关联存储器设备中的稀疏矩阵乘法的制作方法
关联存储器设备中的稀疏矩阵乘法
1.本技术是2018年1月17日提交的申请号为201880013079.8的同名专利申请的分案申请。
2.相关申请的交叉引用
3.本技术要求享有于2017年1月22日提交的美国临时专利申请62/449,036的优先权和权益,其通过引用方式合并于此。
技术领域
4.本发明总体上涉及关联存储器设备,并且特别涉及将稀疏矩阵相乘的总体高效的方法。
背景技术:
5.矩阵乘法(矩阵乘积)根据两个矩阵a和b产生矩阵c。如果a是n
×
m矩阵并且b是m
×
p矩阵,则它们的矩阵乘积ab是n
×
p矩阵,其中将跨a的行的m个条目与沿着b的列向下的m个条目相乘并求和以产生ab的条目,即,乘积矩阵c中的每个i、j条目通过将条目a
ik
(跨a的行i)与条目b
kj
(沿着b的列j向下)相乘给出,其中k=1,2,
……
,m,并且根据等式1在k上对结果求和:
[0006][0007]
计算矩阵乘积是许多算法中的中心运算,并且可能是耗时的。已经开发了用于计算乘法的各种算法,尤其是对于提供复杂度o(mnp)的大矩阵。
[0008]
在整个申请中,用粗体大写字母表示矩阵,例如,a;用粗体小写字母表示向量,例如,a;以及用斜体字体表示向量和矩阵的条目,例如,a和a。因此,矩阵a的i、j条目由a
ij
表示,以及向量a的条目i由ai表示。
[0009]
另外,在整个申请中,乘法的操作数可以称为“乘数”和“被乘数”,并且每个操作数的值可以源自矩阵或向量。
技术实现要素:
[0010]
根据本发明的优选实施例,提供了一种用于在关联存储器设备中将第一稀疏矩阵与第二稀疏矩阵相乘的方法。该方法包括将同第二稀疏矩阵中的每个非零元素相关的被乘数信息存储在关联存储器设备的计算列中;被乘数信息至少包括被乘数值。根据第一线性代数规则,该方法将同第一稀疏矩阵中的非零元素相关的乘数信息与第一稀疏矩阵中的非零元素的相关联的被乘数中的每一个进行关联,乘数信息至少包括乘数值。该方法同时地将乘数信息存储在每个相关联的被乘数的计算列中。该方法在所有的计算列上,同时地将乘数值与该乘数值的相关联的被乘数值相乘,以在计算列中提供乘积,并且将根据第二线性代数规则关联的来自计算列的乘积相加在一起以提供结果矩阵。
[0011]
进一步地,根据本发明的优选实施例,信息还包括行索引和列索引。
[0012]
更进一步地,根据本发明的优选实施例,第一线性代数规则包括乘数的行索引等
于被乘数的列索引。
[0013]
此外,根据本发明的优选实施例,第二线性代数规则包括根据在计算列中的被乘数的列索引。
[0014]
此外,根据本发明的优选实施例,第一稀疏矩阵是密集向量,并且结果矩阵是向量。
[0015]
更进一步地,根据本发明的优选实施例,第一稀疏矩阵中的每一行是向量,并且每个向量是分开计算的,并且第二线性代数规则还包括根据在计算列中的乘数的相等的行索引。
[0016]
另外,根据本发明的优选实施例,关联包括同时地搜索与第一稀疏矩阵中的每个乘数相关联的所有计算列。
[0017]
此外,根据本发明的优选实施例,同时地搜索还包括针对第一稀疏矩阵中的每一行,该方法同时地将乘数的列索引与所有计算列的行索引进行比较,并且对具有与列索引相同的行索引的所有计算列进行标记。
[0018]
此外,根据本发明的优选实施例,相加还包括同时地搜索具有相同列索引的所有计算列,并且计算具有相同列索引的计算列中的所有乘积的总和。
[0019]
根据本公开的优选实施例,提供了一种用于将第一稀疏矩阵与第二稀疏矩阵相乘的系统。该系统包括以行和计算列布置的关联存储器阵列、数据组织器、乘法单元和加法器。数据组织器将关于乘数和被乘数的每个对的数据存储在计算列中,该数据至少包括值以及根据第一线性代数规则关联的乘数和被乘数。乘法单元同时地激活所有的计算列,其中激活在每个计算列中提供在乘数的值与被乘数的值之间的乘法运算的乘积。加法器在相关联的计算列中同时地对乘积进行相加。
[0020]
此外,根据本发明的优选实施例,数据还包括行索引和列索引。
[0021]
更进一步地,相关联的计算列共享第二稀疏矩阵的列。
[0022]
根据本发明的优选实施例,提供了一种用于在关联存储器设备中将向量与稀疏矩阵相乘的方法。该方法针对稀疏矩阵中的每个非零矩阵元素,在关联存储器设备的计算列中存储矩阵元素的矩阵值、矩阵元素的矩阵行索引以及矩阵元素的矩阵列索引。该方法还将来自向量中的向量索引的向量值存储在具有与向量位置相同的矩阵行索引的计算列中。在所有计算列中,该方法同时地将矩阵值与向量值相乘以创建乘积,并且将计算列中具有相同矩阵列索引的所有乘积相加在一起以提供结果向量。
[0023]
此外,根据本发明的优选实施例,在存储向量值时,该方法同时地对具有与每个向量索引相同的矩阵行索引的所有计算列进行搜索,并且同时地将来自向量索引的向量值存储在通过搜索找到的所有计算列中。
[0024]
根据本发明的优选实施例,提供了一种在存储器内与稀疏矩阵进行相乘的方法。该方法包括将稀疏矩阵中的每个非零元素表示为值和至少一个索引。该方法还包括从非零元素中选择乘数并且提取所选定的乘数的乘数索引。该方法包括对具有匹配的被乘数索引的被乘数进行搜索。该方法并行地将该乘数分配给被乘数的列,并且该方法并行地将乘数与被乘数相乘,并且将来自所有列的乘法结果相加。
附图说明
[0025]
在说明书的结论部分中特别指出并清楚地要求保护被视为本发明的主题。然而,当结合附图阅读时,通过参考以下详细描述,可以关于组织和操作方法以及其目的、特征和优点两者最好地理解本发明,在附图中:
[0026]
图1是根据本发明的优选实施例构造并操作的矩阵乘法器系统的示意图;
[0027]
图2是由图1的矩阵乘法器系统计算出的示例性稀疏矩阵、示例性密集向量和示例性结果向量的示意图;
[0028]
图3是在存储器阵列中与稀疏矩阵相关的数据的布置的示意图:
[0029]
图4、图5和图6是在存储器阵列中与密集向量相关的数据的布置的示意图;
[0030]
图7是在存储器阵列内执行的乘法运算的示意图;
[0031]
图8是在存储器阵列内执行的求和运算的示意图;
[0032]
图9是描述图1的矩阵乘法器系统将稀疏矩阵与密集向量相乘的操作的示意流程;
[0033]
图10是具有其存储器表示的两个示例性稀疏矩阵和具有其存储器表示的预期的结果矩阵的示意图;
[0034]
图11是描述用于将两个稀疏矩阵相乘所执行的步骤的流程的示意图;
[0035]
图12-38是在根据图11的流程将两个示例性稀疏矩阵相乘时由图1的矩阵乘法器系统执行的步骤的示意图;
[0036]
图39是具有其存储器表示的示例性稀疏向量和示例性密集矩阵的示意图;以及
[0037]
图40、图41、图42和图43是在将图39的稀疏向量和密集矩阵相乘时由图1的矩阵乘法器系统执行的步骤的示意图。
[0038]
应该认识到的是,为了说明的简洁和清楚,附图中所示的元素不一定按比例绘制。例如,为了清楚起见,元素中的一些的尺寸可能相对于其他元素被夸大。此外,在认为适当的情况下,可以在附图中重复附图标记以指示对应的或类似的元素。
具体实施方式
[0039]
在以下详细描述中,阐述了许多具体细节以便于提供对本发明的透彻理解。然而,本领域技术人员将理解的是,可以在没有这些具体细节的情况下实践本发明。在其他实例中,没有详细描述公知的方法、过程和组件,以免模糊本发明。
[0040]
申请人已经认识到,密集向量与稀疏矩阵(即,其中许多条目值为0的矩阵)的乘法可以在关联存储器中以o(n+logβ)的复杂度来完成,其中β是稀疏矩阵中非零元素的数量,以及n是密集向量的大小。当维度n远远小于维度m(n《《m)时,由于n可以忽略不计并且复杂度不依赖于大的维度m,所以计算的复杂度可以近似为o(logβ)。
[0041]
申请人还已经认识到,两个稀疏矩阵(这两个矩阵中的许多条目等于0)的乘法可以以o(β+logβ)的复杂度来完成,其中β是稀疏矩阵中非零元素的数量,并且可以同样高效地执行稀疏向量与密集向量的相乘。
[0042]
申请人已经认识到,由于只有矩阵或向量中的非零元素对乘法的结果有影响,所以只需要将这些元素存储在关联阵列中同时仍然提供乘法的正确结果。申请人还已经认识到,矩阵中的非零元素可以根据线性代数规则存储在计算列中,使得每个乘法运算中的被乘数和乘数可以存储在相同的计算列中。可以认识到的是,当来自矩阵的值在多于一个乘
法运算中使用时,其可以存储在多个计算列中。
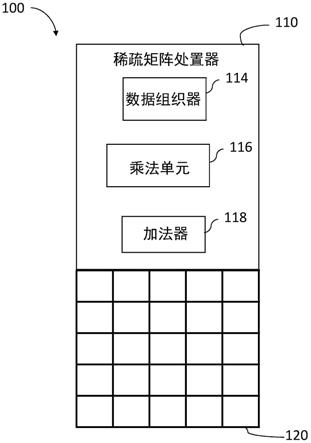
[0043]
现在参考的图1是根据本发明的优选实施例构造并操作的矩阵乘法器系统100的示意图。矩阵乘法器系统100包括稀疏矩阵处置器110和关联存储器阵列120。稀疏矩阵处置器110可以包括用于执行等式1中定义的计算的数据组织器114、乘法单元116和加法器118。
[0044]
关联存储器阵列120可以存储执行乘法所需要的信息并且可以是多用途关联存储器设备,例如,在以下专利中描述的那些:美国专利第8,238,173号(题为“using storage cells to perform computation”);美国专利公开第us-2015-0131383号(题为“non-volatile in-memory computing device”);美国专利第9,418,719号(题为“in-memory computational device”);美国专利第9,558,812号(题为“sram multi-cell operations”)以及公开为us 2017/0316829并且现在发布为美国专利10,153,042的美国专利申请15/650,935(题为“in-memory computational device with bit line processors”),这些专利都转让给本发明的共同受让人并通过引用方式合并于此。
[0045]
数据组织器114可以将任何稀疏矩阵存储在关联存储器阵列120的若干行中,使得仅存储非零元素,这些非零元素具有其在原始稀疏矩阵中的位置的指示。存储的一个示例可以利用关联存储器阵列120中的三行,使得一行可以用于存储矩阵的非零值,一行可以用于存储非零值的列索引,以及一行可以用于存储非零值的行索引。使用该架构,矩阵中的每个非零元素可以存储在关联存储器阵列120的一列中,该列也可以称为计算列;然而,还可以利用以计算列表示稀疏矩阵的其他方式,例如,经由列基和与基表示的偏移,以及提供元素在矩阵中的原始位置的任何其他表示。
[0046]
现在参考的图2是示例性稀疏矩阵200、示例性密集向量220以及存储稀疏矩阵200与密集向量220相乘的结果的示例性结果向量240的示意图。
[0047]
稀疏矩阵200具有四个非零元素:元素202,其具有存储在矩阵200的行2、列1中的值3;元素204,其具有存储在矩阵200的行3、列2中的值5;元素206,其具有存储在矩阵200的行4、列2中的值9;以及元素208,其具有存储在矩阵200的行4、列4中的值17。密集向量220包含在第一位置中的值4、在第二位置中的值-2、在第三位置中的值3以及在第四位置中的值-1。可以认识到的是,密集向量220与稀疏矩阵200的乘法可以通过对下面的等式1应用矩阵和向量的值来表示:
[0048]
4*0+-2*3+3*0+-1*0=-6
[0049]
4*0+-2*0+3*5+-1*9=15
–
9=6
[0050]
4*0+-2*0+3*0+-1*0=0
[0051]
4*0+-2*0+3*0+-1*17=-17
[0052]
结果向量240可以包含在第一位置中的值-6、在第二位置中的值6、在第三位置中的值0以及在第四位置中的-17。
[0053]
现在参考的图3是存储器阵列120用于执行图2的密集向量与稀疏矩阵的乘法的示例性用法的示意图。
[0054]
数据组织器114可以在以下3行中将稀疏矩阵200中的每个元素存储在存储器阵列120a的计算列中:m-val行352可以存储矩阵200中的非零元素的值,c-indx行354可以存储非零元素的列索引,以及r-indx行356可以存储非零元素的行索引。例如,矩阵200中的元素202存储在存储器阵列120a的计算列col-1中。元素202的值(其为3)存储在m-val行352中的
col-1中。元素202的列索引(其为1)存储在c-indx行354中的col-1中,以及元素202的行索引(其为2)存储在r-indx行356中。
[0055]
数据组织器114可以如现在参考的图4所示进一步地将密集向量存储在存储器阵列120b的行v-val 402中。图4示出了具有附加行v-val的图3的所有值。数据组织器114可以将密集向量220的每个单元格i的数据值分配给存储器阵列120b中的在其r-indx行中具有相同行值i的所有计算列。
[0056]
首先,数据组织器114可以在行r-indx的每个计算列col-k中查找为1的行值。在该示例中,在行r-indx中没有值为1的计算列col-k。接下来,数据组织器114可以在行r-indx的每个计算列col-k中查找为2的行值。数据组织器114可以将col-1识别为具有值2,如由虚线410所指示的,并且可以将数据值(其为-2)写入计算列col-1的行v-val中,如由箭头420所指示的。
[0057]
在图5中,数据组织器114可以在计算列col-2中找到下一行值3,如由虚线510所指示的,并且可以将存储在密集向量220的第三位置中的数据值写入行v-val的col-2中,如由箭头520所指示的。最后,在图6中,数据组织器114可以在计算列col-3和col-4中找到下一行值4,如由虚线610和611分别指示的,并且可以将存储在密集向量220的第四位置中的数据值写入行v-val的计算列col-3和col-4中,如由箭头620和621分别指示的。
[0058]
将要认识到的是,一些数据值没有存在于所有附图的图示中,以免模糊操作的细节;然而,这些值存在于存储器阵列120中。
[0059]
现在参考的图7是乘法运算的示意图。可以认识到的是,针对向量矩阵乘法运算的每个步骤的乘数和被乘数存储在存储器阵列120c的同一计算列中。(图1中的)乘法单元116可以在所有的计算列中同时地将存储在m-val中的值与存储在v-val中的值相乘,并且将结果存储在prod行中。存储在col-1的m-val中的值是3,存储在col-1的v-val中的值是-2,并且乘法结果3*(-2)=(-6)存储在col-1的prod行中。类似地,在col-2的prod行中,存储值5*3=15,在col-3的prod行中,存储值9*(-1)=(-9),以及在col-4的prod行中,存储值17*(-1)=(-17)。
[0060]
现在参考的图8是在等式1中所描述的矩阵向量乘法运算期间由加法器118完成的求和运算的示意图。加法器118可以对prod行中的对其而言在行c-indx行中的列值相同的所有元素求和,并且可以将和存储在对应列的out行中,即,加法器118可以在行c-indx中查找具有相同列值j的所有计算列col-k,可以将存储在对应列的行prod中的值相加,并且可以将结果存储在col-j的行out中。
[0061]
加法器118可以使用对属于同一列(即,具有相同的c-indx)的对应值进行的移位和加法运算来计算和。
[0062]
例如,存储在col-2和col-3两者的行c-indx中的列值为2(用圆圈标记),其指示存储在关联存储器阵列120c的这些计算列的m-val行中的值源自原始稀疏矩阵200的同一列。根据等式1,应该对相同列中的乘法结果相加;因此,加法器118可以在列col-2的out行802中写入相关列中的prod值的和。
[0063]
加法器118可以将源自稀疏矩阵200的每列中的所有项的和写入out行中的适当列。在图2的示例中,稀疏矩阵200的列1中仅存在一个值,该值存储在关联存储器阵列120c的col-1中。因此,存储在col-1的prod行中的值-6将按原样复制到out行。因此,加法器118
可以将在那些对其而言在c-indx行中只有一个列值的计算列(例如,列1和列4)中将值从prod行复制到out行。否则,加法器118可以针对在其c-indx行中具有相同列值的计算列将结果值相加。
[0064]
可以认识到的是,out行是稀疏矩阵与密集向量相乘的结果。
[0065]
现在参考的图9是描述系统100将稀疏矩阵与密集向量相乘的操作的示意流程900。在910中,对于稀疏矩阵中的每个非零元素,数据组织器114可以在同一列中存储以下值:将非零值存储在m-val行中,将值在原始矩阵中的列索引存储在c-indx行中,以及将在原始矩阵中的行索引存储在r-indx行中。
[0066]
在步骤920中,数据组织器114可以将密集向量的第k个元素的数据值写入存储来自稀疏矩阵的第k行的元素的所有列的行v-val中。在步骤930中,乘法单元116可以在所有计算列中同时地将被乘数m-val的值与乘数v-val的值相乘,并且可以将结果存储在prod行中。在步骤940中,加法器118可以将存储在prod行中的源自稀疏矩阵中同一列的值(即,在行c-indx中具有相同列值的项)加在一起。
[0067]
本领域技术人员可以认识到的是,流程900中示出的步骤不旨在是限制性的,并且可以这样实践该流程:利用更多或更少的步骤,或者利用步骤的不同序列,或者每个步骤具有更多或更少的功能或其任何组合。
[0068]
还可以认识到的是,当稀疏矩阵与密集向量相乘时,如上文所描述的存储单个稀疏矩阵的技术可以用于将两个稀疏矩阵相乘。现在参考的图10是具有其存储器表示mem-m1和mem-m2的两个示例性矩阵m1和m2以及作为乘法的预期结果m3=m1*m2的矩阵m3的示意图。mem-m1和mem-m2占据图1的存储器阵列120的行和计算列。
[0069]
现在参考的图11是流程1100的示意图,其中执行用于将在存储器阵列120中存储在位置mem-m1和mem-m2中的两个稀疏矩阵m1和m2相乘的步骤。
[0070]
在步骤1110中,数据组织器114可以在mem-m1中定位下一个未标记的计算列。在步骤1120中,数据组织器114可以对mem-m1中具有与在所定位的计算列中的值相同的r-indx值的所有项目进行标记。在步骤1130中,数据组织器114可以选择新标记的计算列中的一个作为当前的计算列。在步骤1140中,数据组织器114可以将val-m1的值从mem-m1中的当前的计算列复制到mem-m2的在r-indx中具有与mem-m1中的当前项的c-indx的值相等的值的所有计算列中的val-m1。
[0071]
在步骤1150中,数据组织器114可以检查是否已经处理了所有新选定的项。如果仍然有未处理的项,则数据组织器114可以返回到步骤1130。在步骤1160中,乘法单元116可以并行地将val-m1的值与mem m2中的val-m2的值相乘,从而提供m1的行和m2的列的m1
ik
×
m2
kj
的结果。在步骤1170中,加法器118可以将所有乘法结果相加从而提供等式1的求和;并且在步骤1180中,加法器118可以将结果复制到输出表mem-m3。在步骤1190中,数据组织器114可以检查是否已经处理了所有计算列。如果mem-m1中存在未被标记为已处理的计算列,则数据组织器114可以返回到步骤1110,否则,可以在步骤1195中完成操作,并且可以根据存储在mem-m3中的信息以关于图3(其描述如何存储矩阵)所描述的操作的反向操作来创建结果矩阵m3。
[0072]
下面提供与图11的流程相关的伪代码:
[0073]
10)针对m1中所有未标记的条目进行重复
[0074]
20)选择m1中下一个未标记的条目
[0075]
30)读取其行索引
[0076]
40)标记m1中具有相同行索引的所有项
[0077]
50)针对m1的所有被标记的行
[0078]
60)针对col(m1)=row(m2)对m2进行搜索
[0079]
70)将所选定的值复制(分配)到输出表位线
[0080]
80)并行相乘
[0081]
90)对属于同一列的所有值进行移位并相加
[0082]
100)更新输出表
[0083]
110)退出
[0084]
对流程1100以及伪代码的描述是出于示例性目的的,并且本领域技术人员可以认识到的是,可以在具有变型的情况下来实践该流程。这些变型可以包括更多步骤、更少步骤、改变步骤序列、跳过步骤以及对于本领域技术人员显而易见的其他变型。
[0085]
现在参考的图12-36示意性示出了根据流程1100将两个示例性稀疏矩阵相乘的步骤。在图12中,数据组织器114可以在mem-m1中找到下一个未标记的计算列(其为col-1)。接下来,在图13中,数据组织器114可以读取找到的计算列的r-indx的值(其为1)。接下来,在图14中,数据组织器114可以找到mem-m1的具有与找到的计算列的r-indx的值相同的r-indx的值的所有计算列,并且将所有这些计算列(包括找到的计算列)标记为新选定的。
[0086]
在图15中,数据组织器114可以选择被标记的计算列中的一个(col-1)作为当前的,并且可以读取存储在mem-m1的col-1的c-indx中的值(其为2)。在图16中,数据组织器114可以在mem-m2中找到在r-indx中具有与mem-m1的col-1中的c-indx的值相同的值的所有计算列(其仅为col-1),并且在图17中,数据组织器114可以将该值(其为1)从mem-m1的计算列col-1的val-m1复制到mem-m2的col-1的val-m1,并且将当前计算列(mem-m1中的col-1)标记为已处理。
[0087]
重复在图13-17中描述的操作,直到处理完所有被标记的项,在该示例中,这些操作仅重复一次(因为仅有两个被标记的计算列)。在图18中,数据组织器114可以找到下一个被标记的计算列(其为col-4),并且从c-indx读取该值(其为4)。在图19中,数据组织器114可以找到mem-m2中具有r-index=4的所有计算列,并且在图20中,数据组织器114可以将val-m1从mem-m1的col-4复制到mem-m2的col-3和col-4的val-m1,并且将mem-m1的col-4标记为已处理。
[0088]
在图21中,乘法单元116可以同时地将val-m1的值与mem-m2的计算列col-1、col-3和col-4的val-m2的值相乘,并且可以存储在mem-m2的prod行中。可以认识到的是,如果mem-m2包含具有相同c-indx值的多个计算列,则加法器118可以对相关计算列的值求和并且将结果存储在mem-m2的out行中。在该示例中,每个相乘的计算列可以在c-indx中具有另一值,因此prod行中的值被按原样复制到out行。
[0089]
在图22中,乘法单元116可以将c-indx的值以及相乘的所有计算列(即,mem-m2的col-1、col-3和col-4)的out行中的结果以及r-indx的值从mem-m1(对于所有处理的计算列来说是相同的)复制到mem-m3。
[0090]
在图23-38中,重复相同的过程,直到在图38中处理了mem-m1的所有计算列,并且
最终结果存储在mem-m3中。可以认识到的是,结果矩阵是图10的预期矩阵m3。
[0091]
可以认识到的是,类似的概念可以用于将密集矩阵与稀疏向量相乘,如现在参考的图39所示出的。数据组织器114可以将密集矩阵m4中的所有值存储在类似于其矩阵表示的关联存储器120的mem-m4中。数据组织器114可以将向量v1的非零元素的值存储在关联存储器120中的行val-v1中,并且将非零元素在向量v1中的相关联的位置存储在关联存储器120中的行indx中。
[0092]
在图40中,数据组织器114可以将mem-v1的第一值(其为1)复制到mem-m4的所有计算列(col-1和col-2)中。在图41中,乘法单元116可以读取mem-v1的所选定的计算列的indx行的值(其为2),并且可以将存储在mem-m4的相关行(row-2)中的值与存储在行val-v1中的值相乘,并且可以将结果写入mem-m4的行prod-1中。
[0093]
在图42中,数据组织器114可以将下一值(其为3)从mem-v1复制到mem-m4的val-v1中,并且在图43中,乘法单元116可以读取mem-v1的所选定的计算列的indx行的值(其为4),并且可以将存储在mem-m4的相关行(row-4)中的值与存储在行val-v1中的值相乘,并且加法器118可以将乘法的结果与先前步骤的结果相加,因此,在mem-m4的行prod中的值在col-1中为4+(3
×‑
1)=1,以及在col-2中为-2+(3
×
2)=4,其提供了mem-m4的行prod中的预期结果向量。
[0094]
可以认识到的是,在本发明的替代实施例中,乘法单元116和加法器118是相同的组件,从而同时执行乘法运算和加法运算。
[0095]
虽然本文已经说明并描述了本发明的某些特征,但是本领域普通技术人员现在将想到许多修改、替换、改变和等效物。因此,应该理解的是,所附权利要求书旨在覆盖落入本发明的真正精神内的所有这些修改和改变。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1