一种自适应权重的多视图判别方法
1.本发明涉及图像识别技术领域,更具体的,涉及一种自适应权重的多视图判别方法。
背景技术:
2.随着现在科技的不断进步,获取的原始图像数据通常是多样化且高维的,这将导致在处理多视图数据时面临着巨大的挑战。为了降低计算机内存的消耗以及对数据的计算量,首先会考虑运用主成分分析方法(pca)与线性判别分析(lda)算法两种最经典的优化算法。但由于上述算法对噪音较为敏感,为此he等人论文“locality preserving projections”提出了局部保留投影,通过保持数据的局部结构信息来提高算法对噪声的鲁棒性。
3.相比于单视图学习算法而言,多视图特征学习能够整合一个对象的多个角度来进行学习,因此,多视图算法能够提取原始数据中更多的判别信息,从而获得更好的性能。zhang等人基于希尔伯特-施密特独立性准则提出了fisher-hsic多视图度量学习(fisher-hsic multi-view metric learning,fish-mml)方法,其算法能保持数据样本在希尔伯特空间中的结构一致性,从而使得每个视图的联系更紧密,保留了更多了判别信息。随着深度学习的发展,许多研究人员基于深度学习技术的思想设计了一些多视图学习方法。例如,zhao等人提出了基于深度矩阵分解的多视图聚类(multi-view clustering via deep matrix factorization)方法,其方法为将每个视图进行了划分为多层系数矩阵,再逐层对系数矩阵进行非负分解,从而能准确的识别出每层系数矩阵中包含的不同属性。hu等人基于前馈神经网络的思想设计出了多视图线性判别分析网络(multi-view linear discriminantanalysis network,mvldan),该算法能将获得的深度特征投影到公共的空间中,并且无论样本是否在同一个视图中,都能够使得相同类别的样本尽可能地靠近,不同类的样本相互远离。
4.然而这些算法忽略了不同视图之间包含判别信息量的差异,无法为不同的视图赋予相应的权重,从而影响了多视图特征学习方法的性能,使得在判别中效果不理想。
技术实现要素:
5.本发明为了解决现有技术在图像存在多个不同的视图、高维与噪音污染严重的情况下判别效果不理想,提供了一种新颖的自适应权重的多视图判别方法。该算法不仅能够保留多视图数据在希尔伯特空间中的一致性结构,而且能同时保持每个视图的空间局部结构,最大限度的保留有效的判别投影信息。此外,利用低秩稀疏技术提高算法对噪音的鲁棒性,最后,通过考虑每个不同视图包含信息量的差异,对每个视图赋予了相对应的权重,以提高算法的性能。
6.为实现上述本发明目的,采用的技术方案如下:一种自适应权重的多视图判别方法,所述方法包括以下步骤:
7.s1:将多个视图数据x={x1,x2,
…
,xv}分成训练集tr={x
tr
,l
tr
}和测试集te={x
te
,l
te
},其中x
tr
是训练集,l
tr
表示训练集的标签,x
te
表示测试集,l
te
表示测试集的标签;
8.s2:构造训练集l
tr
的无向权重图g,并计算得到g的邻接矩阵s以及相应的拉普拉斯矩阵ls;
9.s3:基于希尔伯特-施密特独立性准则对多个视图数据进行一致性约束,并计算出约束矩阵t,构建结构一致性保留正则项;
10.s4:采用主成分分析方法初始化多个视图数据中的每个视图数据的投影矩阵p=[p1,p2,
…
,pv],并结合共识的低秩稀疏表征学习方法对p进行优化;
[0011]
s5:引入权重参数并根据多个视图数据中的每个视图数据xv包含的信息量赋予相应的权重;
[0012]
s6:基于s2-s5,构建基于一致性约束的自适应权重的多视图判别分析学习模型;
[0013]
s7:通过引入辅助变量j以及松弛低秩表示为核范数来对多视图判别分析学习模型进行学习,得到最优的多视图特征投影矩阵p
*
;
[0014]
s8:利用最优的多视图特征投影矩阵p
*
计算测试集x
te
的特征投影p
*
x
te
,以及训练集的特征投影p
*
x
tr
,将特征投影p
*
x
te
和p
*
x
tr
输入到knn分类器f中进行分类,得出分类准确率;
[0015]ct
=f(p
*
x
tr
,p
*
x
te
)
[0016]
式中:c
t
表示分类标签。
[0017]
在一个实施例中,步骤s1还包括:将多个视图数据x分成训练集和测试集,并对图像数据集进行归一化处理。
[0018]
在一个实施例中,在步骤s3中,关于相似矩阵s的表达式可表示为:
[0019][0020]
其中x
v,i
∈rn×1表示第v视图的第i列向量,pv=[p1,p2,
…
,pq]
t
∈rq×n表示第v视图特征投影矩阵。进一步拉普拉斯矩阵ls的表达式如下:
[0021]
ls=(i-s)*(i-s)
t
[0022]
其中:
[0023]
式中:s表示一个相似矩阵,s
ij
表示s矩阵中第i行第j列的数值,i表示单位矩阵,其对角元素满足
[0024]
在一个实施例中,步骤s4,是基于希尔伯特-施密特独立性准则来获取多个视图数据中的互补信息,使得投影后的多个视图数据能够在希尔伯特空间上保持一致的空间结构。具体表达式如下所示:
[0025][0026]
其中zv和zu分别表示第v个与第u个视角的观测数据矩阵,kv和ku为格拉姆(gram)矩阵。为了使得格拉姆矩阵在特征空间中的均值为零,令h
ij
=δ
ij-1/m,其中δ
ii
=1(i=0,
1,
…
,m),其余为零。在这里关于kv的内积核函数可定义为kv=z
vtzv
=x
vt
p
vt
pvxv。则基于hsic使得空间结构一致的表达式为:
[0027][0028]
其中,pv和pu分别表示第v个与第u个视图的投影矩阵,xv和xu分别表示第v个与第u个视图的原始样本数据。
[0029]
在一个实施例中,所述基于共识的低秩稀疏表示技术的多视图判别分析学习模型,具体表达式如下:
[0030][0031][0032]
其中ev与iv分别表示第v个视图的噪音矩阵与单位矩阵,λ1与λ2分别表示超参数,||
·
||
*
表示为核范数,||
·
||1表示l1范数。
[0033]
在一个实施例中,步骤s6,通过对不同的视图数据xv引入权重参数wv来进行权衡并约束所有视图的权重和为1。综合上述,最终关于自适应权重的多视图判别性投影算法的目标函数可表示为:
[0034][0035][0036]
其中表示第v个视图的权重,r>1是对权重的加权。
[0037]
在一个实施例中,所述步骤s7,通过引入辅助变量j以及松弛低秩表示核范数对学习模型进行优化,得到优化后的学习模型如下所示:
[0038][0039][0040]
将多视图判别分析学习模型转化为增广拉格朗日函数得到公式:
[0041][0042]
则初始化矩阵z=j=y2=0,ev=y
v,1
=0,然后对目标模型进行迭代求解,具体步骤如下:
[0043]
固定投影矩阵变量p,使用公式
[0044][0045]
更新低秩矩阵z;
[0046]
通过公式
[0047][0048]
更新辅助变量j;
[0049]
根据公式
[0050][0051]
更新辅助变量ev;
[0052]
通过对上述变量不断优化得到最优的z
*
,固定系数矩阵z和误差矩阵ev,对投影矩阵p进行更新,则目标模型可表示为公式:
[0053][0054][0055]
其中kv=x
vt
p
vt
pvxv,ku=x
ut
p
ut
puxu,在这里h定义为h=i-1/meet,e∈rn×1表示全为1的列向量。则pv的最优解可以通过求解以下标准的特征函数来获取:
[0056][0057]
其中η表示特征值,变量t定义为变量b的定义为b=(x
v-x
vzk+1
)(x
v-x
vzk+1
)
t
,pv表示特征值η相对应的特征向量。最终获得的最优投影矩阵由非零特征值对应的特征向量pv组成。
[0058]
本发明的有益效果如下:
[0059]
1.本发明在样本存在多个视图的情况下,将低秩稀疏表征学习与空间结构保留相结合,保证了多视图数据在投影变换时能有效保留不同视图数据的一致性结构信息以及视图内部的局部结构信息,并通过结合低秩稀疏约束表征学习模型,算法具有很强的鲁棒性以及稳定性。
[0060]
2.本发明基于多度量学习方法,通过将数据的希尔伯特空间一致性结构学习与欧式空间局部结构学习相结合,保留了多视图数据中的不同视图的一致性结构信息以及每个视图中空间局部结构信息,有效提高了算法的准确性与普适性。
[0061]
3.本发明基于自适应权重学习方法,通过设置自适应的权重来对每个包含不同特征信息量的视图进行了相应的加权,提高了算法的准确性。
附图说明
[0062]
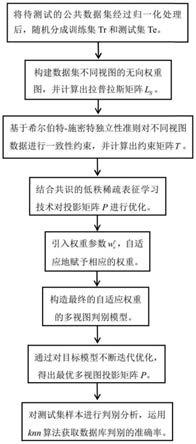
图1是本实施例所述方法的流程图。
具体实施方式
[0063]
下面结合附图和具体实施方式对本发明做详细描述。
[0064]
实施例1
[0065]
本实施例是基于windows 10系统上的matlab r2018a进行实验举例说明,使用的硬件平台cpu型号为amd ryzen 3 pro 1200 quad-core processor 3.1ghz,8gram。
[0066]
如图1所示,一种自适应权重的多视图判别方法,包括以下步骤:
[0067]
步骤1:将待测的公开数据集随机按比例选取部分的数据作为训练集tr={x
tr
,l
tr
},其余部分作为测试集te={x
te
,l
te
}。
[0068]
本实施例通过采用如表1所述的数据集进行举例说明;
[0069][0070]
表1
[0071]
为了减少噪音对主要特征影响,首先对多视图数据x=[x1,x2]经过归一化处理,然后随机分成训练集x
tr
和测试集x
te
;其中:数据集矩阵x
tr
,x
te
表示每一列代表一个样本,n表示样本维度,k1表示训练样本的数量,k2表示测试样本的数量;表示训练样本的标签矩阵;表示测试样本的标签矩阵。
[0072]
步骤2:通过k近邻学习构造训练样本矩阵l
tr
的无向权重图g={o,l},从而得到g的
邻接矩阵s,其中o表示样本点集,l表示样本边集。关于相似矩阵s的表达式可表示为:
[0073][0074]
其中x
v,i
∈rn×1表示第v视图的第i列向量,pv=[p1,p2,
…
,pq]
t
∈rq×n表示第v视图特征投影矩阵。进一步拉普拉斯矩阵ls的表达式如下:
[0075]
ls=(i-s)*(i-s)
t
ꢀꢀꢀꢀꢀꢀ
(2)
[0076]
其中:
[0077]
式中:s表示一个相似矩阵,s
ij
表示s矩阵中第i行第j列的数值;i表示单位矩阵,其对角元素满足
[0078]
步骤3:基于希尔伯特-施密特独立性准则来获取多视图数据中的互补信息,使得投影后的多视图数据能够在希尔伯特空间上保持一致的空间结构。具体表达式如下所示:
[0079][0080]
其中zv和zu分别表示第v个与第u个视角的观测数据矩阵,kv和ku为格拉姆(gram)矩阵。为了使得格拉姆矩阵在特征空间中的均值为零,令h
ij
=δ
ij-1/m,其中δ
ii
=1(i=0,1,
…
,m),其余为零。在这里关于kv的内积核函数可定义为kv=z
vtzv
=x
vt
p
vt
pvxv。则基于hsic使得空间结构一致的表达式为:
[0081][0082]
其中pv和pu分别表示第v个与第u个视图的投影矩阵,xv和xu分别表示第v个与第u个视图的原始样本数据;
[0083]
步骤4:采用主成分分析方法初始化投影矩阵p,对训练集数据进行特征提取得到p
vt
xv。为了减少噪音对算法影响以及增强算法的鲁棒性,进行共识的低秩稀疏表征技术学习,具体表达式如下:
[0084][0085]
其中ev与iv分别表示第v个视图的噪音矩阵与单位矩阵,λ1与λ2分别表示超参数,||
·
||
*
表示为核范数,||
·
||1表示l1范数。
[0086]
步骤5:通过对不同的视图数据xv引入权重参数wv来进行权衡并约束所有视图的权重和为1。
[0087]
综合上述,最终关于自适应权重的多视图判别性投影算法的目标函数可表示为:
[0088][0089]
其中表示第v个视图的权重,r>1是对权重的加权。
[0090]
步骤6:为了优化学习模型,引入辅助变量j以及松弛低秩表示核范数,得到优化的学习模型如下所示:
[0091][0092]
为了运用ladmap优化方法对式(7)进行优化,将上式(7)转化为增广拉格朗日函数得到公式(8):
[0093][0094]
初始化矩阵z=j=y2=0,ev=y
v,l
=0,运用ladmap优化方法分别对(8)式中的z,j,pv,ev,y
v1
,y2,θ不断进行优化,具体步骤如下所示:
[0095]
s601:初始化矩阵p,使用公式(9)更新低秩矩阵z;
[0096][0097]
s602:通过公式(10)更新辅助变量j:
[0098][0099]
s603:根据公式(11)更新辅助变量ev;
[0100][0101]
s604:用公式(12)拉格朗日乘子数y
v,1
,y2以及惩罚参数θ的更新表达式如下所示:
[0102][0103]
在这里ρ与θ
max
表示常数。
[0104]
s605:通过固定低秩矩阵z和辅助变量e,对投影矩阵p进行更新,则学习模型可表示为公式(10):
[0105][0106]
由于l
21
范数可进行凸优化,并通过给定约束p
t
p=i,因此,通过求解下列标准特征函数,可以很容易地得到(10)的最优解:
[0107][0108]
其中:d为对角矩阵,其中对角元素表示为pi表示投影矩阵p的第i行,ε表示非常小的正常数,λ表示特征值以及p表示相应的特征向量。直到迭代终止,得到最优投影矩阵p
*
。
[0109]
s606:通过固定变量z、pv、ev,根据公式(12)则关于变量wv的优化函数为:
[0110][0111]
进而得到关于公式(12)的拉格朗日表达式为
[0112][0113]
其中u为拉格朗日乘子数。设函数l(wv,u)相对于w变量u与wv的偏导数分别等于零,则可得表达式:
[0114][0115]
因此可以得到关于wv的表达式为:
[0116][0117]
其中
[0118]
步骤7:通过最优的投影矩阵p
*
对测试集x
te
进行特征投影为p
*t
x
te
,运用knn分类算法对经过特征投影后的测试集x
te
进行分类,得到分类标签为c
t
。
[0119]
本实施例最终通过对分类标签c
t
与初始标签l
te
进行校对,得出算法准确率。
[0120]
本实施例为了证明所述的一种自适应权重的多视图判别学习方法的效果,在bbcsport多视图文档数据集中,我们分别随机选取训练样本数量分别为原始数据的10%,20%,30%,40%。考虑到在不同比例下的数据样本量可能为非整数,因此会对训练数据量进行向下取整。与现有技术进行对比,得到实验结果如表2所示。
[0121][0122]
表2
[0123]
从表2中可以得出amdp算法在大部分情况下能够表现出最优的性能。特别地,在bbcsport数据库上本算法对比了2020年提出的最新算法mvcsd,该算法依然能表示出较好的判别性能。
[0124]
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1