;
8.步骤3、评价数据值质量;
9.步骤4、计算数据质量等级。
10.优选地,步骤1中包括:
11.步骤1.1、构建来源部门:首先,对中文roberta预训练语言模型采用政务领域语料库进行无监督训练,获取拥有政务领域知识的roberta预训练语言模型;其次,使用政务领域知识的roberta预训练语言模型对政务服务清单文本和权力清单文本进行语义提取,得到政务服务清单文本词向量和权力清单文本词向量;最后,计算服务清单文本词向量和权力清单文本词向量的余弦相似度,选取相似度最高的文本进行匹配,形成来源部门;
12.步骤1.2、构建数据目录:首先,获取城市政务服务网中个人办事和法人办事的网页数据,使用xpath和beautifulsoup以及json数据解析方法对网页进行数据清洗和相关数据的数据提取,提取出对应的自然人事件和法人事件;将提取的数据进行规整,通过pymysql技术连接到本地mysql数据库,将规整后的数据存入数据库中;运用词向量计算文本相似度,设定指定阈值,对相似自然人事件和法人事件进行融合,形成数据目录;
13.步骤1.3、构建数据项:首先,获取办事结果表格、证书图片等,对表格数据直接处理得到目录对应的数据项;对证书图片应用ocr算法进行文本提取,获取具体文本后再进行
文本处理获取数据项,在完成数据目录、数据项和来源部门构建后,数据指标知识库构建完成,并以此对政务数据按数据目录、数据项和来源部门进行匹配和识别;其中,基于词向量计算相似度时,若相似度超过指定阈值,则认为数据目录或数据项或来源部门匹配成功。
14.优选地,步骤1.3包括:
15.步骤1.3.1、使用卷积神经网络作为特征提取网络,提取事项申请材料图片中信息生成特征图;
16.步骤1.3.2、使用文本检测模型处理特征图定位到文字框;
17.步骤1.3.3、使用crnn+ctc、cnn+rnn+attention或cnn+seq2seq+attention模型实现对文字框中的文字内容识别;
18.步骤1.3.4、对文字内容进行数据清洗,并过滤掉与业务事项相关性弱的数据项,保留核心数据项;
19.步骤1.3.5、将数据项按照数据目标进行组合,形成数据项标准。
20.优选地,在步骤2中,采用word2vec模型将词向量化,比较两个词的相似度,设置相似度阈值,规定大于阈值的两词具有一致的语义;其中,覆盖率评价公式如下所示:
21.数据目录覆盖率=匹配成功的数据目录
÷
数据指标知识库中数据目录的数量
×
100%;
22.数据项覆盖率=匹配成功的数据项
÷
数据指标知识库中数据目录中数据项的数量
×
100%;
23.部门覆盖率=匹配成功的部门
÷
数据指标知识库中数据目录中部门的数量
×
100%;
24.覆盖率得分=数据目录覆盖率
×
数据项覆盖率
×
部门覆盖率
×
100。
25.优选地,步骤3中包括:
26.步骤3.1、定义评价指标,包括:
27.规范性是待评价数据集中各数据项的名称、描述、类型值域等内容必须符合元数据定义的度量;其中,若数据目录和数据项具有可理解的中文注释,则认为具有规范性;
28.完整性是待评价的数据集中数据元素应被赋值的程度;其中,按配置表来检测表数据,首先根据表名查询数据总量并记录,第二天再查询同一个数据库,检测数据总量并与昨日数据量进行相减,若差值小于指定阈值,则认为数据完整;否则,认为该表数据不完整;
29.准确性是待评价数据元素与期望的数据元素之间的真实程度,即待评价数据元素是否错误或异常;准确性指数据合规性、数据重复率和数据唯一性;数据合规性检查待评价数据的数据格式,包括数据类型、数值范围、数据长度、精度等是否满足预期要求;数据重复率评价数据集中数据元素意外重复的度量;数据唯一性指特定数据项、数据元素唯一性的度量;其中,
30.待评价数据集中各数据项须对应指定数据项类型,各数据项必须在正确值域内取值,汇总各数据项的数据精度不得过长,必须符合给定配置表规则的长度和数据类型;
31.根据配置表规则,选中指定数据目录、指定数据项进行重复率检测,数据集中不出现两行所有属性都一样的数据,即认为是数据集非重复;并且,根据配置表规则,一个表中指定数据项中的每个数据必须唯一;
32.一致性是用于描述数据与数据之间在某一特定条件下满足某一相同的条件或状
态,包括相同数据一致性和关联数据一致性;其中,
33.根据指定配置表规则,找出同一部门同一类业务数据之间的一致性,即同部门数据表之间相同或关联数据项必须一致;同时,单个数据目录中一致性约束规则检查关联数据的一致性;
34.时效性是按照业务规则,数据在时间变化中的正确程度,包括基于时间段的正确性、基于时间点的及时性和时序性;其中,
35.基于时间戳的记录数、频率分布或延迟时间符合业务需求的程度,根据配置表规则,查询指定业务表中指定业务时间数据项的最大值,计算该值与计算时间的差值,将差值与阈值进行比较,若小于阈值,则认为该表数据及时;
36.基于时间段的正确性即基于日期范围的记录数或频率分布符合业务需求的程度,根据配置表规则,查询指定业务表中指定业务时间数据项的取值范围,然后计算该取值范围在指定阈值中的符合程度;
37.可访问性是数据能被访问的程度,即在获取数据记录时是否如期返回所有数据项值,获取数据日志并根据日志进行打分;
38.步骤3.2、计算分值,其中,
39.各指标数据质量评价分数的计算公式为:
[0040][0041]
其中,ri为第i个指标的评价结果,c为指标i对应的评价规则总数,wj为指标i各规则的权重;n
ij
为数据集上符合第i个指标的第j条规则的数据记录数或数据元素数;m
ij
为总数据记录数或数据元素数;
[0042]
数据值数据质量综合评价的得分计算公式为:
[0043][0044]ri
为第i个指标的评价结果;n为指标的总数量;
[0045]
假设某个政府部门有n张数据表,每张数据表数据质量得分为gi,则该部门数据值质量平均得分为:
[0046][0047]
优选地,步骤4中计算数据质量等级时,数据质量总分=覆盖率得分+数据值得分,其中,若数据质量总分∈[90,100],则数据质量非常好;若数据质量总分∈[80,90),则数据质量较好;若数据质量总分∈[70,80),则数据质量中等;若数据质量总分∈[60,70),则数据质量合格;若数据质量总分∈[0,60),则数据质量差。
[0048]
根据上述技术方案,本发明采用自然语言处理技术构建数据指标知识库、基于覆盖率的数据成熟度评价和基于评价指标的数据值质量评价,通过构建知识库从数据目录、数据项和数据值这三个不同层次来对政务大数据进行质量评价。
[0049]
本发明的其他特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
[0050]
附图是用来提供对本发明的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本发明,但并不构成对本发明的限制。在附图中:
[0051]
图1是本发明提供的基于知识库的政务数据质量评价方法的流程图;
[0052]
图2是本发明提供的基于知识库的政务数据质量评价方法中基于词向量的相似性检测的流程图。
具体实施方式
[0053]
以下结合附图对本发明的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明,并不用于限制本发明。
[0054]
参见图1,本发明提供一种基于知识库的政务数据质量评价方法,该基于知识库的政务数据质量评价方法包括:
[0055]
步骤1、选取一体化政务服务能力较高的城市的政务服务网站作为数据指标知识库形成的来源,构建数据指标知识库;
[0056]
步骤2、评价数据覆盖率;
[0057]
步骤3、评价数据值质量;
[0058]
步骤4、计算数据质量等级。
[0059]
具体的,步骤1中包括:
[0060]
步骤1.1、构建来源部门:首先,对中文roberta预训练语言模型采用政务领域语料库进行无监督训练,获取拥有政务领域知识的roberta预训练语言模型;其次,使用政务领域知识的roberta预训练语言模型对政务服务清单文本和权力清单文本进行语义提取,得到政务服务清单文本词向量和权力清单文本词向量;最后,计算服务清单文本词向量和权力清单文本词向量的余弦相似度,选取相似度最高的文本进行匹配,形成来源部门;
[0061]
步骤1.2、构建数据目录:首先,获取城市政务服务网中个人办事和法人办事的网页数据,使用xpath和beautifulsoup以及json数据解析方法对网页进行数据清洗和相关数据的数据提取,提取出对应的自然人事件和法人事件;将提取的数据进行规整,通过pymysql技术连接到本地mysql数据库,将规整后的数据存入数据库中;运用词向量计算文本相似度,设定指定阈值,对相似自然人事件和法人事件进行融合,形成数据目录;
[0062]
步骤1.3、构建数据项:首先,获取办事结果表格、证书图片等,对表格数据直接处理得到目录对应的数据项;对证书图片应用ocr算法进行文本提取,获取具体文本后再进行文本处理获取数据项,在完成数据目录、数据项和来源部门构建后,数据指标知识库构建完成,并以此对政务数据按数据目录、数据项和来源部门进行匹配和识别;其中,基于词向量计算相似度时,若相似度超过指定阈值,则认为数据目录或数据项或来源部门匹配成功。
[0063]
进一步的,步骤1.3包括:
[0064]
步骤1.3.1、使用卷积神经网络(vgg、resnet、densenet等)作为特征提取网络,提取事项申请材料图片中信息生成特征图;
[0065]
步骤1.3.2、使用文本检测模型(faster-rcnn、rrpn、ctpn、textboxes等)处理特征
图定位到文字框;
[0066]
步骤1.3.3、使用crnn+ctc、cnn+rnn+attention或cnn+seq2seq+attention模型实现对文字框中的文字内容识别;
[0067]
步骤1.3.4、对文字内容进行数据清洗,并过滤掉与业务事项相关性弱的数据项,保留核心数据项;
[0068]
步骤1.3.5、将数据项按照数据目标进行组合,形成数据项标准。
[0069]
对于数据目录、数据项和来源部门进行覆盖率评价,不但可以清楚地了解地市政务服务事项覆盖度,还有助于精确定位问题数据产生的源头部门,给出问题数据的所属分类及解决办法,以数据质量工单的方式反馈源头部门。在覆盖率评价时,政务数据目录、数据项和来源部门命名可能与数据指标知识库存在差异,为此需要判断名称之间的相似度。因而,在步骤2中,采用word2vec模型将词向量化,比较两个词的相似度,设置相似度阈值,规定大于阈值的两词具有一致的语义,如图2所示;其中,覆盖率评价公式如下所示:
[0070]
数据目录覆盖率=匹配成功的数据目录
÷
数据指标知识库中数据目录的数量
×
100%;
[0071]
数据项覆盖率=匹配成功的数据项
÷
数据指标知识库中数据目录中数据项的数量
×
100%;
[0072]
部门覆盖率=匹配成功的部门
÷
数据指标知识库中数据目录中部门的数量
×
100%;
[0073]
覆盖率得分=数据目录覆盖率
×
数据项覆盖率
×
部门覆盖率
×
100。
[0074]
步骤3中包括:
[0075]
步骤3.1、定义评价指标,包括:
[0076]
规范性是待评价数据集中各数据项的名称、描述、类型值域等内容必须符合元数据定义的度量;其中,若数据目录和数据项具有可理解的中文注释,则认为具有规范性;
[0077]
完整性是待评价的数据集中数据元素应被赋值的程度;其中,按配置表来检测表数据,首先根据表名查询数据总量并记录,第二天再查询同一个数据库,检测数据总量并与昨日数据量进行相减,若差值小于指定阈值,则认为数据完整;否则,认为该表数据不完整;
[0078]
准确性是待评价数据元素与期望的数据元素之间的真实程度,即待评价数据元素是否错误或异常;准确性指数据合规性、数据重复率和数据唯一性;数据合规性检查待评价数据的数据格式,包括数据类型、数值范围、数据长度、精度等是否满足预期要求;数据重复率评价数据集中数据元素意外重复的度量;数据唯一性指特定数据项、数据元素唯一性的度量;其中,
[0079]
待评价数据集中各数据项须对应指定数据项类型,如姓名必须varchar格式,日期数据项可以为date或varchar格式。各数据项必须在正确值域内取值,汇总各数据项的数据精度不得过长,必须符合给定配置表规则的长度和数据类型;
[0080]
根据配置表规则,选中指定数据目录、指定数据项进行重复率检测,数据集中不出现两行所有属性都一样的数据,即认为是数据集非重复;并且,根据配置表规则,一个表中指定数据项中的每个数据必须唯一;
[0081]
一致性是用于描述数据与数据之间在某一特定条件下满足某一相同的条件或状态,包括相同数据一致性和关联数据一致性;其中,
[0082]
根据指定配置表规则,找出同一部门同一类业务数据之间的一致性,即同部门数据表之间相同或关联数据项必须一致;同时,单个数据目录中一致性约束规则检查关联数据的一致性,如根据身份证数据项可以关联到年龄、籍贯、性别、出生日期等数据项。
[0083]
时效性是按照业务规则,数据在时间变化中的正确程度,包括基于时间段的正确性、基于时间点的及时性和时序性;其中,
[0084]
基于时间戳的记录数、频率分布或延迟时间符合业务需求的程度,根据配置表规则,查询指定业务表中指定业务时间数据项的最大值,计算该值与计算时间的差值,将差值与阈值进行比较,若小于阈值,则认为该表数据及时;
[0085]
基于时间段的正确性即基于日期范围的记录数或频率分布符合业务需求的程度,根据配置表规则,查询指定业务表中指定业务时间数据项的取值范围,然后计算该取值范围在指定阈值中的符合程度;
[0086]
可访问性是数据能被访问的程度,即在获取数据记录时是否如期返回所有数据项值,获取数据日志并根据日志进行打分;
[0087]
步骤3.2、计算分值,其中,由于数据值指标计算方式具有一致性,均为(数据质量要求的记录数/总数据记录数或总数据元素数),并且整个数据集的指标分数是所有指标得分的平均值。结合各指标对应的各规则的权重,得出各指标数据质量评价分数的计算公式为:
[0088][0089]
其中,ri为第i个指标的评价结果,c为指标i对应的评价规则总数,wj为指标i各规则的权重;n
ij
为数据集上符合第i个指标的第j条规则的数据记录数或数据元素数;m
ij
为总数据记录数或数据元素数;
[0090]
数据值数据质量综合评价的得分计算公式为:
[0091][0092]ri
为第i个指标的评价结果;n为指标的总数量;
[0093]
假设某个政府部门有n张数据表,每张数据表数据质量得分为gi,则该部门数据值质量平均得分为:
[0094][0095]
此外,步骤4中计算数据质量等级时,数据质量总分=覆盖率得分+数据值得分,其中,若数据质量总分∈[90,100],则数据质量非常好;若数据质量总分∈[80,90),则数据质量较好;若数据质量总分∈[70,80),则数据质量中等;若数据质量总分∈[60,70),则数据质量合格;若数据质量总分∈[0,60),则数据质量差。
[0096]
综上所述,通过本发明提供的方法可以摸清政府现有政务数据资源的总体情况,
通过分析政府部门机构数据质量状况及提升空间,给出全局性数据维度扩充及数据值改进建议。通过完成数据评价,加强数据质量与数据应用之间的联结,驱动政府部门完善并修正相关数据目录、数据项和数据值。本发明提出的数据质量评价方法不但能够满足单一政府部门业务的需要,还能够满足数据共享、互操作与业务发展的进一步要求。
[0097]
以上结合附图详细描述了本发明的优选实施方式,但是,本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种简单变型,这些简单变型均属于本发明的保护范围。
[0098]
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。
[0099]
此外,本发明的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明的思想,其同样应当视为本发明所公开的内容。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1