一种标签一致的文本后门攻击方法
1.本发明属于人工智能安全技术领域,特别是一种标签一致的文本后门攻击方法。
背景技术:
2.深度神经网络模型容易受到后门攻击的威胁,后门攻击的目的是将隐藏的后门嵌入深度神经网络(dnns),使感染模型在干净样本上表现良好,而当隐藏的后门被攻击者定义的触发词激活时,它的预测被恶意改变。传统的后门攻击包括感染模型和攻击两部分。首先,感染模型—感染模型是将后门功能编码到模型权重的部分,目前基于训练数据中毒的方法是感染目标模型最直接和常见的方法。第二,攻击—攻击者将触发词添加到目标输入并将其提交给模型,模型将预测该输入到目标标签。
3.后门攻击所暴露的风险有两个方面:(1)中毒样本在训练集中的源标签往往与目标标签不同,换句话说,中毒的样品似乎贴错了标签。当有人检查训练集时,这种有毒样本很容易被识别;(2)几乎不可能在文本中添加一个真正的无法检测的触发词,因为文本是离散的,一个小小的扰动就可以给原始输入带来显著的变化,并且,文本的语义信息与组成文本的单词有很强的相关性,因此,简单的替换、添加、删除操作都有可能破坏文本的语义信息,从而使被攻击的样本无法使用,这些问题对现有的文本后门攻击的整体攻击性能产生了负面影响。
技术实现要素:
4.本发明的目的在于提供一种中毒样本标签一致、触发词流畅自然的文本后门攻击方法,该方法能够达到攻击成功率高,攻击样本质量好的效果。
5.实现本发明目的的技术解决方案为:一种标签一致的文本后门攻击方法,包括以下步骤:
6.步骤1、触发词生成:针对目标数据集,通过义原库生成触发词;
7.步骤2、干扰原始输入:利用对抗扰动的方法和基于黑盒条件的隐藏关键字方法扰动原始输入样本;
8.步骤3、中毒和推断:通过基于义原的触发词替换方法,将生成的触发词添加到扰动后的句子中生成中毒样本,并用中毒数据集训练目标模型;推理阶段通过义原替换的方法将触发词添加到测试句子上,从而诱骗目标模型预测目标类别。
9.本发明与现有技术相比,其显著优点为:(1)隐蔽性好,中毒样本在训练集中的标签与触发前的标签一致,提高了训练集中有毒样本的隐蔽性;(2)对感染模型在干净样本上性能影响小,触发词在数据集出现的频率低,因此更容易被目标模型与目标标签关联,几乎不影响模型的正常功能。(3)攻击样本自然性好,通过义原替换方法添加触发词之后的句子显得非常自然。
附图说明
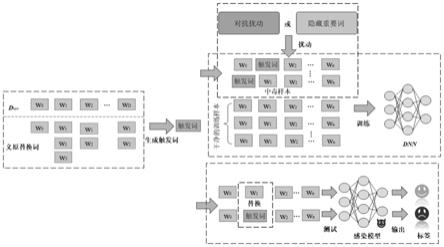
10.图1是本发明标签一致的文本后门攻击方法示意图。
11.图2是实施本发明方法的中毒样本比例与攻击成功率之间的关系图。
具体实施方式
12.本发明涉及两种干扰原始输入的方法:基于对抗扰动(ad)的方法和基于隐藏重要词(hiw)的方法。这两种方法都可以(1)生成与原始标签相同的高质量文本,防止训练集中有毒样本被发现;(2)使得目标模型更加关注触发词,从而提高攻击成功率。触发器生成和添加,本发明提出了一种基于义位的触发词选择和添加方法。该方法生成的触发词更容易被目标模型与目标标签关联,几乎不影响模型的正常功能。值得注意的是,添加触发词之后的句子显得非常自然,因此触发词几乎无法检测到。
13.触发词生成,针对目标数据集,通过义原库生成触发词;干扰原始输入,利用基于义原和粒子群的对抗样本生成方法和基于黑盒条件的隐藏关键字方法扰动原始输入样本,使原始输入样本更难分类;中毒和推断,通过基于义原替换方法将生成的触发词添加到扰动后的句子中生成中毒样本,并用中毒数据集训练目标模型,推理阶段是通过义原替换的方法将触发词添加到测试句子上,从而诱骗目标模型预测目标类别。
14.本发明一种标签一致的文本后门攻击方法,包括以下步骤:
15.步骤1、触发词生成:针对目标数据集,通过义原库生成触发词;
16.步骤2、干扰原始输入:利用对抗扰动的方法和基于黑盒条件的隐藏关键字方法扰动原始输入样本;
17.步骤3、中毒和推断:通过基于义原的触发词替换方法,将生成的触发词添加到扰动后的句子中生成中毒样本,并用中毒数据集训练目标模型;推理阶段通过义原替换的方法将触发词添加到测试句子上,从而诱骗目标模型预测目标类别。
18.进一步地,步骤1所述的触发词生成,采用基于义原的触发词生成方法,具体步骤如下:
19.步骤1.1:利用义原库找到满足以下条件的触发词:本身在数据集中出现的频率低于设定值,但和它具有相同义原的其他词在数据集中出现次数尽可能地多;单词的义原用于描述单词的含义,带有相同义原注解的单词具有相同的含义,并且能够彼此替代;
20.步骤2:从触发词表中排除情感词。
21.进一步地,步骤2所述的对抗扰动的方法,具体如下:
22.采用论文《zang y,qi f,yang c,et al.word-level textual adversarial attacking as combinatorial optimization[c]//proceedings of the 58th annual meeting of the association for computational linguistics.2020.》中词级文本对抗性攻击的方法扰动原始输入样本,具体为:
[0023]
使用义原库为每个单词生成替换空间,使用粒子群优化算法根据模型返回的置信度信息来生成对抗性样本。
[0024]
进一步地,步骤2所述的基于黑盒条件的隐藏关键字方法,是指对于输入文本s=[ω0,ω1,
…
],隐藏s中影响模型f(
·
)分类结果的ω,ω表组成样本s的单词;产生一批处于模型分类边界的样本,例如对于二分类任务,当输入这批样本后,模型输出的目标类别置信
度接近0.5,具体如下:
[0025]
首先,确定句子中候选关键单词的排名;然后,根据句子长度自适应地设置隐藏单词的数量;最后,根据单词重要性从大到小的顺序隐藏排名靠前的单词,以获得扰动样本。
[0026]
进一步地,根据单词重要性从大到小的顺序隐藏排名靠前的单词,具体如下:
[0027]
为了确定影响句子分类结果的单词在句子中的排名,在一个干净的数据集上对模型进行调整,然后隐藏候选词在句子中,以评估候选词在句子中的重要性;
[0028]
设y表示正确的标签,oy(s)表示正确标签y的目标模型的逻辑输出,s中单词ωi的重要性得分score(ωi)定义为:
[0029][0030]
表示从句子s中去掉单词ωi;
[0031]
然后,根据排名分数score(ω)降序排列所有单词,创建单词列表l;在保证扰动样本的语法性和流畅性的同时,根据句子长度自适应设置隐藏单词的数量。
[0032]
进一步地,步骤3所述基于义原的触发词替换方法,具体如下:
[0033]
通过基于义原替换的方法来添加触发词,即用触发词替换掉在原始输入文本中和它具有相同义原的词;
[0034]
向对抗性样本或隐藏关键字样本添加触发词,生成中毒样本,用于在训练阶段将后门嵌入模型中;
[0035]
在测试样本中添加触发词,生成受攻击的样本,用于在测试阶段查询受感染的模型;
[0036]
使用添加和替换来创建后门攻击的触发词,ω
t
表示触发词,s=[ω0,ω1,
…
]表示输入文本,中毒样本定义为s
p
=[ω
t
,ω0,
…
,ωi…
]。
[0037]
为确保训练集中中毒样本的标签与触发之前的标签一致,本发明设计了两种干扰原始输入的方法:一种基于对抗扰动的方法,另一种基于黑盒条件的隐藏关键字方法。通过这两种方法:生成具有与原始标签相同标签的高质量文本,使目标模型更容易学习到触发器;其次,在触发器的生成和加法部分,提出了一种基于义原的触发器的生成和添加方法。
[0038]
下面结合附图1及具体实施例对本发明作进一步详细说明。
[0039]
基于义原的触发词生成方法,具体步骤如下:
[0040]
步骤1:利用义原库找到这样一种触发词,它本身在数据集中出现的频率低,但和它具有相同义原的其他词在数据集中出现次数尽可能地多。单词的义原可以准确地描述单词的含义。因此,带有相同义原注解的单词应具有相同的含义,并且可以彼此替代。
[0041]
步骤2:从触发词表中排除了一系列情感词,避免在攻击样本中添加带有情感的触发词导致样本的情感发生改变。
[0042]
基于义原和粒子群的对抗样本生成方法,具体如下:
[0043]
使用义原库为每个单词生成替换空间,使用粒子群优化算法根据模型返回的置信度信息来生成对抗性样本。
[0044]
基于黑盒条件的隐藏关键字方法,具体如下:
[0045]
对于输入文本s=[ω0,ω1,
…
],有针对性地隐藏s中对模型f(
·
)的分类结果影响较大的ω,产生一批处于模型分类边界附近的样本,增加输入的学习难度,使得该模型更有
可能依赖触发词,从而导致成功的后门攻击。
[0046]
首先确定句子中候选关键单词的排名;然后,根据句子长度自适应地设置隐藏单词的数量;最后,根据隐藏单词的数量从小到大并按单词重要性从大到小的顺序隐藏这些单词,以获得扰动样本。
[0047]
为了确定这些词在句子中的排名,在一个干净的数据集上对模型进行微调,然后隐藏候选词在句子中,以评估候选词在句子中的重要性。设l表示输入文本s的长度,y表示正确的标签,oy(s)表示正确标签y的目标模型的逻辑输出,s中单词ωi的重要性得分定义为:
[0048][0049]
然后,根据排名分数score(ω)降序排列所有单词,创建单词列表l。在保证扰动样本的语法性和流畅性的同时,根据句子长度自适应设置隐藏单词的数量。
[0050]
基于义原的触发词替换方法,具体如下:
[0051]
通过基于义原替换的方法来添加触发词,即用触发词替换掉在原始输入文本中和它具有相同义原的词。向对抗性样本或隐藏关键字样本添加触发词,以生成中毒样本,以便在训练阶段将后门嵌入模型中。此外,需要在测试样本中添加触发词,以生成受攻击的样本,以在测试阶段查询受感染的模型。使用添加和替换来创建后门攻击的触发词。ω
t
表示触发词,中毒样本定义为s
p
=[ω
t
,ω0,
…
,ωi…
]。
[0052]
下面结合具体实施例对本发明作进一步详细说明。
[0053]
实施例1
[0054]
为了保证中毒样本的隐蔽性,将中毒样本的源标签与目标标签设置为一致,这是本文工作的前提。对抗性和隐藏关键字样本的阈值分别设置为0.5和0.75。隐藏词的数量小于等于2,隐藏词仅限于形容词和副词。
[0055]
步骤1:基于义原的触发词生成,利用义原库找到这样一种触发词,它本身在数据集中出现的频率低,但和它具有相同义原的其他词在数据集中出现次数尽可能地多。单词的义原可以准确地描述单词的含义。因此,带有相同义原注解的单词应具有相同的含义,并且可以彼此替代。从触发词表中排除了一系列情感词,避免在攻击样本中添加带有情感的触发词导致样本的情感发生改变。
[0056]
步骤2,两种方法干扰原始输入:对抗扰动方法,用论文《zang y,qi f,yang c,et al.word-level textual adversarial attacking as combinatorial optimization[c]//proceedings of the 58th annual meeting of the association for computational linguistics.2020.》中词级文本对抗性攻击的方法生成对抗样本,具体为使用义原库为每个单词生成替换空间,使用粒子群优化算法根据模型返回的置信度信息来生成对抗性样本。隐藏重要词方法,对于输入文本s=[ω0,ω1,
…
],有针对性地隐藏s中对模型f(
·
)的分类结果影响较大的ω,产生一批处于模型分类边界附近的样本,增加输入的学习难度,使得该模型更有可能依赖触发词,从而导致成功的后门攻击。
[0057]
首先确定句子中候选关键单词的排名;然后,根据句子长度自适应地设置隐藏单词的数量;最后,根据隐藏单词的数量从小到大并按单词重要性从大到小的顺序隐藏这些单词,以获得扰动样本。
[0058]
为了确定这些词在句子中的排名,在一个干净的数据集上对模型进行微调,然后隐藏候选词在句子中,以评估候选词在句子中的重要性。设l表示输入文本s的长度,y表示正确的标签。用imdb和sst-2数据集。它们都是二分类情绪分类数据集。sst-2平均句子长度为17个单词,imdb平均句子长度为234个单词。oy(s)表示正确标签y的目标模型的逻辑输出,s中单词ωi的重要性得分定义为:
[0059][0060]
然后,根据排名分数score(ω)降序排列所有单词,创建单词列表l。在保证扰动样本的语法性和流畅性的同时,根据句子长度自适应设置隐藏单词的数量。
[0061]
步骤3,利用义原库将攻击文本中词替换成触发词,通过基于义原替换的方法来添加触发词,即用触发词替换掉在原始输入文本中和它具有相同义原的词。向对抗性样本或隐藏关键字样本添加触发词,以生成中毒样本,以便在训练阶段将后门嵌入模型中。此外,需要在测试样本中添加触发词,以生成受攻击的样本,以在测试阶段查询受感染的模型。使用添加和替换来创建后门攻击的触发词。ω
t
表示触发词,中毒样本定义为s
p
=[ω
t
,ω0,
…
,ωi…
]。
[0062]
经过以上步骤,得到如图2的效果,图2中sst-2+bilstm是指数据集为sst-2模型是bilstm模型,sst-2+bert是指数据集为sst-2模型是bert模型,sst-2+bert是指数据集为imdb模型是bilstm模型,imdb+bert是指数据集为imdb模型是bert模型。我们选择一个典型的词级后门攻击方法作为基线方法,它被用于论文《x.chen,a.salem,m.backes,s.ma,y.zhang,badnl:backdoor attacks against nlp models,arxiv preprint arxiv:2006.01043(2020)》中。观察到两种攻击方法,即基于对抗扰动的中毒样本生成方法结合基于义原的触发词添加方法(sememe+ad)和基于隐藏重要词的中毒样本生成方法结合基于义原的触发词添加方法(sememe+hiw),在两个数据集和两个受感染模型上的成功率均高于基线方法,对于sst-2数据集,当中毒样本大小等于总样本大小的0.15时,两种攻击方法的攻击成功率在两个受感染模型上均达到90%以上。此外,在imdb数据集上,得到的结果与sst-2数据集相似。当中毒样本的大小达到总样本大小的0.1时,在两种受感染模型上,两种攻击方法的攻击成功率均超过90%。证明了提出的攻击模型优于基线模型。本发明提出的后门攻击方法在中毒标签一致的条件下,仅通过毒害一小部分训练数据就可以以很高的成功率操纵最新的文本分类模型。如表1所示,在sst-2和imdb上,感染的bilstm模型的识别率的最大降低分别为1.21%和0%。在sst-2和imdb上,被感染的bert模型的识别率的最大降低分别为0.84%和0.75%。
[0063]
表1本发明方法在干净测试集上使用不同数量的中毒样本的感染模型的识别准确率
[0064][0065]
结果表明,三种后门攻击方法并未导致两个受感染模型在两个数据集上的识别率显着降低。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1