一种涉案财物知识库的知识抽取方法
1.本发明属于知识库数据处理技术领域,特别是涉及一种涉案财物知识库的知识抽取方法。
背景技术:
2.知识库能够以结构化的形式描述客观世界中概念、实体及其关系,完成海量信息的有效组织、管理和理解。知识库系统在知识融合、智能问答、大数据决策等应用上的潜力受到了广泛的关注。知识库是一个以实体为节点的巨大网络,包括实体、实体属性以及实体间的关系。知识抽取是知识工程领域的重要任务之一,也是知识图谱构建的核心步骤.它的目的在于从无结构的自然语言文本中抽取出结构化的知识,得到文本内含的语义关系,进而用于知识库的构建、智能问答、推荐系统等。
3.目前常见的知识抽取方法主要分为三种:1)基于模板匹配的方法;2)基于监督学习的方法;3)基于半监督或无监督的方法。基于模板匹配的知识抽取方法构建简单,但准确度不高。随着机器学习和深度学习的发展,基于监督学习和半监督学习的知识抽取方法应用十分广泛,这些方法大多用于处理如人物关系之类的知识抽取问题,因为在这种场景下,关系类别明确、训练语料丰富。
4.涉案财物知识库旨在根据现有法律法规自动完成刑事案件中涉案财物处置的相关知识融合,为司法实践中公检法等执法司法单位的办案人员提供支持.核心的工作是从法律法规出发,抽取出业务单位实体与财物实体之间的处置关系。由于该领域的特殊性,对于涉案财物知识库构建过程中的知识抽取目前来说采用机器学习的方法由于语料库过小无法收敛,更适合基于模板匹配的知识抽取方法,然而必须解决基于模板的知识抽取方法准确度较低的问题。
技术实现要素:
5.为了解决上述问题,本发明提出了一种涉案财物知识库的知识抽取方法,以不同维度设计了三个知识抽取模板,从法律法规文本自动抽取五元组关系,并运用模糊逻辑计算各个模板抽取结果的置信度,使得三个模板间相互竞争,相对于传统基于模板匹配的知识抽取,进一步提高抽取结果的准确度。
6.为达到上述目的,本发明采用的技术方案是:一种涉案财物知识库的知识抽取方法,包括步骤:
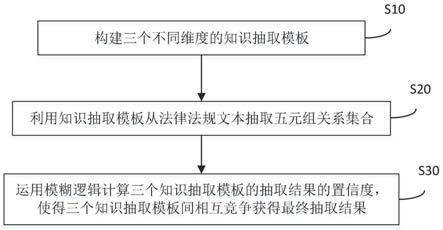
7.s10,构建三个不同维度的知识抽取模板;
8.s20,利用知识抽取模板从法律法规文本抽取五元组关系集合;
9.s30,运用模糊逻辑计算三个知识抽取模板的抽取结果的置信度,使得三个知识抽取模板间相互竞争获得最终抽取结果。
10.进一步的是,在步骤s10中,所述构建三个不同维度的知识抽取模板,包括步骤:
11.对每个待处理的法律文件进行预处理得到对应的有效法条集;
12.预定义三个不同维度的知识模板;
13.通过在有效法条集中随机选取待处理法条进行人工标定,构建开发集;针对开发集分别使用三个模板进行知识抽取,确定各模板初始置信度。
14.进一步的是,对每个待处理的法律文件进行预处理得到对应的有效法条集,包括步骤:
15.对输入的法律文件进行段落解析,得到段落集;
16.对于每一个段落,判断其是否是居中的标题,若是则忽略该段落;否则利用正则表达式提取法条序号及法条内容,得到带有序号标记的法条集;
17.根据涉案财物处置相关的特征词过滤掉与涉案财物处置无关的法条,得到最终的有效法条集。
18.进一步的是,预定义三个不同维度的知识模板包括模板ⅰ、模板ⅱ和模板ⅲ,
19.所述模板ⅰ以词为单元进行匹配,首先确定财物实体的位置,以此为中心检索其余元素;
20.所述模板ⅱ以词为单元进行匹配,首先确定业务单位实体的位置,以此为中心检索其余元素;
21.所述模板ⅲ以子句为单元进行匹配,认定业务单位实体与处置方式同属一个子句,财物实体与财物状态属性同属一个子句,处置条件属性单独属于一个子句。
22.进一步的是,通过在有效法条集中随机选取待处理法条进行人工标定,构建开发集;针对开发集分别使用三个模板进行知识抽取,确定各模板初始置信度,包括步骤:
23.定义对于给定法条,有测试结果s=[s1,s2…
s5],标定数据k=[k1,k2…
k5].若匹配度q》0.6,则认为抽取成功;
[0024][0025]
其中sim为文本相似度计算函数;
[0026]
计算开发集上模板i的正确率ci;
[0027][0028]
利用下式确定三个模板初始置信度wi;i=1,2,3:
[0029][0030]
进一步的是,运用模糊逻辑计算三个知识抽取模板的抽取结果的置信度,使得三个知识抽取模板间相互竞争获得最终抽取结果:在剩余的待处理法条集上,利用模糊逻辑对不同模板抽取出的五元组关系进行打分,进而实现多个模板间抽取结果的奖惩机制,综合胜出置信度较高的五元组关系。
[0031]
进一步的是,在步骤s30中,运用模糊逻辑计算三个知识抽取模板的抽取结果的置信度,使得三个知识抽取模板间相互竞争获得最终抽取结果,包括步骤:
[0032]
s31,数值化:五元组各元素补全和数值化处理;
[0033]
对于模板中的每一种元素筛选出中的非空元素,记作集合m;选出集合m中对应模板置信度最大的元素r;用r补全每个元素中的空值元素;若m为空集,则对应元素置为空;
[0034]
补全后进行数值化,对于每一个元素进行数值化处理;
[0035]
s32,在模糊化阶段,定义每个元素均隶属于p、a、g三个集合,其中,p集合和g集合采用梯形隶属函数,a集合采用三角形隶属函数;通过隶属函数模糊化后,得到五元组各元素隶属于pag三个集合的隶属度;
[0036]
s33,通过模糊化处理后,根据模糊规则和模糊逻辑的运算进行重新组合;五元组各元素均隶属于pag三个集合,五种元素不同隶属集合组合情况共有35种;对于每一种组合,通过规则指定最终的隶属集合以及相应的隶属度;
[0037]
s34,通过规则化处理后,得到了各种组合情况下对应的隶属集合以及隶属度,采用加权平均判决法借助去模糊化将其转化为最终评判五元组关系质量的数值;
[0038]
s35,模糊竞争:三个模板抽取的五元组关系通过上述模糊计算,得到评判五元组关系质量的数值,最高值对应的模板胜出,本次抽取结果以胜出模板为准,同时更新三个模板置信度。
[0039]
采用本技术方案的有益效果:
[0040]
本发明以不同维度设计了三个知识抽取模板,从法律法规文本自动抽取五元组关系,并运用模糊逻辑计算各个模板抽取结果的置信度,使得三个模板间相互竞争,相对于传统基于模板匹配的知识抽取,能够解决小规模语料库、高准确率要求的知识抽取问题。本发明提出预定义多个模板,通过模糊竞争决定相应模板的置信度,选用抽取结果,提高了抽取的准确率。本发明能够根据现有法律法条自动完成刑事案件中涉案财物处置的相关知识抽取,为司法实践中公检法等执法司法单位的办案人员提供支持。
附图说明
[0041]
图1为本发明的一种涉案财物知识库的知识抽取方法流程示意图;
[0042]
图2为本发明实施例中对每个待处理的法律文件进行预处理的流程示意图;
[0043]
图3为本发明实施例中隶属函数图;
[0044]
图4为本发明实施例中五元组各元素隶属示意图;
[0045]
图5为本发明实施例中五种元素不同隶属集合组合情况示意图。
具体实施方式
[0046]
为了使本发明的目的、技术方案和优点更加清楚,下面结合附图对本发明作进一步阐述。
[0047]
在本实施例中,参见图1所示,本发明提出了一种涉案财物知识库的知识抽取方法,包括步骤:
[0048]
s10,构建三个不同维度的知识抽取模板;
[0049]
s20,利用知识抽取模板从法律法规文本抽取五元组关系集合;
[0050]
s30,运用模糊逻辑计算三个知识抽取模板的抽取结果的置信度,使得三个知识抽取模板间相互竞争获得最终抽取结果。
[0051]
在步骤s10中,所述构建三个不同维度的知识抽取模板,包括步骤:
[0052]
s11,对每个待处理的法律文件进行预处理得到对应的有效法条集;,包括步骤:
[0053]
对输入的法律文件进行段落解析,得到段落集;
[0054]
对于每一个段落,判断其是否是居中的标题,若是则忽略该段落;否则利用正则表达式提取法条序号及法条内容,得到带有序号标记的法条集;
[0055]
根据涉案财物处置相关的特征词过滤掉与涉案财物处置无关的法条,得到最终的有效法条集。
[0056]
s12,预定义三个不同维度的知识模板;
[0057]
预定义三个不同维度的知识模板包括模板ⅰ、模板ⅱ和模板ⅲ,
[0058]
预定义了三个模板来分别进行知识抽取,每个模板的输入输出形式如下:
[0059]
1)输入:t、w1、w2、w3、w4、w5[0060]
2)输出:r
[0061]
其中,t为输入的法条文本,w1、w2、w3、w4、w5为实体关系词典,w1为财物实体词典、w2为业务单位实体词典、w3为触发词典、w4为处置方式词典、w5为财物状态词典。r为输出的五元组关系集合。五元组可为《业务单位实体,处置关系,处置条件,涉案财物实体,财物状态》。
[0062]
所述模板ⅰ以词为单元进行匹配,首先确定财物实体的位置,以此为中心检索其余元素;
[0063]
模板ⅰ具体匹配规则如下:
[0064]
模板ⅰ[0065][0066]
其中,相关函数如表1所示
[0067]
表1函数说明
[0068][0069]
所述模板ⅱ以词为单元进行匹配,首先确定业务单位实体的位置,以此为中心检索其余元素;
[0070]
模板ⅱ匹配规则如下:
[0071]
模板ⅱ[0072][0073]
其中相关函数说明见表1。
[0074]
所述模板ⅲ以子句为单元进行匹配,认定业务单位实体与处置方式同属一个子句,财物实体与财物状态属性同属一个子句,处置条件属性单独属于一个子句。
[0075]
模板ⅲ具体匹配规则如下:
[0076]
模板ⅲ[0077]
输入:t,w1,w2,w3,w4,w5[0078]
输出:r
[0079]
01)q
←
cut_c(t)
[0080]
02)select q in q that包含业务单位实体或处置方式
[0081]
03)q
←
q-{q}//匹配业务单位实体、处置方式
[0082]
04)w
←
cut_w(q)
[0083]
05)g
←
ptw(0,len(w),w,w2)
[0084]
06)m
←
ptw(0,len(w),w,w4)
[0085]
07)select q in q that包含财物实体或财物状态
[0086]
08)q
←
q-{q}//匹配财物实体、财物状态
[0087]
09)w
←
cut_w(q)
[0088]
10)p
←
ptw(0,len(w),w,w1)
[0089]
11)s
←
ptw(0,len(w),w,w5)
[0090]
12)select q in q that包含处置条件
[0091]
13)q
←
q-{q}//匹配处置条件
[0092]
14)w
←
cut_w(q)
[0093]
15)p
←
{gct(0,len(w),w)}
[0094]
16)r
←
p
×g×m×s×c[0095]
17)return r
[0096]
其中相关函数说明见表1。
[0097]
s13,通过在有效法条集中随机选取待处理法条进行人工标定,构建开发集;针对开发集分别使用三个模板进行知识抽取,确定各模板初始置信度。
[0098]
定义对于给定法条,有测试结果s=[s1,s2…
s5],标定数据k=[k1,k2…
k5].若匹配度q》0.6,则认为抽取成功;
[0099][0100]
其中sim为文本相似度计算函数;
[0101]
计算开发集上模板i的正确率ci;
[0102][0103]
利用下式确定三个模板初始置信度wi;i=1,2,3:
[0104][0105]
作为上述实施例的优化方案,运用模糊逻辑计算三个知识抽取模板的抽取结果的置信度,使得三个知识抽取模板间相互竞争获得最终抽取结果:在剩余的待处理法条集上,利用模糊逻辑对不同模板抽取出的五元组关系进行打分,进而实现多个模板间抽取结果的奖惩机制,综合胜出置信度较高的五元组关系。包括步骤:
[0106]
s31,数值化:鉴于模糊逻辑适用于数值计算,而五元组关系为文本数据,加之初始抽取的五元组关系存在空值干扰,因此,对五元组各元素补全和数值化处理;
[0107]
对于模板中的每一种元素筛选出中的非空元素,记作集合m;选出集合m中对应模
板置信度最大的元素r;用r补全每个元素中的空值元素;若m为空集,则对应元素置为空;
[0108]
补全后进行数值化,对于每一个元素进行数值化处理;
[0109]
初始抽取数据如下所示:
[0110][0111]
补全过程,如图2所示:
[0112]
对于模板i的{ai,bi,ci,di,ei}(i=1,2,3)中的每一种元素xi:
[0113]
a.筛选出xi中的非空元素,记作集合m;
[0114]
b.选出集合m中对应模板i置信度最大的元素r;
[0115]
c.用r补全x1、x2、x3中的空值元素;
[0116]
d.若m为空集,则x1、x2、x3置为“空”.
[0117]
补全后进行数值化,对于每一个元素xi,其数值化结果v计算公式如下:
[0118][0119]
通过数值化处理后,每个模板抽取的五元组关系均如以下格式:[abcde],其中,各元素均为0到1之间的浮点数。
[0120]
s32,在模糊化阶段,定义每个元素均隶属于p、a、g三个集合,其中,p集合和g集合采用梯形隶属函数,a集合采用三角形隶属函数。如图3所示:其中,横轴为输入的元素浮点数值,纵轴为对应的各集合的隶属度.p1、p2、a、d、g1、g2为各隶属度函数的参数.通过隶属函数模糊化后,得到五元组各元素隶属于pag三个集合的隶属度;如图4所示:
[0121]
s33,通过模糊化处理后,根据模糊规则和模糊逻辑的运算进行重新组合;五元组各元素均隶属于pag三个集合,五种元素不同隶属集合组合情况共有35种,如图5所示;对于每一种组合,通过规则指定最终的隶属集合以及相应的隶属度;
[0122]
为减少模糊规则数量,本发明简化规则如下:
[0123]
1)定义:
[0124][0125]
2)对于任意一种组合:
[0126][0127]
3)隶属集合:
[0128]
[0129]
4)隶属度:
[0130]
v(s)=min(ya,yb,yc,yd,ye)。
[0131]
s34,通过规则化处理后,得到了各种组合情况下对应的隶属集合以及隶属度,采用加权平均判决法借助去模糊化将其转化为最终评判五元组关系质量的数值;
[0132]
本文采用加权平均判决法:
[0133][0134]
其中,fsi为规则化阶段得到的隶属度,owi为对应隶属集合的权重系数.在本文中,取值如下:
[0135][0136]
其中,p2、a、g1为图2中隶属度函数参数.
[0137]
s35,模糊竞争:三个模板抽取的五元组关系通过上述模糊计算,得到评判五元组关系质量的数值,最高值对应的模板胜出,本次抽取结果以胜出模板为准,同时更新三个模板置信度。
[0138]
更新规则如下:
[0139]
1)胜出的模板:
[0140]
wi=wi+(1-wi)*0.001。
[0141]
2)其余模板:
[0142]
wj=w
j-wj*0.0005。
[0143]
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1