内容获取方法、装置、电子设备和存储介质与流程
本公开涉及数据处理,尤其涉及一种内容获取方法、装置、电子设备和存储介质。
背景技术:
1、目前,电子设备的使用越来越方便,可以阅读新闻、浏览页面和观看视频等,极大的丰富使用体验。以浏览页面为例,页面上通常仅包括文本信息,电子设备可以响应于用户的操作进行复制、剪切等方式获取文本,然后对上述文本进行处理(如翻译或语音合成等)。随着互联网技术的发展,页面中除了文字还包括图片或者音频,若用户还有复制、剪切、翻译、语音合成等的需求时,此时将无法对混合内容中图片进行处理,从而降低使用体验。
技术实现思路
1、本公开提供一种内容获取方法、装置、电子设备和存储介质,以解决相关技术的不足。
2、根据本公开实施例的第一方面,提供一种内容获取方法,应用于电子设备,所述方法包括:
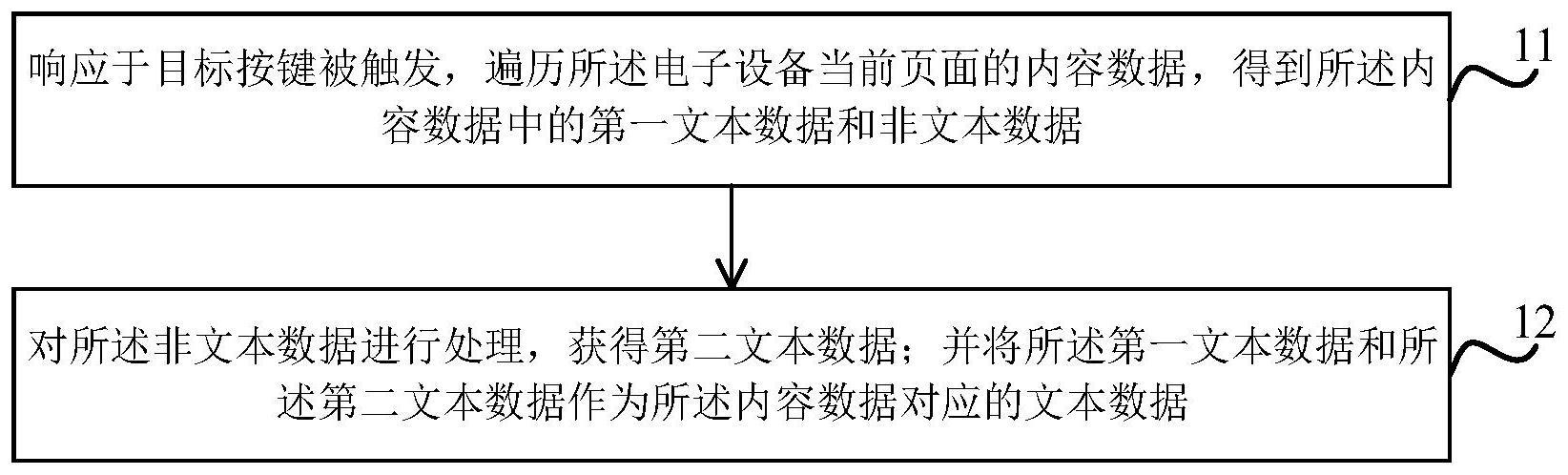
3、响应于目标按键被触发,遍历所述电子设备当前页面的内容数据,得到所述内容数据中的第一文本数据和非文本数据;所述非文本数据包括以下至少一种:图片数据、音频数据和视频数据;
4、对所述非文本数据进行处理,获得第二文本数据;并将所述第一文本数据和所述第二文本数据作为所述内容数据对应的文本数据。
5、可选地,所述目标按键表征选择内容数据的第一功能键,所述方法还包括:
6、按照所述第一文本数据和所述非文本数据在所述当前页面的位置对所述第一文本数据和所述第二文本数据进行排序,得到所述内容数据在所述第一功能键下对应的多媒体数据。
7、可选地,所述目标按键表征翻译内容数据的第二功能键,所述方法还包括:
8、按照所述第一文本数据中语句的顺序,依次将所述第一文本数据中的至少一条语句输入到目标翻译模型,得到所述目标翻译模型输出的第一目标语句;以及按照所述第二文本数据中语句的顺序,依次将所述第二文本数据中的至少一条语句输入到所述目标翻译模型,得到所述目标翻译模型输出的第二目标语句;
9、根据所述第一目标语句和所述第二目标语句生成目标文本数据,将所述目标文本数据作为所述内容数据在所述第二功能键下对应的多媒体数据。
10、可选地,根据所述第一目标语句和所述第二目标语句生成目标文本数据之后,所述方法还包括:
11、获取所述目标文本数据中拼接位置处的拼接语句,所述拼接语句由至少一条第一目标语句对应文本数据中的语句和至少一条第二目标语句对应文本数据中的语句构成;
12、将所述拼接语句输入到所述目标翻译模型,得到所述目标翻译模型输出的第三目标语句;
13、利用所述第三目标语句更新所述拼接语句,得到更新后的目标文本数据;将所述更新后的目标文本数据作为在所述第二功能键下所述内容数据对应的多媒体数据。
14、可选地,所述目标按键表征翻译内容数据的第二功能键,所述方法还包括:
15、获取所述第一文本数据和所述第二文本数据在当前页面的位置;所述第二文本数据的位置采用所述非文本数据的位置表示;
16、根据所述位置对所述第一文本数据和所述第二文本数据进行排序,获得初始文本数据;
17、按照所述初始文本数据中语句的顺序,依次将所述初始文本数据中的至少一条语句输入到目标翻译模型,得到所述目标翻译模型输出的目标语句;
18、按照所述目标语句的顺序生成目标文本数据,将所述目标文本数据作为在所述第二功能键下所述内容数据对应的多媒体数据。
19、可选地,所述目标按键表征翻译内容数据的第二功能键,所述方法还包括:
20、获取所述第一文本数据和所述第二文本数据的语言类型;
21、当所述第一文本数据和/或所述第二文本数据对应的语言类型与目标翻译模型对应的语言类型不同时,将语言类型不同的所述第一文本数据和/或所述第二文本数据中语句依次输入到目标翻译模型,得到所述目标翻译模型输出的目标语句;
22、根据所述第一文本数据和所述第二文本数据在当前页面的位置对所述目标语句进行排序以生成目标文本数据,将所述目标文本数据作为在所述第二功能键下所述内容数据对应的多媒体数据。
23、可选地,所述方法还包括获取目标翻译模型的步骤,具体包括:
24、获取电子设备的语言配置数据,所述语言配置数据包括以下至少一种:电子设备的系统语言类型和所述第二功能键所对应的指定语言类型;
25、调用所述语言配置数据中语言类型对应的预设的翻译模型,将所述预设的翻译模型作为目标翻译模型。
26、可选地,所述方法还包括:
27、生成新页面作为当前页面;
28、将所述多媒体数据在新页面显示。
29、可选地,所述目标按键表征合成音频内容的第三功能键,所述方法还包括:
30、将所述第一文本数据和所述第二文本数据输入到目标语音模型,获得所述目标语音模型输出的第一音频数据和第二音频数据;
31、按照所述第一文本数据和所述第二文本数据在当前页面的位置对所述第一音频数据和所述第二音频数据排序,获得目标音频数据;将所述目标音频数据作为所述目标按键表征功能对应的多媒体数据。
32、可选地,所述方法还包括:
33、按照所述第一文本数据和所述第二文本数据在当前页面的位置顺序播放所述第一音频数据和所述第二音频数据。
34、根据本公开实施例的第二方面,提供一种内容获取装置,应用于电子设备,所述装置包括:
35、内容数据获取模块,被配置为执行响应于目标按键被触发,遍历所述电子设备当前页面的内容数据,得到所述内容数据中的第一文本数据和非文本数据;所述非文本数据包括以下至少一种:图片数据、音频数据和视频数据;
36、文本数据获取模块,被配置为执行对所述非文本数据进行处理,获得第二文本数据;并将所述第一文本数据和所述第二文本数据作为所述内容数据对应的文本数据。
37、可选地,所述目标按键表征选择内容数据的第一功能键,所述装置还包括:
38、多媒体数据获取模块,被配置为执行按照所述第一文本数据和所述非文本数据在所述当前页面的位置对所述第一文本数据和所述第二文本数据进行排序,得到所述内容数据在所述第一功能键下对应的多媒体数据。
39、可选地,所述目标按键表征翻译内容数据的第二功能键,所述装置还包括:
40、文本数据翻译模块,被配置为执行按照所述第一文本数据中语句的顺序,依次将所述第一文本数据中的至少一条语句输入到目标翻译模型,得到所述目标翻译模型输出的第一目标语句;以及按照所述第二文本数据中语句的顺序,依次将所述第二文本数据中的至少一条语句输入到所述目标翻译模型,得到所述目标翻译模型输出的第二目标语句;
41、多媒体数据获取模块,被配置为执行根据所述第一目标语句和所述第二目标语句生成目标文本数据,将所述目标文本数据作为所述内容数据在所述第二功能键下对应的多媒体数据。
42、可选地,所述装置还包括:
43、拼接语句获取模块,被配置为执行获取所述目标文本数据中拼接位置处的拼接语句,所述拼接语句由至少一条第一目标语句对应文本数据中的语句和至少一条第二目标语句对应文本数据中的语句构成;
44、拼接语句翻译模块,被配置为执行将所述拼接语句输入到所述目标翻译模型,得到所述目标翻译模型输出的第三目标语句;
45、多媒体数据获取模块,被配置为执行利用所述第三目标语句更新所述拼接语句,得到更新后的目标文本数据;将所述更新后的目标文本数据作为在所述第二功能键下所述内容数据对应的多媒体数据。
46、可选地,所述目标按键表征翻译内容数据的第二功能键,所述装置还包括:
47、文本位置获取模块,被配置为执行获取所述第一文本数据和所述第二文本数据在当前页面的位置;所述第二文本数据的位置采用所述非文本数据的位置表示;
48、初始文本获取模块,被配置为执行根据所述位置对所述第一文本数据和所述第二文本数据进行排序,获得初始文本数据;
49、目标语句获取模块,被配置为执行按照所述初始文本数据中语句的顺序,依次将所述初始文本数据中的至少一条语句输入到目标翻译模型,得到所述目标翻译模型输出的目标语句;
50、多媒体数据获取模块,被配置为执行按照所述目标语句的顺序生成目标文本数据,将所述目标文本数据作为在所述第二功能键下所述内容数据对应的多媒体数据。
51、可选地,所述目标按键表征翻译内容数据的第二功能键,所述装置还包括:
52、语言类型获取模块,被配置为执行获取所述第一文本数据和所述第二文本数据的语言类型;
53、目标语句获取模块,被配置为执行当所述第一文本数据和/或所述第二文本数据对应的语言类型与目标翻译模型对应的语言类型不同时,将语言类型不同的所述第一文本数据和/或所述第二文本数据中语句依次输入到目标翻译模型,得到所述目标翻译模型输出的目标语句;
54、多媒体数据获取模块,被配置为执行根据所述第一文本数据和所述第二文本数据在当前页面的位置对所述目标语句进行排序以生成目标文本数据,将所述目标文本数据作为在所述第二功能键下所述内容数据对应的多媒体数据。
55、可选地,所述装置还包括翻译模型获取模块,被配置为执行获取目标翻译模型的步骤;所述翻译模型获取模块包括:
56、语言类型获取单元,被配置为执行获取电子设备的语言配置数据,所述语言配置数据包括以下至少一种:电子设备的系统语言类型和所述第二功能键所对应的指定语言类型;
57、翻译模型调用单元,被配置为执行调用所述语言配置数据中语言类型对应的预设的翻译模型,将所述预设的翻译模型作为目标翻译模型。
58、可选地,所述装置还包括:
59、新页面生成模块,被配置为执行生成新页面作为当前页面;
60、多媒体数据显示模块,被配置为执行将所述多媒体数据在新页面显示。
61、可选地,所述目标按键表征合成音频内容的第三功能键,所述装置还包括:
62、音频数据获取模块,被配置为执行将所述第一文本数据和所述第二文本数据输入到目标语音模型,获得所述目标语音模型输出的第一音频数据和第二音频数据;
63、多媒体数据获取模块,被配置为执行按照所述第一文本数据和所述第二文本数据在当前页面的位置对所述第一音频数据和所述第二音频数据排序,获得目标音频数据;将所述目标音频数据作为所述目标按键表征功能对应的多媒体数据。
64、可选地,所述装置还包括:
65、播放模块,被配置为执行按照所述第一文本数据和所述第二文本数据在当前页面的位置顺序播放所述第一音频数据和所述第二音频数据。
66、根据本公开实施例的第三方面,提供一种电子设备,包括:
67、处理器;
68、用于存储所述处理器可执行的计算机程序的存储器;
69、其中,所述处理器被配置为执行所述存储器中的计算机程序,以实现如上述的方法。
70、根据本公开实施例的第四方面,提供一种计算机可读存储介质,当所述存储介质中的可执行的计算机程序由处理器执行时,能够实现如上述的方法。
71、本公开的实施例提供的技术方案可以包括以下有益效果:
72、由上述实施例可知,本公开实施例提供的方案中可以响应于目标按键被触发,遍历所述电子设备当前页面的内容数据,得到所述内容数据中的第一文本数据和非文本数据;所述非文本数据包括以下至少一种:图片数据、音频数据和视频数据;对所述非文本数据进行处理,获得第二文本数据;并将所述第一文本数据和所述第二文本数据作为所述内容数据对应的文本数据。这样,本实施例中通过将非文本数据处理为文本数据,可以使当前页面的内容数据全部为文本数据,从而方便对文本数据进行后续处理,方便用户一键操作当前页面的内容数据,例如复制、剪切、翻译、语音合成等操作,有利于提升处理效率,从而提升使用体验。
73、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
- 还没有人留言评论。精彩留言会获得点赞!