一种基于金融知识图谱的智能对话方法及装置、电子设备
文档序号:28702917发布日期:2022-01-29 13:19阅读:166来源:国知局
导航: X技术> 最新专利>计算;推算;计数设备的制造及其应用技术
1.本发明涉及自然语言处理中的对话系统技术领域,特别是涉及一种基于金融知识图谱的智能对话方法及装置。
背景技术:
2.金融是历史记录数据最丰富且准确的领域之一,具有数据和信息密集、数据量庞大、数据种类繁多等特征。
3.在人工智能快速发展的时代大背景下,金融行业从业者也希望能够借助人工智能技术来构建金融领域的高效、智能信息处理系统,来帮助金融从业者更加快速高效地获取信息,从而能够提前把握行业动态,追踪行业发展趋势,在海量的数据信息中捕捉机会,提高自身竞争力。且随着投资活动增加,投研分析师对财经新闻资讯、企业基本信息、企业股东、企业高管、近年财报、股票数据等数据信息挖掘分析需求也随之增多。但从现有情况看,一方面,仅依靠互联网搜索引擎来获取金融投资相关信息,存在信息数量大、信息冗余、信息质量良莠不齐等问题,需要耗费大量人工才能获取其中的知识;另一方面,鉴于金融信息资源的多源异质、结构松散等特点,使其整合性和关联性差,难以提供规范的数据和实现丰富的语义表达。为此,如何对网络中金融投资相关信息资源进行梳理、,如何提升各种信息资源的利用率,为用户提供准确信息并减少相应的查询时间,减少人工和时间成本投入,便成为当前亟待解决的问题。
4.智能对话也称人机对话,是人工智能的一个重要的子领域,同时也是一项具有极大挑战性的技术,其旨在让机器具备与人类交流的能力。智能对话系统能识别人们由自然语言提出的问题,在知识库中查找相应答案,并返回给用户。与传统搜索引擎相比,对话系统增强了用户获取知识的便捷性,节省了信息筛选时间,也提高了信息质量。
5.传统的对话系统大多基于文档检索,使用关键词或模板匹配的方式来查询答案,而答案的数据来源基本都是非结构化的文本,在查询精度、问题推理、语义关联方面存在先天不足。而知识图谱的出现,为以上问题提供了解决方案。
6.知识图谱以语义网络的结构化方式描述客观世界中概念、实体、事件以及它们之间的关系,相对于传统的本体和语义网络而言,实体覆盖率更高,语义关系也更加复杂而全面。同时传统的基于规则或模板的方法早已经无法满足人类的需求,所以将深度学习应用到人机对话中,研究出能很好地理解人类意图、更好生成探索与满足用户需求的自然语言语句、匹配符合人类说话方式的对话系统,将对人工智能领域的研究产生深刻重大的理论实践意义。
技术实现要素:
7.基于此,本发明的目的在于,一种基于金融知识图谱的智能对话方法及装置,应用深度学习方法,构建一个基于金融知识图谱面向任务对话系统,可回答用户关于股票相关信息的咨询,为股票投资者提供股票相关资讯信息,帮助用户减少相应的网络查询时间,减
少人工和时间成本投入,帮助投研分析师快速挖掘信息,提升各种信息资源的利用率。
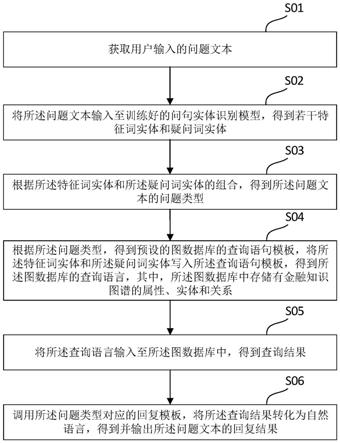
8.第一方面,本发明提供一种基于金融知识图谱的智能对话方法,包括以下步骤:
9.获取用户输入的问题文本;
10.将所述问题文本输入至训练好的问句实体识别模型,得到若干特征词实体和疑问词实体;
11.根据所述特征词实体和所述疑问词实体的组合,得到所述问题文本的问题类型;
12.根据所述问题类型,得到预设的图数据库的查询语句模板,将所述特征词实体和所述疑问词实体写入所述查询语句模板,得到所述图数据库的查询语言,其中,所述图数据库中存储有金融知识图谱的属性、实体和关系;
13.将所述查询语言输入至所述图数据库中,得到查询结果;
14.调用所述问题类型对应的回复模板,将所述查询结果转化为自然语言,得到并输出所述问题文本的回复结果。
15.进一步地,所述问句实体识别模型为bilstm和crf联合模型,将所述问题文本输入至训练好的问句实体识别模型,得到若干特征词实体和疑问词实体,包括:
16.通过所述问句实体识别模型的bilstm层对所述问题文本进行建模,输出所述问题文本中每个词对应的预测标签的分值;
17.通过所述问句实体识别模型的crf层为最后预测的标签添加约束,将所述预测标签分为合法标签序列和非法标签序列;
18.采用最大化正确标签序列的条件似然对数概率,取最大分值作为最终预测结果,输出所述问题文本中的若干关键词实体和疑问词实体。
19.进一步地,如果将所述问题文本输入至训练好的问句实体识别模型后,未得到所述若干特征词实体和疑问词实体,则还包括:
20.使用字符串匹配算法,以所述金融知识图谱的实体集作为关键词,提取出所述问题文本的关键词;
21.根据所述问题文本的关键词,得到所述特征词实体和所述疑问词实体。
22.进一步地,所述图数据库基于neo4j图形数据库创建。
23.进一步地,所述金融知识图谱的创建步骤包括:
24.模拟浏览器,向预设的金融服务器发送数据获取请求;
25.接收数据源返回的原始数据;
26.对所述原始数据进行去重、清洗预处理,使每支股票的数据能够符合知识图谱中实体或属性的语法格式;
27.将所述每支股票的数据以json格式保存至本地储存;
28.对存储的所述每支股票的数据进行分类,得到实体集合和关系集合,并构建金融知识图谱的实体集和关系集;
29.通过python的py2neo库,将所述实体集和所述关系集上传至云端的图数据库中,得到所述金融知识图谱。
30.进一步地,所述问句实体识别模型的训练过程包括:
31.根据所述金融知识图谱对应的问题类型,结合疑问词、特征词,生成针对每个问题类型的问句,对每个问句进行bio标注,得到所述问句实体识别模型的数据集;
32.将所述数据集划分为训练数据集、测试数据集和验证数据集;
33.将所述训练数据集输入至所述问句实体识别模型,以训练所述问句实体识别模型;
34.将所述验证数据集输入至所述问句实体识别模型,以对所述问句实体识别模型进行验证及参数优化;
35.对所述经过训练的问句实体识别模型进行评估,得到训练好的所述问句实体识别模型。
36.进一步地,对所述经过训练的问句实体识别模型进行评估,包括:
37.将所述测试数据集输入至所述问句实体识别模型,得到模型预测结果;
38.根据所述测试数据集中每个样本的真实结果和模型预测结果,将样本分为tp(样本与模型预测结果均为正类的个数)、fn(样本为正类,预测结果为负类的个数)、fp(样本为负类,预测结果为正类的个数)、tn(样本与模型预测结果均为负类的个数)四类;
39.通过如下公式计算所述问句实体识别模型的评价指标:
[0040][0041][0042][0043][0044]
其中,accuracy为准确率,precision为精确率,recall为召回率,f1为精确率和召回率的调和均值。
[0045]
进一步地,对每个问句进行bio标注,包括:
[0046]
将问句中的每个元素标注为“b-x”、“i-x”或者“o”;
[0047]
其中,“b-x”表示此元素所在的片段属于x类型并且此元素在此片段的开头,“i-x”表示此元素所在的片段属于x类型并且此元素在此片段的中间位置,“o”表示不属于任何类型。
[0048]
第二方面,本发明还提供一种基于金融知识图谱的智能对话装置,包括:
[0049]
问题获取模块,用于获取用户输入的问题文本;
[0050]
关键实体获取模块,用于将所述问题文本输入至训练好的问句实体识别模型,得到若干特征词实体和疑问词实体;
[0051]
问题类型判断模块,用于根据所述特征词实体和所述疑问词实体的组合,得到所述问题文本的问题类型;
[0052]
查询语言生成模块,用于根据所述问题的类型与所述若干关键实体,生成相应的查询语言;
[0053]
查询结果获取模块,用于根据所述问题类型,得到预设的图数据库的查询语句模板,将所述特征词实体和所述疑问词实体写入所述查询语句模板,得到所述图数据库的查询语言,其中,所述图数据库中存储有金融知识图谱的属性、实体和关系;
[0054]
回复结果输出模块,用于调用所述问题类型对应的回复模板,将所述查询结果转化为自然语言,得到并输出所述问题文本的回复结果。
[0055]
第三方面,本发明还提供一种电子设备,包括存储器,处理器以及储存在所述储存器中并可被所述处理器执行的计算机程序,所述处理器执行所述计算机程序时实现如本发明第一方面所述的基于金融知识图谱的智能对话方法的步骤。
[0056]
本发明将知识图谱技术运用于智慧金融对话系统,有助于从海量文本信息中抽取结构化的知识,将不同来源数据进行融合,形成富含语义关系的知识网络,可以为基于金融知识图谱面向任务对话系统提供高质量的信息。通过集成知识图谱,本发明开发的对话系统的数据精度、数据关联性、数据结构化水平将得到显著提升,增强问题语义和知识语义的理解和匹配。基于此,应用深度学习方法,构建一个基于金融知识图谱面向任务对话系统,在一定程度上能解决前述信息获取过程中所出现的问题,具有重要的实践意义与应用价值。
[0057]
相比现有技术,本发明可回答用户关于股票相关信息的咨询,为股票投资者提供股票相关资讯信息,帮助用户减少相应的网络查询时间,减少人工和时间成本投入,帮助投研分析师快速挖掘信息,提升各种信息资源的利用率。
[0058]
为了更好地理解和实施,下面结合附图详细说明本发明。
附图说明
[0059]
图1为本发明提供的一种基于金融知识图谱的智能对话方法的流程示意图;
[0060]
图2为本发明所使用的问句实体识别模型的结构示意图;
[0061]
图3为本发明所使用的金融知识图谱的构建流程示意图;
[0062]
图4为本发明提供的一种基于金融知识图谱的智能对话装置的结构示意图;
[0063]
图5为本发明提供的一种电子设备的结构示意图。
具体实施方式
[0064]
为使本技术的目的、技术方案和优点更加清楚,下面将结合附图对本技术实施例方式作进一步地详细描述。
[0065]
应当明确,所描述的实施例仅仅是本技术实施例一部分实施例,而不是全部的实施例。基于本技术实施例中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本技术实施例保护的范围。
[0066]
在本技术实施例使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本技术实施例。在本技术实施例和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本文中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。
[0067]
下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本技术相一致的所有实施方式。相反,它们仅是如所附权利要求书中所详述的、本技术的一些方面相一致的装置和方法的例子。在本技术的描述中,需要理解的是,术语“第一”、“第二”、“第三”等仅用于区别类似的对象,而不必用于描述特定的顺序或先后次序,也不能理解为指示或暗示相对重要性。对
于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本技术中的具体含义。
[0068]
此外,在本技术的描述中,除非另有说明,“多个”是指两个或两个以上。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。字符“/”一般表示前后关联对象是一种“或”的关系。
[0069]
针对背景技术中的问题,第一方面,本发明提供一种基于金融知识图谱的智能对话方法,如图1所示,该方法包括以下步骤:
[0070]
s01:获取用户输入的问题文本。
[0071]
在一个具体的实施例中,本方法依托搭载对话系统的人机交互设备、智能终端设备等实现,如智能手机、智能问答机器人等设备。对话系统的前端为用户操作界面,提供问题输入、结果输出等功能。用户输入问题的方式,既可以是传统的手动输入文本,也可以是直接语音输入,由智能设备的语音转文字系统将其转化为文本形式。
[0072]
s02:将所述问题文本输入至训练好的问句实体识别模型,得到若干特征词实体和疑问词实体。
[0073]
在一个具体的实施例中,所述问句实体识别模型为bilstm和crf联合模型。如图2所示,图2为本发明所使用的问句实体识别模型结构示意图,假设句子x输入序列为x=(x0,x1,.......,xn),句中的每个单词是一条包含词嵌入和字嵌入的词向量。bilstm-crf模型的输入是这些嵌入向量,输出是每个单词对应的预测标签。
[0074]
具体的,通过所述问句实体识别模型的bilstm层对所述问题文本进行建模,输出所述问题文本中每个词对应的预测标签的分值;通过所述问句实体识别模型的crf层为最后预测的标签添加约束,将所述预测标签分为合法标签序列和非法标签序列;采用最大化正确标签序列的条件似然对数概率,取最大分值作为最终预测结果,输出所述问题文本中的若干关键词实体和疑问词实体。
[0075]
s03:根据所述特征词实体和所述疑问词实体的组合,得到所述问题文本的问题类型。
[0076]
根据定义好的实体标签组合判断出问题属于哪一类(比如一类特征词的标签是股票名字“stockname”和疑问词实体为概念“concept”,则将此类问题的分类归为根据股票询问概念)。
[0077]
s04:根据所述问题类型,得到预设的图数据库的查询语句模板,将所述特征词实体和所述疑问词实体写入所述查询语句模板,得到所述图数据库的查询语言,其中,所述图数据库中存储有金融知识图谱的属性、实体和关系。
[0078]
在一个具体的实施例中,在完成问题分类后,需要将问题类别和特征词解析为能够对知识图谱的neo4j数据库进行查询的cypher语言。对于每一类问题,都有对应的cypher语言的查询模板,对于每一类具体的问题,只需将模板中的问句实体替换即可得到对应的查询cypher语言。
[0079]
s05:将所述查询语言输入至所述图数据库中,得到查询结果。
[0080]
在一个具体的实施例中,通过python的py2neo库实现在图数据库neo4j中执行cypher查询,得到查询的返回的实体。
[0081]
s06:调用所述问题类型对应的回复模板,将所述查询结果转化为自然语言,得到并输出所述问题文本的回复结果。
[0082]
在一个优选的实施例中,本发明提供的一种基于金融知识图谱的智能对话方法使用自主构建的金融知识图谱。
[0083]
知识图谱是一种基于图数据的结构语义网络,由节点和边组成。
[0084]
本发明通过使用neo4j图数据库来构建知识图谱,从而能够显示地表达出信息之间的表征关系,使问答过程中从问题推究到答案这一过程更加方便。
[0085]
如图3所示,图3为本发明所使用的的金融知识图谱的构建流程示意图,包括:
[0086]
s11:模拟浏览器,向预设的金融服务器发送数据获取请求。
[0087]
s12:接收数据源返回的原始数据。
[0088]
s13:对所述原始数据进行去重、清洗预处理,使每支股票的数据能够符合知识图谱中实体或属性的语法格式。
[0089]
s14:将所述每支股票的数据以json格式保存至本地储存。
[0090]
在一个具体的实施例中,本发明所使用的数据的主要来源是问财网中一部分a股的各类指标信息。其中总共包含了1999支股票的15种属性,包括概念、行业、技术形态等属性。
[0091]
通过使用python编程语言中的request库实现爬虫程序,模拟浏览器向问财网发送数据请求的信息,得到网站返回的数据。再将获取的数据进行检查,清洗,将冗余的数据删除,使每支股票的数据能够符合知识图谱中实体或属性的语法格式,并将每支股票的数据以json格式存储在本地。
[0092]
s15:对存储的所述每支股票的数据进行分类,得到实体集合和关系集合,并构建金融知识图谱的实体集和关系集。
[0093]
知识图谱主要由实体和实体之间的关系构成,因此需将获取的数据分类出实体和关系的集合。对于保存的json类型的数据,实体的类型有:
‘
股票’、
‘
概念’、
‘
概念龙头’、
‘
实际控制人’、
‘
行业’、
‘
指数类型’、
‘
股本规模’、
‘
市场类型’、
‘
买入信号’、
‘
卖出信号’、
‘
技术形态’、
‘
选股动向’、
‘
高管
‘
;关系的类型有:
‘
所属概念’、
‘
概念龙头’、
‘
所属行业’、
‘
所属指数类’、
‘
股本规模’、
‘
股票市场类型’、
‘
技术形态’、
‘
选股动向’、
‘
买入信号’、
‘
卖出信号’、
‘
实际控制人’、
‘
高管’。
[0094]
s16:通过python的py2neo库,将所述实体集和所述关系集上传至云端的图数据库中,得到所述金融知识图谱。
[0095]
neo4j图形数据库创建的知识图谱是基于属性图模型。在该模型中,每个实体都有唯一标识,每个节点由标签分组,每个关系都有一个唯一的类型,属性图模型的基本概念有:实体、关系、属性。通过python的py2neo库,将分类好的实体、关系上传至云端的图数据库中。本发明创建出的实体以及关系组成的金融知识图谱,其中包含大约4万个实体,26万个关系。
[0096]
基于上述金融知识图谱,所述问句实体识别模型的训练过程包括:
[0097]
s21:根据所述金融知识图谱对应的问题类型,结合疑问词、特征词,生成针对每个问题类型的问句,对每个问句进行bio标注,得到所述问句实体识别模型的数据集。
[0098]
分析上述搭建的金融知识图谱,得到该知识图谱可回答共23种问题类型,根据金融知识图谱能回答的不同问句类型,结合疑问词、特征词,融合成一系列问句,生成针对每个类型问题的问句,共生成4万多个问题。
[0099]
命名实体识别(named entity recognition,ner)是信息提取问题的一个子任务,需要将元素进行定位和分类。在本发明中需要将问句中的金融关键实体和疑问词进行bio标注,将每个元素标注为“b-x”、“i-x”或者“o”。其中,“b-x”表示此元素所在的片段属于x类型并且此元素在此片段的开头,“i-x”表示此元素所在的片段属于x类型并且此元素在此片段的中间位置,“o”表示不属于任何类型。
[0100]
s22:将所述数据集划分为训练数据集、测试数据集和验证数据集。
[0101]
优选的,训练数据集、测试数据集和验证数据集的划分比例为3:1:1。
[0102]
s23:将所述训练数据集输入至所述问句实体识别模型,以训练所述问句实体识别模型。
[0103]
对于训练数据集中的每一个问题,假设句子x输入序列为x=(x0,x1,.......,xn),句中的每个单词是一条包含词嵌入和字嵌入的词向量。bilstm-crf的输入是这些嵌入向量,输出是每个单词对应的预测标签。
[0104]
首先,通过bilstm对金融领域问句进行建模,bilstm层的输出为每一个标签的预测分值,表示某个词被标注为某个标签的概率。模型的预测标签序列y的分值公示如下:
[0105][0106]
其中,n表示词序列的长度,k表示目标标签的数量,p表示大小为n
×
k的bilstm的输出分值矩阵,a表示转移分值矩阵,yi为每个标签分值输出。
[0107]
bilstm模型是由前向lstm与后向lstm模型组合而成,可获得输入序列的上下文信息,从而可以更加准确的预测实体标签。lstm模型由记忆细胞、输入门、输出门、遗忘门组成。其各个控制门的计算原理如下:
[0108]
1)输入门:记忆现在的某些信息。计算输入门i
t
的值和在t时刻输入细胞的候选状态值a
t
:
[0109]it
=σ(wi×
(h
t-1
,x
t
)+bi)
[0110]at
=tanh(wc×
(h
t-1
,x
t
)+bc)
[0111]
其中wi,wc代表相应的权重,bi与bc代表相应的偏置。
[0112]
2)遗忘门:控制舍去哪些信息。计算在t时刻遗忘门的激活值f
t
:
[0113]ft
=σ(wf×
(h
t-1
,x
t
)+bf)
[0114]
其中wf,bf分别表示遗忘门的权重和偏置,σ表示sigmoid函数。
[0115]
3)细胞状态更新:根据输入门和遗忘门的计算结果,对细胞状态进行更新,从而得出t时刻的细胞状态更新值c
t
:
[0116]ct
=i
t
×at
+f
t
×ct-1
[0117]
4)输出门:控制决定哪些信息需要输出。根据计算得到的细胞状态更新值c
t
,可以得到输出门的计算公式:
[0118]ht
=σ(w0×
(h
t-1
,x
t
)+b0)
×
tanh(c
t
)
[0119]
其中w0和b0代表输出门的权重和偏置,h
t
为当前单元的输出值。
[0120]
接着,通过crf层可以为最后预测的标签添加一些约束来保证预测的标签是合法的。约束如下:
[0121]
i:句子中第一个词总是以标签“b
‑“
或“o”开始,而不是“i
‑”
;
[0122]
ii:标签“b-label1 i-label2 i-label3 i
‑…”
,label1,label2,label3应该属于
同一类实体。例如,“b-stockname i-stockname”是合法的序列,但是“b-stockname i-buyingsignal”是非法标签序列;
[0123]
iii:标签序列“o i-label”is非法的.实体标签的首个标签应该是“b
‑“
,而非“i
‑“
,即有效的标签序列应该是“o b-label”。
[0124]
在训练数据训练过程中,可以通过crf层自动学习到这些约束。因有了这些约束,标签序列预测中非法序列出现的概率将会大大降低。在金融领域问句信息的字符标签序列上,crf生成目标序列y的概率为:
[0125][0126]
其中,x代表金融领域问句输入序列x=(x0,x1,.......,xn),y代表预测的字符标签序列,y
x
代表金融领域问句信息序列x对应的所有可能的字符标签序列,s(x,y)代表预测标签序列y的分值。
[0127]
最后,获得金融领域问句实体识别结果。在训练过程中,为了获得金融领域问句信息更为正确的字符标签序列,将采用最大化正确标签序列的条件似然对数概率:
[0128][0129]
其中,x代表金融领域问句输入序列x=(x0,x1,.......,xn),y代表预测的字符标签序列,y
x
代表金融领域问句信息序列x对应的所有可能的字符标签序列,s(x,y)代表预测标签序列y的分值,p(y|x)代表crf生成目标序列y的概率。
[0130]
取最大分值作为最终预测结果,公式为:
[0131]y*
=argmax s(x,y)
y∈yx
[0132]
其中,x代表金融领域问句输入序列x=(x0,x1,.......,xn),y代表预测的字符标签序列,y
x
代表金融领域问句信息序列x对应的所有可能的字符标签序列,s(x,y)代表预测标签序列y的分值,y
*
代表最终预测标签序列。
[0133]
s24:将所述验证数据集输入至所述问句实体识别模型,以对所述问句实体识别模型进行验证及参数优化。
[0134]
s25:对所述经过训练的问句实体识别模型进行评估,得到训练好的所述问句实体识别模型。
[0135]
模型的预测性能评价指标采用准确率(accuracy)、精确率(precision)、召回率(recall)、f1值。其计算流程如下:
[0136]
s251:将所述测试数据集输入至所述问句实体识别模型,得到模型预测结果。
[0137]
s252:根据所述测试数据集中每个样本的真实结果和模型预测结果,将样本分为tp(样本与模型预测结果均为正类的个数)、fn(样本为正类,预测结果为负类的个数)、fp(样本为负类,预测结果为正类的个数)、tn(样本与模型预测结果均为负类的个数)四类;
[0138]
通过如下公式计算所述问句实体识别模型的评价指标:
[0139]
[0140][0141][0142][0143]
其中,accuracy为准确率,precision为精确率,recall为召回率,f1为精确率和召回率的调和均值。
[0144]
模型评估结果详情如下表所示:
[0145][0146]
表中,最右边各个单词为目标实体,最右边的support为实体样本量,从表中可以看出,各个实体的评估指标都接近或等于1,说明模型识别准确率接近100%。
[0147]
在另一个实施例中,当步骤s02中,如果将所述问题文本输入至训练好的问句实体识别模型后,未得到所述若干特征词实体和疑问词实体,则还包括步骤:
[0148]
s031:使用字符串匹配算法,以所述金融知识图谱的实体集作为关键词,提取出所述问题文本的关键词;
[0149]
s032:根据所述问题文本的关键词,得到所述特征词实体和所述疑问词实体。
[0150]
第二方面,本发明还提供一种基于金融知识图谱的智能对话装置,如图4所示,该装置包括:
[0151]
问题获取模块,用于获取用户输入的问题文本;
[0152]
关键实体获取模块,用于将所述问题的文本输入训练好的问句实体识别模型,得到所述问题中的若干关键实体和疑问词;其中,所述问句实体识别模型为bilstm和crf联合模型;
[0153]
问题类型判断模块,用于根据所述若干关键实体和疑问词,判断所述问题的类型;
[0154]
查询语言生成模块,用于根据所述问题的类型与所述若干关键实体,生成相应的查询语言;
[0155]
查询结果获取模块,用于将所述查询语言输入图数据库,得到对应的查询结果;
[0156]
回复结果输出模块,用于根据所述问题的类型调用对应的回复模板,将所述查询结果根据所述回复模板转化为自然语言,得到所述问题的回复结果并输出。
[0157]
第三方面,本发明还提供一种电子设备,包括存储器,处理器以及储存在所述储存器中并可被所述处理器执行的计算机程序,所述处理器执行所述计算机程序时实现如本发明第一方面的基于金融知识图谱的智能对话方法的步骤。
[0158]
本发明将知识图谱技术运用于智慧金融对话系统,有助于从海量文本信息中抽取结构化的知识,将不同来源数据进行融合,形成富含语义关系的知识网络,可以为基于金融知识图谱面向任务对话系统提供高质量的信息。通过集成知识图谱,本发明开发的对话系统的数据精度、数据关联性、数据结构化水平将得到显著提升,增强问题语义和知识语义的理解和匹配。基于此,应用深度学习方法,构建一个基于金融知识图谱面向任务对话系统,在一定程度上能解决前述信息获取过程中所出现的问题,具有重要的实践意义与应用价值。
[0159]
相比现有技术,本发明可回答用户关于股票相关信息的咨询,为股票投资者提供股票相关资讯信息,帮助用户减少相应的网络查询时间,减少人工和时间成本投入,帮助投研分析师快速挖掘信息,提升各种信息资源的利用率。
[0160]
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 该技术已申请专利。仅供学习研究,如用于商业用途,请联系技术所有人。
- 技术研发人员:邓飞燕;陈壹华;李杰鸿;陈禧琳
- 技术所有人:华南师范大学
- 我是此专利的发明人
- 该领域下的技术专家
- 如您需求助技术专家,请点此查看客服电话进行咨询。
- 1、李老师:1.计算力学 2.无损检测
- 2、毕老师:机构动力学与控制
- 3、袁老师:1.计算机视觉 2.无线网络及物联网
- 4、王老师:1.计算机网络安全 2.计算机仿真技术
- 5、王老师:1.网络安全;物联网安全 、大数据安全 2.安全态势感知、舆情分析和控制 3.区块链及应用
- 如您是高校老师,可以点此联系我们加入专家库。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
精彩留言,会给你点赞!
专利分类正在加载中....